GraphX图计算引擎:在Apache Spark中处理图数据
发布时间: 2024-02-23 13:12:14 阅读量: 55 订阅数: 22 
# 1. 介绍GraphX图计算引擎
## 1.1 图计算引擎的定义和作用
图计算引擎是一种用于处理大规模图数据的计算框架,其作用是实现图数据的存储、处理和分析,可以用于解决复杂的图结构数据分析和挖掘问题。
## 1.2 GraphX在Apache Spark中的定位和优势
GraphX是Apache Spark中的图计算引擎模块,借助Spark的分布式计算能力,GraphX能够高效地处理大规模图数据,并且具有良好的容错性和扩展性。
GraphX的优势包括:
- 支持大规模图数据的并行处理和分布式计算
- 结合了图计算和机器学习功能,可以进行复杂的图数据分析和模型建立
- 具有丰富的API和算法库,方便用户进行图数据处理和分析
## 1.3 使用场景和应用范围
GraphX广泛应用于各种领域,包括社交网络分析、金融风险控制、网络安全监测、推荐系统等,适用于需要处理大规模图数据的场景和问题。GraphX的强大功能和灵活性使其成为大数据领域图计算的重要工具之一。
# 2. GraphX图计算引擎的核心功能
GraphX图计算引擎是建立在分布式数据处理框架Apache Spark之上的,其核心功能包括顶点和边的表示、API和数据模型、数据分布和存储策略等。接下来我们将详细介绍GraphX图计算引擎的核心功能。
### 2.1 顶点(Vertex)和边(Edge)的表示
在GraphX中,顶点可以被表示为包含唯一标识符和属性的数据结构,边可以被表示为连接两个顶点的带有属性的有向边。这种表示方式使得图结构可以方便地被分布式存储和处理。
```python
# Python代码示例
from pyspark import SparkContext
from pyspark.sql import SQLContext
from graphframes import GraphFrame
# 创建顶点DataFrame
v = sqlContext.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
# 创建边DataFrame
e = sqlContext.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
# 创建图
g = GraphFrame(v, e)
```
在上面的Python代码示例中,我们使用了Spark的`GraphFrame`库来创建顶点和边的表示,其中`v`和`e`分别表示顶点和边的DataFrame,`g`为创建的图。
### 2.2 图计算引擎的API和数据模型
GraphX提供了丰富的API和数据模型来对图进行操作和计算,例如顶点和边的属性查询、图的联接和过滤、图计算算法(如PageRank、社区检测算法等)等,开发者可以根据具体的需求选择适当的API进行操作和计算。
```java
// Java代码示例
import org.apache.spark.graphx.Graph;
import org.apache.spark.graphx.VertexRDD;
import org.apache.spark.graphx.util.GraphGenerators;
import org.apache.spark.graphx.lib.PageRank;
import org.apache.spark.graphx.lib.ConnectedComponents;
// 创建顶点和边
VertexRDD<Object> vertexRDD = ...;
EdgeRDD<Object> edgeRDD = ...;
// 创建图
Graph<Object, Object> graph = Graph.apply(vertexRDD, edgeRDD, ...);
// 运行PageRank算法
Graph<Object, Object> ranks = PageRank.run(graph, 5);
// 运行ConnectedComponents算法
Graph<Object, Object> components = ConnectedComponents.run(graph);
```
在上面的Java代码示例中,我们使用了Spark的`GraphX`库来创建图的表示,并且调用了PageRank和ConnectedComponents算法进行计算。
### 2.3 数据分布和存储策略
在分布式环境下,图的数据分布和存储是一个重要的问题,GraphX通过合理的数据分区和存储策略来优化图的计算性能。通常情况下,顶点和边的数据会被分布式存储在不同的节点上,并且可以通过分布式计算框架来进行计算和处理。
```go
// Go代码示例
import "github.com/Shopify/sarama"
// 使用Sarama库来创建Kafka生产者
producer, err := sarama.NewSyncProducer([]string{"kafka-broker1:9092", "kafka-broker2:9092"}, nil)
if err != nil {
panic(err)
}
defer producer.Close()
// 发送消息
msg := &sarama.ProducerMessage{Topic: "my-topic", Value: sarama.StringEncoder("hello, world")}
partition, offset, err := producer.SendMessage(msg)
if err != nil
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏“Apache Spark数据处理”涵盖了广泛的主题,旨在帮助读者深入了解和掌握Apache Spark在大数据处理领域的各种应用。从入门指南到高级技术,专栏内容包括对Resilient Distributed Datasets(RDD)的深入讨论、Spark SQL的结构化数据处理、DataFrame API的实用技巧、以及流式处理和实时数据分析等方面的实操指导。此外,还介绍了构建推荐系统、处理图数据、进行聚合分析、性能优化等内容,并探讨了与Hadoop、Kafka、Hive等技术的集成应用。同时,专栏还涉及数据安全、隐私保护、机器学习模型优化以及文本挖掘等高级话题,旨在帮助读者构建实时大数据处理应用、数据仓库与分析平台等解决方案。通过本专栏,读者将获得全面的Apache Spark数据处理知识,从而在大数据领域取得更多的成功。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
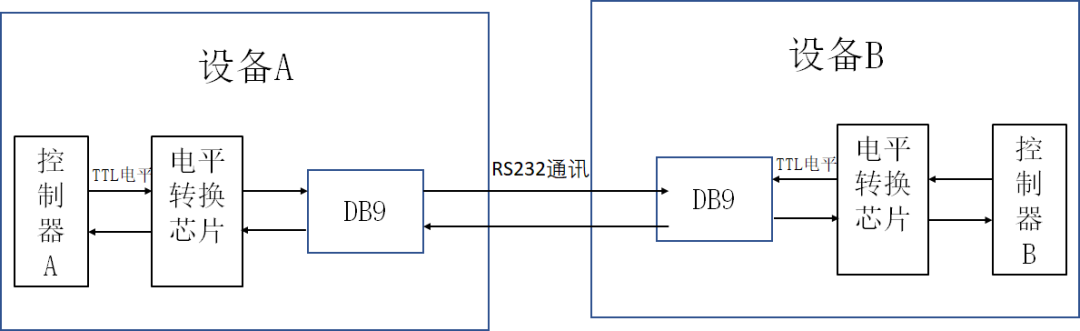
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )