Apache Spark入门指南:大数据处理基础
发布时间: 2024-02-23 13:03:36 阅读量: 53 订阅数: 21 

Spark大数据技术处理
# 1. 什么是Apache Spark?
## 1.1 Apache Spark介绍
在本节中,我们将介绍什么是Apache Spark,包括其起源、发展历程以及基本概念。
## 1.2 Spark与传统大数据处理框架的对比
本节将对比Spark与传统大数据处理框架(如Hadoop)的差异,探讨Spark的优势所在。
## 1.3 Spark的优势和应用场景
我们将深入探讨Spark的优势及其在不同应用场景下的应用,为读者提供全面的了解。
# 2. Apache Spark基础概念
Apache Spark作为一个快速、通用、可扩展的大数据处理引擎,其核心概念是理解Spark的关键。在本章中,我们将深入研究Apache Spark的基础概念,包括Resilient Distributed Dataset (RDD)的介绍、Spark核心概念的解析以及Spark应用程序的基本结构。
### 2.1 Resilient Distributed Dataset (RDD)介绍
在这一部分中,我们将学习RDD的概念、特性和基本操作。我们将探讨RDD的惰性求值特性、弹性容错性以及RDD的创建和转换操作。通过一些实际的代码演示,我们将更好地理解RDD在Spark中的重要性。
### 2.2 Spark核心概念解析
在本节中,我们将介绍Spark的核心概念,包括Spark的任务(Task)、作业(Job)、阶段(Stage)以及任务调度和执行的流程。通过这些核心概念的讲解,我们可以更好地理解Spark应用程序在集群上的执行流程。
### 2.3 Spark应用程序的基本结构
本节将重点介绍Spark应用程序的基本结构和执行流程。我们将讨论Spark应用程序的启动过程、作业的划分和调度、以及应用程序的DAG执行过程。此外,我们还会深入讨论如何通过编程方式构建一个简单的Spark应用程序。
以上是第二章的内容概要,接下来我们将深入探讨每个小节的具体内容,包括代码示例和实际应用场景。
# 3. Apache Spark核心组件
Apache Spark作为一个强大的大数据处理框架,拥有多个核心组件,每个组件都有其独特的功能和用途。在本章中,我们将深入探讨Apache Spark的核心组件,并介绍它们在大数据处理中的作用。
#### 3.1 Spark SQL:结构化数据处理
Spark SQL是Apache Spark用于结构化数据处理的模块,它提供了用于处理结构化数据的接口,并支持SQL查询。通过Spark SQL,用户可以将数据加载为DataFrame,然后执行SQL查询或使用内置的函数进行数据处理。Spark SQL还允许将不同数据源的数据进行集成,如Parquet、JSON、Hive等。
```python
# 示例代码:使用Spark SQL加载数据并执行查询
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder.appName("SparkSQLExample").getOrCreate()
# 加载数据为DataFrame
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# 创建临时视图
df.createOrReplaceTempView("data")
# 执行SQL查询
result = spark.sql("SELECT * FROM data WHERE age > 30")
# 显示查询结果
result.show()
# 停止SparkSession
spark.stop()
```
**代码总结:**
- 通过Spark SQL可以使用SQL语句查询DataFrame中的数据。
- 可以将原始数据加载为DataFrame,并创建临时视图。
- 支持数据集成、数据处理和结果展示。
**结果说明:**
以上代码示例演示了如何使用Spark SQL加载数据并执行SQL查询,筛选出年龄大于30的数据,并显示查询结果。
#### 3.2 Spark Streaming:实时数据处理
Spark Streaming是Apache Spark提供的实时数据处理引擎,可用于实时处理数据流。它支持各种数据源,如Kafka、Flume、HDFS等,可以将实时数据流切割成微批处理,并对每个微批数据进行操作和分析。
```java
// 示例代码:使用Spark Streaming处理实时数据流
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
// 创建Spark配置
SparkConf conf = new SparkConf().setAppName("SparkStreamingExample");
// 创建StreamingContext
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// 从Kafka数据源读取数据流
JavaDStream<String> lines = jssc.textFileStream("hdfs://path/to/directory");
// 处理数据流
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaDStream<String> pairs = words.map(word -> new Tuple2<>(word, 1));
JavaDStream<String> wordCounts = pairs.reduceByKey((v1, v2) -> v1 + v2);
// 输出处理结果
wordCounts.print();
// 启动StreamingContext
jssc.start();
jssc.awaitTermination();
```
**代码总结:**
- Spark Streaming支持实时处理数据流,可以从各种数据源读取数据。
- 可以对实时数据流进行处理、转换和分析。
- 支持输出处理结果和持续运行StreamingContext。
**结果说明:**
以上Java示例代码展示了如何使用Spark Streaming从Kafka数据源读取实时数据流,对数据进行处理并统计词频,最后输出处理结果。
#### 3.3 Spark MLlib:机器学习库介绍
Spark MLlib是Apache Spark提供的机器学习库,包含了各种常用的机器学习算法和工具,如分类、回归、聚类、推荐等。用户可以借助Spark MLlib进行大规模数据的机器学习任务,同时支持特征提取、模型训练、评估和预测等功能。
```scala
// 示例代码:使用Spark MLlib进行分类任务
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.sql.SparkSession
// 创建SparkSession
val spark = SparkSession.builder().appName("SparkMLlibExample").getOrCreate()
// 读取数据为DataFrame
val data = spark.read.format("libsvm").load("data.libsvm")
// 创建逻辑回归模型
val lr = new LogisticRegression()
// 拟合模型
val model = lr.fit(data)
// 打印模型参数
println(s"Coefficients: ${model.coefficients}, Intercept: ${model.intercept}")
// 停止SparkSession
spark.stop()
```
**代码总结:**
- Spark MLlib提供了丰富的机器学习算法和工具。
- 可以轻松应用机器学习算法进行大规模数据的模型训练和预测。
- 支持数据读取、模型构建、拟合和结果展示。
**结果说明:**
以上Scala示例代码展示了如何使用Spark MLlib进行分类任务,读取LibSVM格式数据,构建逻辑回归模型并拟合数据,最后打印模型参数。
#### 3.4 Spark GraphX:图计算引擎简介
Spark GraphX是Apache Spark提供的图计算引擎,用于处理大规模图数据和执行图算法。它提供了图的创建、转换、操作和计算功能,支持图的顶点、边等属性操作,并实现了常见的图算法,如PageRank、连通性组件等。
```python
# 示例代码:使用Spark GraphX执行PageRank算法
from pyspark import SparkContext
from pyspark.graphx import Graph
# 创建SparkContext
sc = SparkContext(appName="SparkGraphXExample")
# 创建图
vertices = sc.parallelize([(1, "Alice"), (2, "Bob"), (3, "Carol")])
edges = sc.parallelize([(1, 2, 0.5), (2, 3, 0.8)])
graph = Graph(vertices, edges)
# 执行PageRank算法
ranks = graph.pageRank(0.85).vertices
# 打印PageRank结果
for (vertex, rank) in ranks.collect():
print(f"Vertex {vertex} has rank: {rank}")
# 关闭SparkContext
sc.stop()
```
**代码总结:**
- Spark GraphX提供了图的创建、操作和常见图算法实现。
- 可以使用GraphX执行图算法,如PageRank、连通性组件等。
- 支持图数据的顶点、边属性操作和结果展示。
**结果说明:**
以上Python示例代码演示了如何使用Spark GraphX创建图数据,执行PageRank算法并打印计算结果。
在本章节中,我们深入介绍了Apache Spark的核心组件,包括Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX,展示了它们在大数据处理中的重要作用和应用场景。希朿这些内容对您有所帮助。
# 4. Apache Spark集群部署与管理
在本章中,我们将深入探讨如何在Apache Spark中进行集群部署与管理,这是使用Spark进行大数据处理的关键步骤之一。
### 4.1 Spark集群部署最佳实践
在本节中,我们将介绍一些Spark集群部署的最佳实践,包括硬件需求、网络配置、节点角色规划等内容。
### 4.2 Spark Standalone集群搭建步骤
我们将逐步介绍如何使用Spark Standalone模式来搭建一个Spark集群,包括master节点和worker节点的配置与启动。
```python
# 以下是一个简单的Python脚本,用于启动Spark Standalone模式的Master节点
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("spark://your-master-ip:7077") \
.appName("SparkMaster") \
.getOrCreate()
# 启动Master节点
spark.stop()
```
### 4.3 Spark集群监控与调优
最后,在本节中,我们将讨论如何监控Spark集群的运行情况,并进行性能调优,以确保集群能够高效稳定地运行。
以上是本章的内容概要,希望能帮助你更好地理解如何在Apache Spark中进行集群部署与管理。
# 5. 使用Spark进行大数据处理
在本章中,我们将介绍如何使用Apache Spark进行大数据处理。大数据处理是Spark最强大的功能之一,Spark提供了丰富的API和工具,方便用户加载、清洗、转换、处理和存储海量数据。
#### 5.1 数据加载和清洗
在大数据处理过程中,首先需要加载数据并进行清洗。Spark支持多种数据源,包括HDFS、S3、Kafka、Cassandra等。下面是一个基本的Python示例,演示如何加载CSV数据,并对数据进行清洗:
```python
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder.appName("data_processing").getOrCreate()
# 读取CSV数据
df = spark.read.csv("data.csv", header=True)
# 数据清洗
cleaned_df = df.na.drop()
cleaned_df.show()
```
**代码说明:**
- 首先,创建SparkSession对象。
- 然后,使用`spark.read.csv()`方法加载CSV数据。
- 调用`na.drop()`方法删除包含空值的行。
- 最后,使用`show()`方法展示清洗后的数据。
#### 5.2 数据转换与处理
一旦数据加载并清洗完毕,接下来是数据转换与处理阶段。Spark提供了丰富的转换和处理函数,如`map`、`filter`、`groupBy`等,方便用户对数据进行各种操作。以下是一个Java示例,展示如何对数据进行简单的转换和处理:
```java
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext("local", "data_processing");
// 读取文本文件
JavaRDD<String> lines = sc.textFile("data.txt");
// 数据转换与处理
JavaRDD<String> filteredLines = lines.filter(line -> line.contains("keyword"));
filteredLines.collect().forEach(System.out::println);
```
**代码说明:**
- 创建JavaSparkContext对象。
- 使用`textFile()`方法读取文本文件。
- 调用`filter()`方法过滤包含特定关键字的行。
- 最后,使用`collect()`和`forEach()`方法输出处理后的数据。
#### 5.3 数据存储与输出
最后,处理完数据后,通常需要将结果存储或输出到外部系统。Spark支持多种数据存储格式和输出方式,如Parquet、JSON、JDBC等。以下是一个Go示例,展示如何将处理后的数据保存为JSON文件:
```go
package main
import (
"github.com/brkyzgn/go-spark"
)
func main() {
// 初始化SparkSession
sparkSession := spark.InitSession()
// 读取数据
df := sparkSession.Read().Json("data.json")
// 数据处理
processedDf := df.Filter(df.Col("column").Eq("value"))
// 存储为JSON文件
sparkSession.Write().Json(processedDf, "output.json")
}
```
**代码说明:**
- 初始化SparkSession对象。
- 使用`Read().Json()`方法读取JSON数据。
- 调用`Filter()`方法对数据进行筛选。
- 最后,使用`Write().Json()`方法将处理后的数据存储为JSON文件。
通过以上步骤,您可以灵活地使用Spark进行大数据处理,包括数据加载、清洗、转换、处理和存储。下一章将介绍如何利用Spark创建更复杂的大数据处理流程。
# 6. 结合实例学习:基于Apache Spark的大数据处理案例
Apache Spark作为一个强大的大数据处理框架,在实际应用中可以帮助我们处理和分析海量数据。本章将通过具体案例来演示如何结合实际场景运用Spark进行大数据处理,并展示如何利用Spark来解决实际业务问题。
#### 6.1 利用Spark进行数据分析与可视化
在这个案例中,我们将使用Apache Spark来进行数据分析和可视化,以帮助我们深入了解所处理的数据。我们将从数据的加载开始,经过清洗和转换,最终以可视化的方式展示分析结果。
```python
# 导入Spark相关模块
from pyspark.sql import SparkSession
# 创建Spark会话
spark = SparkSession.builder.appName("data_analysis").getOrCreate()
# 读取数据
data = spark.read.csv("data.csv", header=True)
# 数据清洗
cleaned_data = data.dropna()
# 数据分析
analysis_result = cleaned_data.groupBy("category").count()
# 可视化展示
analysis_result.show()
```
**代码总结:**
- 我们首先创建了Spark会话,并读取了数据文件。
- 然后进行了数据清洗,删除了缺失值。
- 接着进行数据分组统计,并展示了分析结果。
**结果说明:**
通过对数据的分析,我们可以清晰地看到各个类别的数据数量,从而更好地了解数据的分布情况。
#### 6.2 实现实时数据处理与监控
在此案例中,我们将展示如何利用Spark Streaming模块来实现实时数据处理和监控,以便及时响应数据变化。
```java
// 导入Spark相关模块
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
// 创建Spark Streaming上下文
SparkConf conf = new SparkConf().setAppName("real_time_processing");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(10));
// 从Kafka读取实时数据
JavaDStream<String> lines = jssc.socketTextStream("localhost", 9999);
// 实时数据处理
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey(Integer::sum);
// 监控处理结果
wordCounts.print();
```
**代码总结:**
- 我们创建了Spark Streaming上下文,并从Kafka中读取实时数据流。
- 对数据进行了分词处理,并统计词频。
- 最后监控并打印处理结果。
**结果说明:**
通过实时数据处理与监控,我们可以及时了解数据流的内容和变化情况,有助于实时决策和应对。
#### 6.3 构建基于机器学习的Spark应用
在这个案例中,我们将演示如何利用Spark MLlib库来构建一个简单的机器学习应用,以实现数据分类任务。
```scala
// 导入Spark相关模块
import org.apache.spark.ml.classification.RandomForestClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
// 加载数据
val data = spark.read.format("libsvm").load("data.libsvm")
// 划分数据集
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
// 训练模型
val rf = new RandomForestClassifier()
val model = rf.fit(trainingData)
// 预测
val predictions = model.transform(testData)
// 评估模型
val evaluator = new MulticlassClassificationEvaluator()
val accuracy = evaluator.evaluate(predictions)
println(s"Test Error = ${(1.0 - accuracy)}")
```
**代码总结:**
- 我们首先加载数据,并将其划分为训练集和测试集。
- 然后使用随机森林分类器训练模型,并对测试集进行预测。
- 最后通过评估器计算模型准确率。
**结果说明:**
通过机器学习模型的构建和评估,我们可以得到模型的预测准确率,从而判断模型的性能和有效性。
以上就是基于Apache Spark的大数据处理案例的示例,展示了如何在实陃场景中运用Spark进行数据分析、实时处理和机器学习任务。希望这些案例可以帮助您更好地理解和应用Spark框架。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏“Apache Spark数据处理”涵盖了广泛的主题,旨在帮助读者深入了解和掌握Apache Spark在大数据处理领域的各种应用。从入门指南到高级技术,专栏内容包括对Resilient Distributed Datasets(RDD)的深入讨论、Spark SQL的结构化数据处理、DataFrame API的实用技巧、以及流式处理和实时数据分析等方面的实操指导。此外,还介绍了构建推荐系统、处理图数据、进行聚合分析、性能优化等内容,并探讨了与Hadoop、Kafka、Hive等技术的集成应用。同时,专栏还涉及数据安全、隐私保护、机器学习模型优化以及文本挖掘等高级话题,旨在帮助读者构建实时大数据处理应用、数据仓库与分析平台等解决方案。通过本专栏,读者将获得全面的Apache Spark数据处理知识,从而在大数据领域取得更多的成功。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
5G NR信号传输突破:SRS与CSI-RS差异的实战应用
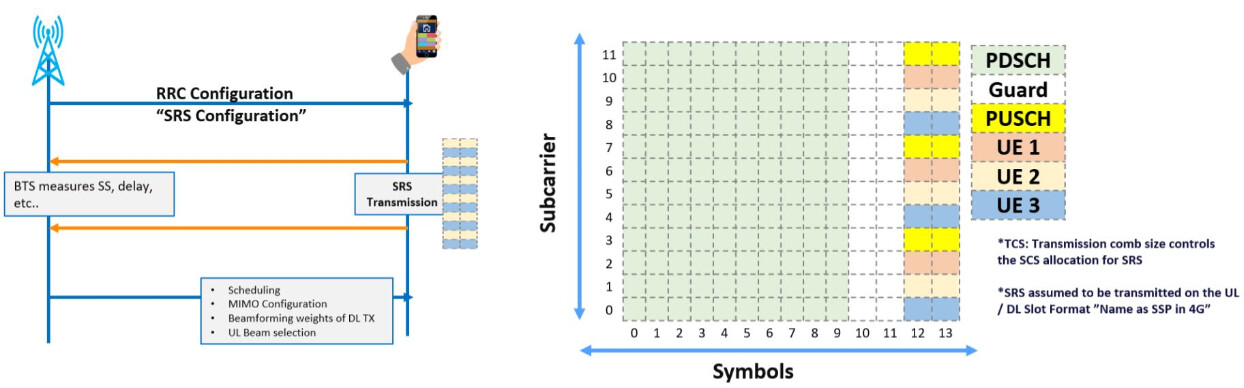
# 摘要
本文深入探讨了5G NR信号传输中SRS信号和CSI-RS信号的理论基础、实现方式以及在5G网络中的应用。首先介绍了SRS信号的定义、作用以及配置和传输方法,并探讨了其优化策略。随后,文章转向CSI-RS信号,详细阐述了其定义、作用、配置与传输,并分析了优化技术。接着,本文通过实际案例展示了SRS和CSI-RS在5G N
【性能分析】:水下机器人组装计划:性能测试与提升的实用技巧
# 摘要
水下机器人作为探索海洋环境的重要工具,其性能分析与优化是当前研究的热点。本文首先介绍了水下机器人性能分析的基础知识,随后详细探讨了性能测试的方法,包括测试环境的搭建、性能测试指标的确定、数据收集与分析技术。在组装与优化方面,文章分析了组件选择、系统集成、调试过程以及性能提升的实践技巧。案例研究部分通过具体实例,探讨了速度、能源效率和任务执行可靠性的
【性能基准测试】:ILI9881C与其他显示IC的对比分析

# 摘要
随着显示技术的迅速发展,性能基准测试已成为评估显示IC(集成电路)性能的关键工具。本文首先介绍性能基准测试的基础知识和显示IC的概念。接着,详细探讨了显示IC性能基准测试的理论基础,包括性能指标解读、测试环境与工具选择以及测试方法论。第三章专注于ILI
从零到英雄:MAX 10 LVDS IO电路设计与高速接口打造

# 摘要
本文主要探讨了MAX 10 FPGA在实现LVDS IO电路设计方面的应用和优化。首先介绍了LVDS技术的基础知识、特性及其在高速接口中的优势和应用场景。随后,文章深入解析了MAX 10器件的特性以及在设计LVDS IO电路时的前期准备、实现过程和布线策略。在高速接口设计与优化部分,本文着重阐述了信号完整性、仿真分析以及测试验证的关键步骤和问题解决方法。最
【群播技术深度解读】:工控机批量安装中的5大关键作用

# 摘要
群播技术作为高效的网络通信手段,在工控机批量安装领域具有显著的应用价值。本文旨在探讨群播技术的基础理论、在工控机批量安装中的实际应用以及优化策略。文章首先对群播技术的原理进行解析,并阐述其在工控机环境中的优势。接着,文章详细介绍了工控机批量安装前期准备、群播技术实施步骤及效果评估与优化。深入分析了多层网络架构中群播的实施细节,以及在保证安全性和可靠性的同时,群播技术与现代工控机发展
Twincat 3项目实战:跟随5个案例,构建高效的人机界面系统
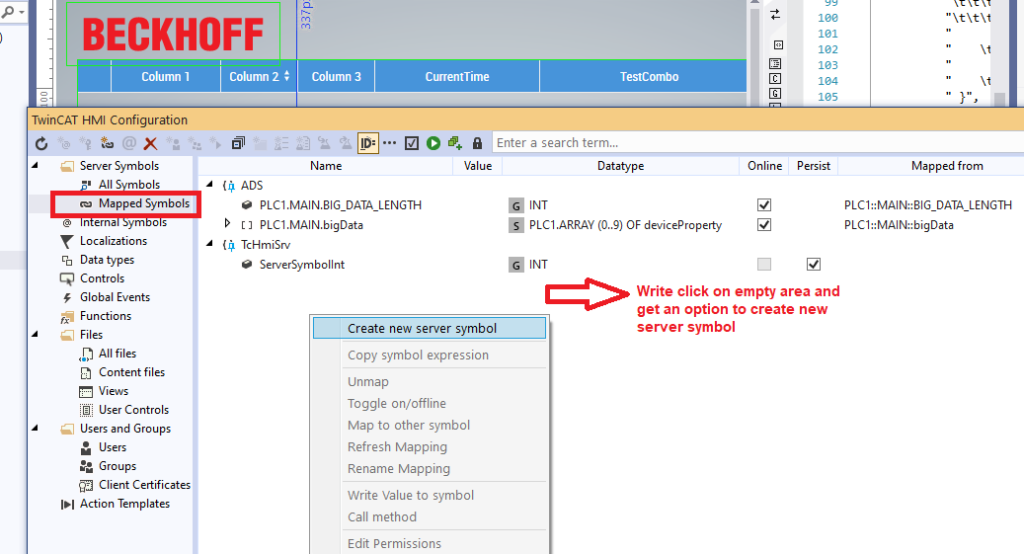
# 摘要
本论文提供了一个全面的Twincat 3项目实战概览,涵盖了从基础环境搭建到人机界面(HMI)设计,再到自动化案例实践以及性能优化与故障诊断的全过程。文章详细介绍了硬件选择、软件配置、界面设计原则、功能模块实现等关键步骤,并通过案例分析,探讨了简单与复杂自动化项目的设计与执行。最后,针对系统性能监测、优化和故障排查,提出了实用的策略和解决方案,并
【MT2492降压转换器新手必读】:快速掌握0到1的使用技巧与最佳实践

# 摘要
本文全面介绍了MT2492降压转换器的设计、理论基础、实践操作、性能优化以及最佳实践应用。首先,本文对MT2492进行了基本介绍,阐释了其工作原理和主要参数。接着,详细解析了硬件接线和软件编程的相关步骤和要点。然后,重点讨论了性能优化策略,包括热管理和故障诊断处理。最后,本文提供了MT2492在不同应用场景中的案例分析,强调了其在电
【水务行业大模型指南】:现状剖析及面临的挑战与机遇
# 摘要
本论文对水务行业的现状及其面临的数据特性挑战进行了全面分析,并探讨了大数据技术、机器学习与深度学习模型在水务行业中的应用基础与实践挑战。通过分析水质监测、水资源管理和污水处理等应用场景下的模型应用案例,本文还着重讨论了模型构建、优化算法和模型泛化能力等关键问题。最后,展望了水务行业大模型未来的技术发展趋势、政策环境机遇,以及大模型在促进可持续发展中的潜在作用。
# 关键字
水务行业;大数据技术;机器学习
SoMachine V4.1与M241的协同工作:综合应用与技巧
# 摘要
本文介绍了SoMachine V4.1的基础知识、M241控制器的集成过程、高级应用技巧、实践应用案例以及故障排除和性能调优方法。同时,探讨了未来在工业4.0和智能工厂融合背景下,SoMachine V4.1与新兴技术整合的可能性,并讨论了教育和社区资源拓展的重要性。通过对SoMachine V4.1和M241控制器的深入分析,文章旨在为工业自动化领域提供实用的实施策略和优化建议,确保系统的高效运行和可靠控
【Cadence Virtuoso热分析技巧】:散热设计与热效应管理,轻松搞定
# 摘要
随着集成电路技术的快速发展,热分析在电子设计中的重要性日益增加。本文系统地介绍了Cadence Virtuoso在热分析方面的基础理论与应用,涵盖了散热设计、热效应管理的策略与技术以及高级应用。通过对热传导、对流、辐射等基础知识的探讨,本文详细分析了散热路径优化、散热材料选择以及热仿真软件的使用等关键技术,并结合电源模块、SoC和激光二极管模块的实践案例进行了深入研究。文章还探讨了多物理场耦合分析、高效热分析流程的建立以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )