Tornado的请求与响应处理:实现简单的HTTP服务器
发布时间: 2024-02-14 01:39:03 阅读量: 13 订阅数: 12 
# 1. 简介
### 1.1 什么是Tornado?
Tornado是一个Python Web框架和异步网络库,最初由FriendFeed开发,用于处理其实时服务的请求。它具有高效的非阻塞IO,可扩展性强和易于使用的特点。
### 1.2 HTTP服务器的基本概念
HTTP服务器是指能够处理和响应HTTP请求的服务器程序。它通过监听特定的网络端口,接收HTTP请求,并返回相应的HTTP响应,以此实现网络服务的提供。
### 1.3 为什么选择Tornado?
- 高性能:Tornado基于非阻塞IO和事件循环机制,适用于高并发的网络应用场景。
- 异步编程:Tornado使用异步编程模型,提供了协程和回调等方式,方便编写高效的异步代码。
- Web框架:Tornado内置了Web框架,支持URL路由、模板引擎等功能,使得开发Web应用更加便捷。
以上是Tornado简介及HTTP服务器基本概念的内容,接下来是Tornado的基本架构。
# 2. Tornado的基本架构
Tornado是一个基于Python的开源Web框架,它的设计目标是高性能和异步IO。下面我们将介绍Tornado的基本架构,包括单线程与多线程模式、IO循环与非阻塞的特性以及异步编程模型。
### 2.1 单线程与多线程模式
Tornado的服务器可以以单线程或者多线程的方式运行。在单线程模式下,所有的请求都由一个线程处理,这样可以避免多线程带来的锁竞争和线程切换开销,提高了整体性能。而在多线程模式下,可以同时处理多个请求,但需要注意线程安全性。
### 2.2 IO循环与非阻塞的特性
Tornado的核心是其IO循环,它采用了非阻塞的方式处理IO操作,提高了系统的并发能力。当一个请求到达时,Tornado会将其注册到IO循环中,并立即返回,不会阻塞其他请求的处理。当IO操作完成后,IO循环会通知请求的处理函数进行下一步处理。
### 2.3 异步编程模型
Tornado使用异步编程模型来处理IO操作。在传统的同步编程模型中,当一个IO操作发起时,程序会等待操作完成才继续执行下一步。而在异步编程模型中,程序会立即返回并注册一个回调函数,当IO操作完成后,会调用相应的回调函数进行处理。这种模型可以提高系统的并发性能,避免了线程等待的开销。
总结:Tornado的基本架构采用了单线程或者多线程模式,使用非阻塞的IO循环来处理请求,同时采用异步编程模型来处理IO操作。这些设计使得Tornado具有高性能和高并发的特性。下一节我们将介绍Tornado的请求处理过程。
# 3. Tornado的请求处理
在Tornado中,请求处理是指服务器接收到客户端发送的HTTP请求后,如何处理和响应。Tornado提供了灵活的请求处理机制,可以帮助开发者轻松地编写和管理各种类型的请求。
#### 3.1 URL路由与请求分发
URL路由是指根据不同的URL路径,将请求分发给不同的处理函数。在Tornado中,可以通过定义一个URL映射表来实现路由功能。下面是一个示例:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上述代码中,我们定义了一个`MainHandler`类作为请求处理函数,当客户端发起GET请求时,会调用`MainHandler`类的`get`方法,并返回`Hello, Tornado!`。
在`make_app`函数中,我们创建了一个`Application`实例,并将URL映射表传递给它。其中`(r"/", MainHandler)`表示将根路径`/`映射到`MainHandler`类。
最后,通过`app.listen(8888)`指定服务器监听的端口为8888,并通过`IOLoop`启动服务器。
#### 3.2 处理请求参数与文件上传
Tornado提供了丰富的方法来处理HTTP请求中的参数和文件上传。
**处理请求参数**
当客户端提交表单数据或发送GET请求时,可以通过Tornado的`RequestHandler`类的一些方法来获取请求参数。例如,可以使用`get_argument`方法来获取URL中的参数,使用`get_body_argument`方法来获取POST请求中的参数,如下所示:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
name = self.get_argument("name")
age = self.get_argument("age")
self.write("Name: {} Age: {}".format(name, age))
def post(self):
name = self.get_body_argument("name")
age = self.get_body_argument("age")
self.write("Name: {} Age: {}".format(name, age))
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上述代码中,当客户端发送GET请求时,可以通过`self.get_argument`方法获取URL中`name`和`age`参数的值。当客户端发送POST请求时,可以通过`self.get_body_argument`方法获取POST请求体中的`name`和`age`参数。
**处理文件上传**
除了处理参数外,Tornado还提供了处理文件上传的功能。可以通过`get_file`或`get_body_files`方法来获取客户端上传的文件。
```python
import tornado.ioloop
import tornado.web
class UploadHandler(tornado.web.RequestHandler):
def post(self):
file = self.request.files.get("file")
if file:
filename = file[0]["filename"]
body = file[0]["body"]
with open(filename, "wb") as f:
f.write(body)
self.write("File uploaded successfully!")
def make_app():
return tornado.web.Application([
(r"/upload", UploadHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上述代码中,我们定义了一个`UploadHandler`类作为文件上传的处理函数。当客户端发送包含文件上传的POST请求时,可以通过`self.request.files`来获取上传的文件,然后可以通过操作文件的内容进行进一步处理。
#### 3.3 Cookie与Session管理
Tornado提供了方便的Cookie和Session管理功能。
**Cookie管理**
可以使用`set_cookie`和`get_cookie`方法来设置和获取Cookie。例如:
```python
impo
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Lucky带你玩转高并发Tornado框架实战与优化》是一本致力于帮助读者深入理解和灵活运用Tornado框架的实用指南。从快速入门指南到核心理念的解读,再到事件循环、协程与生成器的实践应用,涵盖了Tornado框架中各个重要的知识点。通过专栏,读者将深入了解Tornado框架下的HTTP服务器搭建、模板引擎运用、表单验证、静态文件处理、WebSocket支持、消息队列、缓存优化、数据库操作和日志记录等内容,并且了解如何保障应用程序的安全性。专栏具有丰富的实例和案例,旨在帮助读者快速上手并掌握Tornado框架的实战技巧与性能优化方法,从而使他们能够更好地应对高并发环境下的挑战。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
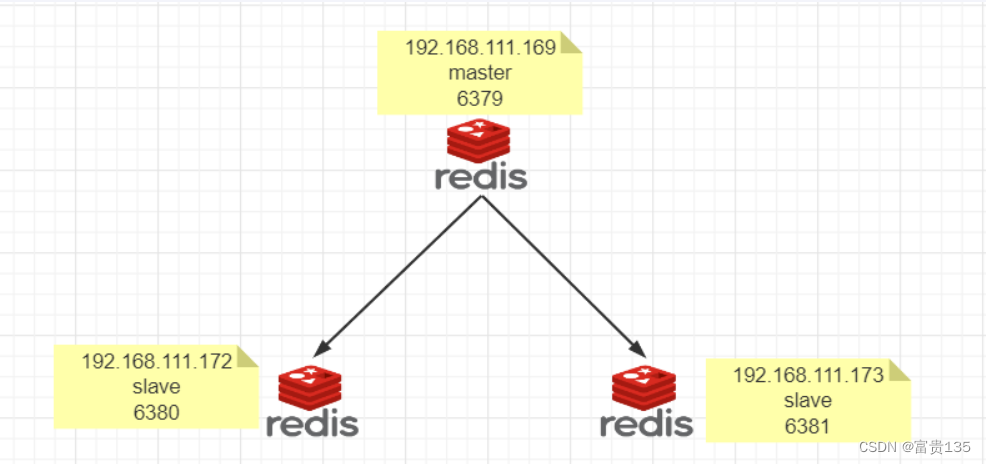
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
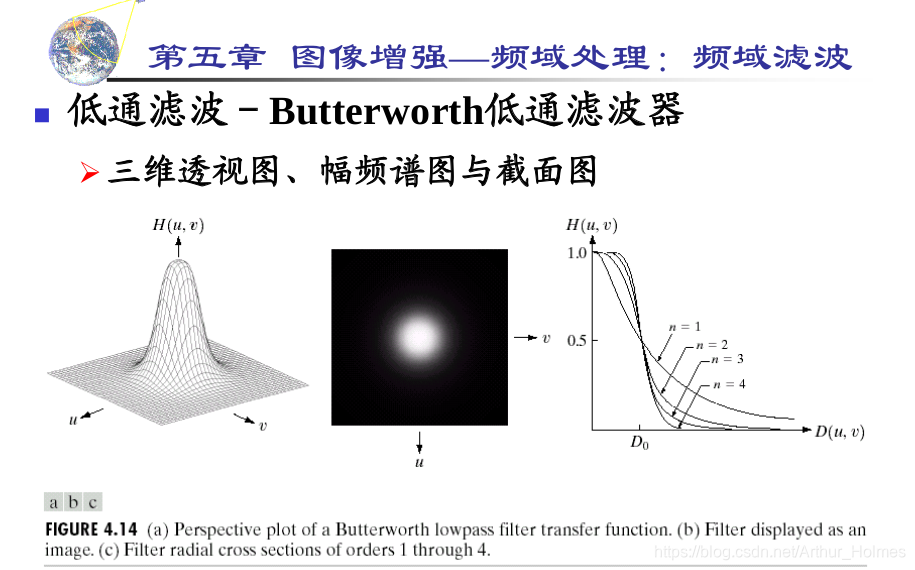
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )