利用Python进行数据清洗与预处理
发布时间: 2024-03-12 20:54:34 阅读量: 97 订阅数: 43 
# 1. 引言
数据在当今社会中起着至关重要的作用,然而原始数据往往存在着许多问题,如数据缺失、异常值等,这就需要对数据进行清洗与预处理。数据清洗与预处理是数据分析过程中不可或缺的环节,它可以帮助我们提高数据质量、减少错误影响,从而得到更准确的分析结果。
## 数据清洗与预处理的重要性
数据清洗与预处理的重要性不言而喻。原始数据可能包含有错误、异常值或者缺失值,如果直接将这些数据用于分析建模,将会导致结果的不准确性,甚至错误的结论。因此,通过数据清洗与预处理,可以有效地净化数据,提高数据的质量与可靠性,为后续的数据分析与建模奠定坚实基础。
## Python在数据清洗与预处理中的作用
Python作为一种功能强大且易于使用的编程语言,在数据科学领域得到了广泛的应用。在数据清洗与预处理的过程中,Python拥有丰富的数据处理库和工具,如Pandas、NumPy、Scikit-learn等,这些工具提供了丰富的函数和方法,能够帮助我们高效地进行数据清洗与预处理工作。通过Python的强大功能和丰富的库支持,数据清洗与预处理变得更加简单、高效。
# 2. 数据清洗
数据清洗是数据处理流程中至关重要的一步,它涉及到对数据质量进行评估、处理缺失值和异常值等工作,确保数据的准确性和完整性。在这一章节中,我们将深入探讨数据清洗的各个方面以及如何利用Python进行数据清洗。
### 2.1 数据质量评估与处理
在进行数据清洗之前,首先需要对数据的质量进行评估。常见的数据质量问题包括重复值、不一致的数据格式、缺失值等。通过Python的Pandas库,我们可以轻松地进行数据质量评估和处理。
```python
# 导入Pandas库
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 检测重复值
duplicate_rows = data[data.duplicated()]
print("重复行数:", duplicate_rows.shape[0])
# 处理重复值
data.drop_duplicates(inplace=True)
# 检查缺失值
missing_values = data.isnull().sum()
print("缺失值统计:")
print(missing_values)
```
通过上述代码,我们可以对数据进行重复值和缺失值的评估,并采取相应的处理措施来提高数据质量。
### 2.2 缺失值处理
缺失值是实际数据处理中常见的问题,对于缺失值的处理可以选择删除、插值或填充等方式。在Python中,Pandas库提供了丰富的方法来处理缺失值。
```python
# 填充缺失值
data.fillna(data.mean(), inplace=True)
```
上述代码展示了一种简单的方法,通过均值填充缺失值。当然,针对不同场景,我们也可以选择其他填充策略来处理缺失值。
### 2.3 异常值处理
异常值可能会对数据分析和建模产生不良影响,因此需要对异常值进行识别和处理。Python的数据处理库提供了多种方法来检测和处理异常值,例如基于统计学方法和机器学习方法。
```python
# 基于标准差的异常值检测
threshold = 3
mean = data['column'].mean()
std = data['column'].std()
outliers = data[(data['column'] - mean).abs() > threshold * std]
print("异常值:", outliers)
```
通过以上代码,我们可以利用数据的均值和标准差来检测异常值,然后可以选择删除、替换或进行其他处理方式来应对异常值问题。
数据清洗是数据分析过程中不可或缺的一环,通过合理的数据清洗流程,可以提高数据的质量和可靠性,为后续的分析和建模奠定基础。
# 3. 数据预处理
数据预处理在机器学习和数据分析中扮演着至关重要的角色。在许多情况下,原始数据并不适合直接用于建模分析,这就需要对数据进行预处理,包括数据标准化与归一化、数据变换与转换以及特征选择与降维等步骤。
#### 3.1 数据标准化与归一化
数据标准化(Normalization)和数据归一化(Standardization)是常见的数据预处理手段,用于确保数据在不同维度上具有可比性,以便于模型的训练和优化。
数据标准化通过减去均值并除以标准差的方式,将数据转换为均值为0,标准差为1的分布。而数据归一化则是通过将数据按其范围进行缩放,使其值落入特定范围,最常见的是将数据缩放到0~1或者-1~1的范围内。
以下是使用Python进行数据标准化与归一化的示例代码:
```python
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 创建示例数据
data = pd.DataFrame({'A': [10, 20, 30, 40, 50],
'B': [1, 2, 3, 4, 5]})
# 数据标准化
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
print("Standardized Data:\n", standardized_data)
# 数据归一化
min_max_scaler = MinMaxScaler()
normalized_data = min_max_scaler.fit_transform(data)
print("Normalized Data:\n", normalized_data)
```
代码总结:以上代码演示了如何使用`StandardScaler`和`MinMaxScaler`对数据进行标准化和归一化处理,分别得到了标准化后的数据和归一化后的数据。
结果说明:经过标准化和归一化处理后,数据的值得到了相应的转换和缩放,使得数据在不同维度上具有可比性。
#### 3.2 数据变换与转换
数据变换与转换是数据预处理的另一个重要环节,它包括对数据进行平滑化、聚合、离散化等操作,以便更好地适应模型的需求。
常见的数据变换与转换操作包括对数变换、指数变换、多项式变换等。这些操作可以帮助调整数据的分布特性,使其更符合模型的假设前提。
以下是使用Python进行数据变换与转换的示例代码:
```python
import pandas as pd
import numpy as np
from sklearn.preprocessing import FunctionTransformer
# 创建示例数据
data = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10]})
# 对数变换
log_transformer = FunctionTransformer(np.log1p, validate=True)
log_transformed_data = log_transformer.transform(data)
print("Log Transformed Data:\n", log_transformed_data)
```
代码总结:以上代码展示了如何使用`FunctionTransformer`对数据进行对数变换,得到了对数变换后的数据。
结果说明:通过对数变换操作,数据得到了相应的对数转换,使其更符合模型的假设前提。
# 4. Python数据清洗工具介绍
数据清洗是数据预处理的重要步骤,而Python作为一种广泛应用的编程语言,拥有丰富的库和工具,能够帮助我们高效地进行数据清洗工作。在本章中,我们将介绍Python中主要用于数据清洗的工具,并结合实际案例进行说明。
#### 4.1 Pandas库的基本概述
Pandas是Python中用于数据操作和分析的重要库,它提供了快速、灵活、简单和富有表现力的数据结构,使得数据清洗和预处理变得更加容易,包括数据的索引、合并、切片、聚合等操作。
#### 4.2 Pandas库在数据清洗中的应用
在数据清洗中,Pandas库提供了丰富的功能,例如:
- 数据读取:Pandas可以方便地读取多种格式的数据,如CSV、Excel、SQL数据库等。
- 缺失值处理:Pandas提供了fillna()方法来填补缺失值,dropna()方法来删除缺失值所在行或列。
- 异常值处理:Pandas可以通过设定阈值或条件来识别和处理异常值。
#### 4.3 示例:使用Pandas清洗数据的实际案例
接下来,让我们通过一个实际案例来演示Pandas库在数据清洗中的应用。假设我们有一个销售数据的CSV文件,需要对其进行清洗和预处理以便进行分析。
```python
# 导入Pandas库
import pandas as pd
# 读取CSV文件
sales_data = pd.read_csv('sales.csv')
# 查看数据缺失情况
print("缺失值数量:\n", sales_data.isnull().sum())
# 填补缺失值
sales_data['sales'].fillna(sales_data['sales'].mean(), inplace=True)
# 删除异常值
sales_data = sales_data[sales_data['sales'] < 10000]
# 保存清洗后的数据
sales_data.to_csv('cleaned_sales_data.csv', index=False)
```
在这个示例中,我们首先使用Pandas库读取了销售数据的CSV文件,然后查看并处理了数据的缺失值和异常值,最后将清洗后的数据保存到了新的CSV文件中。这展示了Pandas在数据清洗中的强大功能。
以上示例展示了Pandas在数据清洗中的简单应用,实际上Pandas还提供了更多丰富的功能来满足不同场景下的数据清洗需求。在实际工作中,我们可以根据具体的数据情况来灵活运用Pandas库进行数据清洗工作。
# 5. Python数据预处理工具介绍
数据预处理在数据科学中占据着至关重要的地位,能够有效提高数据挖掘和机器学习模型的准确性和效果。Python提供了丰富的数据预处理工具,其中Scikit-learn库是其中最为常用和强大的工具之一。
#### 5.1 Scikit-learn库的基本概述
Scikit-learn是一个开源的Python机器学习库,它包含了各种工具用于数据挖掘和数据分析。Scikit-learn提供了简单而高效的数据预处理功能,使数据清洗和特征工程变得更加便捷和高效。
#### 5.2 Scikit-learn库在数据预处理中的应用
Scikit-learn库提供了丰富的数据预处理功能,包括数据标准化、数据变换、特征选择、降维等多种操作。下面是一些Scikit-learn库常用的数据预处理方法:
- 数据标准化:使用`StandardScaler`对数据进行标准化处理,使得数据服从标准正态分布。
- 数据变换:通过`PolynomialFeatures`可以进行数据的多项式特征构造,增加数据的多样性。
- 特征选择:使用`SelectKBest`可以根据给定的得分函数选择前K个最重要的特征。
- 降维:通过`PCA`(Principal Component Analysis)可以实现数据的降维处理,减少特征的数量同时保留数据的主要信息。
#### 5.3 示例:使用Scikit-learn进行数据预处理的实际案例
下面是一个简单的示例,演示如何使用Scikit-learn库对数据进行预处理:
```python
# 导入所需的库
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 创建一个示例数据集
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# 数据降维
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(scaled_data)
print("原始数据集:\n", data)
print("标准化后的数据集:\n", scaled_data)
print("降维后的数据集:\n", reduced_data)
```
**代码总结:**
1. 通过`StandardScaler`对数据进行标准化处理。
2. 利用`PCA`对标准化后的数据进行降维操作。
3. 最终输出原始数据集、标准化后的数据集和降维后的数据集。
**结果说明:**
- 原始数据集包含3行3列的数据。
- 经过数据标准化处理后,数据被转换成符合标准正态分布的数据。
- 经过PCA降维处理后,数据被压缩为2维数据,保留了较多的主要信息。
通过这个示例,可以看到Scikit-learn库在数据预处理中的强大功能,能够帮助我们高效地处理数据,为后续的建模工作提供更好的数据基础。
# 6. 结语
数据清洗与预处理是数据分析过程中至关重要的一步,Python作为一种强大的编程语言,在数据清洗与预处理领域发挥了巨大作用。通过利用Python中丰富的数据处理库和工具,可以高效地清洗和预处理各种类型的数据,为后续的建模和分析工作奠定良好的基础。
#### 6.1 总结Python在数据清洗与预处理中的优势
- **丰富的库支持**:Python拥有诸多优秀的数据处理库,如Pandas、NumPy、Scikit-learn等,提供了丰富的函数和工具,极大地简化了数据清洗与预处理的流程。
- **灵活性与可扩展性**:Python具有较高的灵活性,不仅可以应对常见的数据清洗需求,还可以根据具体情况编写自定义的处理逻辑,满足个性化的数据处理需求。
- **强大的可视化支持**:Python的数据可视化库(如Matplotlib、Seaborn等)可以帮助分析人员直观地理解数据的分布特征,有助于更好地进行数据清洗与预处理。
#### 6.2 展望数据清洗与预处理的未来发展方向
- **自动化与智能化**:未来随着人工智能技术的发展,数据清洗与预处理过程将更加自动化与智能化,能够识别和处理更多复杂的数据异常情况。
- **实时处理与大数据**:随着大数据时代的来临,数据清洗与预处理需求将更加迫切,未来的发展将更加强调对实时数据的处理能力。
- **跨学科整合**:数据清洗与预处理不再仅限于数据领域,未来可能会更多地整合计算机科学、统计学、人工智能等多个领域的知识,为数据分析提供更加全面与深入的支持。
通过不断地学习和探索,我们将能够更好地应对日益复杂的数据清洗与预处理挑战,为数据驱动的决策和应用提供可靠的数据基础。让我们共同期待数据处理技术的未来发展,为构建更加智能、高效的数据处理系统而努力奋斗。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
XGBoost时间序列分析:预测模型构建与案例剖析
# 1. 时间序列分析与预测模型概述
在当今数据驱动的世界中,时间序列分析成为了一个重要领域,它通过分析数据点随时间变化的模式来预测未来的趋势。时间序列预测模型作为其中的核心部分,因其在市场预测、需求计划和风险管理等领域的广泛应用而显得尤为重要。本章将简单介绍时间序列分析与预测模型的基础知识,包括其定义、重要性及基本工作流程,为读者理解后续章节内容打下坚实基础。
# 2. XGB
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
LSTM在语音识别中的应用突破:创新与技术趋势

# 1. LSTM技术概述
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。不同于标准的RNN结构,LSTM引入了复杂的“门”结构来控制信息的流动,这允许网络有效地“记住”和“遗忘”信息,解决了传统RNN面临的长期依赖问题。
## 1
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
从GANs到CGANs:条件生成对抗网络的原理与应用全面解析
.jpg)
# 1. 生成对抗网络(GANs)基础
生成对抗网络(GANs)是深度学习领域中的一项突破性技术,由Ian Goodfellow在2014年提出。它由两个模型组成:生成器(Generator)和判别器(Discriminator),通过相互竞争来提升性能。生成器负责创造出逼真的数据样本,判别器则尝试区分真实数据和生成的数据。
## 1.1 GANs的工作原理
【深度学习与AdaBoost融合】:探索集成学习在深度领域的应用

# 1. 深度学习与集成学习基础
在这一章中,我们将带您走进深度学习和集成学习的迷人世界。我们将首先概述深度学习和集成学习的基本概念,为读者提供理解后续章节所必需的基础知识。随后,我们将探索这两者如何在不同的领域发挥作用,并引导读者理解它们在未来技术发展中的潜在影响。
## 1.1 概念引入
深度学习是机器学习的一个子领域,主要通过多
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
梯度提升树的并行化策略:训练效率提升的秘诀
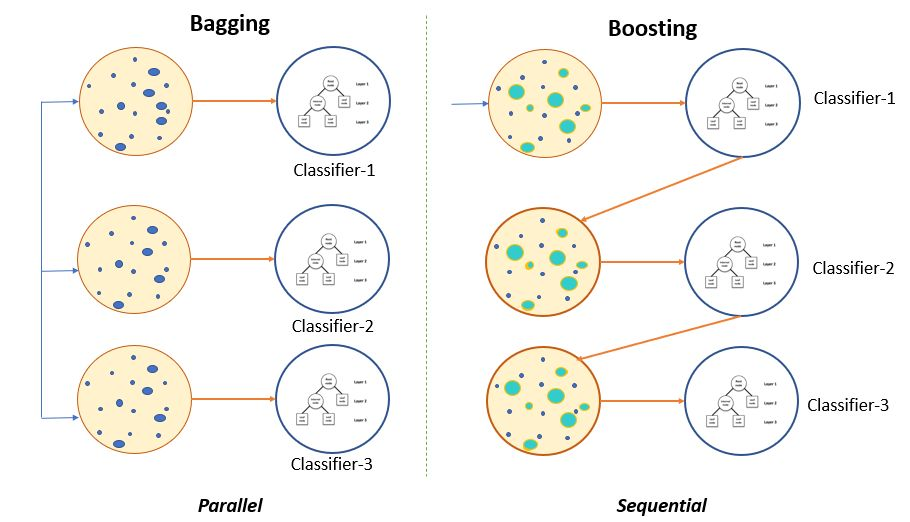
# 1. 梯度提升树模型概述
在机器学习领域,梯度提升树(Gradient Boosting Tree,GBT)是一种广泛使用的集成学习算法,以其高效性、灵活性和模型解释性而受到青睐。本章将首先介绍梯度提升树的历史背景和发展,然后阐述其与随机森林等其他集成算法的区别和联系,为读者提供一个关于梯度提升树模型的全面概述。
梯度提升树模型最初由J. H. Frie
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )