【2023版】动态数据源配置手册:Spring Boot、MyBatis与Druid终极融合策略
发布时间: 2024-12-26 07:45:59 阅读量: 5 订阅数: 14 

spring-boot-security-druid-mybatis:spring boot mybatis整合项目

# 摘要
随着业务需求的复杂化,动态数据源管理已成为现代企业级应用开发的热点。本文首先探讨了业务需求对动态数据源提出的新挑战,接着详细分析了Spring Boot与MyBatis整合的技术细节,并基于此框架实现了动态数据源的配置与管理。文章进一步提供了将动态数据源应用于实际项目的案例分析,深入剖析了动态数据源在大型项目中的优势和实施策略,以及在微服务架构中的应用。文章最后讨论了动态数据源实施过程中遇到的挑战和未来的发展方向,旨在为相关领域的开发者提供实践指导和理论支持。
# 关键字
动态数据源;Spring Boot;MyBatis;数据源管理;微服务架构;案例分析
参考资源链接:[SILVACO TCAD工具使用教程:源/漏极退火与NMOS工艺仿真](https://wenku.csdn.net/doc/4jdeu8qxjz?spm=1055.2635.3001.10343)
# 1. 动态数据源的业务需求与技术选型
## 1.1 业务需求背景
在现代的企业级应用中,业务需求的多样性导致数据源配置的复杂性日益增加。随着业务规模的扩大和用户数量的增长,如何有效管理多个数据源成为IT系统架构中的一个重要议题。动态数据源的引入旨在解决多数据源环境下的挑战,如读写分离、故障转移和负载均衡等。
## 1.2 动态数据源的必要性
动态数据源允许应用程序在运行时根据不同情况选择最合适的数据源,实现数据源的动态切换。这种机制提高了系统的灵活性和扩展性,从而支持复杂的业务场景,例如在线分析处理(OLAP)和在线事务处理(OLTP)的分离,以及高可用架构的实现。
## 1.3 技术选型考量
选择合适的技术栈对于实现动态数据源至关重要。Spring Boot因其简洁的自动配置和强大的社区支持成为Java领域的首选框架。MyBatis作为一款持久层框架,以其高度的定制性和清晰的SQL语句管理优势,在众多ORM框架中脱颖而出。结合这些技术,我们可以构建出灵活高效的数据访问层,支持动态数据源的需求。下一章我们将深入探讨Spring Boot与MyBatis的整合基础。
# 2. Spring Boot与MyBatis整合基础
## 2.1 Spring Boot的自动配置原理
### 2.1.1 Spring Boot自动配置概览
Spring Boot提供了一种快速便捷的方式来创建独立的、生产级别的基于Spring框架的应用。自动配置是Spring Boot的核心特性之一,旨在简化项目搭建和配置过程。通过自动配置,Spring Boot能够根据项目中添加的依赖自动推断出应该如何配置Spring应用。例如,在项目中引入了`spring-boot-starter-web`依赖后,它会自动配置嵌入式的Tomcat服务器、Spring MVC等。
自动配置的过程由`spring-boot-autoconfigure`模块管理。该模块包含众多以`spring.factories`文件形式存在的自动配置类。这些配置类是通过条件注解`@Conditional`系列(例如`@ConditionalOnClass`、`@ConditionalOnMissingBean`)来定义条件的,从而确保只有在满足特定条件时,相应的配置才会生效。
### 2.1.2 自定义自动配置案例分析
理解自动配置的原理后,我们可以通过创建自定义的自动配置来深入掌握这一过程。让我们以一个简单的MyBatis自动配置为例:
1. 创建一个新的Spring Boot应用,并添加MyBatis依赖。
2. 在`src/main/resources/META-INF`目录下创建一个名为`spring.factories`的文件。
3. 在该文件中指定我们的自动配置类,例如:
```properties
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.demo.config.MyBatisConfiguration
```
4. 创建自动配置类`MyBatisConfiguration`,使用`@Configuration`注解标记该类作为配置类,同时使用`@ConditionalOnClass`来确保当`SqlSessionFactory`、`DataSource`等MyBatis相关类存在时才会加载该配置:
```java
@Configuration
@ConditionalOnClass({SqlSessionFactory.class, SqlSessionFactoryBean.class})
public class MyBatisConfiguration {
@Bean
@ConfigurationProperties(prefix = "mybatis.configuration")
public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource) {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
return sqlSessionFactoryBean;
}
@Bean
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
```
5. 最后,定义`application.yml`或`application.properties`来配置数据源和MyBatis的属性,例如:
```yaml
mybatis:
configuration:
mapUnderscoreToCamelCase: true
spring:
datasource:
url: jdbc:mysql://localhost:3306/db_example
username: user
password: pass
```
这样,当启动Spring Boot应用时,如果你已经正确地引入了相关依赖并配置了数据源,那么Spring Boot将自动配置MyBatis。
## 2.2 MyBatis的集成与配置
### 2.2.1 MyBatis的组件和作用域
MyBatis是一个持久层框架,它简化了JDBC操作,支持定制化SQL、存储过程以及高级映射。MyBatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集。MyBatis可以使用简单的XML或注解来配置和映射原生信息,将接口和Java的POJOs(Plain Old Java Objects,普通老式Java对象)映射成数据库中的记录。
MyBatis的主要组件有:
- SqlSessionFactory:用于创建SqlSession实例的工厂。
- SqlSession:执行持久层操作的会话,类似于JDBC中的Connection,可以获取Mapper接口的代理实例。
- Mapper接口:定义SQL操作语句的接口。
- XML Mapper:映射SQL语句的XML文件。
MyBatis组件的作用域:
- SqlSessionFactoryBuilder:作用范围是局部变量,它用来创建SqlSessionFactory。
- SqlSessionFactory:作用范围是应用作用域,一旦创建就应该在应用的运行期间一直存在,没有任何理由来丢弃它或重新创建另一个实例。
- SqlSession:作用范围是方法作用域,每个线程都应该有它自己的SqlSession实例。
- Mapper实例:作用范围是方法作用域,每个Mapper实例应该只对应一个SqlSession。
### 2.2.2 配置MyBatis的核心组件
要配置MyBatis的核心组件,首先需要在Spring Boot项目中添加MyBatis的依赖,例如使用Maven添加`mybatis-spring-boot-starter`依赖。然后,通过`application.properties`或`application.yml`配置文件定义数据源和MyBatis的属性。配置示例如下:
```yaml
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.example.demo.model
```
这里的`mapper-locations`属性指定了MyBatis的Mapper XML文件的位置,`type-aliases-package`指定了类型别名包的路径。
### 2.2.3 MyBatis与Spring Boot整合策略
在Spring Boot中整合MyBatis,我们通常采用以下策略:
1. **配置数据源**:使用Spring Boot自动配置的数据源或自定义数据源配置。
2. **配置SqlSessionFactory**:通过`@Bean`注解配置一个SqlSessionFactory bean,并且指定数据源以及MyBatis的配置信息,例如:
```java
@Bean
@ConfigurationProperties(prefix = "mybatis.configuration")
public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource) {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:mapper/**/*.xml"));
sqlSessionFactoryBean.setTypeAliasesPackage("com.example.demo.model");
return sqlSessionFactoryBean;
}
```
3. **注册Mapper接口**:MyBatis与Spring Boot整合后,可以直接在Mapper接口上添加`@Mapper`注解,这样Spring Boot会自动注册这些接口为bean。
## 2.3 数据源的基本配置与管理
### 2.3.1 配置数据源的基本属性
在Spring Boot中,数据源的配置相对简单。只需要在`application.properties`或`application.yml`文件中指定数据源的相关属性即可。例如,配置MySQL数据库的数据源属性如下:
```yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/your_database?useSSL=false&serverTimezone=UTC
username: your_username
password: your_password
driver-class-name: com.mysql.cj.jdbc.Driver
```
这里的`url`是数据库的URL地址,`username`和`password`是访问数据库的用户名和密码,`driver-class-name`是JDBC驱动类的全限定名。对于`useSSL`和`serverTimezone`的设置是为了在某些数据库连接场景中避免SSL握手警告和时区问题。
### 2.3.2 使用Spring的DataSource进行数据源管理
Spring提供了一个`DataSource`接口,它是用于获取数据库连接的工厂对象。在Spring Boot应用中,数据源的管理非常简单,只需配置`spring.datasource.*`属性,Spring Boot就能自动配置数据源,比如使用HikariCP作为默认的连接池实现。
如果你需要自定义数据源,可以使用`@Bean`注解定义一个`DataSource` bean,并且指定数据源的实现类。例如,配置Druid数据源的示例如下:
```java
@Bean
@ConfigurationProperties(prefix = "spring.datasource.druid")
public DataSource dataSource() {
return new DruidDataSource();
}
```
在上面的代码中,`DruidDataSource`是阿里巴巴开源的一个数据库连接池实现。通过`@ConfigurationProperties`注解,可以将配置文件中的属性值映射到`DruidDataSource`实例的相应属性上。
### 2.3.3 使用Spring的JdbcTemplate进行数据库操作
Spring提供了`JdbcTemplate`类,它是对JDBC API的封装,提供了更简洁、更安全的方式来操作数据库。使用`JdbcTemplate`之前,需要将它注册为Spring管理的bean:
```java
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
```
注册`JdbcTemplate` bean后,可以在服务层直接注入并使用它来执行SQL查询或更新:
```java
@Service
public class SomeService {
private final JdbcTemplate jdbcTemplate;
@Autowired
public SomeService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public void performDatabaseOperation() {
jdbcTemplate.update("INSERT INTO some_table (column1, column2) VALUES (?, ?)", "value1", "value2");
List<Map<String, Object>> rows = jdbcTemplate.queryForList("SELECT * FROM some_table");
}
}
```
在这个服务类`SomeService`中,`performDatabaseOperation`方法演示了如何使用`JdbcTemplate`进行数据插入和查询操作。通过这样的实践,开发者可以轻松地实现数据访问层的编码,而无需直接处理JDBC资源的管理。
# 3. 动态数据源的配置与实现
在构建复杂的业务系统时,经常需要面对多数据源的管理问题。本章节将深入探讨动态数据源的配置与实现细节,包括需求分析、具体实现方法以及高级特性。随着企业系统的发展,数据源的动态配置和管理成为一项关键技术挑战。
## 3.1 动态数据源配置的需求分析
### 3.1.1 多数据源环境下的挑战
在多数据源环境中,最常见的问题是如何有效管理这些数据源以及如何在不同的数据源之间进行切换。这涉及到几个关键挑战,包括但不限于:
- **连接管理:** 如何管理不同数据源的数据库连接池,保证连接的有效复用和及时回收。
- **性能优化:** 在不同数据源之间切换时,性能优化成为重要考虑因素,需要减少切换带来的性能损耗。
- **代码可维护性:** 数据源切换逻辑不应该导致业务代码复杂度的大幅增加。
### 3.1.2 动态切换数据源的策略
动态切换数据源的基本策略通常包含以下几点:
- **使用数据源标识符:** 通过定义明确的数据源标识符,在业务逻辑中根据实际需要选择合适的数据源。
- **数据源上下文:** 利用上下文信息存储当前线程使用的是哪个数据源,以支持后续的切换。
- **中间件支持:** 依赖于数据库中间件来管理数据源,例如MyCat、ShardingSphere等。
## 3.2 动态数据源的具体实现
### 3.2.1 自定义数据源切换逻辑
为了实现数据源的动态切换,可以自定义一个数据源切换逻辑类,例如`DataSourceContextHolder`。这个类的职责是在不同数据源之间切换上下文,代码示例如下:
```java
public class DataSourceContextHolder {
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setDataSourceType(String dataSourceType) {
contextHolder.set(dataSourceType);
}
public static String getDataSourceType() {
return contextHolder.get();
}
public static void clearDataSourceType() {
contextHolder.remove();
}
}
```
### 3.2.2 集成Druid数据源
Druid是一个优秀的数据库连接池实现,它提供了监控功能,并且可以很容易地与Spring Boot整合。使用Druid数据源可以方便地实现动态数据源的管理。配置示例如下:
```java
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.druid.master")
public DataSource masterDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.druid.slave")
public DataSource slaveDataSource() {
return DruidDataSourceBuilder.create().build();
}
// ... 配置DataSource路由逻辑
}
```
### 3.2.3 实现数据源上下文(DataSourceContextHolder)
`DataSourceContextHolder`是实现动态数据源切换的核心,它利用ThreadLocal存储当前线程使用的数据源标识。以下是一个简单的数据源切换逻辑实现:
```java
public class DataSourceContextHolder {
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setDataSourceType(String dataSourceType) {
contextHolder.set(dataSourceType);
}
public static String getDataSourceType() {
return contextHolder.get();
}
public static void clearDataSourceType() {
contextHolder.remove();
}
}
```
## 3.3 动态数据源的高级特性
### 3.3.1 配置读写分离
读写分离是一种常见的数据库管理策略,可以提高系统的读取性能,减轻数据库的写操作压力。在动态数据源配置中,可以通过配置多个数据源,一个作为写库,多个作为读库,根据业务需求选择对应的数据库进行操作。
### 3.3.2 实现数据源路由策略
数据源路由策略用于决定在特定的业务场景下使用哪个数据源。路由策略通常依赖于数据源上下文,结合业务逻辑动态选择数据源。下面是一个简单的路由策略实现示例:
```java
public class MyBatisDynamicSQLSessionFactory extends SqlSessionFactoryBean {
@Autowired
private MyBatisDynamicDataSource dynamicDataSource;
@Override
public void afterPropertiesSet() throws Exception {
super.setDataSource(dynamicDataSource);
SqlSessionFactory sqlSessionFactory = this.getSqlSessionFactory();
sqlSessionFactory.getConfiguration().setObjectWrapperFactory(new MyObjectWrapperFactory());
}
}
```
以上就是动态数据源配置与实现的基本思路和核心实现细节。在下一章中,我们将结合Spring Boot和MyBatis来实现动态数据源,并展示具体的编码实践。
# 4. 实践应用:结合Spring Boot和MyBatis实现动态数据源
## 4.1 基于Spring Boot的配置整合
### 4.1.1 配置文件与环境的准备
在实现动态数据源之前,首先需要对Spring Boot项目进行基础配置。配置文件是配置数据源的关键,可以使用`application.properties`或`application.yml`来完成数据源的配置。我们通常在`application.properties`中添加如下基本属性:
```properties
spring.datasource.url=jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
```
这里配置了数据库的URL、用户名、密码和驱动类名。在进行数据源的配置之前,还需要确保项目中已经添加了必要的依赖,如`spring-boot-starter-jdbc`、`mybatis-spring-boot-starter`以及对应数据库的驱动依赖。
### 4.1.2 Spring Boot配置Druid数据源
Druid是阿里巴巴提供的一个数据库连接池实现,具有强大的监控和扩展功能。为了使用Druid作为连接池,首先需要在项目中添加Druid的依赖:
```xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
```
然后,可以在配置文件中进行Druid连接池的配置,以自定义连接池的属性:
```properties
spring.datasource.druid.initial-size=5
spring.datasource.druid.min-idle=5
spring.datasource.druid.max-active=20
spring.datasource.druid.max-wait=60000
spring.datasource.druid.time-between-eviction-runs-millis=60000
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.filters=stat,wall,log4j
```
通过这些配置,我们已经为Spring Boot项目设置了Druid数据源。但要实现动态数据源,还需要进一步编写代码逻辑来处理数据源的动态切换。
## 4.2 动态数据源的编码实践
### 4.2.1 编写数据源切换逻辑
在Spring Boot和MyBatis环境下实现动态数据源的核心在于创建一个能够根据业务场景动态选择数据源的逻辑。下面是一个简单示例,展示如何编写数据源切换的逻辑:
```java
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// 此处是动态选择数据源的逻辑,可以根据ThreadLocal或者某个标识符来决定使用哪个数据源
return DataSourceContextHolder.getDataSourceType();
}
}
```
`AbstractRoutingDataSource`是Spring提供的一个抽象类,用于实现基于查找键(Key)来切换数据源。`DataSourceContextHolder`是一个自定义类,用于存储当前线程所使用的数据源类型。
### 4.2.2 实现基于注解的数据源动态切换
要实现基于注解的数据源动态切换,首先需要创建一个自定义注解`@DataSource`,用于标记需要切换到哪个数据源:
```java
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface DataSource {
String value();
}
```
然后,使用`AspectJ`来拦截带有`@DataSource`注解的方法,并执行数据源切换的逻辑:
```java
@Aspect
@Component
public class DataSourceAspect {
@Before("@annotation(com.example.DataSource)")
public void beforeSwitchDS(JoinPoint point) {
MethodSignature signature = (MethodSignature) point.getSignature();
DataSource ds = signature.getMethod().getAnnotation(DataSource.class);
if (ds == null) {
DataSourceContextHolder.useMasterDataSource();
return;
}
DataSourceContextHolder.useDataSource(ds.value());
}
}
```
### 4.2.3 测试动态数据源的稳定性
测试动态数据源的稳定性是一个重要步骤,需要确保在各种不同业务场景下,动态数据源都能正确切换,并且保证事务的正确性。可以通过编写单元测试或者集成测试来进行验证。
## 4.3 动态数据源的监控与优化
### 4.3.1 配置Druid监控统计功能
为了监控和优化数据源,可以利用Druid提供的监控统计功能。首先需要在Spring配置中添加Druid的Servlet配置:
```java
@Configuration
public class DruidConfig {
@Bean
public ServletRegistrationBean druidServlet() {
ServletRegistrationBean reg = new ServletRegistrationBean();
reg.setServlet(new StatViewServlet());
reg.addUrlMappings("/druid/*");
return reg;
}
}
```
### 4.3.2 分析监控结果并优化数据源配置
在配置完成监控统计功能后,可以通过访问`http://<host>:<port>/<context>/druid/login.html`来查看监控界面。登录后,可以看到数据源使用情况、SQL监控、慢SQL列表、数据库访问日志等详细信息。
通过监控结果,可以分析数据源的使用情况,根据实际情况对数据源配置进行调优。例如,如果发现某个数据源的连接池频繁被耗尽,可能需要增加最大连接数,或者调整连接池的其他参数来优化性能。
通过以上内容,我们完成了Spring Boot结合MyBatis实现动态数据源的编码实践,并通过测试验证了动态数据源的稳定性。同时,介绍了如何配置Druid监控统计功能,并使用监控结果来进行数据源配置的优化。在下一章节中,我们将探讨动态数据源在生产环境中的高级应用,包括多级配置策略和动态热加载等高级特性。
# 5. 动态数据源的扩展功能
## 5.1 动态数据源的多级配置策略
### 5.1.1 多级数据源配置的必要性
在处理复杂的业务场景时,可能不仅仅需要多个数据源,还需要在不同的数据源之间实现更细粒度的管理。这就需要一个多级数据源配置策略,这样的策略可以更好地适应层次化的系统架构设计,比如在微服务架构中,每个微服务可能需要访问多个数据库实例。
在大型项目中,不同模块之间可能需要独立的数据源,以避免数据隔离或者依赖的问题。此外,多级数据源配置可以有效地解决数据库实例升级、迁移或者维护过程中,对业务服务的影响降到最低。
### 5.1.2 实现多级数据源动态切换
实现多级数据源的关键是构建一个分层的数据源配置和管理机制。这通常涉及到以下几个步骤:
- **定义数据源组**:将相关的数据源按照业务或功能进行分组,形成数据源组。每个数据源组内可以包含多个数据源。
- **配置管理策略**:为每个数据源组定义一套管理策略,包括数据源的创建、销毁、切换等。
- **动态切换逻辑**:实现一套动态切换逻辑,当业务请求发生时,根据配置的策略和条件,实时切换到对应的数据源组中的某个数据源。
在实现上,可以利用Spring Boot和MyBatis提供的配置和扩展点,以及Java的动态代理或者AOP技术,来动态地拦截数据库操作,并根据上下文信息切换到正确的数据源。
```java
// 示例代码:数据源路由策略实现
public class DynamicDataSourceStrategy {
private static final ThreadLocal<String> currentDataSourceKey = new ThreadLocal<>();
public static void setDataSourceKey(String key) {
currentDataSourceKey.set(key);
}
public static String getDataSourceKey() {
return currentDataSourceKey.get();
}
public static void clearDataSourceKey() {
currentDataSourceKey.remove();
}
}
```
在上述代码中,`currentDataSourceKey` 用于存储当前线程需要使用的数据源标识,通过设置和清除线程局部变量来实现数据源的切换。
## 5.2 数据源配置的动态热加载
### 5.2.1 动态热加载的概念与实现
动态热加载指的是在应用程序运行时,不需要重启服务就能加载新的配置或修改现有配置,并立即生效的技术。在动态数据源的场景下,动态热加载可以实现在不中断服务的前提下,动态地添加、删除或更改数据源配置。
要实现动态热加载,需要做好以下几个方面的工作:
- **支持热加载的配置管理器**:配置管理器需要能够侦听配置文件或配置中心的变化,并在变化发生时更新配置信息。
- **动态更新机制**:实现动态更新机制,以便在配置更新后能够刷新相关的组件,比如数据源连接池的配置。
- **线程安全和事务控制**:确保热加载过程中数据的一致性和线程安全。
### 5.2.2 配置热加载对应用的影响
动态热加载虽然提供了便利,但也可能给应用程序带来一些风险,包括但不限于:
- **配置不一致问题**:在动态加载配置的瞬间,可能会出现服务端读取到的是旧的配置信息,而另一部分客户端已经读取到新的配置信息,从而导致配置不一致。
- **性能开销**:频繁的配置检查和动态加载可能会对性能产生影响,尤其是在高并发的环境下。
- **异常处理**:需要设计合理的异常处理和回滚机制,以确保在更新配置失败时不会导致服务不稳定。
为了缓解上述问题,可以采取以下措施:
- **原子性配置更新**:确保配置更新的原子性,更新操作要么完全成功,要么完全不执行。
- **变更通知机制**:通过事件或消息通知机制来触发配置更新,而不是频繁检查配置文件。
- **日志与监控**:在配置更新过程中加入详细的日志记录和实时监控,以便于问题的追踪和调试。
## 5.3 动态数据源与微服务架构
### 5.3.1 微服务架构下的数据源管理
在微服务架构下,服务往往由多个独立部署且可独立扩展的微服务组成,每个微服务可能需要访问一个或多个数据库。动态数据源为微服务架构提供了灵活的数据访问策略,使得每个微服务可以有自己独立的数据源配置,而不受其他服务的影响。
为了在微服务架构中有效地使用动态数据源,需要考虑以下几个方面:
- **服务注册与发现**:数据源的配置信息可以通过服务注册与发现机制来管理,服务启动时从配置中心获取自己的数据源配置。
- **配置中心的统一管理**:配置中心统一管理微服务的数据源配置,确保配置的一致性和实时性。
- **服务边界清晰**:微服务之间通过定义清晰的边界,实现数据源的独立管理,避免服务间的数据库直接依赖。
### 5.3.2 动态数据源在微服务中的应用案例
假设有一个电商系统的微服务架构,不同的微服务负责不同的业务领域,如用户管理、商品管理、订单管理等。在这种情况下,每个服务都需要访问对应的数据库,且每个数据库都有可能在不同的节点上。
使用动态数据源可以为每个服务提供一个数据源池,服务启动时会根据配置中心的配置来初始化自己的数据源池。当需要动态添加或修改某个服务的数据源配置时,可以及时通过配置中心推送新的配置到服务实例,服务实例读取到新的配置后,立即使用新的数据源配置进行数据库操作。
```mermaid
flowchart LR
A[配置中心] -->|推送配置| B[服务A]
A -->|推送配置| C[服务B]
A -->|推送配置| D[服务C]
B -->|使用数据源| E[数据库A]
C -->|使用数据源| F[数据库B]
D -->|使用数据源| G[数据库C]
```
在上面的流程图中,配置中心负责统一管理各个服务的数据源配置,当配置发生变化时,会推送到对应的服务实例。各个服务在接收到新的配置后,会立即使用新的数据源配置进行操作。
通过这种方式,不仅保证了数据源配置的灵活性和可扩展性,也确保了微服务架构下的服务自治和高可用性。
# 6. 案例分析:动态数据源在大型项目中的应用
在第五章中,我们深入探讨了动态数据源的高级功能以及其在微服务架构中的应用。本章将通过具体的案例分析,进一步了解动态数据源在实际大型项目中的应用情况,并且探讨在实际操作过程中遇到的挑战以及未来的发展趋势。
## 6.1 动态数据源解决的实际问题
### 6.1.1 问题背景与业务场景
在大型企业的业务系统中,经常会遇到需要处理复杂业务流程的情况。比如,一个电商平台可能同时拥有用户订单系统、库存管理系统、支付系统等多个子系统。每个子系统都可能对应独立的数据库,以便于各自业务的高效运作。在这些情况下,动态数据源技术就显得尤为重要了。
例如,电商平台在处理一个购买流程时,需要从用户订单系统中查询用户信息,从库存管理系统中确认商品库存,并且通过支付系统处理交易。这些操作都需要在不同的数据源之间进行切换,而动态数据源技术恰好可以解决这一问题,使得数据库的切换操作对业务代码透明。
### 6.1.2 动态数据源带来的优势分析
动态数据源的应用为大型项目带来了诸多优势:
- **代码解耦**:业务代码不再与特定的数据源耦合,提高了代码的复用性和可维护性。
- **高可用性**:通过动态数据源,可以实现读写分离和故障转移,增强了系统的高可用性。
- **易于扩展**:当新的数据库需要加入系统时,可以快速配置并接入,无需对现有业务逻辑做出大的调整。
## 6.2 大型项目的动态数据源配置实例
### 6.2.1 项目配置文件详解
在大型项目中,配置文件通常会非常复杂,下面是一个配置动态数据源的示例配置文件:
```yaml
spring:
datasource:
dynamic:
primary: masterDataSource
datasource:
masterDataSource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/master_db
username: root
password: root
slaveDataSource1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/slave_db1
username: root
password: root
```
该配置文件定义了一个主数据源`masterDataSource`和一个从数据源`slaveDataSource1`。通过Spring Boot的自动配置,我们可以轻松地在不同数据源之间进行切换。
### 6.2.2 数据源切换机制的实践细节
在实际的业务代码中,数据源的切换通常需要遵循一定的策略。比如,根据操作类型或者业务需求,决定读取的是主数据库还是从数据库。下面是一个简单的数据源切换逻辑的示例代码:
```java
public void processBusiness() {
// 检测当前业务需求,决定使用哪个数据源
if (needReadFromMaster()) {
DataSourceContextHolder.setDataSource("masterDataSource");
} else {
DataSourceContextHolder.setDataSource("slaveDataSource1");
}
// 获取DataSource,执行数据库操作
DataSource dataSource = DataSourceContextHolder.getDataSource();
// ... 执行数据库操作代码 ...
}
```
其中`DataSourceContextHolder`是一个用于存储当前线程数据源标识的工具类。
## 6.3 面临的挑战与未来展望
### 6.3.1 当前实现的局限与挑战
在动态数据源的应用实践中,依然面临一些挑战:
- **一致性问题**:使用多个数据源时,保证数据一致性和同步是一个关键问题。
- **性能问题**:频繁的数据源切换可能会影响系统性能。
- **配置管理**:随着数据源数量的增加,配置和管理的复杂度也会随之增加。
### 6.3.2 动态数据源技术的发展趋势
随着微服务架构的普及和云原生技术的发展,动态数据源技术将会朝着以下几个方向发展:
- **智能化**:动态数据源将集成更多的智能化特性,例如自动化的配置和优化。
- **服务化**:数据源的管理可能会成为一项服务,由专门的服务组件来处理。
- **标准化**:将会出现更多标准化的解决方案,以满足不同业务场景下的需求。
通过本章的案例分析,我们深入了解了动态数据源在大型项目中的实际应用情况,同时也看到了技术的发展趋势。动态数据源技术正在逐渐成为复杂企业级应用不可或缺的一部分,其发展潜力巨大。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Spring Boot 动态数据源配置的各个方面,涵盖了 MyBatis 和 Druid 的高级配置技巧。从源与漏极注入机制到性能优化和退火过程,专栏提供了全面的指南,帮助读者掌握 Spring Boot 动态数据源的方方面面。此外,专栏还提供了实战案例、源码解析、挑战与应对措施,以及生产环境应用教程,为读者提供全面的知识和实践经验。通过深入剖析 Spring Boot、MyBatis 和 Druid 的协同工作原理,本专栏旨在帮助读者构建高效、可扩展和可靠的动态数据源解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MySQL InnoDB数据恢复专家教程】:全面解析数据恢复的10个必要步骤
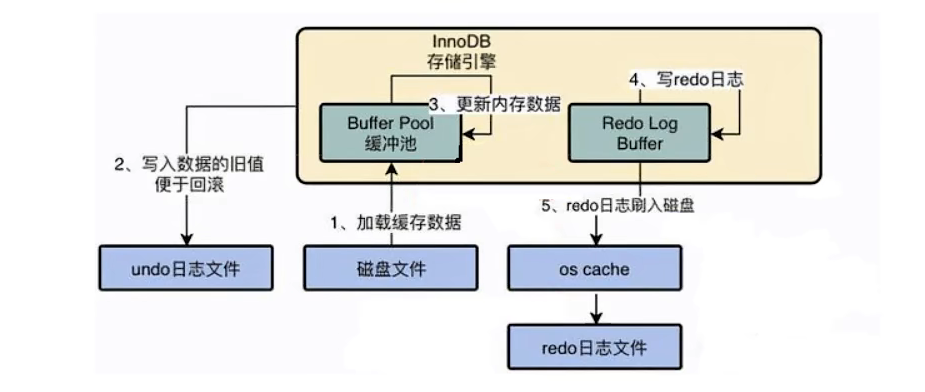
# 摘要
随着信息技术的迅速发展,数据库的稳定性与数据安全性变得尤为重要。本文全面介绍了MySQL InnoDB存储引擎的数据恢复过程,从基础知识到恢复前的准备工作,再到具体的数据恢复方法和步骤。首先阐述了InnoDB存储引擎的结构、事务和锁机制,然后讨论了在数据损坏和系统故障等不同情况下应做的准备工作和备份的重要性。接着,本文详细说
流式处理速成课:设计高效流处理架构的5个实战技巧

# 摘要
流式处理作为一种新兴的数据处理范式,已经成为实时分析和大数据处理的重要技
MySQL基础精讲:5个步骤搞定数据库设计与SQL语句

# 摘要
本文旨在深入介绍MySQL数据库系统的各个方面,包括其基本概念、安装过程、数据库和表的设计管理、SQL语言的基础及进阶技巧和优化,以及MySQL的高级应用。文中首先提供了MySQL的简介和安装指南,随后详细探讨了数据库和表的设计原则,包括规范化理论、逻辑结构设计以及表的创
深入探索AAPL协议:苹果配件开发进阶必备知识

# 摘要
AAPL协议作为一套为特定领域设计的通信标准,其在功能实现、安全性和与其他系统集成方面表现出色。本文首先概述了AAPL协议的基本概念和理论基础,解析了协议的层次结构、核心组件以及数据封装与传输机制。随后,重点介绍了AAPL协议在开发实践中的应用,包括开发环境的搭建、编程接口的使用以
【光模块发射电路全攻略】:彻底掌握设计、测试、优化到故障排除
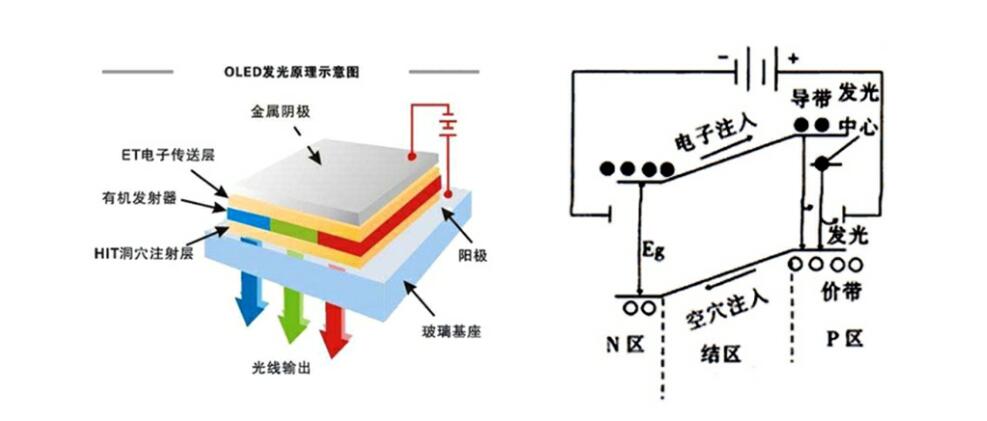
# 摘要
光模块发射电路的设计对于高速数据通信系统的性能和可靠性至关重要。本文首先概述了光模块发射电路设计的基础,涵盖了光通信的理论基础、关键组件选择及技术原理。接着,文章深入探讨了设计实践过程中的注意事项、仿真分析方法以及原型制作和测试。此外,本文还着重分析了电路优化技术与故障排除方法,并对光模块发射电路未来的发展趋势进行了展望,包括新技术的应用前景、行业标准的重
【SIM卡故障诊断手册】:专业IT人士的必备工具
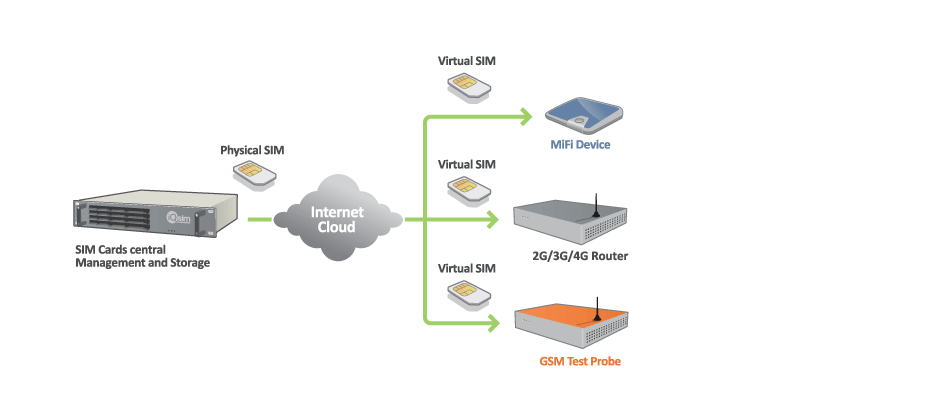
# 摘要
SIM卡是现代通信设备不可或缺的组成部分,其稳定性和安全性对移动通信至关重要。本文全面概述了SIM卡故障诊断的基础知识,深入分析了硬件和软件层面的故障原因,探讨了故障诊断工具和维护技巧。通过对SIM卡物理结构、供电要求、操作系统、应用程序故障的详细讨论,以及对常见故障排除技巧的介绍,本文旨在为行业人员提供一套实用的故障诊断和维护指南。最后,本文展望了SI
红外遥控信号捕获与解码入门:快速上手技巧

# 摘要
红外遥控技术作为一种无线通信手段,在家用电器和消费电子产品中广泛应用。本文首先介绍了红外遥控信号捕获与解码的基础知识,然后深入探讨了红外通信的理论基础,包括红外光的物理特性和红外遥控的工作模式,以及红外遥控信号的编码方式如脉冲编码调制(PCM)和载波频率。文章接着讨论了红外遥控信号捕获所
【性能调优】:Web后台响应速度提升的关键步骤

# 摘要
随着Web应用对性能要求的不断提升,后台性能调优成为保证用户体验和系统稳定性的关键。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )