Python库文件调试进阶:解决常见问题的终极指南
发布时间: 2024-10-13 04:53:42 阅读量: 29 订阅数: 28 

java计算器源码.zip

# 1. Python库文件的基础知识
## 1.1 Python库文件概述
Python库文件是Python编程中不可或缺的一部分,它为程序员提供了一种组织和复用代码的有效方式。库文件通常包含了函数、类、变量等资源,它们可以被不同的Python程序所导入和使用。了解和掌握库文件的基础知识,对于提高编程效率和代码质量至关重要。
## 1.2 导入库文件的方法
在Python中,我们可以使用`import`语句来导入库文件。例如,要导入标准库中的`os`模块,可以使用`import os`。此外,我们还可以使用`from...import...`语句来导入模块中的特定函数或类,如`from os import path`。
## 1.3 创建自定义库文件
除了使用Python标准库和第三方库之外,我们还可以创建自己的库文件。这涉及到将常用的代码封装成模块,然后将模块打包成`.py`文件。自定义库文件可以提高代码的可维护性和可重用性,同时也是分享代码给其他开发者的好方式。
```python
# 示例:创建一个简单的库文件 mylib.py
def greet(name):
return f"Hello, {name}!"
```
通过上述步骤,我们可以轻松地在其他Python脚本中导入并使用`mylib`库文件。
```python
# 示例:导入并使用自定义库文件
import mylib
print(mylib.greet("World"))
```
以上示例展示了如何创建和使用自定义库文件,接下来的章节将深入探讨库文件的调试技巧、高级应用和实践应用等内容。
# 2. 库文件的调试技巧
在本章节中,我们将深入探讨Python库文件的调试技巧,这是提高代码质量和效率的关键环节。我们将从常用的调试工具和方法开始,逐步深入到常见问题的调试和解决策略。
## 2.1 常用的调试工具和方法
### 2.1.1 调试工具的安装和配置
在Python开发中,有多种工具可以帮助我们进行代码调试,例如pdb、PyCharm等。以pdb为例,它是Python内置的调试器,可以让我们逐行执行代码并检查变量的状态。要使用pdb,你只需要在你的代码中导入它,并在你想要停止执行的行前添加`pdb.set_trace()`。
安装和配置pdb非常简单,因为它已经包含在Python标准库中。如果你使用的是PyCharm这样的集成开发环境(IDE),则可以直接使用其内置的调试功能,无需额外安装。
```python
import pdb
def some_function():
# 这里是一些代码
pdb.set_trace() # 在这里停止执行
# 这里是更多代码
```
### 2.1.2 常见的调试命令和用法
pdb提供了一系列的调试命令,可以让我们控制程序的执行流程,检查变量的值,甚至修改它们。以下是一些常用的pdb命令:
- `n`:执行下一行代码。
- `c`:继续执行,直到遇到下一个断点。
- `l`:查看当前的代码上下文。
- `p`:打印变量的值。
- `q`:退出调试器。
通过这些命令,我们可以有效地控制程序的执行,检查程序的状态,从而找到和修复bug。
## 2.2 常见的调试问题和解决方法
### 2.2.1 语法错误的调试和解决
语法错误通常是由于代码中的拼写错误或者语法不正确引起的。pdb可以帮助我们定位这些错误的位置。例如:
```python
def some_function():
varible_name = "Hello World" # 拼写错误
print(variable_name)
some_function()
```
当你尝试运行这段代码时,Python解释器会抛出一个`NameError`异常。如果你使用pdb调试,它会在抛出异常的行前停止,你可以检查变量名是否正确。
### 2.2.2 逻辑错误的调试和解决
逻辑错误是最难调试的一类错误,因为它们不会立即引起异常,而是会导致程序的输出不符合预期。在这种情况下,我们可以使用pdb逐步执行代码,检查每一行代码的执行结果和变量的值。
例如,以下代码中的逻辑错误可能会导致函数返回不正确的结果:
```python
def add(a, b):
return a + b
def subtract(a, b):
# 错误的逻辑
return a + b - a
print(add(5, 3)) # 正确
print(subtract(5, 3)) # 错误的逻辑
```
### 2.2.3 运行时错误的调试和解决
运行时错误通常是在程序运行时发生的,比如除以零、访问不存在的字典键等。这些错误会导致程序崩溃或者产生不正确的结果。使用pdb可以帮助我们定位这些错误发生的位置。
以下是一个除以零的错误示例:
```python
def divide(a, b):
return a / b # 运行时错误
print(divide(5, 0))
```
当运行这段代码时,会抛出`ZeroDivisionError`异常。使用pdb,我们可以在抛出异常的行前停止,检查变量`b`的值是否为零。
通过本章节的介绍,我们可以看到,无论是语法错误、逻辑错误还是运行时错误,调试工具和方法都是我们不可或缺的助手。通过熟练掌握这些工具和方法,我们可以有效地识别和解决代码中的问题,提高开发效率和代码质量。接下来的章节将介绍如何实现库文件的模块化设计和性能优化,以及如何在项目中应用和维护更新这些库文件。
# 3. 库文件的高级应用
## 3.1 库文件的模块化设计
### 3.1.1 模块化的概念和优势
模块化设计是软件工程中的一个重要概念,它指的是将一个复杂的系统分解成独立的模块,每个模块负责一组特定的功能。在Python库文件的开发中,模块化设计具有以下几个优势:
1. **提高代码的可维护性**:模块化使得代码结构更加清晰,每个模块负责一部分功能,便于开发者理解和维护。
2. **增强代码的复用性**:独立的模块可以被不同的项目或库文件重复使用,减少了代码的冗余。
3. **便于团队协作**:模块化设计允许不同的开发者或团队成员同时工作在不同的模块上,提高了开发效率。
4. **降低复杂性**:模块化将复杂的问题分解成小的、可管理的部分,使得整体系统的复杂性降低。
### 3.1.2 模块化的实现方法
在Python中,模块化的实现主要依赖于以下几个方面:
1. **定义模块**:创建一个`.py`文件,这个文件就是一个模块。
2. **组织模块**:将相关的模块组织成一个包(package),包是一个包含`__init__.py`文件的目录。
3. **模块化命名空间**:使用包和模块来创建一个清晰的命名空间,避免命名冲突。
4. **模块化依赖管理**:使用`requirements.txt`或类似的文件来管理模块依赖。
一个典型的模块化设计示例如下:
```python
# my_module.py
def my_function():
pass
# another_module.py
from my_module import my_function
def another_function():
my_function()
```
在这个例子中,`my_module`是一个模块,`another_module`依赖于`my_module`中的`my_function`函数。
### 3.1.3 模块化设计的最佳实践
模块化设计的最佳实践包括:
1. **遵循PEP 8规范**:Python官方风格指南,确保代码的一致性和可读性。
2. **编写文档字符串**:为每个模块和函数编写文档字符串,说明其用途和使用方法。
3. **编写单元测试**:为每个模块编写单元测试,确保其功能正确性和稳定性。
4. **避免全局变量**:减少全局变量的使用,以避免潜在的冲突和依赖问题。
5. **模块化依赖管理**:使用虚拟环境和依赖管理工具(如`pipenv`或`poetry`)来管理项目依赖。
## 3.2 库文件的性能优化
### 3.2.1 性能瓶颈的识别和分析
性能瓶颈是指程序运行中的某个环节,由于资源限制或算法效率低下等原因,导致程序运行速度下降。在Python库文件中,性能瓶颈通常出现在以下几个方面:
1. **计算密集型任务**:涉及到大量数值计算或循环的任务。
2. **IO密集型任务**:涉及到大量磁盘读写或网络通信的任务。
3. **算法效率**:使用了低效算法或数据结构。
### 3.2.2 性能优化的方法和技巧
性能优化的方法和技巧包括:
1. **使用更高效的数据结构**:例如,使用`set`代替`list`进行快速查找。
2. **利用内置函数和库**:Python的内置函数和标准库通常经过优化,性能优于自己编写的代码。
3. **使用C扩展**:对于计算密集型任务,可以使用C语言编写的扩展来提高性能。
4. **分析和优化循环**:减少循环内部的计算量,避免不必要的循环。
5. **多线程或多进程**:对于IO密集型任务,可以使用多线程或多进程来提高性能。
### 3.2.3 性能优化实践案例
假设我们有一个Python库文件`example.py`,它包含以下代码:
```python
# example.py
def calculate_squares(numbers):
squares = []
for number in numbers:
squares.append(number ** 2)
return squares
numbers = range(10000)
results = calculate_squares(numbers)
```
这段代码计算了一系列数字的平方,并存储在列表中。我们可以使用`cProfile`模块来分析这段代码的性能瓶颈。
```bash
python -m cProfile -o profile.prof example.py
```
然后使用`pstats`模块来查看性能分析结果:
```python
import pstats
p = pstats.Stats('profile.prof')
p.sort_stats('time').print_stats(10)
```
通过分析,我们可能会发现`calculate_squares`函数是性能瓶颈。为了优化,我们可以使用列表推导式来替代循环,提高性能。
```python
def calculate_squares(numbers):
return [number ** 2 for number in numbers]
```
## 3.3 库文件的并发编程
### 3.3.1 并发编程的概念和优势
并发编程是指同时执行多个计算任务的能力,以提高程序的效率和响应性。在Python中,可以使用多种方式来实现并发编程,包括多线程和多进程。
### 3.3.2 并发编程的实现方法
在Python中,实现并发编程的常用方法包括:
1. **多线程**:使用`threading`模块来创建和管理线程。
2. **多进程**:使用`multiprocessing`模块来创建和管理进程。
3. **异步编程**:使用`asyncio`模块来编写异步代码。
### 3.3.3 并发编程的应用实例和分析
以下是一个使用`threading`模块的并发编程示例:
```python
import threading
def task(n):
print(f"Task {n} started.")
# 模拟耗时操作
for i in range(5):
print(f"Task {n} step {i}")
print(f"Task {n} finished.")
threads = []
for i in range(3):
t = threading.Thread(target=task, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
```
在这个例子中,我们创建了三个线程,每个线程执行`task`函数。`threading.Thread`用于创建一个新的线程,`t.start()`启动线程,`t.join()`等待线程完成。
通过并发编程,我们可以提高程序的效率,特别是在执行IO密集型任务时。然而,多线程编程也引入了新的复杂性,例如线程安全问题和资源竞争问题。因此,在设计并发程序时,需要仔细考虑同步机制,如锁、信号量等。
# 4. 库文件的实践应用
在本章节中,我们将深入探讨Python库文件在实际项目中的应用,并介绍如何对库文件进行维护和更新。我们将从项目需求分析和设计开始,逐步深入到库文件的应用实例和分析,最后讨论库文件的版本控制和更新,以及测试和验证的重要性。
#### 4.1 库文件在项目中的应用
##### 4.1.1 项目需求分析和设计
在开始编写代码之前,需求分析是至关重要的一步。它涉及理解项目的目标、功能需求以及预期的用户群体。需求分析的目的是确保开发团队对项目有一个清晰的理解,并能够根据这些需求设计出合适的库文件结构。
在需求分析阶段,我们通常会创建用例图和需求规格说明书。用例图帮助我们识别系统的参与者和功能,而需求规格说明书则是详细的需求文档。以下是一个用例图的例子:
```mermaid
graph LR
A[Actor] -->|uses| B(Use Case)
C[Actor 2] -->|interacts with| D(Another Use Case)
```
##### 4.1.2 库文件的应用实例和分析
在确定了项目需求后,我们可以开始设计和实现库文件。这里,我们将通过一个简单的示例来演示如何构建一个功能模块,并将其打包成库文件供其他项目使用。
```python
# mylib/my_module.py
def greet(name):
return f"Hello, {name}!"
def add(a, b):
return a + b
```
接下来,我们将这个模块打包成一个库文件:
```shell
# setup.py
from setuptools import setup
setup(
name="mylib",
version="0.1",
packages=["mylib"],
install_requires=[
# 依赖列表
],
)
```
安装这个库文件:
```shell
pip install .
```
然后,在另一个项目中导入和使用这个库文件:
```python
import mylib
print(mylib.greet("World"))
print(mylib.add(1, 2))
```
通过这个简单的例子,我们可以看到库文件在项目中的应用流程:需求分析、设计、实现、打包和安装。每个步骤都是项目成功的关键。
#### 4.2 库文件的维护和更新
##### 4.2.1 库文件的版本控制和更新
库文件的版本控制是确保代码质量和用户信任的重要环节。通常,我们使用版本控制系统(如Git)来管理库文件的版本。每个版本都会对应一个唯一的版本号,通常是语义版本控制格式,如`major.minor.patch`。
```mermaid
gitGraph
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
checkout main
commit
```
在版本更新时,我们需要遵循语义版本控制的规则,确保向后兼容性,同时提供清晰的变更日志。
##### 4.2.2 库文件的测试和验证
在库文件的维护过程中,测试和验证是不可或缺的步骤。我们通常使用单元测试框架(如pytest)来编写测试用例,并使用持续集成工具(如Travis CI)来自动化测试流程。
```python
# tests/test_my_module.py
import pytest
from mylib.my_module import greet, add
def test_greet():
assert greet("Alice") == "Hello, Alice!"
def test_add():
assert add(1, 2) == 3
```
在本章节中,我们介绍了Python库文件在项目中的实际应用,包括需求分析、设计、实现、打包和安装的流程。同时,我们也探讨了库文件的维护和更新,包括版本控制、测试和验证的重要性。通过这些实践,我们可以确保库文件的质量和可靠性,为项目的成功打下坚实的基础。
# 5. 库文件的进阶应用
## 5.1 库文件的并发编程
### 并发编程的概念和优势
在本章节中,我们将深入探讨库文件在并发编程领域的应用。并发编程是指在单个程序中同时处理多个任务的能力,它是提高程序执行效率和响应速度的关键技术之一。在Python中,库文件可以通过多种方式支持并发编程,例如使用多线程、多进程或者异步编程模型。
并发编程的主要优势包括:
- **提高效率**:能够更充分地利用CPU资源,特别是在I/O密集型应用中,可以显著提高程序的整体性能。
- **提高响应性**:对于需要同时响应多个客户端请求的应用,例如Web服务器,使用并发编程可以提高系统的响应速度。
- **增强用户体验**:在图形用户界面(GUI)程序中,通过并发编程可以使界面保持响应,提升用户交互体验。
### 并发编程的实现方法
Python提供了多种并发编程的实现方法,其中最常用的是多线程和异步编程。
#### 多线程
Python的`threading`模块可以用来创建和管理线程。下面是一个简单的多线程示例代码:
```python
import threading
import time
def thread_function(name):
print(f"Thread {name}: starting")
time.sleep(2)
print(f"Thread {name}: finishing")
if __name__ == "__main__":
print("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
print("Main : before running thread")
x.start()
print("Main : wait for the thread to finish")
x.join()
print("Main : all done")
```
在这个例子中,我们定义了一个函数`thread_function`,它将被一个线程执行。在主函数中,我们创建了一个线程对象`x`,并启动它。主程序等待线程`x`完成后才继续执行。
#### 异步编程
Python的`asyncio`模块是处理异步编程的首选工具。下面是一个简单的异步编程示例代码:
```python
import asyncio
async def main():
print('hello ...')
await asyncio.sleep(1)
print('... world!')
asyncio.run(main())
```
在这个例子中,我们定义了一个异步函数`main`,使用`asyncio.sleep`来模拟异步操作。`asyncio.run`函数启动了事件循环并运行了`main`函数。
### 并发编程的应用实例和分析
为了更好地理解并发编程的应用,我们来看一个实际的例子:一个简单的Web爬虫程序,它使用多线程来提高爬取效率。
```python
import threading
import requests
from bs4 import BeautifulSoup
def fetch_url(url, queue):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
queue.put(soup)
if __name__ == "__main__":
urls = ['***', '***', '***']
threads = []
queue = []
results = {}
for url in urls:
t = threading.Thread(target=fetch_url, args=(url, queue))
threads.append(t)
t.start()
for thread in threads:
thread.join()
while not queue.empty():
page = queue.pop()
# 假设我们只关心页面中的某个特定信息
info = extract_info_from_page(page)
results[page.url] = info
print(results)
```
在这个例子中,我们创建了一个线程列表`threads`和一个队列`queue`。对于每个URL,我们创建一个线程来获取页面内容,并将结果放入队列中。主程序等待所有线程完成后,从队列中取出结果并处理。
通过本章节的介绍,我们可以看到并发编程在提高程序性能方面的强大能力。无论是通过多线程还是异步编程,合理地使用并发技术可以使我们的程序更加高效和响应迅速。在实际应用中,选择合适的并发模型对于实现最佳性能至关重要。
## 5.2 库文件的网络编程
### 网络编程的概念和实现
网络编程是指编写能够在网络上传输和接收数据的程序,它是互联网应用开发的基础。Python的库文件为网络编程提供了强大的支持,包括套接字编程、HTTP请求处理等。
#### 套接字编程
套接字编程是网络通信的基础,Python的`socket`模块提供了丰富的网络操作接口。下面是一个使用TCP套接字的简单客户端和服务器示例:
**服务器端代码:**
```python
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 5000))
server_socket.listen(5)
while True:
client_socket, address = server_socket.accept()
print(f"Connected to {address}")
client_socket.sendall(b'Hello from server')
client_socket.close()
```
**客户端代码:**
```python
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('localhost', 5000))
data = client_socket.recv(1024)
print(data.decode())
client_socket.close()
```
#### HTTP请求处理
对于HTTP请求的处理,Python的`requests`库是一个非常流行的第三方库,它简化了HTTP客户端的实现。下面是一个使用`requests`库发送HTTP请求的示例:
```python
import requests
response = requests.get('***')
data = response.json()
print(data)
```
### 网络编程的应用实例和分析
为了更好地理解网络编程的应用,我们来看一个实际的例子:一个简单的HTTP服务器,它使用Python的`socket`模块来处理客户端请求。
**服务器端代码:**
```python
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 5000))
server_socket.listen(5)
print("Server is listening on port 5000")
while True:
client_socket, addr = server_socket.accept()
print(f"Connection from {addr}")
request = client_socket.recv(1024)
print(request.decode())
response = "HTTP/1.1 200 OK\nContent-Type: text/plain\n\nHello, world!"
client_socket.sendall(response.encode())
client_socket.close()
```
在这个例子中,我们创建了一个监听在本地5000端口的服务器。服务器接收客户端请求,并发送一个简单的HTTP响应。
**客户端代码:**
```python
import requests
response = requests.get('***')
print(response.text)
```
通过本章节的介绍,我们可以看到网络编程在构建互联网应用中的重要性。无论是使用套接字进行低级网络通信,还是使用高级库简化HTTP请求处理,Python的库文件都提供了强大的工具来满足不同的网络编程需求。在实际开发中,选择合适的网络编程方法对于构建高性能、可扩展的网络应用至关重要。
# 6. 库文件的未来发展趋势
随着Python语言的不断演进和其在各行各业中的广泛应用,Python库文件作为Python生态中不可或缺的一部分,也在不断发展和演变。本章节将探讨Python库文件的未来发展趋势、应用前景以及学习和研究建议。
## 6.1 Python库的发展趋势
Python库的发展趋势主要体现在以下几个方面:
### 6.1.1 智能化和自动化
随着人工智能和机器学习的快速发展,Python库正在变得更加智能化和自动化。例如,深度学习库TensorFlow和PyTorch已经能够自动调优超参数,简化模型训练过程。在未来,我们可以预见更多的库将集成智能化的功能,提高开发效率和模型性能。
### 6.1.2 跨平台和云计算
随着云计算和容器技术的兴起,Python库也在向跨平台和云计算方向发展。Docker容器化技术使得Python应用可以轻松部署在不同的环境中,而云计算平台如AWS、Azure则提供了强大的计算资源,Python库需要更好地支持这些平台的特性。
### 6.1.3 性能优化
性能一直是软件开发中的重要考量因素。Python库未来的趋势之一是更加注重性能优化。例如,NumPy和Pandas等科学计算库通过与Cython、Numba等工具结合,不断提升计算速度和内存效率。
### 6.1.4 社区驱动和开源
Python社区是推动Python库发展的重要力量。开源和社区驱动的模式使得Python库能够快速迭代和改进。未来,我们可以期待更多的社区参与和贡献,使得Python库更加完善和强大。
## 6.2 库文件的应用前景
Python库的应用前景广阔,以下是一些主要领域:
### 6.2.1 数据科学和机器学习
数据科学和机器学习是Python库应用最为广泛的领域之一。随着企业和组织对数据驱动决策的需求增加,Python库如Scikit-learn、TensorFlow、PyTorch等在这一领域将有更大的发展空间。
### 6.2.2 网络安全
网络安全领域对Python库的需求也在不断增长。Python提供了如Scapy、PyCrypto等强大的库,用于网络分析、加密解密和安全测试等任务。未来,随着网络安全威胁的增加,Python库在这一领域的作用将更加重要。
### 6.2.3 云计算和大数据
云计算和大数据是当前技术发展的热点。Python库如Dask、PySpark等能够有效处理大规模数据集,并与云计算平台无缝集成。随着大数据技术的不断进步,Python库在这一领域的应用前景看好。
## 6.3 库文件的学习和研究建议
为了跟上Python库的发展趋势,以下是几点学习和研究建议:
### 6.3.1 持续学习
技术日新月异,持续学习是跟上Python库发展的重要途径。可以通过阅读官方文档、参加在线课程、阅读开源项目代码等方式来不断提升自己的技能。
### 6.3.2 参与社区
积极参与Python社区,可以快速了解最新的库文件动态和最佳实践。可以通过参与开源项目、贡献代码、参加社区讨论等方式来增加实践经验。
### 6.3.3 实践应用
理论知识需要通过实践来巩固。通过参与实际项目,可以将学到的知识应用到具体的场景中,解决实际问题,同时也能够更好地理解库文件的工作原理和应用场景。
### 6.3.4 跨领域学习
跨领域学习可以帮助开发者拓宽视野,例如结合Python在数据分析、机器学习、网络编程等不同领域的知识,可以创造出更多创新的解决方案。
通过不断学习和实践,开发者可以更好地适应Python库文件的发展趋势,把握应用前景,为未来的技术挑战做好准备。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件调试学习专栏!本专栏将带领您从零开始掌握调试工具,并逐步深入探索高级调试技巧。从解决常见问题到优化代码性能,再到构建自定义调试环境,您将学习如何高效定位和修复 bug。此外,我们还将探讨代码审查、自动化测试、多线程调试、性能分析工具等主题,帮助您全面提升调试技能。无论您是 Python 新手还是经验丰富的开发者,本专栏都将为您提供宝贵的知识和实践指导,让您成为一名调试高手。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Nginx终极优化手册】:提升性能与安全性的20个专家技巧
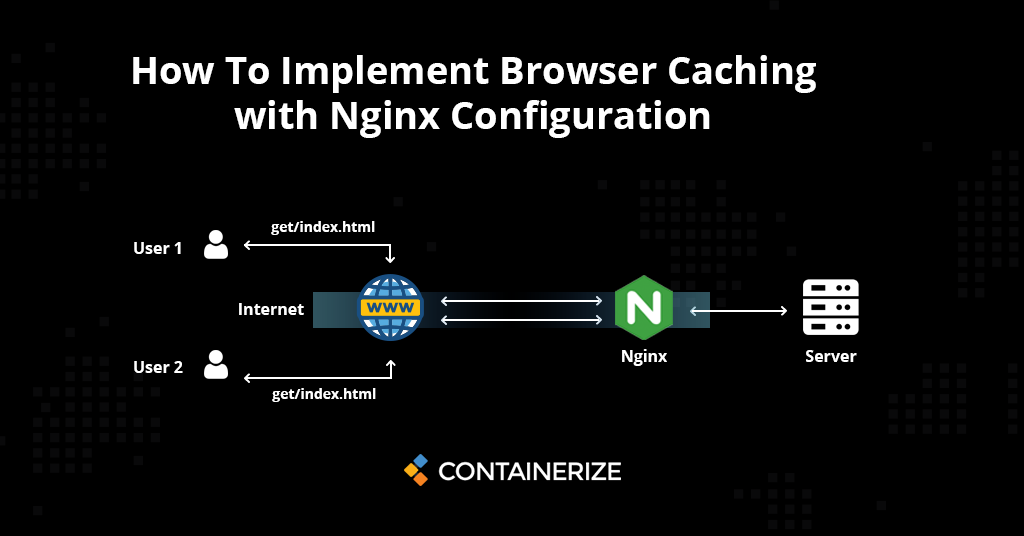
# 摘要
本文详细探讨了Nginx的优化方法,涵盖从理论基础到高级应用和故障诊断的全面内容。通过深入分析Nginx的工作原理、性能调优、安全加固以及高级功能应用,本文旨在提供一套完整的优化方案,以提升Nginx
【云计算入门】:从零开始,选择并部署最适合的云平台

# 摘要
云计算作为一种基于互联网的计算资源共享模式,已在多个行业得到广泛应用。本文首先对云计算的基础概念进行了详细解析,并深入探讨了云服务模型(IaaS、PaaS和SaaS)的特点和适用场景。随后,文章着重分析了选择云服务提供商时所需考虑的因素,包括成本、性能和安全性,并对部署策略进行了讨论,涉及不同云环境(公有云、私有云和混合云)下的实践操作指导。此外,本文还覆盖了云安全和资源管理的实践,包括
【Python新手必学】:20分钟内彻底解决Scripts文件夹缺失的烦恼!
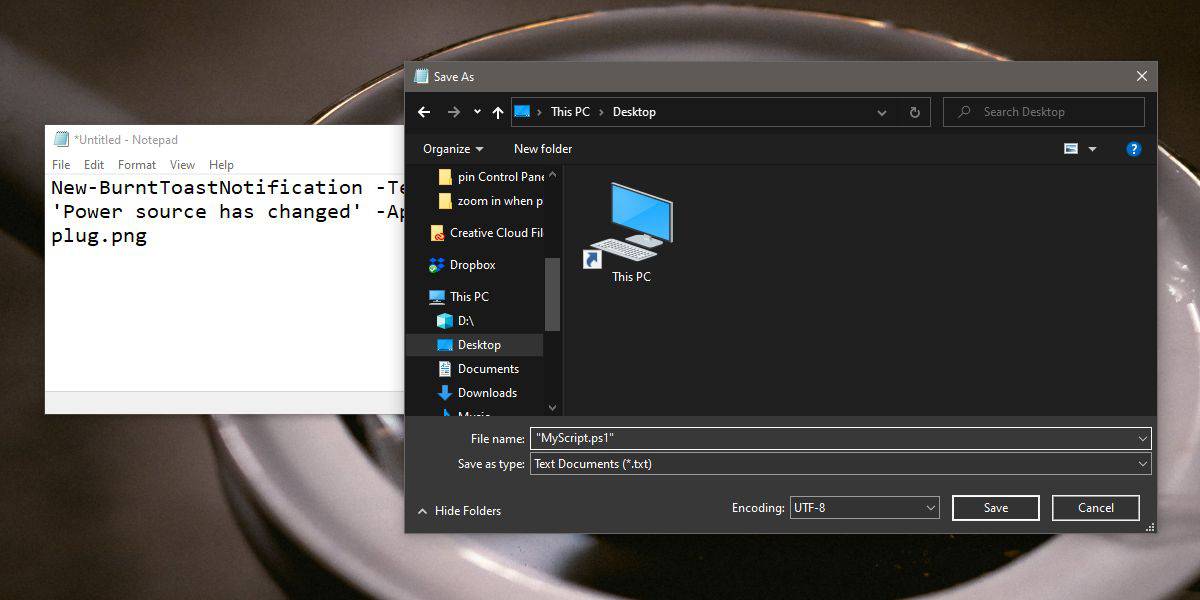
# 摘要
Python作为一种流行的编程语言,其脚本的编写和环境设置对于初学者和专业开发者都至关重要。本文从基础概念出发,详细介绍了Python脚本的基本结构、环境配置、调试与执行技巧,以及进阶实践和项目实战策略。重点讨论了如何通过模块化、包管理、利用外部库和自动化技术来提升脚本的功能性和效率。通过对Python脚本从入门到应用的系统性讲解,本文
【Proteus硬件仿真】:揭秘点阵式LED显示屏设计的高效流程和技巧
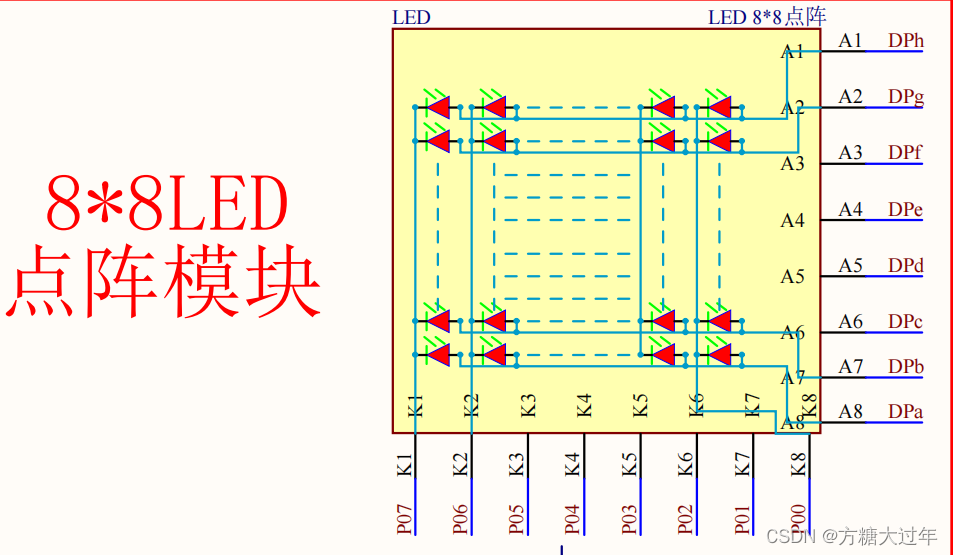
# 摘要
本论文旨在为点阵式LED显示屏的设计与应用提供全面的指导。首先介绍了点阵式LED显示屏的基础知识,并详细阐述了Proteus仿真环境的搭建与配置方法。随后,论文深入探讨了LED显示屏的设计流程,包括硬件设计基础、软件编程思路及系统集成测试,为读者提供了从理论到实践的完整知识链。此外,还分享了一些高级应用技巧,如多彩显示、微控制器接口设计、节能优化与故障预防等,以帮助读者提升产
Nginx配置优化秘籍:根目录更改与权限调整,提升网站性能与安全性

# 摘要
Nginx作为一个高性能的HTTP和反向代理服务器,广泛应用于现代网络架构中。本文旨在深入介绍Nginx的基础配置、权限调整、性能优化、安全性提升以及高级应用。通过探究Nginx配置文件结构、根目录的设置、用户权限管理以及缓存控制,本文为读者提供了系统化的部署和管理Nginx的方法。此外,文章详细阐述了Nginx的安全性增强措施,包括防止安全威胁、配置SSL/TLS
数字滤波器优化大揭秘:提升网络信号效率的3大策略
# 摘要
数字滤波器作为处理网络信号的核心组件,在通信、医疗成像以及物联网等众多领域发挥着关键作用。本文首先介绍了数字滤波器的基础知识和分类,探讨了其在信号数字化过程中的重要性,并深入分析了性能评价的多个指标。随后,针对数字滤波器的优化策略,本文详细讨论了算法效率提升、硬件加速技术、以及软件层面的优化技巧。文章还通过多个实践应用案例,展示了数字滤波器在不同场景下的应用效果和优化实例。最后,本文展望了数字滤波器未来的发展趋势,重点探讨了人工智能与机器学习技术的融合、绿色计算及跨学科技术融合的创新方向。
# 关键字
数字滤波器;信号数字化;性能评价;算法优化;硬件加速;人工智能;绿色计算;跨学科
RJ-CMS模块化设计详解:系统可维护性提升50%的秘密
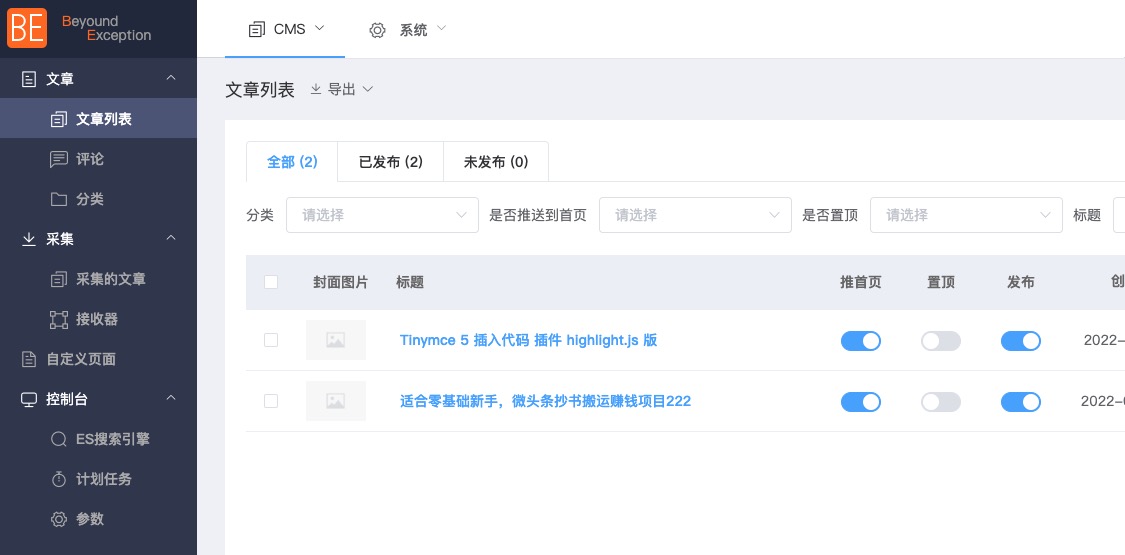
# 摘要
随着互联网技术的快速发展,内容管理系统(CMS)的模块化设计已经成为提升系统可维护性和扩展性的关键技术。本文首先介绍了RJ-CMS的模块化设计概念及其理论基础,详细探讨了模块划分、代码组织、测试与部署等实践方法,并分析了模块化系统在配置、性能优化和安全性方面的高级技术。通过对RJ-CMS模块化设计的深入案例分析,本文旨在揭示模块化设计在实际应用中的成功经验、面临的问题与挑战,并展望其未来发展趋势,以期为CMS的模块化设计提供参考和借鉴。
# 关
AUTOSAR多核实时操作系统的设计要点

# 摘要
随着计算需求的增加,多核实时操作系统在满足确定性和实时性要求方面变得日益重要。本文首先概述了多核实时操作系统及其在AUTOSAR标准中的应用,接着探讨了多核系统架构的设计原则,包括处理多核处理器的挑战、确定性和实时性以及系统可伸缩性。文章重点介绍了多核实时操作系统的关键技术,如任务调度、内存管理、中断处理及服务质量保证。通过分析实际的多核系统案例,评估了性能并提出了优化策略。最后,本文
五个关键步骤:成功实施业务参数配置中心系统案例研究

# 摘要
本文对业务参数配置中心进行了全面的探讨,涵盖了从概念解读到实际开发实践的全过程。首先,文章对业务参数配置中心的概念进行了详细解读,并对其系统需求进行了深入分析与设计。在此基础上,文档深入到开发实践,包括前端界面开发、后端服务开发以及配置管理与动态加载。接着,文中详细介绍了业务参数配置中心的部署与集成过程,包括环境搭建、系统集成测试和持续集成与自动化部署。最后,通过对成功案例的分析,文章总结了在项目实施过程中的经验教训和
Origin坐标轴颜色与图案设计:视觉效果优化的专业策略
# 摘要
本文全面探讨了Origin软件中坐标轴设计的各个方面,包括基本概念、颜色选择、图案与线条设计,以及如何将这些元素综合应用于提升视觉效果。文章首先介绍了坐标轴设计的基础知识,然后深入研究了颜色选择对数据表达的影响,并探讨了图案与线条设计的理论和技巧。随后,本文通过实例分析展示了如何综合运用视觉元素优化坐标轴,并探讨了交互性设计对用户体验的重要性。最后,文章展望了高级技术如机器学习在视觉效果设计中的应用,以及未来趋势对数据可视化学科的影响。整体而言,本文为科研人员和数据分析师提供了一套完整的坐标轴设计指南,以增强数据的可理解性和吸引力。
# 关键字
坐标轴设计;颜色选择;数据可视化;交
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )