OCR技术赋能文档扫描:应用与实践指南
发布时间: 2024-08-11 19:10:02 阅读量: 48 订阅数: 49 

人工智能赋能网络空间安全:模式与实践 .pdf

# 1. OCR技术概述
光学字符识别(OCR)技术是一种将图像中的文字信息转换为可编辑文本格式的技术。它广泛应用于各种领域,如文档处理、图像分析和身份验证。OCR技术通过以下步骤实现:
- **图像采集:**使用扫描仪或相机获取文档或图像的数字图像。
- **预处理:**对图像进行预处理,包括降噪、二值化和字符分割。
- **特征提取:**从字符图像中提取特征,如形状、纹理和边缘。
- **模式识别:**使用机器学习算法将提取的特征与已知的字符模式进行匹配。
- **文本生成:**将识别的字符组合成可编辑的文本格式。
# 2. OCR技术原理与应用
### 2.1 OCR技术原理
OCR技术的基本原理是将图像中的文字信息转换为可编辑的文本格式。其主要步骤包括:
1. **图像预处理:**对图像进行预处理,包括去噪、二值化、倾斜校正等,以提高图像质量和文本清晰度。
2. **字符分割:**将图像中的文本区域分割成单个字符。
3. **特征提取:**从每个字符中提取特征,如笔画、形状、纹理等,以区分不同的字符。
4. **字符识别:**利用提取的特征,通过模式识别算法将字符与已知字符库进行匹配,识别出每个字符。
5. **文本还原:**将识别的字符组合成单词和句子,还原为可编辑的文本格式。
### 2.2 OCR技术应用场景
OCR技术广泛应用于各种领域,包括:
- **文档处理:**扫描纸质文档、识别和提取文本内容,实现文档数字化和电子化。
- **图像识别:**从图像中识别文字信息,如交通标志、产品包装上的文字等。
- **身份验证:**识别身份证、护照等证件上的文字信息,用于身份验证和防伪。
- **医疗影像:**识别医疗影像中的文字信息,如病历、处方等,辅助医疗诊断和决策。
- **语言翻译:**识别外语文本,并将其翻译成目标语言。
#### 代码示例:
```python
import cv2
import pytesseract
# 图像预处理
image = cv2.imread('image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# 字符分割
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
chars = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
chars.append(thresh[y:y+h, x:x+w])
# 特征提取和字符识别
text = ''
for char in chars:
char = cv2.resize(char, (20, 20))
features = cv2.HOGDescriptor((20, 20), orientations=9).compute(char)
text += pytesseract.image_to_string(char, config='--psm 6 --oem 3')
# 文本还原
print(text)
```
#### 代码逻辑分析:
1. 图像预处理:将图像转换为灰度图,并使用 Otsu 阈值化进行二值化,提高文本清晰度。
2. 字符分割:使用轮廓检测算法分割出图像中的字符区域。
3. 特征提取和字符识别:使用 HOG 特征描述符提取字符特征,并使用 Tesseract OCR 引擎进行字符识别。
4. 文本还原:将识别的字符组合成单词和句子,还原为可编辑的文本格式。
#### 参数说明:
- `--psm 6`: 指定 Tesseract 使用单字符识别模式。
- `--oem 3`: 指定 Tesseract 使用默认 OCR 引擎。
# 3.1 OCR技术实施步骤
**3.1.1 文档准备**
OCR技术实施的第一步是准备要进行光学字符识别的文档。这包括扫描文档或将数字文档转换为图像格式。扫描时,应确保图像质量高,清晰度高,且没有模糊或扭曲。对于数字文档,应将其转换为高分辨率的图像格式,如 TIFF 或 PNG。
**3.1.2 OCR引擎选择**
市场上有各种 OCR 引擎可供选择,每种引擎都有其独特的优点和缺点。选择合适的 OCR 引擎取决于特定应用程序的需求。一些流行的 OCR 引擎包括:
- Tesseract OCR:开源 OCR 引擎,免费使用,支持多种语言。
- Google Cloud Vision API:基于云的 OCR 服务,提供高精度和广泛的语言支持。
- Amazon Rekognition:AWS 提供的 OCR 服务,具有强大的图像分析功能。
**3.1.3 OCR参数优化**
OCR 引擎通常提供各种参数,可以对其进行优化以提高识别率和速度。这些参数包括:
- **语言:**指定要识别的文档语言。
- **页面布局:**指定文档的页面布局,例如单列或多列。
- **分辨率:**指定图像的分辨率。
- **二值化阈值:**指定将图像转换为二值图像的阈值。
- **降噪:**指定用于从图像中去除噪声的算法。
优化这些参数需要反复试验,以找到特定应用程序的最佳设置。
### 3.2 OCR技术常见问题及解决方法
**3.2.1 OCR识别率低**
OCR 识别率低可能是由以下原因造成的:
- **图像质量差:**图像模糊、扭曲或分辨率低。
- **文档复杂:**文档包含复杂的布局、字体或背景。
- **OCR引擎不匹配:**所选的 OCR 引擎不适用于特定类型的文档。
- **参数未优化:**OCR 参数未针对特定应用程序进行优化。
**解决方法:**
- 提高图像质量。
- 简化文档布局。
- 选择合适的 OCR 引擎。
- 优化 OCR 参数。
**3.2.2 OCR识别速度慢**
OCR 识别速度慢可能是由以下原因造成的:
- **图像文件过大:**图像文件过大,导致处理时间长。
- **OCR引擎性能差:**所选的 OCR 引擎性能较差。
- **硬件资源不足:**用于运行 OCR 引擎的计算机硬件资源不足。
**解决方法:**
- 缩小图像文件大小。
- 选择性能更好的 OCR 引擎。
- 升级硬件资源。
# 4. OCR技术进阶应用
### 4.1 OCR技术与人工智能的结合
OCR技术与人工智能的结合,为OCR技术的发展带来了新的契机。人工智能技术,特别是机器学习和深度学习技术,可以显著提升OCR技术的识别率和速度。
#### 4.1.1 OCR技术与机器学习
机器学习是一种人工智能技术,它可以通过从数据中学习来执行任务。在OCR领域,机器学习技术可以用于训练OCR引擎识别各种字体、语言和文档布局。
**代码块:**
```python
import cv2
import pytesseract
# 加载图像
image = cv2.imread("image.png")
# 使用 Tesseract OCR 引擎进行识别
text = pytesseract.image_to_string(image)
# 打印识别结果
print(text)
```
**逻辑分析:**
* `cv2.imread()` 函数加载图像。
* `pytesseract.image_to_string()` 函数使用 Tesseract OCR 引擎识别图像中的文本。
* 识别结果存储在 `text` 变量中。
#### 4.1.2 OCR技术与深度学习
深度学习是一种机器学习技术,它使用神经网络来执行任务。在OCR领域,深度学习技术可以用于训练OCR引擎识别更复杂的文档,例如手写文档和历史文档。
**代码块:**
```python
import tensorflow as tf
# 加载模型
model = tf.keras.models.load_model("ocr_model.h5")
# 加载图像
image = cv2.imread("image.png")
# 预处理图像
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (28, 28))
# 预测文本
text = model.predict(image)
# 打印识别结果
print(text)
```
**逻辑分析:**
* `tf.keras.models.load_model()` 函数加载深度学习模型。
* `cv2.cvtColor()` 函数将图像转换为灰度图像。
* `cv2.resize()` 函数将图像调整为模型输入大小。
* `model.predict()` 函数预测图像中的文本。
* 识别结果存储在 `text` 变量中。
### 4.2 OCR技术在文档管理中的应用
OCR技术在文档管理中有着广泛的应用,可以帮助企业提高文档处理效率,降低成本。
#### 4.2.1 文档分类和归档
OCR技术可以自动识别文档类型,并将其分类归档到相应的文件夹中。这可以帮助企业快速找到所需文档,提高文档管理效率。
**表格:OCR技术在文档分类中的应用**
| 文档类型 | 识别特征 | 分类规则 |
|---|---|---|
| 发票 | 发票号、金额 | 根据发票号和金额进行分类 |
| 合同 | 合同编号、日期 | 根据合同编号和日期进行分类 |
| 简历 | 姓名、联系方式 | 根据姓名和联系方式进行分类 |
#### 4.2.2 文档检索和分析
OCR技术可以提取文档中的文本信息,并将其存储到数据库中。这使得企业可以快速检索文档,并对文档内容进行分析。
**流程图:OCR技术在文档检索中的应用**
```mermaid
sequenceDiagram
participant OCR
participant Database
OCR->>Database: Send document text
Database->>OCR: Store document text
OCR->>User: Return search results
```
# 5.1 OCR技术的发展方向
随着人工智能和云计算技术的不断发展,OCR技术也在不断演进,呈现出以下发展方向:
### 5.1.1 OCR技术在移动端的应用
智能手机和平板电脑的普及,使得OCR技术在移动端得到了广泛应用。移动端OCR技术主要用于以下场景:
- **文档扫描和识别:**用户可以使用手机摄像头扫描纸质文档,并通过OCR技术将其转换为可编辑的文本。
- **名片识别:**用户可以使用手机摄像头扫描名片,并通过OCR技术提取名片上的联系信息。
- **翻译:**用户可以使用手机摄像头扫描外语文本,并通过OCR技术将其翻译成母语。
### 5.1.2 OCR技术在云端的应用
云计算平台提供了强大的计算和存储能力,使得OCR技术可以在云端进行大规模处理。云端OCR技术主要用于以下场景:
- **文档处理:**企业可以使用云端OCR服务批量处理大量文档,实现文档分类、归档、检索和分析。
- **图像识别:**云端OCR技术可以用于识别图像中的文字内容,例如广告牌、路标和产品包装上的文字。
- **视频分析:**云端OCR技术可以用于分析视频中的文字内容,例如监控视频中的车牌号和人员信息。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 OpenCV 在文档扫描和 OCR 识别中的应用,从基础知识到高级技术,为您提供全面的指南。您将了解图像预处理、深度学习、图像分割、增强和降噪等关键技术,以及它们在提升 OCR 精度中的作用。此外,专栏还介绍了 OCR 识别算法、特征提取、后处理技术和创新应用,帮助您打造高效且准确的 OCR 系统。通过实战项目和性能优化策略,您将掌握 OpenCV 在文档扫描 OCR 识别中的实际应用,并了解如何应对海量文档处理的挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【刷机安全教程】:如何安全地刷Kindle Fire HDX7 三代
# 摘要
本文旨在提供关于刷机操作的全面基础知识与实践指南。从准备刷机工作环境的细节,如设备兼容性确认、软件获取和数据备份,到详细的刷机流程,包括Bootloader解锁、刷机包安装及系统引导与设置,本文深入讨论了刷机过程中的关键步骤和潜在风险。此外,本文还探讨了刷机后的安全加固、性能调优和个性化定制,以及故障诊断与恢复方法,为用户确保刷机成功和设备安全性提供了实用的策略和技巧。
# 关键字
刷机;设备兼容性;数据备份;Bootloader解锁;系统引导;故障诊断
参考资源链接:[Kindle Fire HDX7三代救砖教程:含7.1.2刷机包与驱动安装](https://wenku.cs
【RN8209D电源管理技巧】:打造高效低耗的系统方案

# 摘要
本文综合介绍RN8209D电源管理芯片的功能与应用,概述其在不同领域内的配置和优化实践。通过对电源管理基础理论的探讨,本文阐释了电源管理对系统性能的重要性,分析了关键参数和设计中的常见问题,并给出了相应的解决方案。文章还详细介绍了RN8209D的配置方
C#设计模式:解决软件问题的23种利器
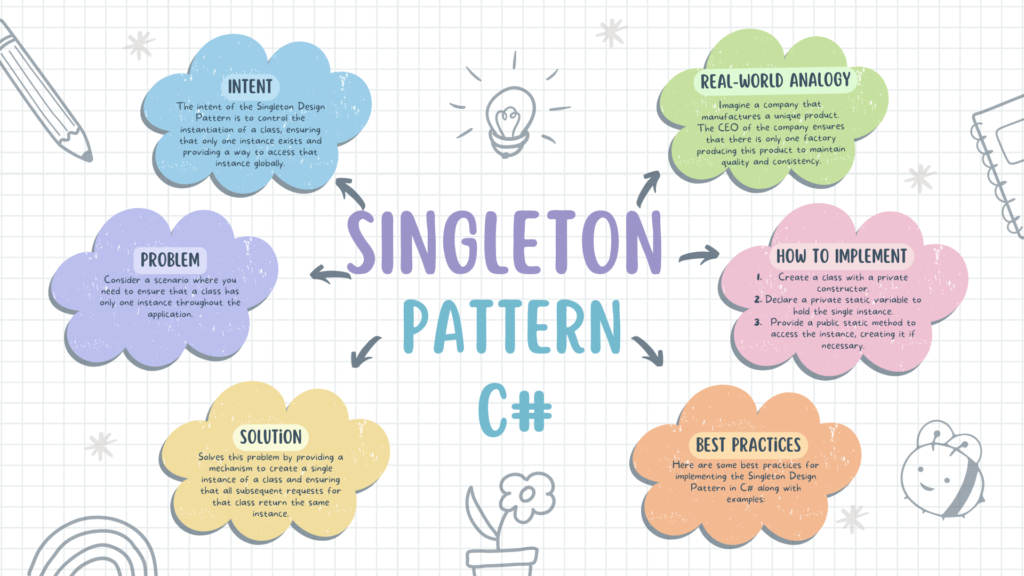
# 摘要
设计模式作为软件工程中的一种重要方法论,对于提高代码的可重用性、可维护性以及降低系统的复杂性具有至关重要的作用。本文首先概述了设计模式的重要性及其在软件开发中的基础地位。随后,通过深入探讨创建型、结构型和行为型三种设计模式,本文分析了每种模式的理论基础、实现技巧及其在实际开发中的应用。文章强调了设计模式在现代软件开发中的实际应用,如代码复用、软件维护和架构设计,并提供了相关模式的选择和运用策略
【性能基准测试】:极智AI与商汤OpenPPL在实时视频分析中的终极较量

# 摘要
实时视频分析技术在智能监控、安全验证和内容分析等多个领域发挥着越来越重要的作用。本文从实时视频分析技术的性能基准测试出发,对比分析了极智AI和商汤OpenPPL的技术原理、性能指标以及实践案例。通过对关键性能指标的对比,详细探讨了两者的性能优势与劣势。文章进一步提出了针对两大技术的性能优化策略,并预测了实时视频分析技术的未来发展趋势及其面临的挑战。研究发现,硬件加速技术和软件算法优化是提升实时视频
【24小时精通安川机器人】:新手必读的快速入门秘籍与实践指南

# 摘要
安川机器人作为自动化领域的重要工具,在工业生产和特定行业应用中发挥着关键作用。本文首先概述了安川机器人的应用领域及其在不同行业的应用实例。随后,探讨了安川机器人的基本操作和编程基础,包括硬件组成、软件环境和移动编程技术。接着,深入介绍了安川机器人的高级编程技术,如数据处理、视觉系统集成和网络通信,这些技术为机器人提供了更复杂的功能和更高的灵活性。
【定时器应用全解析】:单片机定时与计数,技巧大公开!

# 摘要
本文深入探讨了定时器的基础理论及其在单片机中的应用。首先介绍了定时器的基本概念、与计数器的区别,以及单片机定时器的内部结构和工作模式。随后,文章详细阐述了单片机定时器编程的基本技巧,包括初始化设置、中断处理和高级应用。第四章通过实时时钟、电机控制和数据采集等实例分析了定时器的实际应用。最后,文章探讨了定时器调试与优化的方法,并展望了定时器技术的未来发展趋势,特别是高精度定时器和物联网应用的可能性
【VIVADO逻辑分析高级应用】:掌握高级逻辑分析在VIVADO中的技巧
# 摘要
本文旨在全面介绍VIVADO逻辑分析工具的基础知识与高级应用。首先,概述了VIVADO逻辑分析的基本概念,并详细阐述了其高级工具,如Xilinx Analyzer的界面操作及高级功能、时序分析与功耗分析的基本原理和高级技巧。接着,文章通过实践应用章节,探讨了FPGA调试、性能分析以及资源管理的策略和方法。最后,文章进一步探讨了
深度剖析四位全加器:计算机组成原理实验的不二法门

# 摘要
四位全加器作为数字电路设计的基础组件,在计算机组成原理和数字系统中有广泛应用。本文详细阐述了四位全加器的基本概念、逻辑设计方法以及实践应用,并进一步探讨了其在并行加法器设
高通modem搜网注册流程的性能调优:影响因素与改进方案(实用技巧汇总)

# 摘要
本文全面概述了高通modem搜网注册流程,包括其技术原理、性能影响因素以及优化实践。搜网技术原理的深入分析为理解搜网流程提供了基础,而性能影响因素的探讨涵盖了硬件、软件和网络环境的多维度考量。理论模型与实际应用的差异进一步揭示了搜网注册流程的复杂性。文章重点介绍了性能优化的方法、实践案例以及优化效果的验证分析。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )