Spark RDD详解与实战应用
发布时间: 2024-02-22 10:08:02 阅读量: 89 订阅数: 40 

spark入门实战
# 1. Spark简介与RDD概述
## 1.1 Spark框架介绍
Apache Spark是基于内存计算的快速通用计算引擎,最初由加州大学伯克利分校AMPLab开发,旨在统一数据分析和大规模机器学习。Spark提供了高层次的API,如Spark SQL用于SQL查询、DataFrame用于结构化数据处理、MLlib用于机器学习等,使得用户可以更方便地进行数据处理和分析。
Spark具有以下特点:
- 速度快:由于基于内存计算,Spark在处理数据时速度非常快。
- 易用性强:提供了丰富的API,可以通过Python、Java、Scala等多种语言进行编程。
- 弹性扩展:可以轻松地扩展到数千台服务器,处理PB级数据。
- 统一解决方案:Spark支持批处理、交互式查询、实时流处理等多种功能,并提供了统一的解决方案。
## 1.2 什么是RDD(Resilient Distributed Dataset)
RDD是Spark中最基本的数据抽象,是不可变的、容错的数据对象集合。RDD可以看作是一个分布式的对象集合,每个RDD都被分成多个分区,这些分区可以在集群的不同节点上进行计算。
RDD具有以下特点:
- 弹性(Resilient):RDD能够自动恢复中间计算数据的能力,保证了计算的顺利进行。
- 分布式(Distributed):数据集合是分布式存储在集群的多个节点上的。
- 数据集转换(Dataset):RDD支持对数据集合进行各种转换操作,如map、filter等。
- 持久化(Persistent):可以通过持久化操作将RDD数据持久化到内存或磁盘,提高计算性能。
## 1.3 RDD特性与优势
- **内存计算**:RDD支持内存计算,加速数据处理过程。
- **容错性**:RDD具有容错机制,保证了计算中间结果的可靠性。
- **并行性**:RDD支持并行计算,能够充分利用集群资源。
- **编程接口**:提供了丰富的编程接口,易于使用和扩展。
- **优化机制**:Spark提供了优化机制,能够对RDD进行高效优化。
通过以上内容,我们对Spark的基本概念和RDD的特点有了初步了解。接下来,我们将深入探讨RDD的基本操作与转换,以更好地应用Spark进行数据处理与分析。
# 2. RDD基本操作与转换
#### 2.1 RDD创建与初始化
在本节中,我们将介绍如何创建和初始化RDD。我们将讨论通过内存集合和外部数据源创建RDD的方法,并演示如何使用不同的方法来初始化RDD。
#### 2.2 RDD转换操作详解
本节将深入讲解RDD的转换操作,包括map、filter、flatMap等常用转换操作的用法,并通过实际示例演示这些操作的作用。
#### 2.3 RDD行动操作详解
在这一部分,我们将详细介绍RDD的行动操作,如collect、count、reduce等,并解释它们的用途和效果。我们将通过实例演示这些行动操作的实际场景应用。
希望这样的章节内容符合你的要求,如有其他需求,还请指出。
# 3. RDD高级操作与优化
在这一章中,我们将深入探讨RDD的高级操作和优化技巧,包括RDD的持久化与检查点、Shuffle操作的详细说明以及RDD的优化与性能调优策略。
#### 3.1 RDD持久化与检查点
在Spark中,RDD的持久化可以通过persist()方法来实现,将RDD持久化到内存或磁盘中,以便在之后的操作中重用。常见的持久化级别包括MEMORY_ONLY、MEMORY_AND_DISK、MEMORY_ONLY_SER等。
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.persist(StorageLevel.MEMORY_ONLY)
```
除了持久化,RDD还支持检查点操作,可以通过checkpoint()方法将RDD在某一点写入磁盘,以便在节点故障时能够快速恢复。
```python
sc.setCheckpointDir("hdfs://path/to/directory")
rdd.checkpoint()
```
#### 3.2 Shuffle操作详解
Shuffle是Spark中一种重要而昂贵的操作,它涉及数据的重新分区和重新组织。常见的Shuffle操作包括groupByKey、reduceByKey、join等,这些操作可能导致大量的数据移动和网络开销。
```python
rdd = sc.parallelize([(1, 'a'), (2, 'b'), (1, 'c')])
result = rdd.groupByKey().mapValues(list).collect()
```
#### 3.3 RDD优化与性能调优
为了提高Spark应用程序的性能,我们可以采取一系列优化措施,例如合理设置RDD的分区数、避免数据倾斜、使用广播变量和累加器等技术。
```python
rdd = sc.parallelize(range(1000), numSlices=10)
result = rdd.map(lambda x: x * 2).reduce(lambda x, y: x + y)
```
通过合理优化和调整,可以有效提升Spark应用程序的执行效率,降低资源消耗,提升整体性能表现。
以上便是RDD高级操作与优化的内容,希望对你理解和应用RDD在实践中有所帮助。
# 4. RDD实战案例分析
在这一章中,我们将深入讨论Spark RDD在实际应用中的案例分析,包括数据清洗、图计算以及机器学习等方面的应用场景和实现方法。
### 4.1 Spark RDD在数据清洗中的应用
数据清洗是数据处理过程中至关重要的一步,而Spark RDD提供了丰富的操作方法和函数,可以帮助我们高效地进行数据清洗工作。下面我们以一个简单的数据清洗案例来说明:
```python
# 导入SparkConf和SparkContext
from pyspark import SparkConf, SparkContext
# 初始化SparkConf和SparkContext
conf = SparkConf().setAppName("data_cleaning")
sc = SparkContext(conf=conf)
# 读取文本文件
data_rdd = sc.textFile("data.txt")
# 进行数据清洗操作,例如去除空行
cleaned_data_rdd = data_rdd.filter(lambda x: x.strip() != "")
# 输出清洗后的数据
for line in cleaned_data_rdd.collect():
print(line)
# 关闭SparkContext
sc.stop()
```
**代码总结:** 上述代码通过读取文本文件,利用filter函数去除了空行,最终输出了清洗后的数据。在实际场景中,数据清洗可能涉及更复杂的逻辑,但通过Spark RDD提供的丰富操作函数,我们能够轻松实现数据清洗工作。
**结果说明:** 经过数据清洗操作后,输出的数据不再包含空行,达到了清洗数据的目的。
### 4.2 RDD在图计算中的实际应用
图计算是另一个重要领域,Spark提供了GraphX图计算库,结合RDD可以方便地进行图数据处理和计算。下面我们以一个简单的图计算案例来说明:
```python
# 导入SparkConf、SparkContext和GraphX
from pyspark import SparkConf, SparkContext
from pyspark.graphx import Graph
# 初始化SparkConf和SparkContext
conf = SparkConf().setAppName("graph_processing")
sc = SparkContext(conf=conf)
# 构建图数据
vertices = sc.parallelize([(1, "Alice"), (2, "Bob"), (3, "Charlie")])
edges = sc.parallelize([(1, 2, "friend"), (2, 3, "follow")])
graph = Graph(vertices, edges)
# 进行图计算操作,例如查找Alice的朋友
friends = graph.edges.filter(lambda x: x[2] == "friend").map(lambda x: (x[0], x[1]))
alice_friends = friends.filter(lambda x: x[0] == 1).map(lambda x: x[1])
# 输出结果
for friend in alice_friends.collect():
print("Alice's friend:", friend)
# 关闭SparkContext
sc.stop()
```
**代码总结:** 上述代码构建了一个简单的图数据,然后通过filter和map等操作,找到了Alice的朋友。实际应用中,图计算可能涉及更复杂的算法和逻辑,但Spark GraphX提供了丰富的图计算函数,能够满足各种需求。
**结果说明:** 经过图计算操作,输出了Alice的朋友列表,帮助我们更好地理解图数据结构和关系。
### 4.3 RDD在机器学习中的使用案例
机器学习是Spark RDD的另一个重要应用领域,通过结合MLlib机器学习库,可以进行各种机器学习模型的建模和训练。下面我们以一个简单的线性回归案例来说明:
```python
# 导入SparkConf、SparkContext和MLlib
from pyspark import SparkConf, SparkContext
from pyspark.mllib.regression import LabeledPoint, LinearRegressionWithSGD
# 初始化SparkConf和SparkContext
conf = SparkConf().setAppName("machine_learning")
sc = SparkContext(conf=conf)
# 构建训练数据
data = sc.textFile("data.csv")
parsed_data = data.map(lambda line: line.split(",")).map(lambda parts: LabeledPoint(parts[0], parts[1:]))
# 训练线性回归模型
model = LinearRegressionWithSGD.train(parsed_data)
# 输出模型参数
print("Model weights: " + str(model.weights))
print("Model intercept: " + str(model.intercept))
# 关闭SparkContext
sc.stop()
```
**代码总结:** 上述代码读取了CSV格式的训练数据,通过解析和转换构建了LabeledPoint数据结构,然后训练了一个线性回归模型。MLlib提供了各种机器学习算法的实现,可以帮助我们快速构建和训练模型。
**结果说明:** 经过模型训练后,输出了线性回归模型的权重和截距等参数,帮助我们理解模型的特征和预测效果。
通过以上实际案例分析,我们可以看到Spark RDD在数据清洗、图计算和机器学习等领域的应用,展现了其强大的数据处理和计算能力。在实际项目中,结合具体场景和需求,我们可以灵活运用Spark RDD提供的操作函数和库,实现各种复杂的数据处理和分析任务。
# 5. Spark RDD与其他组件整合
在这一章节中,我们将深入探讨Spark RDD如何与其他Spark组件进行整合,进一步拓展其在大数据处理应用中的应用场景和潜力。通过与Spark SQL、Spark Streaming、GraphX等组件的配合应用,可以实现更加复杂和多样化的数据处理和分析任务。接下来将分别介绍RDD与这些组件的整合方式及应用实例。
### 5.1 RDD与Spark SQL集成
Spark SQL作为Spark生态系统中的一个组件,提供了将结构化数据和RDD进行整合的功能。通过Spark SQL,可以使用SQL查询或者DataFrame API来操作数据,而RDD可以很方便地转换为DataFrame进行处理。
#### 示例代码(使用Python):
```python
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder \
.appName("RDD-SparkSQL Integration") \
.getOrCreate()
# 创建一个RDD
data = [("Alice", 34), ("Bob", 45), ("Catherine", 28)]
rdd = spark.sparkContext.parallelize(data)
# 将RDD转换为DataFrame
df = rdd.toDF(["name", "age"])
# 使用Spark SQL查询数据
df.createOrReplaceTempView("people")
result = spark.sql("SELECT * FROM people WHERE age >= 30")
# 展示查询结果
result.show()
# 停止SparkSession
spark.stop()
```
#### 代码解析:
1. 创建SparkSession对象,初始化应用程序名称。
2. 创建一个包含数据的RDD。
3. 将RDD转换为DataFrame,并指定列名。
4. 将DataFrame注册为临时视图。
5. 使用SQL查询筛选年龄大于等于30的数据。
6. 展示查询结果。
7. 停止SparkSession。
### 5.2 RDD与Spark Streaming结合
Spark Streaming是Spark提供的处理实时数据流的组件,在与RDD结合时,可以实现对实时数据流的即时处理和分析。通过DStream(离散流)的概念,将实时数据流划分为一系列批次数据,然后利用RDD的转换操作对每个批次进行处理。
#### 示例代码(使用Scala):
```scala
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("RDD-SparkStreaming Integration").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
```
#### 代码解析:
1. 创建SparkConf,设置应用程序名称和Master为本地模式。
2. 初始化StreamingContext,设置批次间隔为1秒。
3. 从本地socket接收实时文本流。
4. 切分每行文本为单词。
5. 每个单词映射为(单词, 1),然后按单词进行reduce操作计数。
6. 打印每个单词的计数。
7. 启动StreamingContext并等待终止。
### 5.3 RDD与GraphX等组件配合应用
除了Spark SQL和Spark Streaming以外,Spark还提供了其他组件如GraphX用于图数据处理。RDD与GraphX的整合可以实现对大规模图数据的高效处理和分析,例如图计算、社交网络分析等。
在实际应用中,可以通过将图数据表示为顶点RDD和边RDD的方式,结合GraphX提供的图算法和操作,对图数据进行复杂的分析和计算。
通过这些整合应用,Spark RDD在与其他组件的配合下,可以更好地适应不同数据处理场景,提供更加全面和强大的数据处理能力。
希望以上内容能够帮助您更深入地理解Spark RDD与其他Spark组件的整合应用,为您在实际项目中的数据处理和分析提供借鉴和参考。
# 6. Spark RDD项目部署与最佳实践
在这一章节中,我们将深入探讨如何在实际项目中部署和使用Spark RDD,并分享一些最佳实践和经验。
#### 6.1 RDD项目开发流程与部署
在这部分,我们将介绍RDD项目的开发流程,包括环境搭建、项目配置、开发调试和打包部署等内容。我们将重点讨论如何利用Maven或SBT构建Spark项目,并演示一个简单的RDD项目实例。
#### 6.2 RDD应用程序调优技巧
作为大数据处理框架,Spark RDD在处理海量数据时可能会遇到性能瓶颈。在这一节,我们将分享一些RDD应用程序调优的常见技巧,包括数据倾斜处理、并行度调整、内存管理等内容。
#### 6.3 RDD在大规模生产环境中的最佳实践
最后,我们将探讨RDD在大规模生产环境中的最佳实践。包括资源管理、故障处理、监控优化等内容,帮助您更好地将RDD应用于生产环境并发挥其最大价值。
希望这部分内容能够为您提供有关Spark RDD项目部署和最佳实践方面的全面指导和实用建议。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Spark进阶》专栏深入探讨了Apache Spark在大数据处理领域的高级应用与进阶技术。通过系列文章的逐一解析,包括《Spark架构与工作原理解析》、《Spark RDD详解与实战应用》、《Spark SQL性能优化策略》等,读者将深入了解Spark核心组件的原理与实际应用。同时,《Spark MLlib机器学习库实战指南》、《Spark GraphFrames图分析实践》等文章则展示了Spark在机器学习和图分析领域的实际应用案例,帮助读者提升数据处理与分析的能力。此外,专栏还涵盖了Spark与各类开源框架(如Kafka、Hadoop、TensorFlow等)的集成实践、机器学习模型部署与服务化,以及在金融领域的具体应用案例剖析等内容。通过专栏的阅读,读者将从多个角度全面了解Spark在大数据处理与应用上的突出表现,并掌握在实际场景中的高级应用技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F030C8T6专攻:最小系统扩展与高效通信策略
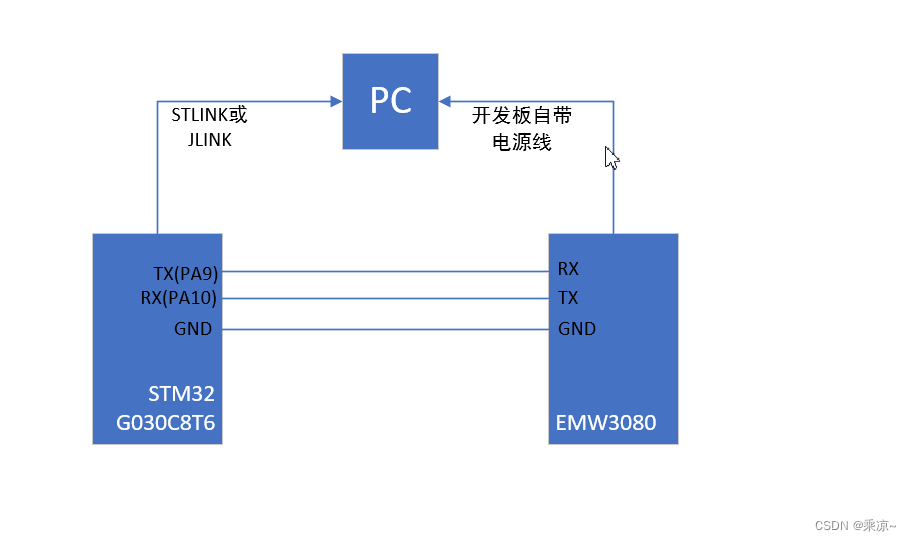
# 摘要
本文首先介绍了STM32F030C8T6微控制器的基础知识和最小系统设计的要点,涵盖硬件设计、软件配置及最小系统扩展应用案例。接着深入探讨了高效通信技术,包括不同通信协议的使用和通信策略的优化。最后,文章通过项目管理与系统集成的实践案例,展示了如何在实际项目中应用这些技术和知识,进行项目规划、系统集成、测试及故障排除,以提高系统的可靠性和效率。
# 关键字
STM32F030C8T6;
【PyCharm专家教程】:如何在PyCharm中实现Excel自动化脚本

# 摘要
本文旨在全面介绍PyCharm集成开发环境以及其在Excel自动化处理中的应用。文章首先概述了PyCharm的基本功能和Python环境配置,进而深入探讨了Python语言基础和PyCharm高级特性。接着,本文详细介绍了Excel自动化操作的基础知识,并着重分析了openpyxl和Pandas两个Python库在自动化任务中的运用。第四章通过实践案
ARM处理器时钟管理精要:工作模式协同策略解析

# 摘要
本文系统性地探讨了ARM处理器的时钟管理基础及其工作模式,包括处理器运行模式、异常模式以及模式间的协同关系。文章深入分析了时钟系统架构、动态电源管理技术(DPM)及协同策略,揭示了时钟管理在提高处理器性能和降低功耗方面的重要性。同时,通过实践应用案例的分析,本文展示了基于ARM的嵌入式系统时钟优化策略及其效果评估,并讨论了时钟管理常见问题的
【提升VMware性能】:虚拟机高级技巧全解析
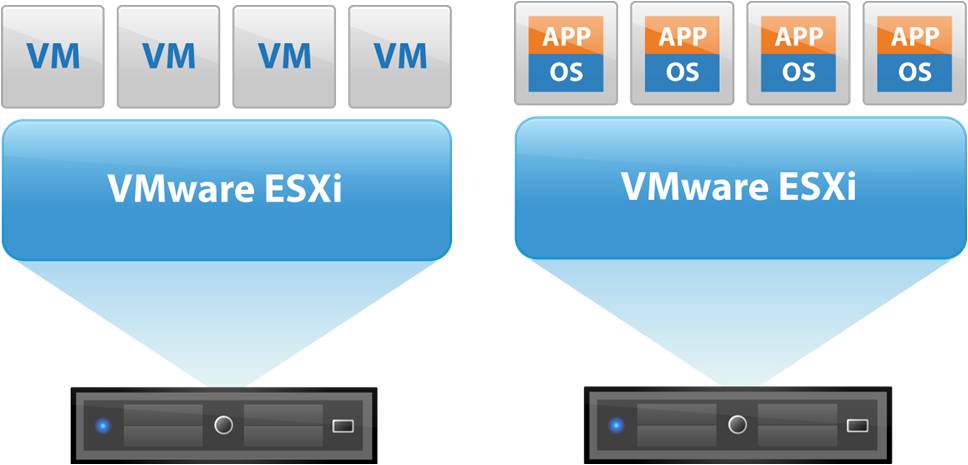
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
数字逻辑综合题技巧大公开:第五版习题解答与策略指南

# 摘要
本文旨在回顾数字逻辑基础知识,并详细探讨综合题的解题策略。文章首先分析了理解题干信息的方法,包括题目要求的分析与题型的确定,随后阐述了数字逻辑基础理论的应用,如逻辑运算简化和时序电路分析,并利用图表和波形图辅助解题。第三章通过分类讨论典型题目,逐步分析了解题步骤,并提供了实战演练和案例分析。第四章着重介绍了提高解题效率的技巧和避免常见错误的策略。最后,第五章提供了核心习题的解析和解题参考,旨在帮助读者巩固学习成果并提供额外的习题资源。整体而言,本文为数字逻辑
Zkteco智慧云服务与备份ZKTime5.0:数据安全与连续性的保障
# 摘要
本文全面介绍了Zkteco智慧云服务的系统架构、数据安全机制、云备份解决方案、故障恢复策略以及未来发展趋势。首先,概述了Zkteco智慧云服务的概况和ZKTime5.0系统架构的主要特点,包括核心组件和服务、数据流向及处理机制。接着,深入分析了Zkteco智慧云服务的数据安全机制,重点介绍了加密技术和访问控制方法。进一步,本文探讨了Zkteco云备份解决方案,包括备份策略、数据冗余及云备份服务的实现与优化。第五章讨论了故障恢复与数据连续性保证的方法和策略。最后,展望了Zkteco智慧云服务的未来,提出了智能化、自动化的发展方向以及面临的挑战和应对策略。
# 关键字
智慧云服务;系统
Java安全策略高级优化技巧:local_policy.jar与US_export_policy.jar的性能与安全提升

# 摘要
Java安全模型是Java平台中确保应用程序安全运行的核心机制。本文对Java安全模型进行了全面概述,并深入探讨了安全策略文件的结构、作用以及配置过程。针对性能优化,本文提出了一系列优化技巧和策略文件编写建议,以减少不必要的权限声明,并提高性能。同时,本文还探讨了Java安全策略的安全加固方法,强调了对local_po
海康二次开发实战攻略:打造定制化监控解决方案

# 摘要
海康监控系统作为领先的视频监控产品,其二次开发能力是定制化解决方案的关键。本文从海康监控系统的基本概述与二次开发的基础讲起,深入探讨了SDK与API的架构、组件、使用方法及其功能模块的实现原理。接着,文中详细介绍了二次开发实践,包括实时视频流的获取与处理、录像文件的管理与回放以及报警与事件的管理。此外,本文还探讨了如何通过高级功能定制实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )