深入学习SQL:从基础到高级查询技巧
发布时间: 2024-02-22 07:16:50 阅读量: 63 订阅数: 24 

SQL从基础到高级
# 1. SQL基础概述
## 1.1 什么是SQL及其作用
SQL(Structured Query Language)是一种用于管理关系型数据库系统的特殊编程语言,它可以用来执行数据库操作、检索数据、更新数据以及管理数据库结构等功能。
## 1.2 SQL的历史和发展
SQL最早由IBM公司开发,后来成为ANSI和ISO的标准。随着关系型数据库的流行,SQL也逐渐成为了标准数据库语言。
## 1.3 SQL语句的基本结构
SQL语句通常包括关键字、函数、表名、字段名等组成部分,而每个语句都以分号结尾。
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition;
```
## 1.4 数据库的基本概念
数据库是一个存储和组织数据的地方,而表是数据库中的一个结构化数据集合。字段是表中的一列,而行则是表中的单个数据记录。
# 2. SQL基础查询
在学习SQL时,掌握基础查询是非常重要的。本章将介绍SQL基础查询的相关内容,包括SELECT语句的基本用法、WHERE子句的条件过滤、ORDER BY子句的结果排序以及LIMIT和OFFSET的结果分页。让我们逐步深入了解。
### 2.1 SELECT语句的基本用法
SELECT语句用于从数据库中检索数据。基本语法如下:
```sql
SELECT column1, column2, ...
FROM table_name;
```
- 示例场景:从名为`employees`的表中选择`id`和`name`列的数据
```sql
SELECT id, name
FROM employees;
```
- 代码总结:SELECT语句用于选择指定列的数据,可从一个或多个表中进行选择。
- 结果说明:将返回`employees`表中所有行的`id`和`name`列数据。
### 2.2 WHERE子句:条件过滤
WHERE子句用于筛选满足指定条件的行。基本语法如下:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition;
```
- 示例场景:从名为`employees`的表中选择`id`和`name`列的数据,其中`id`为1的行
```sql
SELECT id, name
FROM employees
WHERE id = 1;
```
- 代码总结:使用WHERE子句可以根据指定条件过滤出需要的数据。
- 结果说明:将返回`employees`表中`id`为1的行的`id`和`name`列数据。
### 2.3 ORDER BY子句:结果排序
ORDER BY子句用于对检索出的数据排序。基本语法如下:
```sql
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
```
- 示例场景:从名为`employees`的表中选择`id`和`name`列的数据,并按`id`进行升序排序
```sql
SELECT id, name
FROM employees
ORDER BY id ASC;
```
- 代码总结:使用ORDER BY子句可以按指定列对查询结果进行升序(ASC)或降序(DESC)排序。
- 结果说明:将返回按`id`列升序排列的`employees`表数据。
### 2.4 LIMIT和OFFSET:结果分页
LIMIT和OFFSET用于限制返回的行数,并可实现分页效果。基本语法如下:
```sql
SELECT column1, column2, ...
FROM table_name
LIMIT number_of_rows OFFSET offset_value;
```
- 示例场景:从名为`employees`的表中选择`id`和`name`列的数据,并限制返回2行,偏移2行
```sql
SELECT id, name
FROM employees
LIMIT 2 OFFSET 2;
```
- 代码总结:使用LIMIT和OFFSET结合可以实现数据分页,便于浏览大量数据。
- 结果说明:将返回`employees`表中从第3行开始的2行数据。
通过本章的学习,你已经初步掌握了SQL基础查询的常用语法和用法,能够灵活运用SELECT语句、WHERE子句、ORDER BY子句以及LIMIT和OFFSET来检索和处理数据库中的数据。
# 3. SQL高级查询
在数据库查询中,有时候需要更复杂的查询语句来满足特定需求,这就需要用到SQL的高级查询技巧。本章将介绍SQL高级查询的一些重要内容,包括多表连接、子查询、聚合函数以及分组和聚合等技术。
### 3.1 多表连接:INNER JOIN, LEFT JOIN, RIGHT JOIN
在实际的数据库操作中,经常需要从多个表中获取数据并进行关联。多表连接就是一种强大的技术,它允许我们根据某些条件将多个表中的数据关联起来。
#### 3.1.1 INNER JOIN
内连接(INNER JOIN)是最常用的连接类型之一,它通过匹配两个表中的共同记录来返回结果。以下是内连接的基本语法:
```sql
SELECT column_name(s)
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;
```
#### 3.1.2 LEFT JOIN
左连接(LEFT JOIN)会返回左表中的所有行,同时返回右表中与左表匹配的行。如果右表中没有匹配的行,将返回 NULL 值。左连接的语法如下:
```sql
SELECT column_name(s)
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;
```
#### 3.1.3 RIGHT JOIN
右连接(RIGHT JOIN)与左连接相反,它会返回右表中的所有行,同时返回左表中与右表匹配的行。如果左表中没有匹配的行,将返回 NULL 值。右连接的语法如下:
```sql
SELECT column_name(s)
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;
```
### 3.2 子查询:IN, EXISTS, ANY, ALL
子查询是指嵌套在其他查询语句中的查询,它可以帮助我们在进行复杂的数据检索和处理时更加灵活地运用SQL语句。常见的子查询包括IN、EXISTS、ANY和ALL等方式。
#### 3.2.1 IN子查询
IN子查询用于判断某列的值是否在子查询返回的结果集中,其基本语法如下:
```sql
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT column_name FROM table_name WHERE condition);
```
### 3.3 聚合函数:COUNT, SUM, AVG, MAX, MIN
SQL提供了丰富的聚合函数,用于对查询结果进行统计和计算。常用的聚合函数包括COUNT、SUM、AVG、MAX和MIN等。
#### 3.3.1 COUNT函数
COUNT函数用于统计指定列的行数,可以根据需要进行条件统计或统计所有行。其基本语法如下:
```sql
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
```
### 3.4 分组和聚合:GROUP BY, HAVING
分组和聚合是SQL中非常重要的操作,它们允许我们根据指定的列对结果集进行分组,并对分组后的数据进行统计和筛选。
#### 3.4.1 GROUP BY子句
GROUP BY子句用于对结果集按照一个或多个列进行分组,其基本语法如下:
```sql
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name;
```
#### 3.4.2 HAVING子句
HAVING子句通常和GROUP BY子句一起使用,用于对分组后的结果集进行筛选操作。其基本语法如下:
```sql
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1;
```
通过学习和掌握这些高级查询技巧,我们可以更加灵活地运用SQL来处理复杂的数据查询和分析,在实际工作中发挥更大的作用。
# 4. SQL高级技巧
### 4.1 窗口函数:ROW_NUMBER, RANK, DENSE_RANK
窗口函数是一种高级技巧,可以对结果集执行各种分析和计算。常见的窗口函数包括ROW_NUMBER, RANK和DENSE_RANK。
#### ROW_NUMBER函数示例
```sql
SELECT
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
employee_id,
first_name,
last_name,
salary
FROM
employees;
```
-- 在结果集中为每条记录分配行号
#### RANK函数示例
```sql
SELECT
RANK() OVER (ORDER BY sales_amount DESC) AS sales_rank,
salesperson_id,
sales_amount
FROM
sales_data;
```
-- 根据销售额对销售人员进行排名
#### DENSE_RANK函数示例
```sql
SELECT
DENSE_RANK() OVER (ORDER BY exam_score DESC) AS exam_rank,
student_id,
exam_score
FROM
exam_results;
```
-- 计算考试成绩的密集排名,不留空位
### 4.2 高级子查询:嵌套子查询, 关联子查询
在SQL中,子查询是指在查询中嵌套另一个SELECT语句,用于检索符合条件的数据。
#### 嵌套子查询示例
```sql
SELECT
employee_id,
first_name,
last_name
FROM
employees
WHERE
department_id IN (SELECT department_id FROM departments WHERE department_name = 'IT');
```
-- 查询IT部门的员工信息
#### 关联子查询示例
```sql
SELECT
product_name,
unit_price
FROM
products p
WHERE
unit_price > (SELECT AVG(unit_price) FROM products WHERE category_id = p.category_id);
```
-- 查询单位价格高于所属分类平均价格的产品信息
### 4.3 模糊查询:LIKE, %, _, ESCAPE
模糊查询用于匹配包含指定模式的数据,常用通配符包括%和_。
#### LIKE运算符示例
```sql
SELECT
product_name
FROM
products
WHERE
product_name LIKE 'Apple%';
```
-- 查询以"Apple"开头的产品名称
#### 使用%通配符示例
```sql
SELECT
customer_name
FROM
customers
WHERE
customer_name LIKE '%Solutions%';
```
-- 查询包含"Solutions"的客户名称
#### 使用_通配符示例
```sql
SELECT
employee_name
FROM
employees
WHERE
employee_name LIKE '__i%';
```
-- 查询第三和第四个字母为"i"的员工名
### 4.4 CASE表达式:简化复杂逻辑
CASE表达式是一种灵活的方式,根据条件返回不同的值。
#### 简单CASE表达式示例
```sql
SELECT
order_id,
quantity,
CASE
WHEN quantity > 10 THEN 'High'
WHEN quantity > 5 THEN 'Medium'
ELSE 'Low'
END AS quantity_category
FROM
orders;
```
-- 根据数量划分订单量级
#### 搜索CASE表达式示例
```sql
SELECT
product_name,
unit_price,
CASE
WHEN unit_price < 50 THEN 'Low Cost'
WHEN unit_price BETWEEN 50 AND 100 THEN 'Medium Cost'
ELSE 'High Cost'
END AS price_category
FROM
products;
```
-- 根据价格范围归类产品价格级别
```
通过掌握窗口函数、高级子查询、模糊查询和CASE表达式等技巧,可以更灵活地处理复杂的查询需求,提升SQL查询的效率和准确性。
# 5. 性能优化与索引
在实际使用SQL进行数据处理时,除了掌握基本的查询语法和高级技巧外,还需要关注SQL查询的性能优化,以及索引的使用。本章将深入讨论索引的作用、类型、创建与管理,以及SQL查询优化的基本原则和使用EXPLAIN语句进行查询分析的方法。
#### 5.1 索引的作用及类型
##### 5.1.1 什么是索引?
索引是一种特殊的数据结构,用于快速查找数据库表中的记录。通过创建索引,可以加快数据查询的速度,特别是对大型数据表的查询操作,能够显著提高查询效率。
##### 5.1.2 索引的类型
常见的索引类型包括:
- 主键索引(Primary Key Index):用于唯一标识表中的每一行数据,通常会自动创建在主键字段上。
- 唯一索引(Unique Index):确保索引列的数值唯一,但允许空值。
- 普通索引(Normal Index):最基本的索引类型,没有特殊约束,允许重复和空值。
- 组合索引(Composite Index):多个字段上的联合索引,可提高查询效率。
#### 5.2 索引的创建与管理
##### 5.2.1 创建索引
在SQL中,可以使用CREATE INDEX语句来创建索引,语法如下:
```sql
CREATE INDEX index_name ON table_name (column1, column2, ...);
```
##### 5.2.2 管理索引
除了创建索引外,还需要定期维护和管理索引,包括:
- 监控索引的使用情况,及时删除未使用的索引。
- 确保索引的选择能够覆盖常用的查询条件。
- 避免频繁的索引修改操作,影响数据库性能。
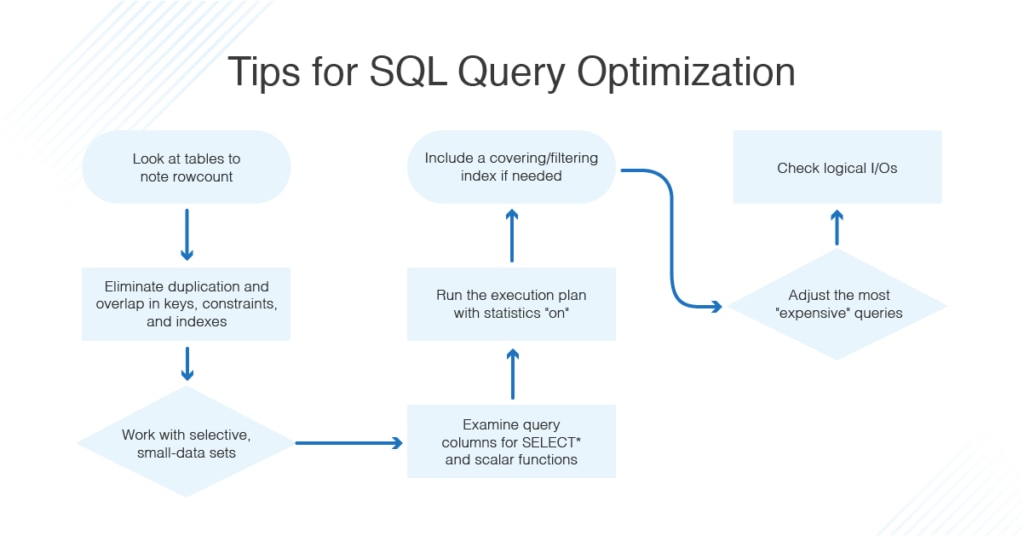
#### 5.3 SQL查询优化的基本原则
为了提高SQL查询的效率,可以遵循以下基本原则进行优化:
- 选择合适的数据类型,减小数据存储空间,提高查询速度。
- 避免使用SELECT *,而是明确指定需要查询的字段。
- 合理使用索引,根据实际查询情况创建适当的索引。
- 编写高效的SQL查询语句,避免冗余的子查询和循环操作。
#### 5.4 EXPLAIN语句的使用与分析
在MySQL等数据库系统中,可以使用EXPLAIN语句对SQL查询进行分析,查看查询执行计划和使用的索引情况,帮助优化查询性能。
```sql
EXPLAIN SELECT * FROM table_name WHERE condition;
```
通过分析EXPLAIN语句的输出结果,可以了解查询涉及的表、查询方式、索引使用情况等重要信息,从而进行合理的优化调整。
通过深入了解和掌握索引的作用与管理、SQL查询的优化原则以及EXPLAIN语句的使用,可以有效提升数据库查询性能,减少查询时间和资源消耗。
接下来,我们将进入第六章,学习高级数据操作的内容。
# 6. 高级数据操作
在SQL中,除了查询数据外,还有对数据进行插入、更新和删除的操作,同时还有事务控制的功能。本章将介绍SQL中的高级数据操作技巧。
#### 6.1 插入数据:INSERT INTO, VALUES
插入数据是指将新的数据行添加到表中。可以使用INSERT INTO语句和VALUES子句来向数据库表中插入数据。
```sql
-- 示例:向users表中插入一条新记录
INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25);
```
- 代码解析:
- `INSERT INTO`: 插入数据的关键词
- `users`: 表名
- `(id, name, age)`: 指定要插入数据的字段顺序
- `VALUES (1, 'Alice', 25)`: 插入的具体数值
- 结果说明: 执行后会在users表中插入一条id为1,名称为Alice,年龄为25的新记录。
#### 6.2 更新数据:UPDATE SET
更新数据是指修改表中已有数据行的数值。使用UPDATE语句和SET子句进行数据更新操作。
```sql
-- 示例:更新users表中id为1的记录的年龄为30
UPDATE users SET age = 30 WHERE id = 1;
```
- 代码解析:
- `UPDATE`: 更新数据的关键词
- `SET age = 30`: 设置要更新的字段及值
- `WHERE id = 1`: 更新条件,确保只更新符合条件的数据行
- 结果说明: 执行后会将users表中id为1的记录的年龄修改为30。
#### 6.3 删除数据:DELETE FROM
删除数据是指从表中删除数据行。使用DELETE FROM语句和WHERE子句进行数据删除操作。
```sql
-- 示例:删除users表中id为1的记录
DELETE FROM users WHERE id = 1;
```
- 代码解析:
- `DELETE FROM`: 删除数据的关键词
- `WHERE id = 1`: 删除条件,确保只删除符合条件的数据行
- 结果说明: 执行后会从users表中删除id为1的记录。
#### 6.4 事务控制:BEGIN, COMMIT, ROLLBACK
事务是指作为单个逻辑工作单元执行的一组操作。在SQL中,可以使用BEGIN来开始一个事务,使用COMMIT来保存更改并结束事务,使用ROLLBACK来撤销更改并结束事务。
```sql
-- 示例:使用事务控制实现转账操作
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE account_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE account_id = 2;
COMMIT;
```
- 代码解析:
- `BEGIN`: 开始一个事务
- `UPDATE`: 执行转账操作,减少一个账户的余额,增加另一个账户的余额
- `COMMIT`: 提交事务,保存更改
- `ROLLBACK`: 可以在需要时撤销事务并回滚操作
- 结果说明: 执行上述代码块后,将完成从账户1向账户2转账100的操作,并保证操作的原子性。
通过掌握这些高级数据操作技巧,可以更灵活地对数据库中的数据进行操作,并确保操作的准确性和完整性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Boost专栏汇集了HTML和CSS入门指南、JavaScript中的函数式编程概念与实践、深入学习SQL,Node.js与Express框架入门指南,数据可视化,Docker容器化技术入门与实践,Web安全性101,深入理解操作系统原理与实践,Angular框架深度解析,以及AWS云服务入门指南等一系列精彩内容。无论您是新手还是有经验的开发者,本专栏都将为您提供全面的指导,帮助您构建第一个网页、掌握高级查询技巧、了解Node.js和Express框架、使用D3.js创建交互式图表、学习Docker容器化技术、保护应用免受攻击、深入理解操作系统原理、解析Angular框架,以及构建可靠的云架构。快来加入我们吧,一起提升技能,探索最新的技术趋势!
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
科东纵密性能革命:掌握中级调试,优化系统表现

# 摘要
本论文旨在全面探讨中级调试的概念、基础理论、系统监控、性能评估以及性能调优实战技巧。通过分析系统监控工具与方法,探讨了性能评估的核心指标,如响应时间、吞吐量、CPU和内存利用率以及I/O性能。同时,文章详细介绍了在调试过程中应用自动化工具和脚本语言的实践,并强调了调试与优化的持续性管理,包括持续性监控与优化机制的建立、调试知识的传承与团队协作以及面向未来的调试
数字信号处理在雷达中的应用:理论与实践的完美融合
# 摘要
本文探讨了数字信号处理技术在雷达系统中的基础、分析、增强及创新应用。首先介绍了雷达系统的基本概念和信号采集与预处理的关键技术,包括采样定理、滤波器设计与信号去噪等。接着,文章深入分析了数字信号处理技术在雷达信号分析中的应用,如快速傅里叶变换(FFT)和时频分析技术,并探讨了目标检测与机器学习在目标识别中的作用。随后,本文探讨了信号增强技
【数据库性能提升20个实用技巧】:重庆邮电大学实验报告中的优化秘密
# 摘要
数据库性能优化是保证数据处理效率和系统稳定运行的关键环节。本文从多个角度对数据库性能优化进行了全面的探讨。首先介绍了索引优化策略,包括索引基础、类型选择、设计与实施,以及维护与监控。接着,本文探讨了查询优化技巧,强调了SQL语句调优、执行计划分析、以及子查询和连接查询的优化方法。此外,数据库架构优化被详细讨论,涵盖设
【PSpice模型优化速成指南】:5个关键步骤提升你的模拟效率

# 摘要
本文对PSpice模型优化进行了全面概述,强调了理解PSpice模型基础的重要性,包括模型的基本组件、参数以及精度评估。深入探讨了PSpice模型参
29500-2 vs ISO_IEC 27001:合规性对比深度分析
# 摘要
本文旨在全面梳理信息安全合规性标准的发展和应用,重点分析了29500-2标准与ISO/IEC 27001标准的理论框架、关键要求、实施流程及认证机制。通过对两个标准的对比研究,本文揭示了两者在结构组成、控制措施以及风险管理方法上的差异,并通过实践案例,探讨了这些标准在企业中的应用效果和经验教训。文章还探讨了信息安全领域的新趋势,并对合规性面临的挑战提出了应对
RH850_U2A CAN Gateway性能加速:5大策略轻松提升数据传输速度

# 摘要
本文针对RH850_U2A CAN Gateway性能进行了深入分析,并探讨了基础性能优化策略。通过硬件升级与优化,包括选用高性能硬件组件和优化硬件配置与布局,以及软件优化的基本原则,例如软件架构调整、代码优化技巧和内存资源管理,提出了有效的性能提升方法。此外,本文深入探讨了数据传输协议的深度应用,特别是在CAN协议数据包处理、数据缓存与批量传输以及实时操作系统任务
MIPI信号完整性实战:理论与实践的完美融合

# 摘要
本文全面介绍了MIPI技术标准及其在信号完整性方面的应用。首先概述了MIPI技术标准并探讨了信号完整性基础理论,包括信号完整性的定义、问题分类以及传输基础。随后,本文详细分析了MIPI信号完整性的关键指标,涵盖了物理层指标、信号质量保证措施,以及性能测试与验证方法。在实验设计与分析章节中,本文描述了实验环境搭建、测
【内存升级攻略】:ThinkPad T480s电路图中的内存兼容性全解析

# 摘要
本文系统性地探讨了内存升级的基础知识、硬件规格、兼容性理论、实际操作步骤以及故障诊断和优化技巧。首先,概述了内存升级的基本概念和硬件规格,重点分析了ThinkPad T480s的核心组件和内存槽位。接着,深入讨论了内存兼容性理论,包括技术规范和系统对内存的要求。实际操作章节提供了详细的内存升级步骤,包括检查配置、更换内存和测试新内存。此外,本文还涵盖故障诊断方法和进阶内存配置
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )