【Java数组数据类型问题】:不同数据类型的存储与处理技巧
发布时间: 2024-09-22 09:23:44 阅读量: 90 订阅数: 44 

Java基础教程:从基本数据类型到数组操作与面向对象实现

# 1. Java数组的基本概念与类型
## 1.1 Java数组的定义
在Java编程语言中,数组是一种引用数据类型,用于存储固定大小的同类型元素。数组可以存储基本数据类型,如整数、浮点数等,也可以存储对象。数组的创建方式相对简单,对于基本数据类型数组,系统会自动初始化默认值;而对于引用数据类型数组,则初始化为null。
## 1.2 数组的类型
Java数组分为两大类型:基本数据类型数组和引用数据类型数组。基本数据类型数组直接存储数值,例如`int[]`数组存储整数。引用数据类型数组存储对象的引用,如自定义的类对象,`String[]`数组存储字符串对象。理解这两类数组是进行Java数组操作的基础。
## 1.3 数组的声明与初始化
数组的声明包括数组类型、数组名和数组大小,例如声明一个整型数组可以写作`int[] numbers;`。数组的初始化可以通过`new`关键字进行,也可以使用数组初始化器进行简化的声明和初始化,例如`int[] numbers = {1, 2, 3};`。在Java 5及以上版本中,可以使用泛型来定义和初始化数组,例如`List<Integer> list = Arrays.asList(1, 2, 3);`。
# 2. 基本数据类型数组的特点与应用
## 2.1 基本数据类型数组的定义与声明
### 2.1.1 整型数组的使用
在Java中,整型数组是最常见的一种基本数据类型数组,它用于存储一系列的整数值。整型数组的声明非常简单,只需要指定数组类型为int,并提供数组名称和大小。例如,声明一个整型数组并初始化它:
```java
int[] numbers = new int[5];
```
这行代码声明了一个名为`numbers`的整型数组,它可以存储5个整数。在Java中,数组的索引是从0开始的,所以`numbers[0]`是数组的第一个元素。
数组的初始化有两种形式,一种是静态初始化,另一种是动态初始化。静态初始化是在声明数组时直接给数组元素赋值,例如:
```java
int[] primes = new int[] {2, 3, 5, 7, 11};
```
可以进一步简写为:
```java
int[] primes = {2, 3, 5, 7, 11};
```
动态初始化则是在声明数组时只指定大小,后续再给数组元素赋值,如前面的例子所示。
### 2.1.2 浮点型数组的使用
浮点型数组是用于存储一系列的浮点数值,如`float`和`double`类型。数组的声明和初始化方式与整型数组类似,但需要注意的是,由于浮点数的范围和精度比整数大,因此在声明时应指定正确的类型(`float`或`double`)。
下面是一个声明`double`类型数组的例子:
```java
double[] distances = new double[3];
distances[0] = 1.5;
distances[1] = 2.2;
distances[2] = 3.7;
```
或者使用静态初始化的方式:
```java
double[] distances = {1.5, 2.2, 3.7};
```
在处理浮点数时,通常需要注意精度问题。由于浮点数是基于IEEE 754标准的二进制表示,所以某些十进制小数无法精确表示为二进制浮点数。这可能会导致在进行浮点数比较时出现意想不到的结果。在实际应用中,建议使用`BigDecimal`类来处理需要精确计算的浮点数。
## 2.2 基本数据类型数组的内存布局
### 2.2.1 内存分配与访问机制
基本数据类型数组在内存中的分配是连续的。这意味着数组中的所有元素都存储在一块连续的内存空间内。当我们访问数组元素时,可以通过数组名加上索引的方式进行。数组的索引实际上是一个偏移量,它是从数组起始地址开始计算的。
例如,对于一个整型数组`int[] numbers = new int[5];`,内存布局大致如下:
```
(numbers + 0) -> [内存地址] -> [值]
(numbers + 1) -> [内存地址 + 4] -> [值]
(numbers + 2) -> [内存地址 + 8] -> [值]
(numbers + 3) -> [内存地址 + 12] -> [值]
(numbers + 4) -> [内存地址 + 16] -> [值]
```
这里,整型(int)在Java中占用4个字节,因此每个数组元素的地址是上一个元素地址加4。
### 2.2.2 基本数据类型数组的内存优化
基本数据类型数组的内存优化可以从两个方面入手:空间效率和时间效率。
- 空间效率主要通过减少数组大小来实现,比如在循环中使用数组前,确保数组大小是必要的,避免分配过大的数组。
- 时间效率则更多地关注于数组操作的优化,例如在进行大量数组操作时,尽量减少数组拷贝的次数,使用局部变量缓存数组元素等。
Java虚拟机(JVM)在内部也对数组做了优化,比如使用逃逸分析技术来判断一个数组是否被外部引用。如果没有外部引用,JVM可能会将数组存储在栈上,而不是堆上,以减少堆内存的使用并提高性能。
## 2.3 基本数据类型数组的操作技巧
### 2.3.1 数组初始化与默认值
Java提供了多种数组初始化的方法。除了前面提到的静态初始化和动态初始化之外,Java 7引入了更简洁的数组初始化语法,允许使用`钻石操作符`(<>)来推断数组类型:
```java
int[] numbers = new int[] {1, 2, 3, 4, 5};
// Java 7 之后可以简化为
int[] numbers = {1, 2, 3, 4, 5};
```
如果声明一个基本数据类型数组但没有显式初始化,那么数组的每个元素都会被赋予一个默认值。对于`int`类型的数组,所有元素的默认值是0;对于`boolean`数组,是`false`;对于`float`和`double`数组,则是`0.0`。
### 2.3.2 数组的排序与查找算法
Java内置了对数组进行排序和查找的便捷方法。`Arrays`类提供了一个`sort`方法,它可以用来对数组进行排序:
```java
int[] numbers = {5, 3, 4, 1, 2};
Arrays.sort(numbers);
```
排序后,数组`numbers`中的元素顺序将变为`{1, 2, 3, 4, 5}`。
对于查找操作,`Arrays`类提供了`binarySearch`方法,它能高效地在已排序的数组中查找特定值。在使用`binarySearch`方法之前,确保数组已经是排序状态,否则结果是不确定的:
```java
int index = Arrays.binarySearch(numbers, 3);
```
如果数组中存在该值,则返回其在数组中的索引;如果不存在,则返回一个负值,其值为`-(插入点) - 1`,插入点是指如果要将该值插入数组时,该值应该插入的位置。
# 总结
本

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Java数组专栏简介**
本专栏深入探索Java数组的方方面面,从创建和内存管理到性能优化和高级技能。通过一系列文章,读者将全面掌握Java数组的精髓。
专栏涵盖广泛主题,包括:
* 数组创建和内存模型
* 性能优化技巧和内存管理
* 多维数组处理和实战应用
* 与集合框架的对比和最佳数据结构选择
* 排序算法和性能优化
* 遍历技巧和适用场景
* 浅拷贝和深拷贝的区分和实现
* 异常处理和数组越界保护
* 操作优化和最佳实践
* 泛型和类型安全
* Stream API和现代数组处理技术
* 并发编程中的数组和集合对比
* 数据结构中的数组角色
* 内存管理和垃圾回收
* 反射技术和动态数组操作
* JSON序列化和反序列化
* 不同数据类型的存储和处理技巧
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
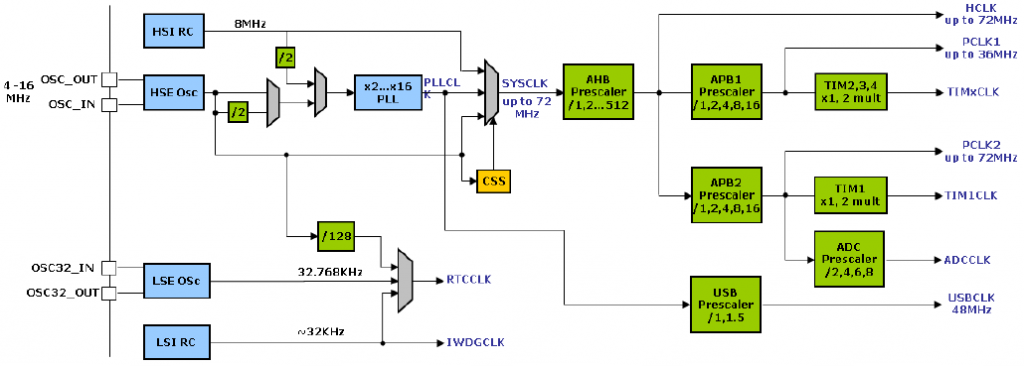
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
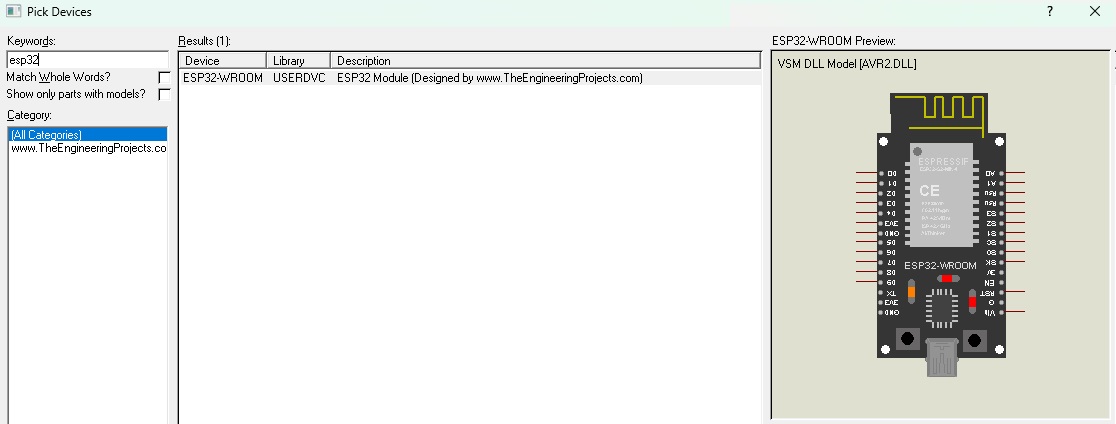
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )