【YOLOv8终极指南】:12个技巧提升输入输出效率及性能优化
发布时间: 2024-12-11 23:26:59 阅读量: 20 订阅数: 14 

YOLOv8模型优化:量化与剪枝的实战指南

# 1. YOLOv8简介及性能概述
## 1.1 YOLOv8的诞生背景
YOLOv8(You Only Look Once version 8)是在YOLO系列快速发展的背景下诞生的最新版本。YOLO作为一种端到端的实时对象检测系统,因其出色的检测速度和准确性受到广泛的关注。YOLOv8在前几代的基础上进一步优化了模型架构,引入了新的训练技巧和数据增强技术,从而在保持高速度的同时,提高了检测的准确度和鲁棒性。
## 1.2 YOLOv8的主要特性
YOLOv8引入了诸如多尺度检测、注意力机制以及改进的后处理流程等关键技术,显著提升了小目标检测的能力和整体性能。这些技术的融合使得YOLOv8能够在复杂环境中对各种尺寸的对象进行有效识别。值得一提的是,YOLOv8还优化了模型的推理速度,使其在边缘设备上部署变得更加高效。
## 1.3 YOLOv8的性能评估
在性能方面,YOLOv8对比前几代版本有显著提升。根据官方发布的测试数据,在多个标准数据集上的评估显示,YOLOv8不仅在速度上保持了极高的实时性,而且在准确率(如mAP)等指标上也达到了当前业界领先水平。这些综合性能的提高,使得YOLOv8成为目前计算机视觉任务中十分有竞争力的选择。
# 2. YOLOv8输入输出机制解析
## 2.1 YOLOv8的数据流理论
### 2.1.1 输入数据预处理
YOLOv8模型在处理输入图像之前需要一系列的预处理步骤,确保数据符合模型的输入要求。这些预处理步骤通常包括图像缩放、归一化、数据增强等。图像缩放使得输入图像符合网络的固定尺寸,归一化则将像素值归一化到一个较小的范围(例如0到1),这样有助于网络的稳定收敛。数据增强技术如随机裁剪、水平翻转等则增加了数据的多样性,提高了模型的泛化能力。
在实际应用中,数据预处理的代码示例如下:
```python
import cv2
import numpy as np
def preprocess_image(image_path, target_size):
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # YOLOv8需要RGB格式的图像
image = cv2.resize(image, target_size) # 调整图像大小
image = image / 255.0 # 归一化
return image
# 假定目标大小为640x640
target_size = (640, 640)
image_path = 'path_to_image.jpg'
preprocessed_image = preprocess_image(image_path, target_size)
```
代码逻辑分析:
1. 使用`cv2.imread`读取图像。
2. 通过`cv2.cvtColor`将图像从BGR颜色空间转换为RGB颜色空间。
3. 使用`cv2.resize`将图像尺寸调整至模型输入所需的尺寸。
4. 将图像像素值归一化到0到1的范围内。
### 2.1.2 输出数据后处理
YOLOv8模型输出的数据通常是经过模型推理后的一系列张量,包含了预测的边界框、类别以及置信度等信息。后处理的任务是将这些原始输出转换为人类可理解的检测结果。这包括使用非极大值抑制(NMS)去除重叠的预测框,以及将模型输出的相对坐标转换为图像的实际坐标。
```python
def postprocess_output(outputs, image_shape):
# 假定outputs为模型输出,image_shape为目标图像的尺寸
# 应用NMS来获取最终的检测结果
detections = nms(outputs)
final_detections = []
for detection in detections:
x1, y1, x2, y2, class_score, class_id = detection
# 将相对坐标转换为绝对坐标并添加到最终结果中
x1, y1, x2, y2 = x1 * image_shape[1], y1 * image_shape[0], x2 * image_shape[1], y2 * image_shape[0]
final_detections.append([x1, y1, x2, y2, class_score, class_id])
return final_detections
# NMS函数用于抑制重叠的边界框
def nms(outputs):
# 这里是NMS的简化实现,实际情况中需要使用更复杂的算法
...
```
代码逻辑分析:
1. `nms`函数实现了非极大值抑制算法,用来过滤掉多余的检测框。
2. 对于每个检测到的目标,计算其在原图上的绝对坐标位置。
3. 将处理后的检测结果列表添加到最终的输出列表中。
## 2.2 YOLOv8的数据处理实践
### 2.2.1 数据增强技术
数据增强技术是提高模型鲁棒性的关键步骤之一,通过人为地对输入数据进行变换以扩大数据集。YOLOv8支持多种数据增强技术,如随机裁剪、缩放、翻转、颜色变换等。
```python
import albumentations as A
from albumentations.pytorch import ToTensorV2
def get_augmentation(aug_type):
if aug_type == 'train':
transform = A.Compose(
[
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(brightness_limit=(-0.1, 0.1), contrast_limit=(-0.1, 0.1), p=0.5),
A.CoarseDropout(max_holes=8, max_width=32, max_height=32, p=0.5),
ToTensorV2(),
]
)
else:
transform = A.Compose(
[
ToTensorV2(),
]
)
return transform
# 使用示例
train_aug = get_augmentation('train')
test_aug = get_augmentation('test')
# 假定img为一个PIL图像
augmented_image = train_aug(image=img)['image']
```
代码逻辑分析:
1. 根据`aug_type`选择合适的增强策略。
2. `A.HorizontalFlip`实现水平翻转,概率为50%。
3. `A.RandomBrightnessContrast`调节亮度和对比度。
4. `A.CoarseDropout`实现粗糙的涂黑效果。
5. `ToTensorV2`将图像转换为PyTorch的张量格式。
### 2.2.2 批量处理与效率优化
YOLOv8在处理大量数据时,应采用批量处理来提高效率。批量处理意味着同时处理多个图像样本,这可以充分使用GPU的计算能力,减少模型推理的时间。
```python
import torch
from torch.utils.data import DataLoader, Dataset
class CustomDataset(Dataset):
def __init__(self, image_paths, targets, transforms):
self.image_paths = image_paths
self.targets = targets
self.transforms = transforms
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.targets is not None:
target = self.targets[idx]
else:
target = None
if self.transforms:
augmented = self.transforms(image=image, bboxes=target)
image = augmented['image']
target = augmented['bboxes']
return image, target
# 加载数据集
dataset = CustomDataset(image_paths, targets, transforms=train_aug)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# 在训练循环中使用
for images, targets in dataloader:
# 假定model为YOLOv8模型实例
outputs = model(images)
# 计算损失和反向传播等
...
```
代码逻辑分析:
1. 创建`CustomDataset`类,继承自PyTorch的`Dataset`。
2. 在`__getitem__`中实现对单个图像样本的加载、转换和数据增强。
3. 使用`DataLoader`管理`CustomDataset`,设置适当的批量大小。
4. 在训练循环中,批量处理图像并获取模型输出。
通过以上章节,我们介绍了YOLOv8的数据流理论和处理实践。理解输入输出机制,对于后续的性能优化和实际应用至关重要。在下一章中,我们将深入探讨提升YOLOv8输入效率的技巧。
# 3. 提升YOLOv8输入效率的技巧
## 3.1 数据加载优化技术
### 3.1.1 多线程与并发处理
在处理大量图像数据时,传统的单线程加载方式往往会成为性能瓶颈。通过采用多线程技术,可以显著提高数据加载的效率。多线程加载允许程序同时从不同源或不同部分加载数据,有效利用CPU资源,缩短等待时间。
为了实现多线程加载,可以使用现代编程语言如Python提供的并发工具。例如,Python的`concurrent.futures`模块提供了一个高层次的异步执行接口。使用`ThreadPoolExecutor`或`ProcessPoolExecutor`可以创建一个线程池或进程池,从而并行执行数据加载任务。
```python
import concurrent.futures
def load_image(image_path):
# 加载图像并执行预处理
image = load_image_from_path(image_path)
return preprocess_image(image)
def main():
image_paths = [...] # 这里是图像路径的列表
with concurrent.futures.ThreadPoolExecutor() as executor:
images = list(executor.map(load_image, image_paths))
# images 是加载和预处理后的图像列表
if __name__ == "__main__":
main()
```
上述代码展示了如何使用Python的`concurrent.futures`模块进行多线程加载图像。通过`ThreadPoolExecutor`可以并发地处理数据加载任务,`executor.map`函数则是将`load_image`函数映射到每个图像路径上,最终返回一个包含所有加载图像的列表。
### 3.1.2 内存管理和缓存策略
内存管理是提高数据加载效率的另一个关键因素。在深度学习任务中,数据往往需要从硬盘读取并转换为模型可接受的格式,这一过程涉及到大量的数据传输和格式转换。合理使用内存缓存可以减少I/O操作的频率,从而加速数据的输入过程。
一种常见的策略是使用数据生成器(data generator)。通过实现一个生成器,可以按需生成数据,并在内存中保持一定量的数据缓冲,以实现快速的数据迭代。
```python
import numpy as np
def data_generator(image_paths, batch_size):
batch = []
for image_path in image_paths:
image = load_image(image_path)
batch.append(image)
if len(batch) == batch_size:
# 处理一个批次的数据
yield np.array(batch)
batch.clear()
if batch:
yield np.array(batch) # 处理剩余的数据
# 使用生成器加载数据
for data_batch in data_generator(image_paths, batch_size):
# 在这里使用数据
...
```
在上述代码中,`data_generator`函数是一个生成器,它会在内存中保持一个固定大小的批次数据。这种方式可以减少内存的使用,同时提供更加灵活的数据加载方式。
## 3.2 硬件加速与适配
### 3.2.1 GPU加速原理
YOLOv8和其它深度学习模型一样,对GPU支持有很高的依赖性,因为GPU可以通过其高度并行的架构显著加速神经网络的运算。当模型在GPU上执行时,可以同时处理大量数据,这比起在CPU上进行顺序计算要快得多。
GPU加速的原理在于其拥有成百上千的核心,可以同时运行多个计算任务。深度学习框架如TensorFlow和PyTorch通常会将计算任务拆分为小块(称为kernels),然后分配给GPU上的多个核心去并行执行。这样可以大幅度减少计算的总时间。
GPU加速的一个关键步骤是内存传输。数据需要从CPU内存传输到GPU内存,再将计算结果传回。这个过程需要通过PCI Express总线进行,比内存访问要慢很多,因此需要尽量减少数据传输的次数。
### 3.2.2 模型量化与剪枝
模型量化(Quantization)和剪枝(Pruning)是深度学习模型优化的两大技术。量化通过减少模型中使用的位数(通常是32位浮点数)来减小模型大小和加快计算速度。剪枝则是去除神经网络中不重要的权重,减少计算量和模型大小。
模型量化可以减少模型在硬件上的存储需求,并在一定程度上减少计算资源的需求。量化过程通常涉及将浮点数转换为定点数,这样做可能会导致一些精度损失,但可以通过适当的方法(例如量化感知训练)来最小化这种影响。
剪枝则是通过移除冗余的神经网络连接或神经元来简化模型结构,从而减少模型的复杂度和推理时的计算量。剪枝可以手动进行,也可以通过自动化的算法来实现。自动剪枝通常基于权重的重要性,将较小的权重认为是不重要的,并将其剪除。
```python
# 假设我们有一个已经训练好的模型
model = ...
# 量化模型
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# 执行模型量化
quantized_model.cpu()()
# 剪枝模型
pruned_model = torch修剪的模型
pruned_model = prune_model(model, ...)
# 执行模型剪枝
```
在上述代码示例中,展示了如何使用PyTorch框架对模型进行量化和剪枝操作。其中`quantize_dynamic`方法将特定层的权重量化为8位整数,`prune_model`方法则根据提供的参数进行剪枝操作。虽然这里没有详细说明函数参数和具体的剪枝策略,但这个过程可以大幅度提高模型的推理速度,降低模型的内存占用。
以上所述的技巧和策略能够有效提升YOLOv8模型在实际应用中的输入效率,特别是在处理大规模数据集时。这些技术的应用需要根据具体情况进行适当的调整和优化。通过多线程并发处理和优化内存管理,可以显著减少数据加载的时间。同时,结合GPU硬件加速和模型的量化与剪枝,可以进一步提升模型的运行效率和推理速度。这些优化方法在实际项目中具有很强的实用价值,能够帮助开发者构建更加高效、稳定和快速的深度学习应用。
# 4. 提高YOLOv8输出效率的技巧
## 4.1 模型后处理优化
### 4.1.1 非极大值抑制(NMS)的改进
在目标检测任务中,非极大值抑制(NMS)是一种常用的后处理方法,用于去除重叠的检测框,以提高检测的准确性。传统的NMS算法在处理大量候选框时可能会导致较高的计算开销,影响实时性。因此,对NMS算法进行优化至关重要。
**优化策略:**
- **并行化NMS:** 通过并行计算框架,例如NVIDIA的TensorRT中的NMS插件,可以显著提高NMS的处理速度,从而提升YOLOv8的整体性能。
- **自适应阈值:** 在NMS算法中引入自适应阈值机制,根据检测目标的大小、类别或其他特征来动态调整抑制阈值,可以提升检测的准确率,同时减少不必要的计算。
- **近似NMS:** 为了进一步提升速度,可以使用近似NMS算法。例如,通过使用空间划分数据结构(如KD树)来加速框与框之间的重叠度计算。
```python
import torch
def nms(boxes, scores, iou_threshold):
"""
对检测框进行NMS处理。
:param boxes: 检测框的坐标,形状为 [num_boxes, 4]。
:param scores: 每个检测框的得分,形状为 [num_boxes]。
:param iou_threshold: NMS抑制的IOU阈值。
:return: 经过NMS处理后的索引。
"""
# 计算坐标框之间的IOU
# 这里应使用高效的矩阵操作来减少计算量
# 例如使用 torchvision.ops.nms()
indices = torchvision.ops.nms(boxes, scores, iou_threshold)
return indices
```
参数说明和逻辑分析:在上述代码中,`nms`函数使用了`torchvision.ops.nms()`,它是对传统NMS的优化版本,通过减少浮点运算量来加速处理速度。`boxes`参数是检测框的坐标,`scores`是对应的置信度分数,`iou_threshold`是用于NMS的交并比阈值。
### 4.1.2 检测结果的快速可视化
检测结果的快速可视化是提升用户体验的关键环节。在进行模型训练和推理时,能够即时查看检测结果,有助于调整模型参数,快速验证算法效果。
**实现步骤:**
1. **定义可视化函数:** 创建一个函数来展示检测结果,该函数能够接收图像和检测框、类别、置信度等信息作为输入。
2. **绘制边界框:** 对于每个检测到的目标,绘制边界框,并在框内标注类别和置信度。
3. **优化绘制效率:** 使用高效的图形库,如OpenCV或Pillow,来处理图像绘制任务。
```python
import cv2
import numpy as np
def visualize_detection(image, detections):
"""
对检测结果进行可视化。
:param image: 输入图像。
:param detections: 检测结果,包含检测框、类别和置信度。
:return: 可视化后的图像。
"""
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
for box, class_id, score in detections:
# 绘制边界框
top, left, bottom, right = box
image = cv2.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2)
# 标注类别和置信度
label = f"{class_id}: {score:.2f}"
image = cv2.putText(image, label, (left, top - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
return image
```
参数说明和逻辑分析:在上述代码中,`visualize_detection`函数接收原始图像和检测结果作为输入。首先将图像从RGB颜色空间转换到BGR空间,以适应OpenCV的显示要求。然后,对每个检测到的目标绘制蓝色的边界框,并在框的左上角标注类别和置信度。这里的标注使用的是OpenCV的`putText`方法。
## 4.2 输出处理的高级应用
### 4.2.1 批量预测与结果汇总
在实际应用中,尤其是需要处理大量数据时,批量预测可以显著提升效率。通过对一批图像进行一次性处理,可以减少模型加载和设备预热的时间开销。
**批量预测实现:**
- **批量加载数据:** 使用数据加载器一次性加载一批图像数据。
- **批量推理:** 在单次前向传播过程中处理这批图像。
- **结果汇总:** 在所有图像的检测结果汇总后,进行后续处理。
```python
def batch_detection(model, batch_images):
"""
执行批量检测。
:param model: 推理模型。
:param batch_images: 批量图像数据。
:return: 每张图像的检测结果。
"""
results = []
with torch.no_grad():
for images in batch_images:
outputs = model(images)
detections = decode_detection(outputs) # 假设decode_detection为解码函数
results.append(detections)
return results
# 假设batch_images为一批图像的Tensor形式
detections = batch_detection(model, batch_images)
```
参数说明和逻辑分析:在`batch_detection`函数中,我们对一批图像进行处理,首先使用`model`进行前向传播得到输出,然后通过`decode_detection`函数将模型输出转换为检测结果。`decode_detection`函数在这里是一个假设的解码函数,用于从模型输出中提取检测框、类别和置信度等信息。
### 4.2.2 动态调度与负载均衡
为了在不同的硬件和软件环境中实现最优的性能,动态调度和负载均衡是必要的。在多个模型实例或多个GPU的情况下,合理分配任务可以让整个系统更加高效。
**策略和实现:**
- **GPU间负载均衡:** 当使用多个GPU进行推理时,可以通过动态调度算法来平衡每个GPU的工作负载。
- **模型实例间调度:** 对于云端服务,可以实现模型实例的动态创建和销毁,以应对用户请求的波动。
```mermaid
flowchart TD
subgraph 负载均衡调度
direction LR
A[开始] --> B{检测请求}
B -- 是 --> C[请求分配]
B -- 否 --> A
C --> D[选择最优模型实例]
D --> E[执行推理]
E --> F[返回检测结果]
end
```
在上述流程图中,系统会根据每个GPU或模型实例的当前负载情况动态分配新的检测请求。当检测请求到来时,系统首先判断是否需要分配任务。如果需要,选择当前负载最轻的模型实例进行处理。完成推理后,将结果返回给用户。这个过程是动态的,并且能够根据实时负载情况进行优化。
参数说明和逻辑分析:在实际的分布式系统中,动态调度会涉及到复杂的负载均衡算法,如轮询调度、最小负载优先等。这些算法通过监控系统资源使用情况,来实现资源的最优分配。通过这种方式,系统能够有效应对不同强度的负载需求,确保整体的服务质量和性能。
# 5. YOLOv8性能优化深入分析
## 5.1 网络架构的优化策略
YOLOv8模型虽已具备强大的目标检测能力,但网络架构的优化仍然是提升其性能的重要手段。优化策略主要分为网络剪枝、通道剪枝和网络蒸馏。
### 5.1.1 网络剪枝与通道剪枝
网络剪枝是一种减少模型大小和提升推理速度的技术。具体操作是去除冗余的神经元和权重,从而减少计算量。在YOLOv8中,可以通过以下步骤进行网络剪枝:
1. 确定剪枝率:根据模型复杂度和目标硬件的计算能力,决定剪枝的比例。
2. 权重重要性评估:利用标准如权重的绝对值大小或梯度信息来评估权重的重要性。
3. 应用剪枝:移除那些重要性低于设定阈值的权重。
4. 微调:剪枝后,通常需要对模型进行微调以恢复精度。
```python
剪枝率设定和权重重要性评估可使用类似以下代码段进行实现:
# 假设权重存储在 `weights` 变量中
def calculate_weight_importance(weights):
# 一个示例函数,评估权重的重要性
# 返回重要性分数
pass
pruning_rate = 0.3 # 设定30%的剪枝率
weight_importances = calculate_weight_importance(weights)
# 通过重要性排序,根据剪枝率确定阈值
threshold = select_threshold(weight_importances, pruning_rate)
# 移除低于阈值的权重
weights[weight_importances < threshold] = 0
```
### 5.1.2 网络蒸馏的应用与效果
网络蒸馏是模型压缩的一种方法,它通过将一个大型、高性能的模型(称为教师模型)的知识转移到一个小型、更易部署的模型(称为学生模型)上。
以下是网络蒸馏的基本步骤:
1. 选择教师模型:一般选择具有较高准确度的复杂模型。
2. 训练学生模型:在蒸馏过程中,学生模型不仅最小化与真实标签的损失,还最小化与教师模型输出之间的差异。
3. 调整温度:在蒸馏损失函数中使用一个温度参数来平滑教师模型的输出,使知识转移更加平滑。
```python
蒸馏过程可使用如下伪代码表示:
# 假设 teacher_output 和 student_output 分别是教师和学生模型的输出
temperature = 5.0 # 设置温度参数
# 软化教师模型的输出
soft_teacher_output = softmax(teacher_output / temperature)
# 计算蒸馏损失函数
distillation_loss = distillation_loss_function(student_output, soft_teacher_output)
```
## 5.2 训练技巧与超参数调整
训练YOLOv8模型时,合适的训练技巧和超参数的选择至关重要。这包括学习率策略、优化器选择、正则化技术等。
### 5.2.1 学习率策略和优化器选择
学习率是影响模型训练速度和收敛性的重要因素。学习率策略应根据具体的训练阶段和任务进行调整:
- 初始学习率:开始阶段应选择较高的学习率,以便模型快速收敛。
- 学习率衰减:随着训练的进行,应逐渐降低学习率,以获得更细致的参数调整。
- 循环或周期性学习率:周期性地调整学习率可以增强模型的泛化能力。
优化器则负责更新网络参数以最小化损失函数。常用的优化器有SGD、Adam等。YOLOv8在训练时可尝试使用动量项的SGD或具有自适应学习率的Adam。
### 5.2.2 正则化与避免过拟合
在训练过程中,正则化技术可以防止模型过拟合。YOLOv8可以采用以下几种正则化方法:
- Dropout:在训练过程中随机丢弃一部分神经元,以减少神经元之间复杂共适应关系。
- 数据增强:通过对训练图像进行旋转、缩放、裁剪等操作,增加数据多样性,提高模型泛化能力。
- 权重衰减:通过在损失函数中增加权重的L1或L2范数惩罚项,限制权重的大小。
```python
# 在YOLOv8的训练配置中,可以通过以下方式设置正则化参数
regularization_parameters = {
'dropout_rate': 0.5, # Dropout比率
'weight_decay': 0.001, # 权重衰减系数
}
# 数据增强的实现示例:
def augment_data(image, labels):
# 实现数据增强的逻辑,例如旋转、缩放等操作
pass
```
通过上述优化策略,YOLOv8的性能可以得到进一步的提升,使其在保持高准确率的同时,也能在资源有限的设备上高效运行。这些策略在很多其他深度学习模型的优化中也具有普适性。
# 6. ```
# 第六章:综合案例分析与实践指南
## 6.1 真实世界数据集的应用
### 6.1.1 数据集的选取与准备
在进行目标检测模型训练之前,数据集的选取和准备至关重要。真实世界数据集通常需要经过一系列的预处理步骤,以确保它们适合于YOLOv8模型。
- **数据集来源**: 选择与目标应用场景相关的数据集,如公共数据集(COCO、VOC等)或者特定领域数据集。
- **数据集清洗**: 清除不清晰、不完整的图像,过滤掉标签错误或缺失的样本。
- **数据标注**: 使用标注工具(如LabelImg、CVAT等)为数据集中的每个目标对象提供精确的边界框和类别标签。
- **数据划分**: 将数据集分为训练集、验证集和测试集,一般比例为6:2:2。
### 6.1.2 部署与实际问题解决
部署YOLOv8模型到实际应用中,需要进行一系列的调试和优化工作,以确保模型的性能满足实际需求。
- **环境搭建**: 搭建适合的硬件和软件环境,包括选择合适的操作系统、安装深度学习框架等。
- **模型转换**: 将训练好的模型转换为适合部署的格式,例如使用ONNX转换模型。
- **性能测试**: 在实际硬件上测试模型的运行速度和准确性,找出可能存在的瓶颈并进行优化。
- **问题解决**: 根据实际运行情况,解决可能出现的延迟、错误等问题,并进行迭代更新。
## 6.2 YOLOv8在不同场景下的应用
### 6.2.1 实时视频流分析
实时视频流分析要求模型具有高速度和高准确率的检测能力。YOLOv8因其轻量级设计和快速处理性能,非常适合这一应用场景。
- **视频处理**: 实现视频帧的实时捕获和预处理。
- **实时检测**: 使用YOLOv8对捕获的视频帧进行目标检测。
- **结果汇总**: 将检测结果进行汇总,可能包括检测框绘制、跟踪标识、统计信息等。
### 6.2.2 多目标跟踪与场景理解
多目标跟踪与场景理解是对模型的更高要求,不仅需要模型能够识别多个目标,还要理解目标间的相互关系以及它们在场景中的作用。
- **目标跟踪**: 应用目标跟踪算法,结合YOLOv8的检测结果,进行连续帧之间的目标匹配和位置更新。
- **场景分析**: 分析目标的运动模式、行为特征等,结合上下文信息进行场景理解。
- **应用扩展**: 探索在安全监控、人机交互等领域的深入应用,挖掘模型的潜在价值。
在本章中,我们通过真实世界数据集的应用和不同场景下的案例分析,展示了YOLOv8在实际操作中遇到的问题和解决方法。这些案例能够帮助读者更好地理解YOLOv8模型在实际工作中的应用和优化策略。
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《YOLOv8输入输出格式说明》专栏全面解析了YOLOv8的输入输出格式,并提供了12个技巧提升输入输出效率和性能优化。专栏涵盖了数据预处理、实时物体检测和性能优化等方面,为读者提供了全面的YOLOv8使用指南。通过优化输入准确性、提升输出效率,用户可以显著提升YOLOv8的检测性能和整体效率。专栏内容深入浅出,案例实操丰富,是YOLOv8使用者提升模型性能的必备参考。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GT-POWER网格划分技术提升:模型精度与计算效率的双重突破

参考资源链接:[GT-POWER基础培训手册](https://wenku.csdn.net/doc/64a2bf007ad1c22e79951b5
【MAC版SAP GUI快捷键大全】:提升工作效率的黄金操作秘籍

参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. MAC版SAP GUI简介与安装
## 简介
SAP GUI(Graphical User Interface)是访问SAP系统
【隧道设计必修课】:FLAC3D网格划分与本构模型选择实用技巧
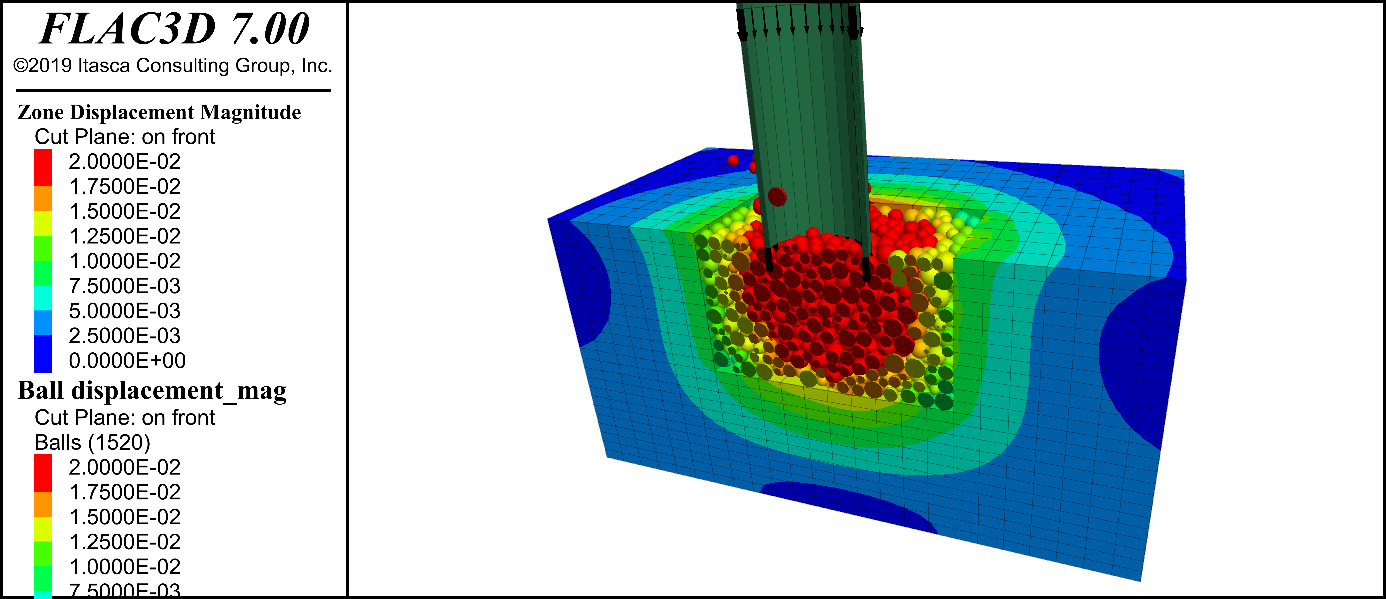
参考资源链接:[FLac3D计算隧道作业](https://wenku.csdn.net/doc/6412b770be7fbd1778d4a4c3?spm=1055.2635.3001.10343)
# 1. FLAC3D简介与应用基础
在本章中,我们将为您介绍FLAC3D(Fast Lagrangian Analysis of Continua in 3 Dimensions)的基础知识以及如何在工程
【故障诊断】:扭矩控制常见问题的西门子1200V90解决方案

参考资源链接:[西门子V90PN伺服驱动参数读写教程](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a36a?spm=1055.2635.3001.10343)
# 1. 扭矩控制概念与西门子1200V90介绍
在自动化与精密工程领域中,扭矩控制是实现设备精确
【Android设备安全必备】:Unknown PIN问题的彻底解决方案
参考资源链接:[unknow PIn解决方案](https://wenku.csdn.net/doc/6412b731be7fbd1778d496d4?spm=1055.2635.3001.10343)
# 1. Unknown PIN问题概述
## 1.1 问题的定义与重要性
Unknown PIN问题通常指用户在忘记或错误输入设备_PIN码后,导致设备锁定,无
【启动速度翻倍】:提升Java EXE应用性能的10大技巧
参考资源链接:[Launch4j教程:JAR转EXE全攻略](https://wenku.csdn.net/doc/6401aca7cce7214c316eca53?spm=1055.2635.3001.10343)
# 1. Java EXE应用性能概述
Java作为广泛使用的编程语言,其应用程序的性能直接影响用户体验和系统的稳定性。Java EXE应用是指那些通过特定打包工具(如Launc
Python Requests高级技巧大揭秘:动态请求头与Cookies管理

参考资源链接:[python requests官方中文文档( 高级用法 Requests 2.18.1 文档 )](https://wenku.csdn.net/doc/646c55d4543f844488d076df?spm=1055.2635.3001.10343)
# 1. 动态请求头与Cookies管理基础
## 1.1 互联网通信
iOS实时视频流传输秘籍:构建无延迟的直播系统
参考资源链接:[iOS平台视频监控软件设计与实现——基于rtsp ffmpeg](https://wenku.csdn.net/doc/4tm4tt24ck?spm=1055.2635.3001.10343)
# 1. 实时视频流传输基础
## 1.1 视频流传输的核心概念
- 视频流传输是构建实时直播系统的核心技术之一,涉及到对视频数据的捕捉、压缩、传输和解码等环节。掌握这些基本概念对于实现高质量
【绘制软件大比拼】:AutoCAD与其它工具在平断面图中的真实对决

参考资源链接:[输电线路设计必备:平断面图详解与应用](https://wenku.csdn.net/doc/6dfbvqeah6?spm=1055.2635.3001.10343)
# 1. 绘制软件大比拼概览
绘制软件领域竞争激烈,为满足不同用户的需求,各种工具应运而生。本章将为读者提供一个概览,介绍市场上流行的几款绘制软件及其主要功能,帮助您快速了解每款软件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )