Java排序算法进化论:冒泡到快速排序的性能飞跃
发布时间: 2024-12-23 02:49:13 阅读量: 5 订阅数: 9 

Java排序算法实现:冒泡与选择排序示例代码

# 摘要
本论文系统地探讨了Java中常用的排序算法,包括冒泡排序、插入排序和快速排序,着重于其原理、实现和性能分析。冒泡排序作为基础排序算法,通过代码实现展示了优化的必要性。插入排序介绍了基本机制及其与冒泡排序的对比,同时评估了性能。快速排序则重点讲解了其高效原理,包括分而治之的策略和分区操作,以及不同实现对性能的影响。此外,论文还比较了Java内置排序与自定义排序方法,探讨了它们在不同场景下的应用。最后,展望了排序算法的未来发展趋势,包括创新算法和大数据环境下的应用,以及研究前沿的新理论和实际案例。
# 关键字
Java排序算法;冒泡排序;插入排序;快速排序;性能分析;大数据应用
参考资源链接:[Java数据结构与算法实战:从基础知识到高级应用](https://wenku.csdn.net/doc/644b7d67fcc5391368e5ee95?spm=1055.2635.3001.10343)
# 1. Java排序算法概述
排序是计算机科学中一个基础且重要的主题,尤其在处理大量数据时,高效的排序算法可以显著提升处理速度和程序性能。Java作为一种广泛应用的编程语言,其提供的排序方法既包括高效的内置排序函数,也允许开发者根据具体需求实现自定义的排序算法。
在讨论排序算法之前,首先应该了解排序算法的目的和应用场景。排序算法的主要目标是将一组数据按照特定的顺序重新排列,比如数值大小或者字母顺序。在软件工程、数据库管理、数据处理等多个领域,排序算法都是不可或缺的工具。
排序算法按照不同的标准可以分为不同的类别,如根据比较次数来分,有比较排序和非比较排序;根据是否稳定来分,有稳定排序和不稳定排序;根据是否原地排序,也有原地排序和非原地排序之分。Java排序算法的应用涵盖了以上多个类别,以满足不同场景下的需求。
在接下来的章节中,我们将深入探讨Java中几种典型的排序算法,包括冒泡排序、插入排序和快速排序,并分析它们的原理、实现和性能表现。此外,我们还将对比Java内置排序与自定义排序的不同,并展望排序算法的未来发展趋势。通过这些内容,我们希望为Java开发者提供一个关于排序算法的全面理解和应用指南。
# 2. 冒泡排序的原理与实现
## 2.1 冒泡排序的理论基础
### 2.1.1 排序算法的基本概念
在计算机科学中,排序算法是用于将一系列元素按照一定的顺序排列的算法。排序算法的种类繁多,根据不同的算法特性,它们可以被分类为比较排序和非比较排序,稳定排序和不稳定排序,原地排序和非原地排序等。
比较排序的基本原理是通过比较两个或多个元素的大小,根据比较的结果来决定元素的顺序。冒泡排序就是其中一种简单的比较排序算法,它通过重复地遍历要排序的列表,比较相邻的元素,并在必要时交换它们的位置,直到列表被排序完成。
### 2.1.2 冒泡排序的工作原理
冒泡排序的工作原理比较直观,它重复地执行以下步骤:从列表的第一个元素开始,比较相邻的两个元素;如果前一个比后一个大,则交换它们的位置。每一轮遍历后,最大(或最小)的元素会被“冒泡”到最后的位置。重复这个过程,直到列表完全排序。
在最坏的情况下(即输入的列表是完全逆序的),冒泡排序需要进行 \(O(n^2)\) 次比较和 \(O(n^2)\) 次交换,其中 \(n\) 是列表的长度。尽管其效率较低,但由于其实现简单,通常用于教学目的来介绍排序算法。
## 2.2 冒泡排序的代码实现
### 2.2.1 简单冒泡排序的Java实现
下面是一个简单的冒泡排序算法的Java实现:
```java
public class BubbleSort {
public static void bubbleSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 交换 arr[j] 和 arr[j+1]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
public static void main(String[] args) {
int[] arr = {64, 34, 25, 12, 22, 11, 90};
bubbleSort(arr);
System.out.println("Sorted array:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
```
在这段代码中,我们首先定义了一个 `bubbleSort` 方法,该方法接受一个整数数组作为参数,并通过两层嵌套循环来完成排序。内层循环负责比较相邻元素并在必要时交换它们,外层循环负责控制遍历的轮数。`main` 方法用于测试排序功能。
### 2.2.2 改进冒泡排序的Java优化
为了提高冒泡排序的效率,可以通过引入一个布尔标志来检测在某一轮遍历中是否发生了交换。如果没有交换发生,说明列表已经排序完成,可以提前结束排序过程。以下是优化后的Java代码:
```java
public class OptimizedBubbleSort {
public static void optimizedBubbleSort(int[] arr) {
int n = arr.length;
boolean swapped;
for (int i = 0; i < n - 1; i++) {
swapped = false;
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 交换 arr[j] 和 arr[j+1]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true;
}
}
// 如果这一轮没有交换发生,则数组已排序完成
if (!swapped)
break;
}
}
public static void main(String[] args) {
int[] arr = {64, 34, 25, 12, 22, 11, 90};
optimizedBubbleSort(arr);
System.out.println("Sorted array:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
```
优化的关键在于 `swapped` 变量的引入,它会跟踪每一轮遍历中是否发生了交换。如果没有,排序提前结束,这可以减少不必要的遍历,从而提高效率。
## 2.3 冒泡排序的性能分析
### 2.3.1 时间复杂度分析
冒泡排序的时间复杂度在最好情况下为 \(O(n)\),当输入列表已经是排序好的时候,只需要经过一轮遍历,没有发生任何交换。在最坏情况下和平均情况下,时间复杂度均为 \(O(n^2)\),因为在列表完全逆序或随机顺序的情况下,需要进行多次遍历和交换。
### 2.3.2 空间复杂度分析
冒泡排序是一种原地排序算法,它的空间复杂度为 \(O(1)\),因为它只需要一个额外的存储空间来交换元素,不需要额外的存储空间来存储中间结果。
总结而言,冒泡排序由于其简单直观,易于理解和实现,常用于教育和入门级程序设计。但是由于其 \(O(n^2)\) 的时间复杂度,在处理大规模数据时并不是一个高效的算法。在实际应用中,往往会选择更高效的排序算法,如快速排序、归并排序或堆排序等。
# 3. 插入排序的优化演进
## 3.1 插入排序的基本概念
### 3.1.1 插入排序的工作机制
插入排序是一种简单直观的排序算法。它的基本思想是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。在最坏的情况下,插入排序的时间复杂度为O(n^2),但它在数据量较小或者基本有序的情况下效率较高。
插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。此算法适用于少量数据的排序,时间复杂度低,且是稳定的排序方法。
### 3.1.2 插入排序与冒泡排序的对比
插入排序和冒泡排序都是基于交换操作的排序算法,且都具有较低的算法复杂度。但二者在处理方式上有所不同。冒泡排序通过重复遍历要排序的数列,一次比较两个元素,如果顺序错误就把它们交换过来。而插入排序则是通过构建一个已排序的序列,每次从未排序的序列中取出一个元素插入到已排序序列的适当位置。
在实际的性能测试中,我们可以观察到,当数据已经部分排序时,插入排序比冒泡排序有更高的效率。然而,当数据完全无序时,冒泡排序通常会比插入排序更快,因为它每次都能保证将一个元素放到它最终的位置上。
## 3.2 插入排序的算法实现
### 3.2.1 直接插入排序的Java代码
直接插入排序的Java实现简单直接,基本步骤如下:
```java
public static void insertionSort(int[] arr) {
if (arr == null || arr.length < 2) return;
for (int i = 1; i < arr.length; i++) {
int current = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > current) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = current;
}
}
```
上述代码中的`insertionSort`方法,遍历数组,将每个元素插入到已排序的序列中。我们注意到,每一步插入操作都保证了`arr[0...i]`区域的数组元素是已经排好序的。
### 3.2.2 二分查找优化插入排序
为了减少插入排序中查找插入位置的时间复杂度,我们可以采用二分查找法来优化该过程。通过二分查找,我们可以在`O(log n)`的时间复杂度内找到插入位置,从而减少比较次数。具体的Java代码如下:
```java
public static void binaryInsertionSort(int[] arr) {
if (arr == null || arr.length < 2) return;
for (int i = 1; i < arr.length; i++) {
int current = arr[i];
int left = 0, right = i - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] > current) {
right = mid - 1;
} else {
left = mid + 1;
}
}
for (int j = i - 1; j >= left; j--) {
arr[j + 1] = arr[j];
}
arr[left] = current;
}
}
```
这段代码中`binaryInsertionSort`方法就是应用二分查找法的优化版插入排序。通过二分查找找到插入点后,将所有后续元素向后移动一位。
## 3.3 插入排序的性能评估
### 3.3.1 最佳、平均、最坏情况分析
插入排序的性能分析依赖于其执行过程中的三种情况:
- **最佳情况**:数组已经是排序好的,即每次插入操作不需要移动任何元素。此时的时间复杂度为`O(n)`。
- **平均情况**:数组中的元素随机分布,平均每次插入需要移动一半的元素。时间复杂度为`O(n^2)`。
- **最坏情况**:数组完全逆序,每次插入需要移动所有已排序的元素。时间复杂度为`O(n^2)`。
我们可以通过比较不同情况下的执行次数来分析性能。最佳情况在实际中较为罕见,但对于部分有序的数据集,插入排序表现出较好的性能。
### 3.3.2 插入排序的稳定性和空间使用
插入排序是一种稳定的排序算法,即相同的元素在排序后的相对位置不会改变。这对于需要保持相等元素相对顺序的场合非常有用。
在空间使用方面,插入排序是原地排序算法,它只需要一个很小的额外空间存放临时变量,通常只需要`O(1)`的额外空间,这使得它在空间效率上非常优秀。
插入排序在处理小规模数据集或者部分有序的数组时,效率较高。然而在面对大规模数据集时,尤其是数据完全随机的情况下,其性能无法与更高级的排序算法(如快速排序、归并排序)相匹敌。因此,选择合适的场景使用插入排序,可以发挥它的优势,避免其劣势。
# 4. 快速排序的高效原理
快速排序是一种被广泛使用的排序算法,由C. A. R. Hoare在1960年提出。快速排序之所以能够得到青睐,源于其高效的性能表现和相对简单的实现逻辑。它属于分而治之策略的典型应用,通过将大问题分割成小问题来简化问题的复杂度。本章我们将深入探讨快速排序的原理和实现,并分析其性能特点。
## 4.1 快速排序的算法设计
快速排序的核心思想是“分而治之”。它通过一个“枢轴”元素将数据分为两部分,左边部分的所有元素都不大于枢轴,而右边部分的所有元素都不小于枢轴,然后再递归地对这两部分继续进行排序。
### 4.1.1 分而治之策略
分而治之是一种解决问题的策略,它将原始问题分解为较小的问题,然后递归地解决这些子问题,最终合并子问题的解以解决原始问题。快速排序的每一次排序操作都利用了这个策略,通过递归的方式来实现整个数组的排序。
### 4.1.2 快速排序的分区操作
分区操作是快速排序的核心步骤,它的目的是选择一个基准值(pivot),然后重新排列数组,使得比基准值小的元素都在它的左边,比基准值大的元素都在它的右边。分区完成后,基准值所在的位置就是最终排序后它应该在的位置。
```java
int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准
int i = (low - 1); // 指向比基准小的元素的最后一个位置
for (int j = low; j <= high - 1; j++) {
// 如果当前元素小于或等于基准
if (arr[j] <= pivot) {
i++; // 移动指针
swap(arr, i, j); // 交换元素
}
}
swap(arr, i + 1, high); // 将基准值放到正确的位置
return (i + 1); // 返回基准值的索引
}
```
## 4.2 快速排序的编码实践
快速排序的编码实践主要包含两个部分,首先是实现标准快速排序,然后是探索优化策略以提升算法性能。
### 4.2.1 标准快速排序的Java实现
快速排序的标准实现相对简单,分为选择基准值、进行分区操作以及递归排序三个部分。
```java
void quickSort(int arr[], int low, int high) {
if (low < high) {
// pi 是枢轴的索引,arr[pi] 现在在正确的位置
int pi = partition(arr, low, high);
// 分别对枢轴左右两部分进行排序
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
```
### 4.2.2 优化快速排序的策略
快速排序虽然在平均情况下有着较高的性能,但是在最坏情况下会退化到O(n^2)的复杂度。因此,开发人员通常会采用一些优化策略来避免这种退化。
- 随机化枢轴选择:通过随机选择枢轴值来减少最坏情况发生的概率。
- 三数取中法:选择low、high和middle三个位置的中间值作为枢轴。
- 小数组切换为插入排序:当数组规模较小时,切换为插入排序通常会更高效。
- 尾递归优化:在递归调用时,尽量将递归转化为迭代,减少函数调用的开销。
## 4.3 快速排序的性能探讨
快速排序的性能分析主要围绕时间和空间复杂度展开。
### 4.3.1 快速排序的时间复杂度
快速排序的平均时间复杂度为O(n log n),而最坏情况下为O(n^2)。在枢轴选择良好的情况下,每次分区操作能将问题规模缩小一半。
### 4.3.2 空间复杂度与递归深度
快速排序的空间复杂度主要取决于递归调用的栈空间。在最坏情况下,递归深度达到O(n),因此空间复杂度为O(n)。通过尾递归优化或使用迭代版本可以减少空间复杂度。
## Mermaid 流程图:快速排序分区示例
```mermaid
graph TD
A[开始] --> B[选择基准值]
B --> C[从左向右遍历]
C --> D{比较元素与基准值}
D -- 小 --> E[交换]
E --> C
D -- 大 --> C
D -- 等于 --> C
C --> F[从右向左遍历]
F --> G{比较元素与基准值}
G -- 大 --> H[交换]
H --> F
G -- 小 --> F
G -- 等于 --> F
F --> I[交换基准值]
I --> J[分区结束]
J --> K[递归排序]
```
通过以上分析,我们可以看到快速排序的高效原理及其应用,同时也要注意其在不同场景下可能存在的性能瓶颈,并且要根据实际情况选择适当的优化策略。
# 5. Java内置排序与自定义排序对比
## 5.1 Java内置排序方法解析
### 5.1.1 Arrays.sort()与Collections.sort()的工作原理
Java为开发者提供了一系列内置排序方法,其中 Arrays.sort() 和 Collections.sort() 是两种最常见的排序方法。它们分别用于数组和集合的排序。这两种方法的背后实现在标准Java库中是高度优化的,足以满足大多数场景下的排序需求。Arrays.sort() 主要用于基本类型数组和对象数组的排序,而 Collections.sort() 用于实现了 List 接口的集合类的排序。
对于基本类型数组,Arrays.sort() 使用了 Dual-Pivot Quicksort 算法,对于对象数组,则使用了一种改进的归并排序算法。归并排序的稳定性和时间复杂度在平均和最坏情况下均表现优异,特别适合处理大量数据。当处理单个对象数组时,Java虚拟机会根据数据的特性和大小进行方法的优化选择,以达到最好的排序效率。
而 Collections.sort() 背后实际上调用的是 List 实现自带的 sort 方法。例如 ArrayList 实现使用了 TimSort 算法,这是归并排序和插入排序的混合体,对部分有序的序列具有优秀的排序效率。
### 5.1.2 自定义对象排序的实现方式
Java允许开发者为自定义对象类型定义排序规则。对于数组和集合中自定义对象的排序,我们通常需要实现 Comparable 或 Comparator 接口。Comparable 接口要求实现 compareTo() 方法,这个方法定义了对象的自然排序规则。而 Comparator 接口允许我们创建一个单独的比较器类,其中定义 compare() 方法,可以定义不同于自然排序的排序规则。
当使用 Arrays.sort() 或 Collections.sort() 对含有自定义对象的数组或集合进行排序时,如果没有提供 Comparator,则默认会调用对象的 compareTo() 方法进行排序。如果提供了 Comparator,则会根据提供的比较器进行排序。这种方式提供了极大的灵活性,使得我们能根据不同的业务需求进行排序。
## 5.2 自定义排序算法的实例应用
### 5.2.1 实现一个排序算法
假设我们需要对一个简单的 Person 对象数组进行排序。Person 类实现了 Comparable 接口,并重写了 compareTo() 方法,代码如下所示:
```java
class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person other) {
return Integer.compare(this.age, other.age);
}
// Getters and setters...
}
```
在这个例子中,我们定义了 Person 类,其中的 compareTo() 方法决定了 Person 实例将基于年龄进行排序。我们可以直接使用 Arrays.sort() 对 Person 类型的数组进行排序:
```java
Person[] people = { new Person("Alice", 25), new Person("Bob", 30), new Person("Charlie", 20) };
Arrays.sort(people);
```
这将按照年龄从小到大的顺序对 people 数组进行排序。
### 5.2.2 性能测试与比较
为了比较自定义排序算法的性能,我们可以进行简单的基准测试。以下是一个简单的基准测试示例:
```java
public static void benchmarkSorting(Comparable[] arrayToSort, int numberOfIterations) {
long startTime = System.nanoTime();
for (int i = 0; i < numberOfIterations; i++) {
Comparable[] copy = Arrays.copyOf(arrayToSort, arrayToSort.length);
Arrays.sort(copy);
}
long endTime = System.nanoTime();
System.out.println("Time taken: " + (endTime - startTime) / 1000000 + " ms");
}
```
我们可以使用这个函数来比较不同规模的数组排序所需时间,进而比较自定义排序算法与 Java 内置排序方法的性能差异。
## 5.3 排序算法的选择与应用
### 5.3.1 不同场景下的排序选择
在选择排序算法时,需要考虑以下几个因素:
- **数据规模**:对于小规模数据,冒泡排序和插入排序简单且易于理解;而大规模数据更适合快速排序、归并排序或者 TimSort。
- **数据特性**:如数组部分已排序、有序度低、稳定性要求等。
- **性能要求**:对于时间敏感或空间敏感的应用,应选择相应优化的排序算法。
例如,对于列表的排序,如果列表元素数量不大,直接使用 Collections.sort() 即可,但如果对性能有特殊要求,比如需要最小化时间复杂度,可能需要根据数据特性选择更合适的排序算法。
### 5.3.2 排序算法的适用性分析
每种排序算法都有其适用场景,没有一种算法能够适用于所有情况。通过分析不同算法的特点和优缺点,我们可以做出更合适的选择:
- **对于基本数据类型数组**:Java内置排序非常高效,通常不需要自定义排序算法。
- **对于自定义对象的排序**:当内置排序不能满足特定需求时,应实现 Comparable 或 Comparator。
- **对于大数据量的排序**:可能需要选择外部排序算法或分布式排序方法,比如 MapReduce。
- **对于并发执行的排序任务**:可以考虑并行排序算法,如并行快速排序,以提高排序效率。
以上内容展示了如何根据数据的特性选择合适的排序算法,并给出了实例应用和性能评估的参考方法。正确的排序算法选择对于提高程序性能至关重要。
# 6. 排序算法的未来发展趋势
## 6.1 排序算法的创新与挑战
### 6.1.1 非比较排序算法概述
随着计算机科学的发展,传统的基于比较的排序算法在处理大数据集时常常显示出性能瓶颈。因此,非比较排序算法逐渐成为研究热点。非比较排序包括计数排序、基数排序和桶排序等,它们根据特定的数据分布特性,通过非比较操作实现排序。
**计数排序**特别适合于那些整数且取值范围有限制的情况。其基本思想是对于每一个输入的元素x,确定小于x的元素个数,然后直接将x放到最终的位置上。计数排序不是通过比较来确定元素间的相对次序的,因此它的性能通常优于比较排序算法。
**基数排序**适用于整数的排序,通过对每一位数字进行排序,从最低有效位开始,直到最高有效位。其基本思想是将整数按位数切割成不同的数字,然后按每个位数分别比较。
**桶排序**是一种分布式排序算法,它将一个数组分成多个桶,并将每个元素分配到对应的桶里,然后再对每个桶进行排序。
这些非比较排序算法由于其特殊的适用场景,能够提供超过传统比较排序算法的性能,如O(n)的时间复杂度,但同时也有一定的局限性。
### 6.1.2 并行排序算法的发展
随着多核处理器的普及,设计和实现并行排序算法成为了提高排序性能的另一条有效路径。并行排序算法通过在多个处理单元上同时进行数据的比较和交换,能够显著加快排序速度。
常见的并行排序算法包括并行快速排序、并行归并排序等。例如,在并行快速排序中,数据集被分割成若干子集,并行地在各个处理单元上进行排序,之后再进行合并。
为了有效利用多核资源,算法设计需要考虑负载均衡和同步开销等问题。在现代处理器架构下,使用多线程技术实现并行算法,可以大幅提升大数据集的排序效率。
## 6.2 排序算法在大数据领域的应用
### 6.2.1 分布式排序简介
在大数据环境下,排序算法的应用场景扩展到了分布式计算框架上。分布式排序算法需要能够在分布式存储系统中有效工作,同时还要考虑到数据的分布和网络传输成本。
**分布式排序算法**将数据集分割成小块,分别在不同的节点上进行排序,然后将排序好的数据块合并。这一过程往往利用了外部排序和合并排序的思想,以及MapReduce等分布式计算框架。
MapReduce是Google提出的一个处理大数据集的编程模型,主要包含Map和Reduce两个步骤。在Map阶段,将数据集分割成多个小块,之后进行Map操作;在Reduce阶段,将中间结果汇总并进行排序和合并。
### 6.2.2 MapReduce框架下的排序实现
在MapReduce框架中,排序是作为Reduce阶段的一个自然结果出现的。数据首先被分割并分发到不同的Map任务,每个Map任务处理一小部分数据并输出键值对(key-value pairs)。
**排序过程**分为两步,首先Map阶段输出的键值对根据键进行局部排序,然后这些局部有序的数据被传输到Reduce任务进行全局排序和合并。由于MapReduce框架本质上就是一个分布式排序系统,它可以很好地扩展到大规模数据集上。
在实际应用中,这种排序算法的实现能够支持数以TB甚至PB级别的数据处理,非常适合于大规模数据的排序需求,例如搜索引擎索引的构建、大规模日志文件的分析等。
## 6.3 排序算法的研究前沿
### 6.3.1 算法优化的新理论
尽管传统的排序算法已经相当成熟,但研究者们依然在寻找新的优化理论以提升性能。当前的研究方向包括利用机器学习技术优化排序性能,以及寻找更优的并行排序算法。
**机器学习辅助排序**通过训练模型来预测数据的分布和排序行为,从而减少不必要的排序操作。而**自适应排序算法**可以动态调整排序策略,以适应不同数据集的特性。
**图排序**作为一种新兴的排序方法,利用图结构来表示排序问题,通过图算法对节点进行排序。这种方法对于复杂的排序依赖关系提供了新的视角。
### 6.3.2 实际应用案例分析
在实际应用中,排序算法的创新已经对多个行业产生了影响。例如,在搜索引擎中,高效的排序算法能够保证用户得到快速且相关性强的搜索结果;在金融市场分析中,复杂的排序算法能够帮助快速处理和分析大量交易数据。
**案例分析**,通过具体的数据集和应用场景,探讨了新排序算法带来的性能提升。例如,在一个大型零售公司的库存管理系统中,采用并行快速排序算法,能够将订单处理时间缩短一半以上,显著提升了业务效率。
排序算法的研究和优化,正随着技术的进步不断演进,其创新思路和应用案例,不仅在理论研究中受到重视,在实际产业应用中也显示出了巨大的价值和潜力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎阅读《Java数据结构与算法》专栏,本专栏将带您深入探索Java数据结构与算法的奥秘。从基础概念到进阶技巧,我们将为您提供全面的提升策略。通过深入解析数据结构的应用实例,您将掌握性能优化的秘诀。我们还将探究排序算法的进化历程,从冒泡排序到快速排序的性能飞跃。
此外,专栏还涵盖了链表优化术、数组与矩阵操作高效指南、动态规划算法实践、回溯算法精讲、搜索算法优化、并发编程数据结构选择、堆与堆排序原理、二分查找进阶、数据结构与算法内存管理、位操作优化术以及单调栈与队列应用等主题。通过深入浅出的讲解和丰富的示例,本专栏将帮助您提升Java数据结构与算法技能,为您的编程能力添砖加瓦。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
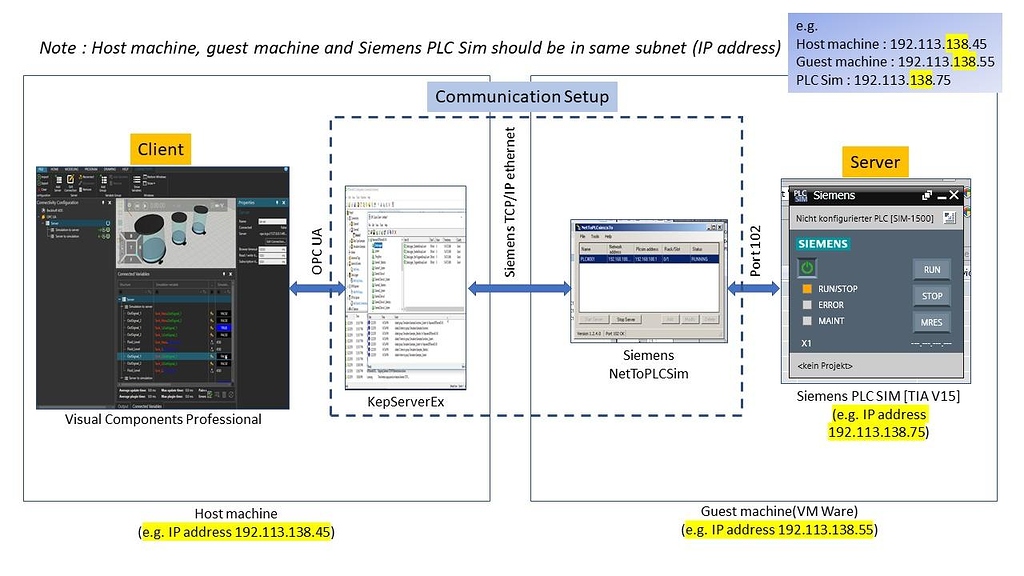
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
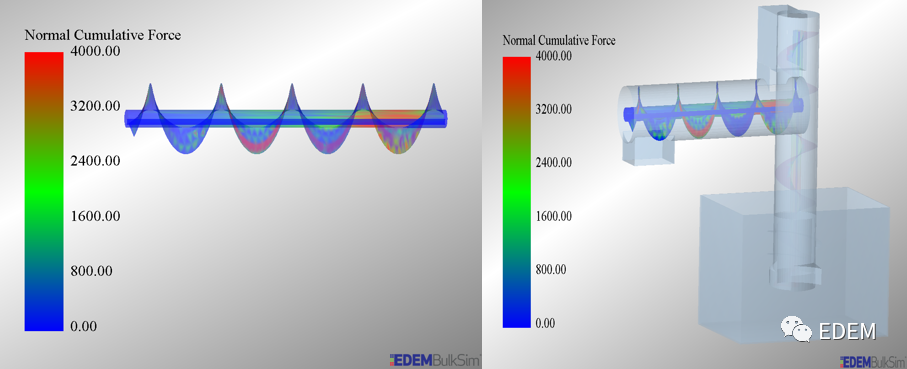
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
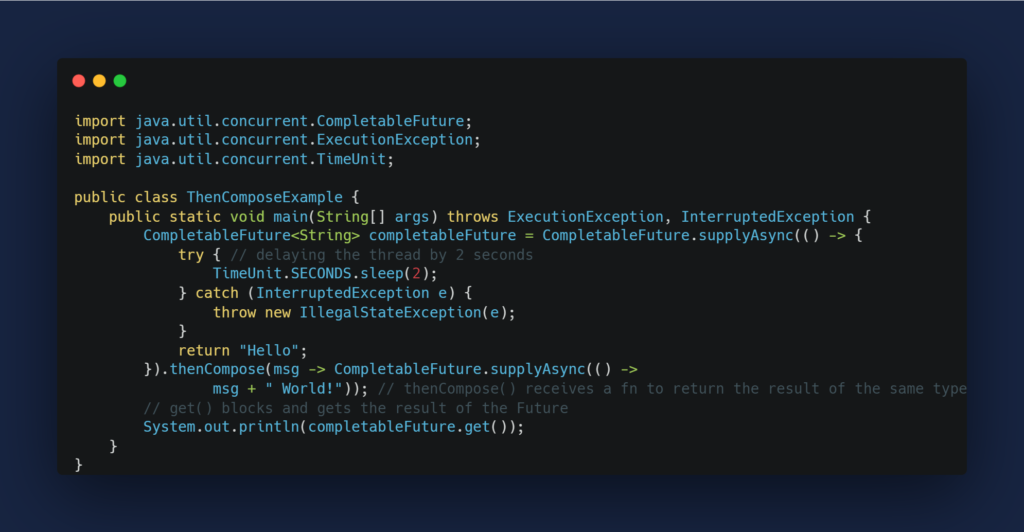
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
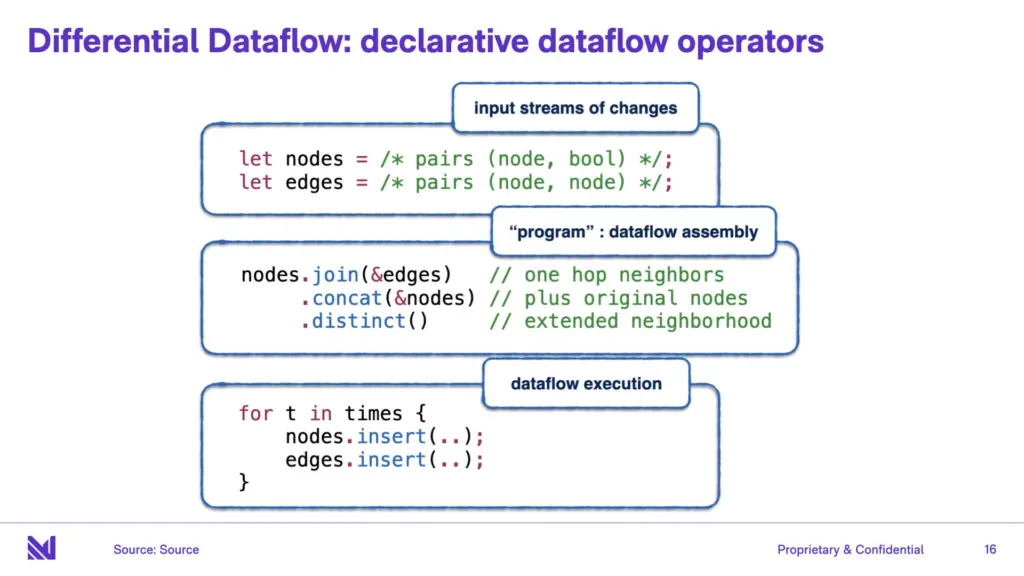
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )