【框架适应性】:YOLOv8跨框架输入输出适配,一步到位
发布时间: 2024-12-12 00:25:53 阅读量: 10 订阅数: 14 

yolov8 华为昇腾适配
# 1. YOLOv8与框架适应性的概述
YOLOv8作为一个在计算机视觉领域备受关注的目标检测模型,其与不同框架的适应性是理解和实现高效部署的基础。YOLOv8不仅保持了实时检测的优势,还在模型结构、计算效率和精度上进行了创新性的优化,以适应多样化的应用需求。框架适应性指模型能够在不同的机器学习框架上运行,如PyTorch、TensorFlow等,而无需进行大量的修改。本章节将从宏观角度概述YOLOv8的核心特性、应用场景以及框架适应性的意义。随后的章节将深入探讨YOLOv8的架构细节、关键技术、适配策略及其面临的挑战与未来的发展方向。通过理解这些内容,开发者和研究人员可以更好地掌握如何将YOLOv8模型有效融入到各种项目中去。
# 2. YOLOv8架构与关键技术
在计算机视觉领域,YOLO(You Only Look Once)系列因其速度快且准确率高而被广泛应用于实时物体检测任务中。YOLOv8作为该系列的最新成员,在继承前辈优点的同时,也引入了新的架构和创新技术。本章节将深入解析YOLOv8的模型架构、关键技术,以及它们是如何提升模型性能和效率的。
## 2.1 YOLOv8的模型架构
YOLOv8的模型架构是其核心,它承载了整个模型的运算逻辑和效率优化。模型架构的设计直接影响到模型的检测精度和速度。
### 2.1.1 网络结构的发展和演进
自YOLOv1问世以来,YOLO系列模型经历了多次迭代更新,每个新版本都在网络结构上做出了改进。YOLOv8也不例外,它在先前版本的基础上,对网络结构进行了以下几方面的演进:
1. **Backbone的改进**:YOLOv8引入了更为高效和轻量级的网络结构,以获得更快的推理速度和更低的计算复杂度。这一点在移动设备和嵌入式系统中尤为重要。
2. **Neck的设计创新**:Neck是连接Backbone和Head的重要部分,YOLOv8在该部分增加了多尺度特征融合模块,从而提高了模型在不同尺度目标检测上的性能。
3. **Head的精细化调整**:YOLOv8优化了预测头的设计,通过更为精细的输出层结构,使得模型能够更好地学习目标的位置和类别信息。
通过这些改进,YOLOv8在保持高准确率的同时,显著提升了处理速度。
### 2.1.2 关键层的功能和优化
YOLOv8中不仅包含了传统YOLO系列的卷积层、池化层等,还特别加入了如下关键层,它们的功能及优化如下:
1. **Darknet-53**:作为YOLOv3的 Backbone,Darknet-53在YOLOv8中得到保留和进一步优化,通过引入深度可分离卷积(Depthwise Separable Convolution),大幅降低计算量。
2. **残差连接(Residual Connection)**:在特征提取网络中使用残差连接,能够提升模型的训练效率,避免梯度消失问题。
3. **多尺度预测(Multi-Scale Prediction)**:YOLOv8实现了在网络的不同层次上进行目标检测,可以在不同尺度上预测目标,这显著提升了模型对小目标的检测能力。
通过这些关键层的功能优化,YOLOv8在网络结构上实现了更好的平衡,既保证了模型的高准确率,也确保了快速的处理速度。
## 2.2 YOLOv8中的创新技术
YOLOv8的创新技术不仅体现在模型架构上,更在于其在检测技术上所做出的突破。接下来,我们将探讨YOLOv8引入的领先检测技术,以及它是如何平衡检测的精确性与速度的。
### 2.2.1 领先的检测技术分析
YOLOv8采用了以下领先技术来提升检测性能:
1. **自适应锚框(Adaptive Anchor Box)**:YOLOv8通过对训练数据集进行分析,自适应地生成最合适的锚框,从而使得模型对目标的定位更加准确。
2. **注意力机制(Attention Mechanism)**:YOLOv8中加入了注意力模块,可以帮助模型聚焦于图像中更加重要的区域,从而提高检测的准确率。
3. **训练技巧的创新**:YOLOv8使用了诸如路径聚合网络(Path Aggregation Network, PANet)等先进的训练技巧来提升特征的聚合能力,这使得模型能够更好地理解复杂场景。
通过上述技术的综合应用,YOLOv8在保持高效推理的同时,进一步提升了检测的准确性。
### 2.2.2 精确性与速度的平衡策略
YOLOv8在速度和准确性之间找到了一个巧妙的平衡点,其策略如下:
1. **精度优化与速度权衡**:YOLOv8在保持较低计算复杂度的基础上,通过调整网络结构,使得模型可以在不显著增加计算量的情况下提高检测精度。
2. **模型压缩和量化**:为了进一步提升速度,YOLOv8实施了模型压缩和量化技术,这既减少了模型大小,也加快了运算速度,而牺牲的准确性则在可接受的范围内。
3. **动态计算**:YOLOv8通过动态计算技术,在不同的检测阶段可以适配不同的计算量,确保在关键阶段可以输出更精确的结果,而在非关键阶段则保持高速运行。
YOLOv8通过这些平衡策略,为用户提供了灵活的选择,既可以满足对实时性有极高要求的应用场景,也可以在必要时提供更高的检测准确率。
在本章节中,我们首先从YOLOv8的模型架构入手,分析其网络结构的演进和关键层的优化。然后我们深入探讨了YOLOv8中引入的创新检测技术和精确性与速度的平衡策略。这些技术和策略的融合使用,使得YOLOv8在保持高效性能的同时,也达到了较高的检测准确性。在后续章节中,我们将继续探索YOLOv8在跨框架适配策略上的细节,以及它如何在实际应用中发挥最大效能。
# 3. ```
# 第三章:YOLOv8的跨框架输入适配策略
## 3.1 输入数据的预处理方法
### 3.1.1 图像格式和尺寸的转换
在深度学习模型中,处理不同类型和尺寸的图像数据是一项基础且重要的任务。YOLOv8模型在训练和推理过程中要求输入图像具备特定的格式和尺寸,这是因为模型的卷积层和池化层需要统一规格的张量。图像是由像素构成的二维矩阵,而卷积神经网络(CNN)需要的是固定大小的多维数据。因此,在跨框架适配策略中,首先需要确保输入图像数据符合模型的输入要求。
数据预处理的步骤通常包括读取原始图像,将其转换为特定格式(例如RGB格式),并调整图像尺寸以匹配网络的输入层。例如,YOLOv8可能要求输入图像的尺寸为640x640像素。图像尺寸的调整需要考虑到缩放算法的选择,常见的算法包括最近邻(nearest-neighbor)、双线性(bilinear)插值和双三次(bicubic)插值等。
下面的伪代码展示了图像尺寸转换的基本逻辑:
```python
def resize_image(image, new_size):
"""
Resize the input image to the new_size.
:param image: The input image (numpy array).
:param new_size: A tuple of (new_height, new_width) for the resized image.
:return: The resized image.
"""
# 选择适当的插值方法
interpolation_method = cv2.INTER_AREA # 或者 cv2.INTER_LINEAR, cv2.INTER_CUBIC
# 使用OpenCV库进行图像尺寸调整
resized_image = cv2.resize(image, new_size, interpolation=interpolation_method)
return resized_image
```
在这段代码中,我们使用了`cv2.resize`方法,这是OpenCV库中的函数,用来调整图像尺寸。`interpolation_method`参数指定了用于重新采样时所用的插值方法。在进行图像尺寸调整时,选择不同的插值方法会直接影响到图像的输出质量和速度。
### 3.1.2 数据增强和归一化的应用
数据增强和归一化是提高模型泛化能力的重要手段。数据增强通过对原始数据应用一系列变换来生成新的训练样本,以增加数据多样性。常见的数据增强技术包括水平或垂直翻转、旋转、缩放、裁剪、色彩抖动等。例如,通过随机裁剪图像的一部分来模拟目标物体在图像中的不同位置,或者通过色彩抖动来模拟不同光照条件下的图像。
归一化是将数据按比例缩放,使之落入一个小的特定区间。对于图像数据而言,常见的归一化方法是将像素值归一化到[0,1]或[-1,1]区间。归一化有助于稳定模型训练过程中的数值稳定性,提高收敛速度。
下面的伪代码展示了数据归一化的基本逻辑:
```python
def normalize_image(i

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《YOLOv8输入输出格式说明》专栏全面解析了YOLOv8的输入输出格式,并提供了12个技巧提升输入输出效率和性能优化。专栏涵盖了数据预处理、实时物体检测和性能优化等方面,为读者提供了全面的YOLOv8使用指南。通过优化输入准确性、提升输出效率,用户可以显著提升YOLOv8的检测性能和整体效率。专栏内容深入浅出,案例实操丰富,是YOLOv8使用者提升模型性能的必备参考。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RTCM 3.3协议的10大秘密】:精通实时定位技术的终极指南

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议概述
RTCM 3.3是实时差分全球定位系统(GNSS
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
升级你的IS903:固件更新全攻略,提升性能与稳定性的终极指南

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. IS903固件更新的必要性和好处
## 理解固件更新的重要性
固件更新,对于任何智能设备来说,都是一个关键的维护步骤。IS903作为一款高性能的设备,其固件更新不仅仅是为了修
ROST软件高级用户必看:全面掌握工具每一个细节的独家技巧
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
# 1. ROST软件概述与安装指南
## ROST
【cx_Oracle权威指南】:版本升级、环境配置与最佳实践案例解析

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle简介与历史回顾
cx_Oracle 是一个流行的 Python 扩展,用于访问 Oracle 数据库。它提供了一个接口,允许 Python 程序
ZMODEM vs XMODEM vs YMODEM:三者的优劣比较分析及选型建议

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM、XMODEM与YMODEM协议概述
在现代数据通
ARINC664协议的可靠性与安全性:详细案例分析与实战应用

参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. ARINC664协议概述
ARINC664协议,作为一种在航空电子系统中广泛应用的数据通信标准,已经成为现代飞机通信网络的核心技术之一。它不仅确保了
HEC-GeoHMS在洪水风险评估中的应用实战:案例分析与操作技巧

参考资源链接:[HEC-GeoHMS操作详析:ArcGIS准备至流域处理全流程](https://wenku.csdn.net/doc/4o9gso36xa?spm=1055.2635.3001.10343)
# 1. HEC-GeoHMS概述与洪水风险评估基础
## 1.1 HEC-GeoHMS简介
HEC-GeoHMS是一个强大的GIS工具,用于洪水风险评估和洪水模型的前期准备工作。它是HEC-HMS(Hydro
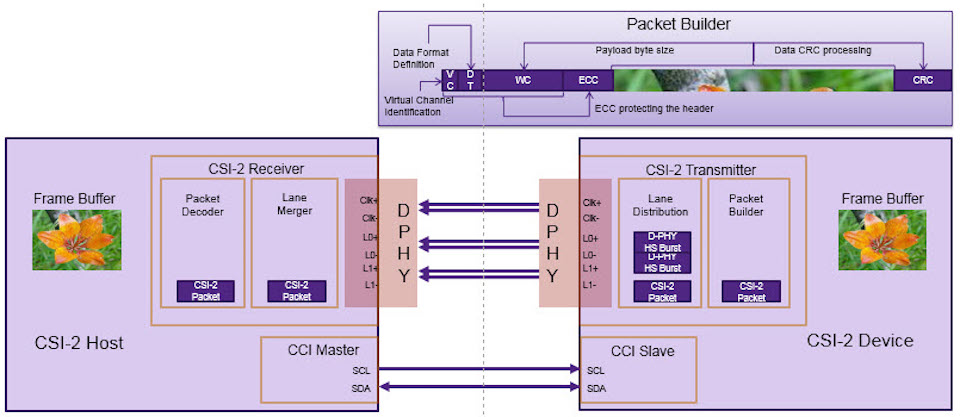
MIPI CSI-2信号传输精髓:时序图分析专家指南
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2信号传输基础
MIPI CSI-2 (Mobile Industry Processor
【系统维护】创维E900 4K机顶盒:更新备份全攻略,保持最佳状态

参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
## 简介
创维E900 4K机顶盒是一款集成了最新技术的家用多媒体设备,支持4K超高清视频播放和多
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )