OCR识别中的后处理技术:锦上添花,提升识别效果
发布时间: 2024-08-11 19:47:26 阅读量: 97 订阅数: 26 
# 1. OCR识别技术概述**
光学字符识别(OCR)是一种将图像中的文字转换为可编辑文本的技术。OCR技术广泛应用于各种领域,如文档处理、身份验证和数据提取。
OCR识别过程主要分为三个步骤:图像预处理、特征提取和字符识别。图像预处理旨在增强图像质量,去除噪声和干扰。特征提取阶段提取图像中与字符相关的特征,如形状、边缘和纹理。最后,字符识别阶段将提取的特征与已知的字符模板进行匹配,识别出图像中的字符。
# 2. OCR后处理技术
OCR后处理技术是OCR识别流程中至关重要的一环,它通过对原始识别结果进行一系列优化和修正,大幅提升最终识别的准确性和可读性。本章将深入探讨OCR后处理技术的原理、方法和实践,为读者提供全面深入的理解。
### 2.1 图像增强
图像增强是OCR后处理技术的首要步骤,其目的是改善原始图像的质量,为后续的文本分割和识别提供更清晰的基础。常见的图像增强技术包括去噪和二值化。
#### 2.1.1 去噪
去噪旨在消除图像中的噪声,如椒盐噪声、高斯噪声和运动模糊。噪声会干扰文本的识别,因此去除噪声对于提高识别准确性至关重要。常用的去噪算法包括中值滤波、高斯滤波和双边滤波。
```python
import cv2
# 使用中值滤波去噪
image = cv2.imread('noisy_image.jpg')
denoised_image = cv2.medianBlur(image, 5)
# 使用高斯滤波去噪
image = cv2.imread('noisy_image.jpg')
denoised_image = cv2.GaussianBlur(image, (5, 5), 0)
```
#### 2.1.2 二值化
二值化将图像转换为黑白两色图像,其中文本区域为黑色,背景为白色。二值化可以简化后续的文本分割和识别过程。常用的二值化算法包括Otsu算法、Sobel算子和Canny算子。
```python
import cv2
# 使用Otsu算法二值化
image = cv2.imread('gray_image.jpg')
thresh, binary_image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY_OTSU)
# 使用Sobel算子二值化
image = cv2.imread('gray_image.jpg')
sobelx = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=5)
sobely = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=5)
binary_image = cv2.bitwise_or(sobelx, sobely)
```
### 2.2 文本分割
文本分割将图像中的文本区域划分为行和字,为后续的文本识别做准备。文本分割算法通常基于连通域分析和形态学操作。
#### 2.2.1 行分割
行分割将图像中的文本行从上到下依次分割出来。常用的行分割算法包括投影法、连通域分析和基于深度学习的方法。
```python
import cv2
# 使用投影法行分割
image = cv2.imread('text_image.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
horizontal_projection = cv2.reduce(gray_image, 1, cv2.REDUCE_SUM)
line_positions = []
for i in range(len(horizontal_projection)):
if horizontal_projection[i] > 0:
line_positions.append(i)
```
#### 2.2.2 字分割
字分割将文本行中的字从左到右依次分割出来。常用的字分割算法包括连通域分析、形态学操作和基于深度学习的方法。
```python
import cv2
# 使用连通域分析字分割
image = cv2.imread('text_image.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY_OTSU)
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
word_positions = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
word_positions.append((x, y, w, h))
```
### 2.3 文本校正
文本校正旨在纠正OCR识别过程中出现的错误,提高识别的准确性。常见的文本校正技术包括拼写检查和语法检查。
#### 2.3.1 拼写检查
拼写检查通过与词典进行比较来识别和纠正拼写错误。常用的拼写检查算法包括哈希表法、编辑距离法和基于语言模型的方法。
```python
import enchant
# 使用哈希表法拼写检查
dictionary = enchant.Dict("en_US")
word = "teh"
if not dictionary.check(word):
suggestions = dictionary.suggest(word)
```
#### 2.3.2 语法检查
语法检查通过分析文本的语法结构来识别和纠正语法错误。常用的语法检查算法包括规则匹配法、依存关系分析法和基于语言模型的方法。
```python
import language_tool_python
# 使用依存关系分析法语法检查
text = "The cat is on the table."
tool = language_tool_python.LanguageTool("en-US")
matches = tool.check(text)
for match in matches:
print(match.message)
```
# 3. OCR后处理技术实践

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 OpenCV 在文档扫描和 OCR 识别中的应用,从基础知识到高级技术,为您提供全面的指南。您将了解图像预处理、深度学习、图像分割、增强和降噪等关键技术,以及它们在提升 OCR 精度中的作用。此外,专栏还介绍了 OCR 识别算法、特征提取、后处理技术和创新应用,帮助您打造高效且准确的 OCR 系统。通过实战项目和性能优化策略,您将掌握 OpenCV 在文档扫描 OCR 识别中的实际应用,并了解如何应对海量文档处理的挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单高级应用

# 摘要
扇形菜单作为一种创新的用户界面设计方式,近年来在多个应用领域中显示出其独特优势。本文概述了扇形菜单设计的基本概念和理论基础,深入探讨了其用户交互设计原则和布局算法,并介绍了其在移动端、Web应用和数据可视化中的应用案例
C++ Builder高级特性揭秘:探索模板、STL与泛型编程

# 摘要
本文系统性地介绍了C++ Builder的开发环境设置、模板编程、标准模板库(STL)以及泛型编程的实践与技巧。首先,文章提供了C++ Builder的简介和开发环境的配置指导。接着,深入探讨了C++模板编程的基础知识和高级特性,包括模板的特化、非类型模板参数以及模板
【深入PID调节器】:掌握自动控制原理,实现系统性能最大化

# 摘要
PID调节器是一种广泛应用于工业控制系统中的反馈控制器,它通过比例(P)、积分(I)和微分(D)三种控制作用的组合来调节系统的输出,以实现对被控对象的精确控制。本文详细阐述了PID调节器的概念、组成以及工作原理,并深入探讨了PID参数调整的多种方法和技巧。通过应用实例分析,本文展示了PID调节器在工业过程控制中的实际应用,并讨
【Delphi进阶高手】:动态更新百分比进度条的5个最佳实践

# 摘要
本文针对动态更新进度条在软件开发中的应用进行了深入研究。首先,概述了进度条的基础知识,然后详细分析了在Delphi环境下进度条组件的实现原理、动态更新机制以及多线程同步技术。进一步,文章探讨了数据处理、用户界面响应性优化和状态视觉呈现的实践技巧,并提出了进度
【TongWeb7架构深度剖析】:架构原理与组件功能全面详解
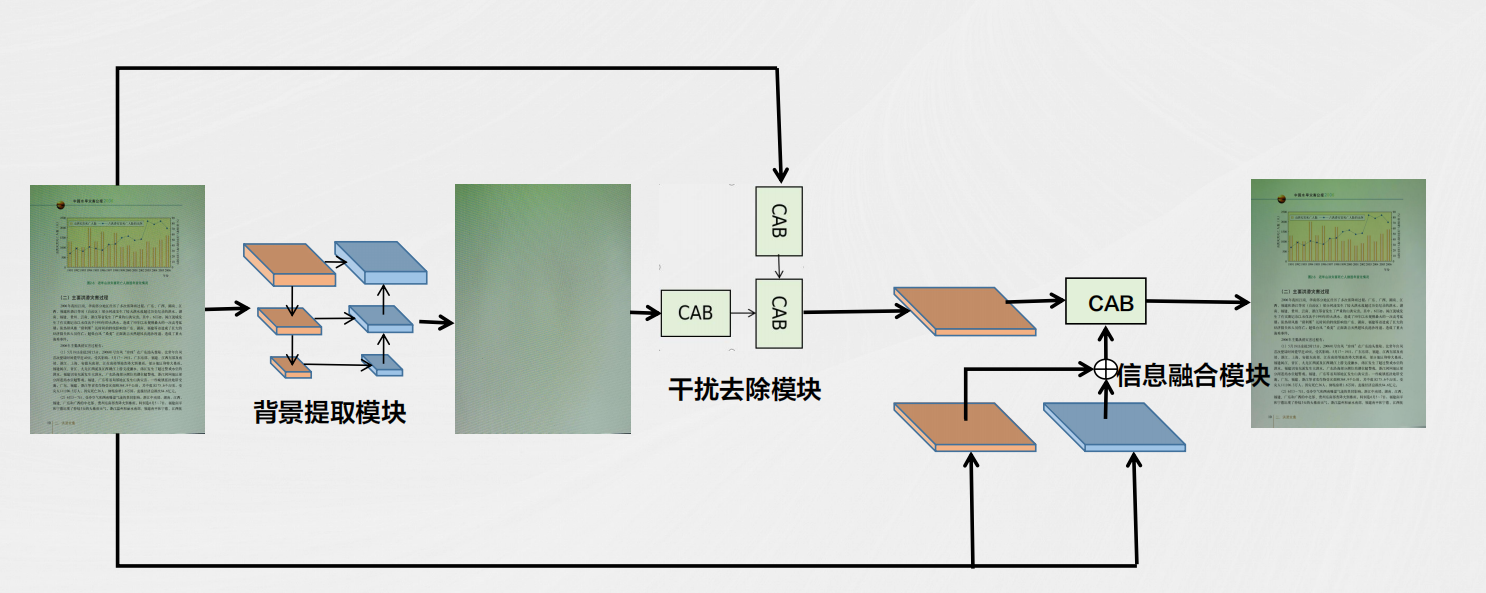
# 摘要
TongWeb7作为一个复杂的网络应用服务器,其架构设计、核心组件解析、性能优化、安全性机制以及扩展性讨论是本文的主要内容。本文首先对TongWeb7的架构进行了概述,然后详细分析了其核心中间件组件的功能与特点,接着探讨了如何优化性能监控与分析、负载均衡、缓存策略等方面,以及安全性机制中的认证授权、数据加密和安全策略实施。最后,本文展望
【S参数秘籍解锁】:掌握驻波比与S参数的终极关系
# 摘要
本论文详细阐述了驻波比与S参数的基础理论及其在微波网络中的应用,深入解析了S参数的物理意义、特性、计算方法以及在电路设计中的实践应用。通过分析S参数矩阵的构建原理、测量技术及仿真验证,探讨了S参数在放大器、滤波器设计及阻抗匹配中的重要性。同时,本文还介绍了驻波比的测量、优化策略及其与S参数的互动关系。最后,论文探讨了S参数分析工具的使用、高级分析技巧,并展望
【嵌入式系统功耗优化】:JESD209-5B的终极应用技巧
# 摘要
本文首先概述了嵌入式系统功耗优化的基本情况,随后深入解析了JESD209-5B标准,重点探讨了该标准的框架、核心规范、低功耗技术及实现细节。接着,本文奠定了功耗优化的理论基础,包括功耗的来源、分类、测量技术以及系统级功耗优化理论。进一步,本文通过实践案例深入分析了针对JESD209-5B标准的硬件和软件优化实践,以及不同应用场景下的功耗优化分析。最后,展望了未来嵌入式系统功耗优化的趋势,包括新兴技术的应用、JESD209-5B标准的发展以及绿色计算与可持续发展的结合,探讨了这些因素如何对未来的功耗优化技术产生影响。
# 关键字
嵌入式系统;功耗优化;JESD209-5B标准;低功耗
ODU flex接口的全面解析:如何在现代网络中最大化其潜力
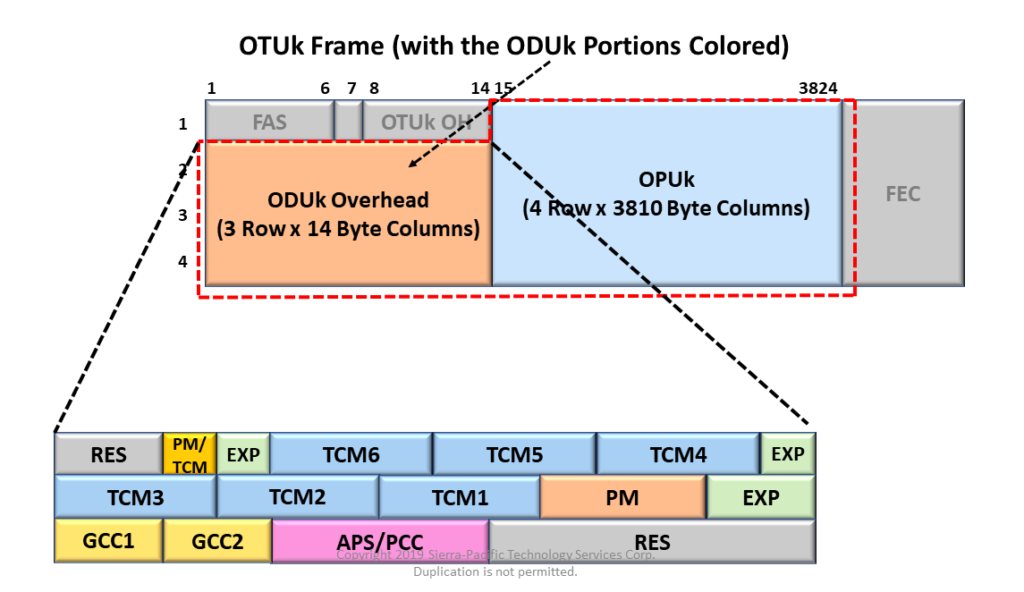
# 摘要
ODU flex接口作为一种高度灵活且可扩展的光传输技术,已经成为现代网络架构优化和电信网络升级的重要组成部分。本文首先概述了ODU flex接口的基本概念和物理层特征,紧接着深入分析了其协议栈和同步机制,揭示了其在数据中心、电信网络、广域网及光纤网络中的应用优势和性能特点。文章进一步
如何最大化先锋SC-LX59的潜力
# 摘要
先锋SC-LX59作为一款高端家庭影院接收器,其在音视频性能、用户体验、网络功能和扩展性方面均展现出巨大的潜力。本文首先概述了SC-LX59的基本特点和市场潜力,随后深入探讨了其设置与配置的最佳实践,包括用户界面的个性化和音画效果的调整,连接选项与设备兼容性,以及系统性能的调校。第三章着重于先锋SC-LX59在家庭影院中的应用,特别强调了音视频极致体验、智能家居集成和流媒体服务的充分利用。在高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )