




【PyTorch学习率调度策略】:动态调整提升模型性能

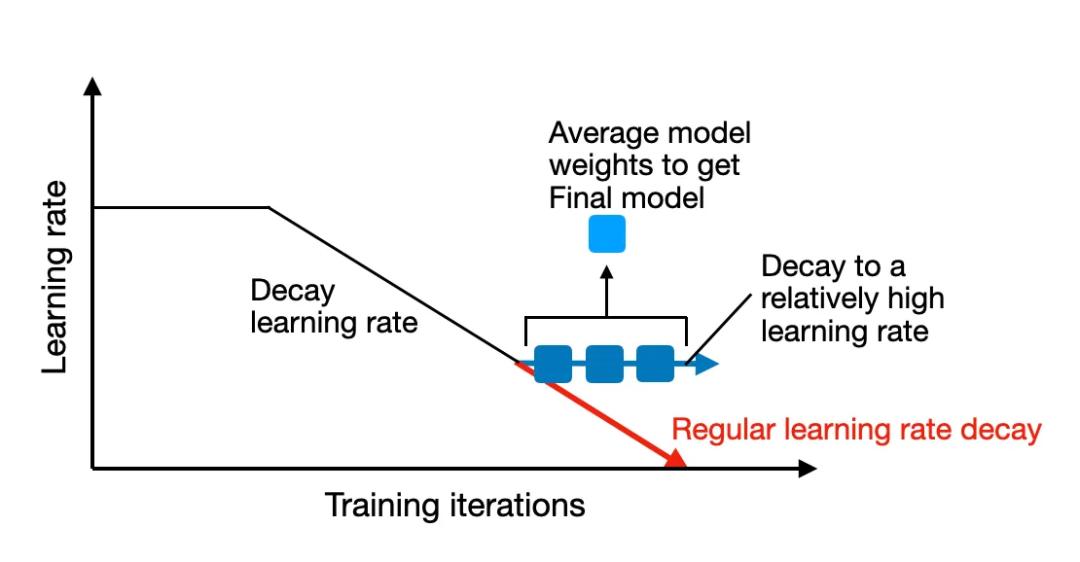
1. PyTorch学习率调度策略概述
在深度学习模型训练过程中,学习率是影响模型收敛速度与最终性能的关键超参数之一。PyTorch作为流行的深度学习框架,提供了多种学习率调度策略,旨在帮助研究者和开发者更好地控制学习过程,提高模型训练的效率和效果。本章将对PyTorch中的学习率调度策略进行概述,为后续章节深入探讨学习率调度的理论基础及其在PyTorch中的实践应用奠定基础。
本章内容将覆盖学习率调度的基本概念、PyTorch提供的各种调度器类型以及它们的使用场景。通过对这些调度器的初步认识,读者将能够为自己的模型训练选择合适的调度策略,并为深入学习后续章节内容打下坚实的基础。
接下来,我们将详细探讨学习率对模型训练的影响,并介绍几种常见的学习率调度方法,包括固定学习率、衰减策略以及动态调整方法等。通过这些理论和实践的结合,我们能够更深入地理解学习率调度策略的重要性及其对模型性能的积极作用。
2. 学习率调度的理论基础
2.1 学习率对模型训练的影响
2.1.1 学习率的作用与重要性
学习率是深度学习中调整模型权重的一个关键超参数。它决定了在梯度下降过程中权重更新的步长大小。学习率设置得当,可以使模型快速收敛到最小损失值;设置不当,则可能导致模型难以收敛,或者收敛速度过慢。在优化过程中,学习率是连接权重更新与损失函数梯度的桥梁。一个合理的学习率可以确保模型参数在损失函数的梯度方向上有效地更新。
2.1.2 学习率过小与过大的问题
当学习率过小时,模型的更新步长太小,这会导致训练过程非常缓慢,甚至停滞不前。这种情况可能会陷入局部最小值,或者在达到全局最小值之前消耗过多的时间和资源。
相反,当学习率设置过大时,模型的权重更新步长过大,这可能会导致模型在优化过程中在最小值附近震荡,甚至发散。学习率过大也可能导致梯度爆炸的问题,使得模型权重快速增长,模型失去控制,无法训练。
2.2 常见的学习率调度方法
2.2.1 固定学习率与衰减策略
固定学习率是一种简单直接的学习率设置方法,一旦设定,在训练过程中保持不变。虽然简单,但固定学习率可能无法适应训练过程中损失函数变化的需求。为了克服这个问题,学习率衰减策略被引入。学习率衰减是指在训练过程中的某些特定时刻或按照某种规则逐渐减小学习率,以帮助模型在训练后期更加细致地调整权重,达到更好的性能。
2.2.2 动态调整方法:Step、MultiStep、Exponential等
动态学习率调度方法可以根据训练进度调整学习率。Step调度方法在固定的训练轮次(epochs)后按比例减小学习率;MultiStep调度则在几个预定的轮次点减小学习率;Exponential调度则以指数方式逐渐减小学习率。这些方法试图在训练初期快速下降损失函数,而在后期则细致地调整权重以优化性能。
2.3 学习率调度的理论模型
2.3.1 学习率预热与循环学习率
学习率预热是在训练初期使用一个较小的学习率,让模型稳定下来之后,再逐渐增大到一个正常的值。循环学习率则是指在训练过程中周期性地改变学习率,从而使得模型在不同的学习率之间循环,每个周期都试图找到损失函数的最小值。
2.3.2 优化器的自适应学习率调整
自适应学习率优化器,如Adam、RMSprop等,内部包含了一个对学习率进行自适应调整的机制。这些优化器可以对不同参数的学习率进行不同的调整,依据历史梯度的大小和方向来决定每个参数应该采用的学习率。这使得模型训练更加稳定,并能更快地收敛到一个较好的性能。
以上章节内容对学习率调度策略的理论基础进行了概述,接下来的章节将会进一步介绍PyTorch中学习率调度的实践细节和应用案例。
3. PyTorch中的学习率调度实践
学习率调度是深度学习模型训练中非常关键的步骤。在PyTorch中,通过其灵活的学习率调度策略,能够帮助我们更好地控制训练过程,提高模型性能。本章将深入探讨如何在PyTorch中实现和优化学习率调度。
3.1 使用torch.optim进行学习率调度
3.1.1 配置基础优化器与学习率
在PyTorch中,首先需要配置一个基础优化器,并为其设置一个初始学习率。优化器是根据损失函数来更新网络权重的算法。学习率则是优化器调整模型权重的步长。
- import torch
- from torch.optim import SGD # 使用随机梯度下降优化器作为例子
- # 假设已经定义了模型model以及损失函数criterion
- model = ... # 模型定义
- criterion = ... # 损失函数定义
- # 配置优化器和学习率
- optimizer = SGD(model.parameters(), lr=0.01)
3.1.2 应用预设的学习率调度器
PyTorch提供了多种预设的学习率调度器,如StepLR、MultiStepLR、ExponentialLR等。这些调度器可以在训练过程中自动调整学习率。
- from torch.optim.lr_scheduler import StepLR
- # 设置学习率调度器,每2个epoch学习率衰减为原来的0.1
- scheduler = StepLR(optimizer, step_size=2, gamma=0.1)
在训练循环中,更新模型权重后紧接着更新学习率:
- # 训练循环
- for epoch in range(num_epochs):
- for inputs, targets in dataloader:
- optimizer.zero_grad()
- outputs = model(inputs)
- loss = criterion(outputs, targets)
- loss.backward()
- optimizer.step()
- scheduler.step() # 更新学习率
3.2 自定义学

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Quartus Qsys问题解决宝典】
无线网络优化中的ADMM:案例分析与作用解析
【PLC高阶应用】:双字移动指令SLDSRD,解锁编程新境界
【显示符号-IDL跨语言交互】:在跨语言开发中的关键作用
Drools WorkBench大数据挑战应对策略:处理大规模规则集
ViewPager技术指南:按需调整预加载策略
【制造业CPK应用】:提升生产过程能力指数的秘诀
【Eclipse IDE火星版深度解析】:MacOSx开发者必学的21个技巧
项目配置管理计划的配置审计:验证配置项完整性的3大关键步骤


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















