【Java数组与Stream API】:掌握现代Java数组处理技术
发布时间: 2024-09-22 08:50:13 阅读量: 158 订阅数: 44 
# 1. Java数组基础
## 1.1 Java数组简介
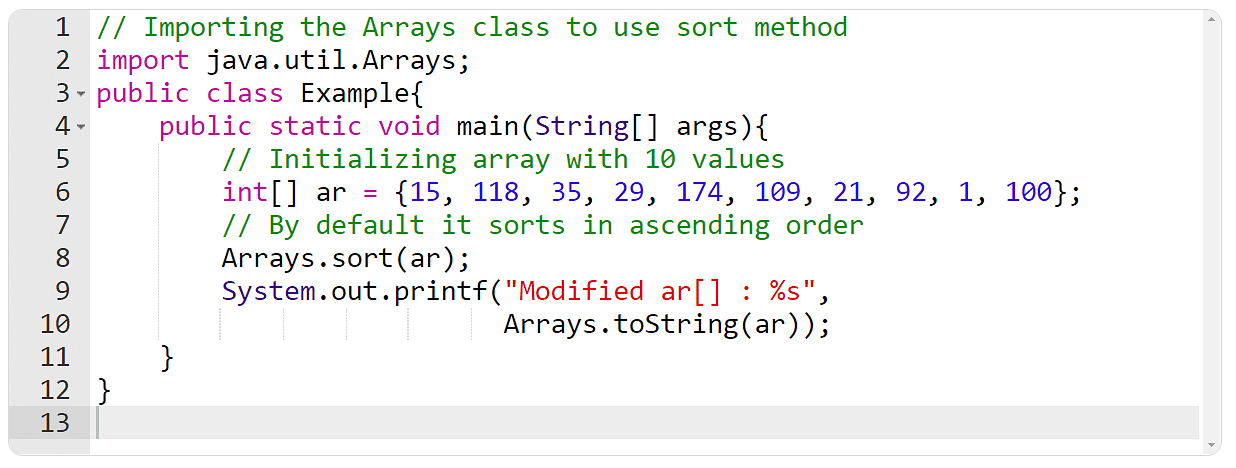
Java数组是一种数据结构,它能够存储固定大小的相同类型元素。数组可以存储基本数据类型和引用数据类型。数组的操作主要包括声明、初始化、访问元素和数组长度的获取。
```java
int[] numbers = new int[5]; // 声明并初始化一个整型数组
numbers[0] = 1; // 访问数组元素并赋值
int length = numbers.length; // 获取数组长度
```
## 1.2 数组的使用
在使用数组时,需要注意数组的索引是从0开始的。若访问不存在的索引将会抛出`ArrayIndexOutOfBoundsException`异常。数组一旦声明,其长度不可更改。
```java
int firstElement = numbers[0]; // 获取数组的第一个元素
```
## 1.3 数组的高级操作
高级操作包括数组的复制、排序等。Java提供了`System.arraycopy()`方法进行数组复制,以及`Arrays.sort()`方法来对数组进行排序。
```java
int[] copy = new int[5];
System.arraycopy(numbers, 0, copy, 0, numbers.length); // 复制数组
Arrays.sort(copy); // 对数组进行排序
```
这一章是整个系列文章的基础,通过阅读本章,读者将对Java数组有一个清晰的认识,为后续学习更为复杂的Stream API打下坚实的基础。
# 2. 深入理解Stream API
Java 8 引入的 Stream API 是处理集合的现代工具,提供了声明式的数据处理方式,可以非常方便地实现复杂的集合操作。与传统的集合操作相比,Stream API 能够利用函数式编程的优势,进行更加灵活和高效的操作。
## Stream API的基本概念
Stream API 通过一系列的中间操作和终止操作来处理数据集合。它不是存储数据的结构,而是一个处理数据的通道。
### Stream与Collection的对比
Java 集合框架中的 Collection 与 Stream API 有本质上的区别。Collection 是静态的数据结构,主要关注于数据的存储;而 Stream API 则是一个流式的数据接口,关注于对数据的计算和处理。
- Collection 是直接存储数据的,而 Stream API 则是处理数据的抽象。
- Collection 需要明确存储、更新、删除数据,Stream API 提供了更为高级的操作,能够将操作延迟执行,直到最终需要结果输出时才进行计算。
### Stream的创建和终止操作
创建 Stream 的方式多种多样,最直接的是通过集合的 stream() 方法,也可以通过 Stream 类的静态工厂方法,如 Stream.of() 来创建。
终止操作包括 collect(), forEach(), reduce() 等方法,它们会强制执行中间操作链,产生结果。这是 Stream API 的核心,没有终止操作,中间操作就不会执行。
## Stream API的数据处理操作
Stream API 提供了一系列的中间操作和终止操作,可以高效地对数据进行处理。
### 中间操作详解
中间操作是可链接的操作,可以进行多次,每次操作都返回一个新的 Stream 对象。
- `filter(Predicate)`:根据提供的条件过滤流中的元素。
- `map(Function)`:转换流中的元素到新的形式。
- `flatMap(Function)`:将流中的每个值都转换成另一个流,然后将所有流连接成一个流。
```java
Stream.of("apple", "banana", "cherry")
.filter(s -> s.startsWith("a"))
.map(String::toUpperCase)
.forEach(System.out::println);
```
上面的代码首先创建了一个包含水果名称的 Stream,然后通过 filter 方法只保留以 "a" 开头的元素。接着通过 map 方法将剩余的字符串转换为大写,最后通过 forEach 方法打印每个元素。
### 终端操作的使用
终端操作是流的终点,一旦执行一个终端操作,这个流就会被消耗掉,无法再被使用。
```java
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
long count = names.stream()
.filter(name -> name.startsWith("A"))
.count();
System.out.println("Number of names starting with A: " + count);
```
这段代码计算了列表中以 "A" 开头的名字的数量。`count()` 是一个终端操作,执行完之后,流就被消费了。
## Stream API的并行处理
Java 并行流可以利用多核处理器的能力,通过将任务拆分成多个子任务,在不同的处理器上并行执行,从而达到提高效率的目的。
### 并行流的概念与好处
并行流(parallel stream)是相对于顺序流而言的。在顺序流中,每个元素的处理都是按顺序一个接一个地进行。而在并行流中,可以将数据分割成块,分别在多个线程上进行处理。
```java
int sum = Arrays.stream(numbers)
.parallel()
.reduce(0, Integer::sum);
```
通过在 `parallel()` 方法,可以将一个顺序流转换成并行流,然后通过 `reduce()` 方法来进行并行求和。
### 并行流的性能优化
并行流的性能并不总是比顺序流快,它依赖于多种因素,例如流中的元素数量、处理元素的复杂性以及可用的处理器核心数量。而且,并行流的创建和管理比顺序流开销大。
```java
List<String> data = // ... 初始化一个大数据集
long startTime = System.nanoTime();
data.parallelStream()
.map(s -> s.toUpperCase())
.forEach(s -> { /* 一些操作 */ });
long endTime = System.nanoTime();
System.out.println("Parallel processing took: " + (endTime - startTime) / 1e6 + " ms");
```
并行流在处理大数据集时表现通常优于顺序流,因为它能利用多核CPU进行有效加速。但是,对于小数据集或简单任务,额外的开销可能会导致性能不如顺序流。因此,选择使用并行流时需要根据具体情况做出判断。
# 3. 数组与Stream API的结合应用
在现代Java应用中,数组和Stream API是处理集合数据的两种常用方法。本章节我们将探讨如何将数组转换为Stream,通过实例来展示如何操作Stream处理数组,以及如何对数组与Stream API的性能进行比较。
## 3.1 数组转换为Stream
### 3.1.1 使用Arrays类与Stream
在Java中,我们常常需要将数组转换为Stream,以便使用Stream API强大的数据处理能力。这可以通过`java.util.Arrays`类中的`stream()`方法轻松完成。
```java
import java.util.Arrays;
import java.util.stream.Stream;
public class ArrayToStream {
public static void main(String[] args) {
Integer[] numbers = {1, 2, 3, 4, 5};
// 创建Stream
Stream<Integer> numbersStream = Arrays.stream(numbers);
// 对Stream进行操作
numbersStream.map(number -> number * 2).forEach(System.out::println);
}
}
```
这段代码首先导入了`Arrays`和`Stream`类,然后创建了一个名为`numbers`的数组。通过调用`Arrays.stream()`方法,我们得到一个与数组对应的Stream,然后可以对其应用各种流式操作。
### 3.1.2 自定义数组转换逻辑
虽然`Arrays.stream()`方法非常方便,但有时候我们需要自定义转换逻辑来生成Stream。这时,我们可以使用`Stream.of()`方法来创建一个基础的Stream,或者使用`Stream.generate()`或`Stream.iterate()`来创建更复杂的Stream。
```java
import java.util.stream.Stream;
public class CustomArrayToStream {
public static void main(String[] args) {
// 使用Stream.of()创建Stream
Stream<Integer> simpleStream = Stream.of(1, 2, 3, 4, 5);
// 使用Stream.generate()创建无限Stream
Stream<Double> randomStream = Stream.generate(Math::random);
// 使用Stream.iterate()创建基于种子的无限Stream
Stream<Integer> iterateStream = Stream.iterate(1, n -> n + 1).limit(10);
// 对Stream进行操作
simpleStream.map(number -> number * 2).forEach(System.out::println);
}
}
```
在这个例子中,`Stream.of()`用于创建一个包含特定元素的Stream;`Stream.generate()`用于创建一个无限的Stream,它在每次调用时返回一个新的随机数;而`Stream.iterate()`则根据提供的种子和函数生成一个无限的Stream,这里限制了长度为10。
## 3.2 Stream操作数组的实例
### 3.2.1 筛选和映射数组元素
Stream API提供的中间操作允许我们对数据进行筛选和映射。筛选操作可以帮助我们选出满足特定条件的元素,而映射操作则允许我们转换元素的类型或形状。
```java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamFilterMapExample {
public static void main(String[] args) {
Integer[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 筛选出偶数并映射为它们的平方
List<Integer> evenSquares = Arrays.stream(numbers)
.filter(n -> n % 2 == 0)
.map(n -> n * n)
.collect(Collectors.toList());
// 输出结果
evenSquares.forEach(System.out::println);
}
}
```
上述代码通过`filter()`方法筛选出偶数,然后使用`map()`方法计算其平方,最后通过`collect()`方法将结果收集到一个新的`List`中。
### 3.2.2 归约与收集操作示例
归约操作用于将Stream中的元素组合成一个单一的结果,如求和、求最大值等。收集操作则是将Stream的元素收集到一个集合中。
```java
import java.util.Arrays;
import java.util.OptionalInt;
public class StreamReductionExample {
public static void main(String[] args) {
Integer[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 归约操作计算最大值
OptionalInt max = Arrays.stream(numbers).mapToInt(n -> n).max();
// 收集操作求和
int sum
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Java数组专栏简介**
本专栏深入探索Java数组的方方面面,从创建和内存管理到性能优化和高级技能。通过一系列文章,读者将全面掌握Java数组的精髓。
专栏涵盖广泛主题,包括:
* 数组创建和内存模型
* 性能优化技巧和内存管理
* 多维数组处理和实战应用
* 与集合框架的对比和最佳数据结构选择
* 排序算法和性能优化
* 遍历技巧和适用场景
* 浅拷贝和深拷贝的区分和实现
* 异常处理和数组越界保护
* 操作优化和最佳实践
* 泛型和类型安全
* Stream API和现代数组处理技术
* 并发编程中的数组和集合对比
* 数据结构中的数组角色
* 内存管理和垃圾回收
* 反射技术和动态数组操作
* JSON序列化和反序列化
* 不同数据类型的存储和处理技巧
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )