【快速上手】Spring Boot多数据源实战:MyBatis与Druid的协同工作原理
发布时间: 2024-12-26 07:51:46 阅读量: 4 订阅数: 14 

Spring Boot+Mybatis+Druid+PageHelper实现多数据源并分页的方法
# 摘要
随着软件架构的复杂性增加,多数据源管理成为了现代企业级应用的常见需求。本文首先介绍了Spring Boot框架下多数据源的基本概念,详细探讨了与MyBatis集成的细节,包括核心组件、配置文件、以及接口绑定。接着,文章深入分析了Druid数据库连接池的性能优势、配置、监控和扩展特性,并指导如何在Spring Boot中集成Druid,实现高效的数据源管理。文章还详细说明了多数据源环境的搭建、动态切换策略、事务管理以及实战演练中的关键代码和问题解决方案。最后,本文提出多数据源架构设计的考量,代码质量提升的方法,并通过实战项目案例分析,分享了架构演变和优化经验,为开发者提供了多数据源管理的最佳实践和未来展望。
# 关键字
Spring Boot;MyBatis;Druid连接池;多数据源;动态切换;架构设计
参考资源链接:[SILVACO TCAD工具使用教程:源/漏极退火与NMOS工艺仿真](https://wenku.csdn.net/doc/4jdeu8qxjz?spm=1055.2635.3001.10343)
# 1. Spring Boot多数据源概述
随着业务的发展,单体应用往往会面临性能瓶颈,这时通过引入多数据源进行分库分表是常见的解决方案。Spring Boot多数据源配置允许我们在同一个应用中连接多个数据源,实现不同业务的逻辑分离,提高系统的伸缩性和维护性。
多数据源配置的核心在于理解数据源的抽象和路由机制。开发者可以自定义数据源配置,根据业务需求指定特定的数据源操作,同时要确保事务管理的一致性和数据的完整。
从本章开始,我们将探讨如何在Spring Boot应用中实现多数据源配置,包含其配置方式、最佳实践以及在实现过程中的注意事项和解决方案。首先,我们从基础的概念开始,逐步深入了解如何在Spring Boot项目中集成和管理多个数据源。接下来的章节,我们将详细讲解与MyBatis和Druid数据库连接池的集成,以及多数据源环境的搭建和实战演练。
了解了Spring Boot多数据源的基础知识后,我们将进一步深入了解在不同场景下,如何进行数据源的动态切换和管理,以及如何优化多数据源环境下的性能和稳定性。这些知识不仅适用于新项目的架构设计,也能帮助现有项目的平滑迁移与升级。
# 2. Spring Boot与MyBatis集成
Spring Boot的出现极大地简化了基于Spring的应用程序的开发和部署过程。与此同时,MyBatis作为一款优秀的持久层框架,因其灵活的SQL编写能力、良好的可定制性以及与Spring的无缝集成而广泛受到开发者的青睐。在这一章节中,我们将深入了解如何将Spring Boot与MyBatis结合,以及在整合过程中涉及的关键概念和配置。
## 2.1 MyBatis基础知识
### 2.1.1 MyBatis的原理和架构
MyBatis是一个半自动的ORM(对象关系映射)框架,它通过XML或注解的方式将对象与数据库中的表相互映射,使得Java程序员可以使用面向对象的方式来操作数据库。MyBatis通过使用内置的SQL解释器将SQL语句和参数映射到结果集上,简化了数据库操作代码。
MyBatis的架构可以分为以下几个核心组件:
- **SqlSessionFactoryBuilder**:用于创建SqlSessionFactory。它会根据提供的XML配置或配置类构建SqlSessionFactory实例。
- **SqlSessionFactory**:是创建SqlSession的工厂,一个SqlSessionFactory实例可以创建多个SqlSession实例。它通常是单例的。
- **SqlSession**:是一个执行持久化操作的独占会话,你可以通过它来执行SQL命令、获取映射器,并将事务提交或回滚。
- **Mapper**:映射器是一个接口,它的方法会被MyBatis用来执行数据库操作。它通过注解或XML文件定义SQL语句。
### 2.1.2 MyBatis的核心组件
MyBatis的核心组件不仅包括上述的会话工厂和会话,还包括以下几个方面:
- **Executor**:MyBatis中的执行器负责SQL语句的生成和查询缓存的维护。
- **StatementHandler**:处理SQL语句的准备和执行。
- **ParameterHandler**:处理SQL语句的参数的设置。
- **ResultSetHandler**:处理SQL查询结果的封装。
- **TypeHandler**:负责Java类型和JDBC类型之间的映射和转换。
- **插件**:MyBatis允许开发者通过插件来拦截方法调用并进行自定义的行为。
## 2.2 MyBatis的配置与使用
### 2.2.1 MyBatis的XML映射文件
MyBatis的XML映射文件是定义SQL语句和如何映射结果集的主要方式。一个映射文件通常包含以下元素:
- `<insert>`、`<update>`、`<delete>`、`<select>`:分别对应SQL的增删改查操作。
- `<parameterMap>`:用于定义输入参数的映射规则。
- `<resultMap>`:用于定义结果集与Java对象属性之间的映射关系。
- `<sql>`:定义可重用的SQL片段。
下面是一个简单的`<select>`语句的映射示例:
```xml
<select id="selectUser" parameterType="int" resultType="User">
SELECT * FROM users WHERE id = #{id}
</select>
```
### 2.2.2 注解与接口绑定
除了XML映射文件,MyBatis也支持使用注解来简化配置。开发者可以直接在Mapper接口的方法上使用注解来指定SQL语句。
```java
public interface UserMapper {
@Select("SELECT * FROM users WHERE id = #{id}")
User selectUser(int id);
}
```
虽然使用注解可以减少XML文件的编写,但XML映射提供了更高的灵活性和可维护性,特别是对于复杂的SQL操作。因此,在实际开发中,可以根据具体情况选择使用注解或者XML映射文件。
## 2.3 MyBatis与Spring Boot整合
### 2.3.1 在Spring Boot中配置MyBatis
Spring Boot与MyBatis的整合相对简单。首先需要在`pom.xml`中添加相关依赖:
```xml
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
```
接下来,配置MyBatis的属性。在`application.properties`或`application.yml`中添加数据源和MyBatis配置:
```properties
# application.properties
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.example.demo.model
spring.datasource.url=jdbc:mysql://localhost:3306/demo?useSSL=false&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
```
### 2.3.2 实现Mapper接口的自动扫描
为了实现Mapper接口的自动扫描,需要在配置类中添加`@MapperScan`注解,指定Mapper接口所在的包路径:
```java
@SpringBootApplication
@MapperScan("com.example.demo.mapper")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
```
通过这样的配置,Spring Boot会自动创建Mapper接口的代理对象,并将其作为Bean注入到Spring容器中。这样就可以在业务层直接注入Mapper接口,实现数据库操作。
以上章节介绍了Spring Boot与MyBatis的集成过程,包括MyBatis的基础知识、配置、以及如何在Spring Boot中进行配置。接下来,我们将会探索Druid连接池的集成及其优化策略,为多数据源管理的深入讨论打下坚实的基础。
# 3. ```markdown
# 第三章:Druid数据库连接池详解
## 3.1 Druid连接池的特性与优势
### 3.1.1 Druid的性能优势
Druid数据库连接池是阿里巴巴开源的一个高质量的数据库连接池,它具有高效的性能和众多扩展特性。其性能优势主要体现在以下几个方面:
- **高并发处理能力**:Druid是目前Java领域中,性能最好的数据库连接池之一,可以轻松应对高并发的场景。
- **资源回收机制**:Druid提供了强大的监控能力和多种资源回收机制,有效防止了内存泄漏等问题。
- **SQL监控**:Druid提供SQL执行日志记录和慢SQL记录,方便开发者监控和分析数据库操作的性能瓶颈。
### 3.1.2 监控与扩展特性
监控和扩展是Druid连接池的另一大特色:
- **内置监控页面**:Druid提供了一个内置的监控页面,可以实时查看数据库连接池的工作状态,包括连接数、SQL监控、系统环境信息等。
- **SQL执行日志**:可以配置开启SQL执行日志,捕获执行时间超过指定阈值的SQL语句。
- **扩展的统计信息**:提供了详细的性能统计信息,如SQL执行时间分布、数据库连接使用情况等。
## 3.2 Druid的配置与优化
### 3.2.1 配置文件详解
在Spring Boot中配置Druid连接池,通常需要在`application.properties`或`application.yml`中进行相关设置。下面是一些常用的配置项:
```properties
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
spring.datasource.username=root
spring.datasource.password=pass
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# 最小空闲连接数
spring.datasource.druid.min-idle=5
# 初始化连接数
spring.datasource.druid.initial-size=10
# 最大连接数
spring.datasource.druid.max-active=20
# 获取连接等待超时时间
spring.datasource.druid.max-wait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.druid.time-between-eviction-runs-millis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.druid.min-evictable-idle-time-millis=300000
```
### 3.2.2 性能调优实战
进行性能调优之前,需要先了解业务场景和数据库的特性。以下是一些常见的调优策略:
1. **合理配置连接池参数**:根据实际应用的负载情况调整连接池的各项参数,如连接数、等待时间等。
2. **SQL优化**:监控慢SQL并进行优化,避免出现长耗时的查询操作。
3. **JVM调优**:确保JVM参数配置合理,避免频繁的Full GC影响数据库连接池的性能。
## 3.3 Spring Boot整合Druid
### 3.3.1 在Spring Boot中集成Druid
在Spring Boot项目中集成Druid非常简单,只需要引入Druid的依赖并在配置文件中进行简单的配置即可。具体操作如下:
1. 添加Druid依赖到项目中:
```xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>最新版本</version>
</dependency>
```
2. 配置Druid数据源:
```properties
# application.properties
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8
spring.datasource.druid.username=root
spring.datasource.druid.password=pass
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
```
### 3.3.2 数据源的自定义与动态配置
在一些复杂的业务场景中,可能需要动态配置数据源,比如在运行时根据不同的业务逻辑切换到不同的数据源。通过Druid提供的API,可以实现数据源的动态管理和切换。
1. **自定义数据源**:通过实现`DataSource`接口或继承`AbstractDataSource`类,可以创建自定义的数据源。
2. **动态数据源切换**:结合AOP和ThreadLocal,可以在方法执行前后切换不同的数据源,实现动态数据源切换。
下面是一个简单的动态数据源切换示例:
```java
@Configuration
public class DynamicDataSourceConfig {
@Bean
public DataSource dataSource() {
DruidDataSource primaryDataSource = new DruidDataSource();
primaryDataSource.setUrl("jdbc:mysql://localhost:3306/primary_db");
primaryDataSource.setUsername("primary");
primaryDataSource.setPassword("primary");
// ... 其他配置 ...
DruidDataSource secondaryDataSource = new DruidDataSource();
secondaryDataSource.setUrl("jdbc:mysql://localhost:3306/secondary_db");
secondaryDataSource.setUsername("secondary");
secondaryDataSource.setPassword("secondary");
// ... 其他配置 ...
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.PRIMARY, primaryDataSource);
targetDataSources.put(DataSourceEnum.SECONDARY, secondaryDataSource);
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(primaryDataSource);
return dynamicDataSource;
}
}
```
在上述配置中,`DynamicDataSource`是一个自定义的类,继承了Spring的`AbstractRoutingDataSource`,通过实现`determineCurrentLookupKey`方法来决定当前线程使用哪个数据源。
通过以上配置,可以在业务代码中通过ThreadLocal来切换数据源,以支持复杂的业务逻辑和事务管理。这样,就可以根据不同的业务需求灵活地切换到对应的数据库连接,达到动态配置数据源的目的。
经过本章的介绍,我们了解了Druid连接池的性能优势、监控与扩展特性,以及在Spring Boot中的配置与优化方法。接下来,我们将深入探讨如何在多数据源环境下进行配置和管理,包括动态切换策略和事务管理等高级技术。
```
# 4. 多数据源配置与管理
## 4.1 多数据源环境的搭建
在开发复杂的企业级应用时,经常会遇到需要连接多个数据库的情况。例如,将用户信息存储在专门的用户数据库中,而将商品信息存储在商品数据库中。这种架构可以提高数据的安全性、灵活性以及可维护性。
### 4.1.1 应用场景与需求分析
在多数据源的应用场景下,常见的需求包括但不限于:
- **业务分离**:不同业务线的数据应该隔离,这样可以提高系统的安全性,降低业务间的耦合度。
- **读写分离**:主从复制架构下,读写操作可以在不同的服务器上进行,提高系统的性能与可用性。
- **分库分表**:为了提高数据库的扩展性和处理能力,将一个大表拆分成多个小表,分布在不同的数据库中。
对于这些需求,合理配置和管理多数据源就显得至关重要。我们需要能够根据不同的业务场景灵活切换数据源,并且保持数据的一致性和事务性。
### 4.1.2 多数据源配置文件的编写
在Spring Boot应用中,可以通过配置文件来设置多数据源。例如,在`application.yml`或`application.properties`文件中添加配置:
```yaml
spring:
datasource:
master:
url: jdbc:mysql://localhost:3306/master_db
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
slave:
url: jdbc:mysql://localhost:3306/slave_db
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
```
以上配置定义了两个数据源:`master`和`slave`。`master`可以配置为主数据库,用于处理写操作;`slave`配置为从数据库,用于读操作。需要注意的是,为了保证数据一致性,复杂的读写分离逻辑需要通过数据访问层或者事务管理器来实现。
## 4.2 多数据源的动态切换与管理
在多数据源的场景中,动态切换数据源是一项关键技术。它需要根据不同的业务需求和上下文环境,动态选择合适的数据源。
### 4.2.1 动态数据源切换策略
动态数据源切换主要通过实现`AbstractRoutingDataSource`类来完成。这个类是Spring提供的抽象数据源路由类,允许我们根据线程上下文来选择数据源。
以下是一个简单的动态数据源切换策略实现的代码示例:
```java
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import org.springframework.transaction.support.TransactionSynchronizationManager;
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// 从ThreadLocal中获取数据源标识
return DataSourceContextHolder.getDataSourceType();
}
}
```
其中`DataSourceContextHolder`是一个工具类,用于存储和获取当前线程使用的数据源类型。
```java
public class DataSourceContextHolder {
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setDataSourceType(String dataSourceType) {
contextHolder.set(dataSourceType);
}
public static String getDataSourceType() {
return contextHolder.get();
}
public static void clearDataSourceType() {
contextHolder.remove();
}
}
```
### 4.2.2 事务管理与一致性控制
事务管理是保证数据一致性的重要手段,在多数据源环境下,需要格外注意事务的传播机制。Spring框架提供了声明式事务管理,可以借助`@Transactional`注解来简化事务的配置。
在使用事务管理时,要特别关注事务的传播行为(`propagation`属性)。例如,在执行跨越多个数据源的业务逻辑时,可能需要配置为`Propagation.REQUIRES_NEW`来确保每个数据源的事务独立。
```java
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void executeMultiDataSourceTransaction() {
// 业务逻辑,可能会操作多个数据源
}
```
此外,可以通过实现`PlatformTransactionManager`来支持多数据源事务的高级配置。
## 4.3 多数据源实战演练
通过理论知识的学习,现在我们来通过一个实战演练来巩固这些概念。
### 4.3.1 实战项目结构与关键代码
一个典型的多数据源项目结构可能包括以下模块:
```
src/
├── main/
│ ├── java/
│ │ ├── com/
│ │ │ ├── yourcompany/
│ │ │ │ ├── config/
│ │ │ │ │ ├── DataSourceConfig.java
│ │ │ │ ├── service/
│ │ │ │ │ ├── UserService.java
│ │ │ │ ├── repository/
│ │ │ │ │ ├── UserRepository.java
│ │ │ │ ├── controller/
│ │ │ │ │ ├── UserController.java
│ │ │ │ ├── MyApplication.java
│ └── resources/
│ ├── application.yml
```
在`DataSourceConfig.java`中配置多数据源和动态数据源:
```java
@Configuration
public class DataSourceConfig {
@Primary
@Bean(name = "masterDataSource")
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "slaveDataSource")
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public DataSource dynamicDataSource() {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceContextHolder.MASTER, masterDataSource());
targetDataSources.put(DataSourceContextHolder.SLAVE, slaveDataSource());
DynamicDataSource dataSource = new DynamicDataSource();
dataSource.setTargetDataSources(targetDataSources);
dataSource.setDefaultTargetDataSource(masterDataSource());
return dataSource;
}
@Bean
public PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dynamicDataSource());
}
}
```
### 4.3.2 遇到的问题与解决方案
在实际的多数据源应用中,可能遇到一些棘手的问题,比如:
- **事务的一致性问题**:由于操作了多个数据源,保证事务的一致性变得困难。解决这个问题可以通过使用分布式事务管理器(如Atomikos),或者采用补偿性事务(Saga模式)。
- **数据源的线程安全问题**:在多线程环境下,数据源的切换可能会受到干扰。解决办法是在每次请求开始时设置数据源,并在请求结束后清除数据源。
在处理多数据源时,需要不断地通过实践来优化配置,解决遇到的问题,提高应用的稳定性和性能。
# 5. 高级应用与最佳实践
## 5.1 多数据源架构的设计考量
在构建复杂的企业级应用时,如何设计和管理多个数据源是一个重要议题。这通常涉及到分库分表以及高可用架构的设计。
### 5.1.1 分库分表的策略
在多个数据源的场景下,分库分表是提高系统性能和扩展性的常见策略。这里介绍垂直分库和水平分表的概念。
- **垂直分库**:即将不同业务的数据表拆分到不同的数据库中。这样可以减少不同业务间的数据竞争,提高数据库的性能。
**垂直分库的策略举例**:
```plaintext
应用模块:
- 用户模块 -> 用户数据库
- 订单模块 -> 订单数据库
- 商品模块 -> 商品数据库
每个模块只关心自己的数据表,避免单库负载过大。
```
- **水平分表**:即将同一数据表根据某个字段的值分散存储到多个表中。这有助于解决单表数据量过大的问题,提升查询效率。
**水平分表的策略举例**:
```plaintext
对于订单表,可以根据订单ID的哈希值将数据分散存储到不同的表中。
表名格式:
- 订单表_00
- 订单表_01
- ...
- 订单表_xx
这样的设计能够提高单表的读写性能,并实现数据的均衡分配。
```
### 5.1.2 高可用架构的设计
在设计高可用的多数据源架构时,我们需要考虑到如何保证服务的连续性,以及在发生故障时如何快速恢复。
- **主从复制**:通过配置主从数据库可以实现数据的热备份,提高数据的安全性。
- **读写分离**:将读操作和写操作分别由不同的数据源处理,可以有效地分担负载,提高系统的整体性能。
- **故障转移与负载均衡**:在主数据库出现故障时,能够快速切换到备用数据库,并且通过负载均衡机制,合理分配读写请求。
## 5.2 代码质量与维护性提升
在IT行业中,代码的可维护性和质量直接影响项目的长期发展。因此,采取相应措施提升代码质量与维护性是至关重要的。
### 5.2.1 代码重构与规范
代码重构是提升代码质量的常用方法,遵循良好的编码规范是保证项目可持续发展的基础。
- **重构目标**:
- 提高代码的可读性
- 减少代码的复杂度
- 消除重复代码
- **编码规范**:
- 命名规范:变量、函数、类等的命名应清晰、具有描述性。
- 格式规范:统一代码缩进、空格、括号等格式问题。
- 注释规范:重要的逻辑和复杂的方法应有清晰的注释。
### 5.2.2 使用AOP提升代码质量
面向切面编程(AOP)是一种在不修改源代码的情况下,对程序的行为进行增强的技术。
- **AOP的使用场景**:
- 日志记录:自动记录方法调用日志,方便问题追踪和性能监控。
- 事务处理:统一管理事务,简化业务代码。
- 权限控制:集中处理权限验证,使业务代码更清晰。
**示例代码块**:
```java
@Aspect
@Component
public class MyLogAspect {
@Autowired
private LogService logService;
@Pointcut("execution(* com.example.service..*.*(..))")
public void serviceLayer() {}
@AfterReturning(value = "serviceLayer()", returning = "result")
public void logAfterReturning(JoinPoint joinPoint, Object result) {
// 记录日志逻辑...
logService.saveLog(joinPoint, result);
}
}
```
## 5.3 实战项目案例分析
通过对实际项目的案例分析,我们可以了解到多数据源架构在实践中的应用和优化。
### 5.3.1 项目架构的演变
项目初期可能只有一个简单的数据源,随着业务的不断扩展,可能逐步引入多个数据源,以支持不同的业务需求。
- **项目初期**:单数据源,所有业务共用一个数据库。
- **发展中期**:引入多数据源,根据业务模块划分不同的数据源。
- **成熟期**:高可用多数据源架构,包含主从复制、读写分离、故障转移等策略。
### 5.3.2 优化经验分享与未来展望
在项目的发展过程中,不断总结和分享优化经验是提高开发效率和系统性能的关键。
- **优化经验**:
- 利用缓存减少数据库访问次数。
- 定期进行SQL性能分析和优化。
- 数据库定期维护,包括索引优化、数据清理等。
- **未来展望**:
- 云原生数据库服务的引入。
- 大数据处理和分析技术的集成。
- 人工智能技术在数据管理中的应用。
以上为第五章的内容,每一节都详细介绍了在实际项目中可能遇到的场景,并提供了相应的优化策略和实践经验,以帮助读者理解多数据源架构的设计考量、代码质量与维护性提升,以及实战项目案例分析。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Spring Boot 动态数据源配置的各个方面,涵盖了 MyBatis 和 Druid 的高级配置技巧。从源与漏极注入机制到性能优化和退火过程,专栏提供了全面的指南,帮助读者掌握 Spring Boot 动态数据源的方方面面。此外,专栏还提供了实战案例、源码解析、挑战与应对措施,以及生产环境应用教程,为读者提供全面的知识和实践经验。通过深入剖析 Spring Boot、MyBatis 和 Druid 的协同工作原理,本专栏旨在帮助读者构建高效、可扩展和可靠的动态数据源解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
理解SN29500-2010:IT专业人员的标准入门手册

# 摘要
SN29500-2010标准作为行业规范,对其核心内容和历史背景进行了概述,同时解析了关键条款,如术语定义、管理体系要求及信息安全技术要求等。本文还探讨了如何在实际工作中应用该标准,包括推广策略、员工培训、监督合规性检查,以及应对标准变化和更新的策略。文章进一步分析了SN29500-2010带来的机遇和挑战,如竞争优势、技术与资源
红外遥控编码:20年经验大佬揭秘家电控制秘籍
# 摘要
红外遥控技术作为无线通信的重要组成部分,在家电控制领域占有重要地位。本文从红外遥控技术概述开始,详细探讨了红外编码的基础理论,包括红外通信的原理、信号编码方式、信号捕获与解码。接着,本文深入分析了红外编码器与解码器的硬件实现,以及在实际编程实践中的应用。最后,本文针对红外遥控在家电控制中的应用进行了案例研究,并展望了红外遥控技术的未来趋势与创新方向,特别是在智能家居集成和技术创新方面。文章旨在为读者提
【信号完整性必备】:7系列FPGA SelectIO资源实战与故障排除
# 摘要
随着数字电路设计复杂度的提升,FPGA(现场可编程门阵列)已成为实现高速信号处理和接口扩展的重要平台。本文对7系列FPGA的SelectIO资源进行了深入探讨,涵盖了其架构、特性、配置方法以及在实际应用中的表现。通过对SelectIO资源的硬件组成、电气标准和参数配置的分析,本文揭示了其在高速信号传输和接口扩展中的关键作用。同时,本文还讨论了信号完整性
C# AES加密:向量化优化与性能提升指南
# 摘要
本文深入探讨了C#中的AES加密技术,从基础概念到实现细节,再到性能挑战及优化技术。首先,概述了AES加密的原理和数学基础,包括其工作模式和关键的加密步骤。接着,分析了性能评估的标准、工具,以及常见的性能瓶颈,着重讨论了向量化优化技术及其在AES加密中的应用。此外,本文提供了一份实践指南,包括选择合适的加密库、性能优化案例以及在安全性与性能之间寻找平衡点的策略。最后,展望了AES加密技术的未来趋势,包括新兴加密算法的演进和性能优化的新思路。本研究为C#开发者在实现高效且安全的AES加密提供了理论基础和实践指导。
# 关键字
C#;AES加密;对称加密;性能优化;向量化;SIMD指令
RESTful API设计深度解析:Web后台开发的最佳实践

# 摘要
本文全面探讨了RESTful API的设计原则、实践方法、安全机制以及测试与监控策略。首先,介绍了RESTful API设计的基础知识,阐述了核心原则、资源表述、无状态通信和媒体类型的选择。其次,通过资源路径设计、HTTP方法映射到CRUD操作以及状态码的应用,分析了RESTful API设计的具体实践。
【Buck电路布局绝招】:PCB设计的黄金法则
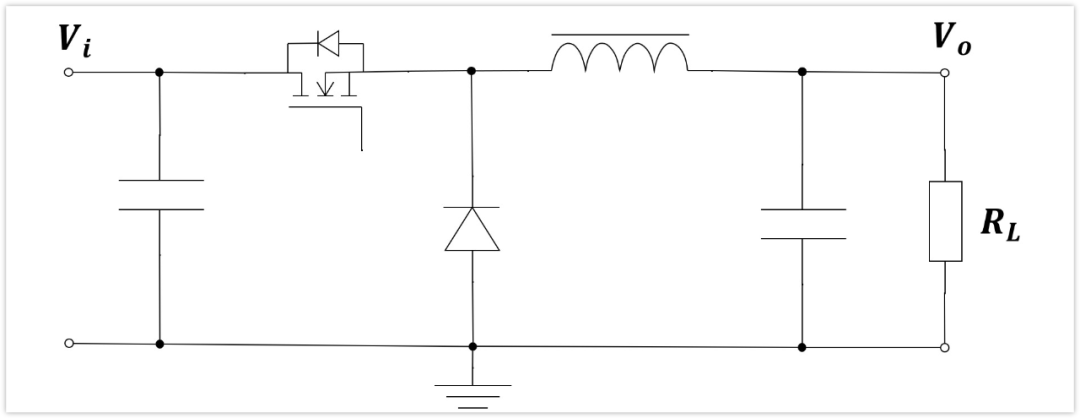
# 摘要
Buck转换器是一种广泛应用于电源管理领域的直流-直流转换器,它以高效和低成本著称。本文首先阐述了Buck转换器的工作原理和优势,然后详细分析了Buck电路布局的理论基础,包括关键参数、性能指标、元件选择、电源平面设计等。在实践技巧方面,本文提供了一系列提高电路布局效率和准确性的方法,并通过案例分析展示了低噪声、高效率以及小体积高功率密度设计的实现。最后,本文展望了Buck电
揭秘苹果iap2协议:高效集成与应用的终极指南
# 摘要
本文系统介绍了IAP2协议的基础知识、集成流程以及在iOS平台上的具体实现。首先,阐述了IAP2协议的核心概念和环境配置要点,包括安装、配置以及与iOS系统的兼容性问题。然后,详细解读了IAP2协议的核心功能,如数据交换模式和认证授权机制,并通过实例演示了其在iOS应用开发和数据分析中的应用技巧。此外,文章还探讨了IAP2协议在安全、云计算等高级领域的应用原理和案例,以及性能优化的方法和未来发展的方向。最后,通过大
ATP仿真案例分析:故障相电压波形A的调试、优化与实战应用
# 摘要
本文对ATP仿真软件及其在故障相电压波形A模拟中的应用进行了全面介绍。首先概述了ATP仿真软件的发展背景与故障相电压波形A的理论基础。接着,详细解析了模拟流程,包括参数设定、步骤解析及结果分析方法。本文还深入探讨了调试技巧,包括ATP仿真环境配置和常见问题的解决策略。在此基础上,提出了优化策略,强调参数优化方法和提升模拟结果精确性的重要性。最后,通过电力系统的实战应用案例,本文展示了故障分析、预防与控制策略的实际效果,并通过案例研究提炼出有价值的经验与建议。
# 关键字
ATP仿真软件;故障相电压波形;模拟流程;参数优化;故障预防;案例研究
参考资源链接:[ATP-EMTP电磁暂
【流式架构全面解析】:掌握Kafka从原理到实践的15个关键点

# 摘要
流式架构作为处理大数据的关键技术之一,近年来受到了广泛关注。本文首先介绍了流式架构的概念,并深入解析了Apache Kafka作为流式架构核心组件的引入背景和基础知识。文章深入探讨了Kafka的架构原理、消息模型、集群管理和高级特性,以及其在实践中的应用案例,包括高可用集群的实现和与大数据生态以及微
【SIM卡故障速查速修秘籍】:10分钟内解决无法识别问题

# 摘要
本文旨在为读者提供一份全面的SIM卡故障速查速修指导。首先介绍了SIM卡的工作原理及其故障类型,然后详细阐述了故障诊断的基本步骤和实践技巧,包括使用软件工具和硬件检查方法。本文还探讨了常规和高级修复策略,以及预防措施和维护建议,以减少SIM卡故障的发生。通过案例分析,文章详细说明了典型故障的解决过程。最后,展望了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )