【Go语言文件读写实战】:构建高效文件处理流程
发布时间: 2024-10-23 13:56:36 阅读量: 18 订阅数: 16 

桫哥-GOlang基础-Go语言实战:驾考系统

# 1. Go语言文件读写的基本概念
在软件开发中,文件读写是进行数据持久化操作的基本要求。Go语言作为一种高效的系统编程语言,提供了丰富的库来实现文件的读写操作。在深入学习Go语言的文件读写API之前,我们首先要理解文件读写的基本概念,这包括了解文件系统的基本工作原理,文件读写的模式(如文本模式和二进制模式),以及文件指针的概念,这些都将为后续更高级的操作打下坚实的基础。
在本章中,我们将覆盖以下主题:
- 文件系统的基本工作原理。
- 文件读写的模式及其选择。
- 文件指针及其在文件读写中的作用。
接下来的章节将具体讨论如何使用Go语言进行文件的打开、读取、写入以及关闭等操作,并介绍相关的API函数和技巧。这将为我们构建更加复杂和高效的文件处理流程奠定基础。
# 2. Go语言文件读写的核心API
### 2.1 文件读取操作
#### 2.1.1 使用os.Open()打开文件
Go语言中,处理文件的首要步骤是使用`os.Open()`函数打开文件。这个函数的定义如下:
```go
func Open(name string) (*File, error) {
// 具体实现细节
}
```
`os.Open()`函数用于打开指定路径`name`的文件,并返回一个表示文件的`*File`对象和一个`error`对象。如果文件成功打开,则`error`为`nil`,否则包含错误信息。
```go
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("example.txt")
if err != nil {
fmt.Printf("Failed to open ***\n", err)
return
}
defer file.Close()
// 继续后续操作...
}
```
在上述代码中,我们尝试打开一个名为`example.txt`的文件。若文件不存在或路径错误,将打印出错误信息。`defer file.Close()`确保文件在操作结束后正确关闭。
#### 2.1.2 文件读取方法与技巧
一旦成功打开了文件,接下来需要读取文件的内容。Go语言提供了多种读取文件的方法:
- `Read()`: 从文件中读取数据到缓冲区。
- `ReadAt()`: 从文件的特定位置开始读取数据。
- `ReadByte()` 和 `ReadRune()`: 读取文件中的下一个字节和字符。
- `Peek()`: 预览文件中的下一个字节。
下面是使用`Read()`方法读取文件内容的一个例子:
```go
package main
import (
"fmt"
"io"
"os"
)
func main() {
file, err := os.Open("example.txt")
if err != nil {
fmt.Printf("Failed to open ***\n", err)
return
}
defer file.Close()
buf := make([]byte, 1024)
for {
n, err := file.Read(buf)
if err != nil {
if err != io.EOF {
fmt.Printf("Read error: %s\n", err)
}
break
}
fmt.Print(string(buf[:n]))
}
}
```
在这个例子中,我们创建了一个足够大的缓冲区`buf`用于读取文件内容。每次调用`file.Read(buf)`都会尝试将文件的数据读取到`buf`中,并返回读取到的字节数和可能发生的错误。如果遇到文件结束标志`io.EOF`,则表示文件已读完,循环结束。
#### 2.1.3 按行读取与缓冲读取
在很多应用场景中,我们可能希望按行读取文件,而不是一次性读取整个文件内容。为了按行读取,我们可以编写一个辅助函数,利用`bufio`包提供的`Scanner`对象:
```go
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
file, err := os.Open("example.txt")
if err != nil {
fmt.Printf("Failed to open ***\n", err)
return
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Printf("Read failed: %s\n", err)
}
}
```
在上述代码中,`bufio.NewScanner(file)`创建了一个新的Scanner对象,该对象会逐行扫描文件内容。`scanner.Scan()`遍历文件的每一行,`scanner.Text()`返回当前行的文本内容。如果在读取过程中遇到错误,则会通过`scanner.Err()`返回。
缓冲读取是指在读取数据时,使用一个临时缓冲区来存储数据,减少系统调用次数,提高文件读取效率。`bufio`包中的`Buffered()`方法可以返回当前的缓冲区大小,这有助于理解缓冲读取的机制:
```go
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
file, err := os.Open("example.txt")
if err != nil {
fmt.Printf("Failed to open ***\n", err)
return
}
defer file.Close()
reader := bufio.NewReader(file)
buffer := make([]byte, 4096)
for {
n, err := reader.Read(buffer)
if err != nil {
if err != io.EOF {
fmt.Printf("Read error: %s\n", err)
}
break
}
fmt.Print(string(buffer[:n]))
}
}
```
在本例中,我们使用`bufio.NewReader(file)`为文件创建了一个`bufio.Reader`对象,该对象内部包含了一个缓冲区。通过`reader.Read(buffer)`,我们读取数据到外部提供的缓冲区`buffer`,之后再处理这些数据。
### 2.2 文件写入操作
#### 2.2.1 使用os.Create()创建和打开文件
要写入文件,首先需要创建或打开文件。在Go语言中,`os.Create()`函数可以用来创建一个新文件或打开一个已存在的文件进行写入。函数定义如下:
```go
func Create(name string) (*File, error) {
// 具体实现细节
}
```
此函数尝试创建一个新的文件,或者如果文件已存在则截断该文件。如果文件创建成功,`*File`对象将被返回,否则返回错误。
```go
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Create("example.txt")
if err != nil {
fmt.Printf("Failed to create ***\n", err)
return
}
defer file.Close()
// 接下来可以写入数据到file中...
}
```
上述代码中,如果`example.txt`文件不存在,则会创建一个新的文件,如果已存在,则会清空原有内容后重新写入。
#### 2.2.2 文件写入方法与缓冲技术
文件写入通常涉及到写入缓冲区的管理。Go语言中文件对象提供了写入数据的方法,如`Write()`, `WriteString()`, `WriteByte()`, 和`WriteRune()`。为了高效地管理写入缓冲,`io`和`bufio`包提供了一些工具,比如`Writer`和`BufferedWriter`。
这里是一个例子,展示如何使用`bufio`包提供的`BufferedWriter`来缓冲写入操作:
```go
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
file, err := os.Create("example.txt")
if err != nil {
fmt.Printf("Failed to create ***\n", err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
fmt.Fprintf(writer, "Line %d\n", i)
}
writer.Flush()
}
```
在这个例子中,我们创建了一个`bufio.Writer`对象。通过循环写入10行文本数据到文件中。`Flush()`方法确保所有缓冲数据被写入文件。
#### 2.2.3 文件追加模式与原子写入
有时我们希望能够追加内容到文件而不是覆盖现有内容。Go语言中的`os.OpenFile()`函数支持文件的追加模式:
```go
func OpenFile(name string, flag int, perm os.FileMode) (*File, error) {
// 具体实现细节
}
```
将`flag`参数设置为`os.O_APPEND`即可开启追加模式。
```go
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.OpenFile("example.txt", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0666)
if err != nil {
fmt.Printf("Failed to open ***\n", err)
return
}
defer file.Close()
_, err = file.WriteString("Additional line\n")
if err != nil {
fmt.Printf("Failed to write to ***\n", err)
}
}
```
此外,原子写入是一种确保写入操作的完整性与安全性的技术,其通过确保写入过程不会被中断来避免数据损坏。在Go中,我们可以通过临时文件和`os.Rename()`函数来模拟原子写入:
```go
package main
import (
"io/ioutil"
"os"
)
func atomicWrite(data []byte) error {
tmpfile, err := ioutil.TempFile("", "atomic")
if err != nil {
return err
}
defer os.Remove(tmpfile.Name())
_, err = tmpfile.Write(data)
if err != nil {
return err
}
return os.Rename(tmpfile.Name(), "example.txt")
}
func main() {
err := atomicWrite([]byte("Atomically written data\n"))
if err != nil {
fmt.Printf("Failed to perform atomic write: %s\n", err)
}
}
```
在上述代码中,我们先写入数据到临时文件,然后再将临时文件重命名为目标文件。这个过程是原子的,因为`os.Rename()`要么完全成功,要么完全失败,从而保证了数据的完整性。
### 2.3 文件元数据处理
#### 2.3.1 获取文件状态信息
获取文件的状态信息是文件管理中常见的需求。Go语言的`os`包提供了`File`类型的`Stat()`方法,可以用来获取文件状态信息:
```go
type Stat_t struct {
//
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 Go 语言的文件系统操作,涵盖了从基础到高级的各个方面。通过一系列深入的文章,您将掌握精通文件系统的 10 大技巧,学习监控和实时响应文件变化的秘诀,了解减少内存消耗的策略,以及构建高效文件处理流程的方法。此外,您还将探索文件安全指南,了解权限管理和数据完整性校验,并掌握代码可维护性提升秘诀。专栏还深入研究了文件压缩、解压、编码和加密技术,以及处理大文件的最佳实践。通过对错误处理和元数据操作的深入探索,您将全面了解 Go 语言的文件系统操作。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Zkteco智慧多地点管理ZKTime5.0:集中控制与远程监控完全指南

# 摘要
本文对Zkteco智慧多地点管理系统ZKTime5.0进行了全面的介绍和分析。首先概述了ZKTime5.0的基本功能及其在智慧管理中的应用。接着,深入探讨了集中控制系统的理论基础,包括定义、功能、组成架构以及核心技术与优势。文章详细讨论了ZKTime5.0的远程监控功能,着重于其工作原理、用户交互设计及安全隐私保护。实践部署章节提供了部署前准备、系统安装配置
Java代码安全审查规则解析:深入local_policy.jar与US_export_policy.jar的安全策略

# 摘要
本文系统探讨了Java代码安全审查的全面方法与实践。首先介绍了Java安全策略文件的组成及其在不同版本间的差异,对权限声明进行了深入解析。接着,文章详细阐述了进行安全审查的工具和方法,分析了安全漏洞的审查实例,并讨论了审查报告的撰写和管理。文章深入理解Java代码安
数字逻辑深度解析:第五版课后习题的精华解读与应用

# 摘要
数字逻辑作为电子工程和计算机科学的基础,其研究涵盖了从基本概念到复杂电路设计的各个方面。本文首先回顾了数字逻辑的基础知识,然后深入探讨了逻辑门、逻辑表达式及其简化、验证方法。接着,文章详细分析了组合逻辑电路和时序逻辑电路的设计、分析、测试方法及其在电子系统中的应用。最后,文章指出了数字逻辑电路测试与故障诊断的重要性,并探讨了其在现代电子系统设计中的创新应用
【CEQW2监控与报警机制】:构建无懈可击的系统监控体系

# 摘要
监控与报警机制是确保信息系统的稳定运行与安全防护的关键技术。本文系统性地介绍了CEQW2监控与报警机制的理论基础、核心技术和应用实践。首先概述了监控与报警机制的基本概念和框架,接着详细探讨了系统监控的理论基础、常用技术与工具、数据收集与传输方法。随后,文章深入分析了报警机制的理论基础、操作实现和高级应用,探讨了自动化响应流程和系统性能优化。此外,本文还讨论了构建全面监控体系的架构设计、集成测试及维
电子组件应力筛选:IEC 61709推荐的有效方法

# 摘要
电子组件在生产过程中易受各种应力的影响,导致性能不稳定和早期失效。应力筛选作为一种有效的质量控制手段,能够在电子组件进入市场前发现潜在的缺陷。IEC 61709标准为应力筛选提供了理论框架和操作指南,促进了该技术在电子工业中的规范化应用。本文详细解读了IEC 61709标准,并探讨了应力筛选的理论基础和统计学方法。通过分析电子组件的寿命分
ARM处理器工作模式:剖析7种运行模式及其最佳应用场景

# 摘要
ARM处理器因其高性能和低功耗的特性,在移动和嵌入式设备领域得到广泛应用。本文首先介绍了ARM处理器的基本概念和工作模式基础,然后深入探讨了ARM的七种运行模式,包括状态切换、系统与用户模式、特权模式与异常模式的细节,并分析了它们的应用场景和最佳实践。随后,文章通过对中断处理、快速中断模式和异常处理模式的实践应用分析,阐述了在实时系统中的关键作用和设计考量。在高级应用部分,本文讨论了安全模式、信任Z
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
海康二次开发进阶篇:高级功能实现与性能优化

# 摘要
随着安防监控技术的发展,海康设备二次开发在智能视频分析、AI应用集成及云功能等方面展现出越来越重要的作用。本文首先介绍了海康设备二次开发的基础知识,详细解析了海康SDK的架构、常用接口及集成示例。随后,本文深入探讨了高级功能的实现,包括实时视频分析技术、AI智能应用集成和云功能的
STM32F030C8T6终极指南:最小系统的构建、调试与高级应用
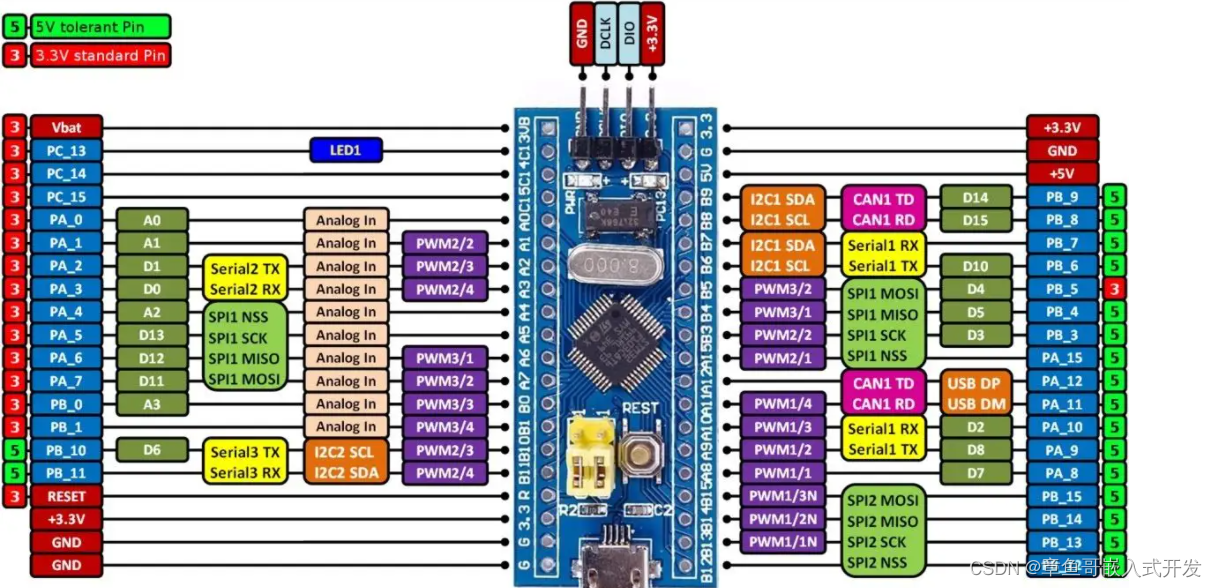
# 摘要
本论文全面介绍了STM32F030C8T6微控制器的关键特性和应用,从最小系统的构建到系统优化与未来展望。首先,文章概述了微控制器的基本概念,并详细讨论了构建最小系统所需的硬件组件选择、电源电路设计、调试接口配置,以及固件准备。随后,论文深入探讨了编程和调试的基础,包括开发环境的搭建、编程语言的选择和调试技巧。文章还深入分析了微控制器的高级特性,如外设接口应用、中断系统优化、能效
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )