【R语言基础教程揭秘】:数据处理与图形绘制的绝对指南
发布时间: 2024-11-08 21:06:28 阅读量: 22 订阅数: 50 

R语言大作业教程:数据挖掘与分析
# 1. R语言简介与安装配置
## R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它是基于S语言发展起来的,广泛应用于数据分析、机器学习、生物信息学等领域。R语言的特点是开源、灵活、功能强大,特别适合处理大数据和复杂的数据分析任务。
## R语言的安装与配置
为了使用R语言,首先需要在操作系统上安装R。对于Windows用户,可以访问CRAN(The Comprehensive R Archive Network)网站下载R的安装程序并执行安装。Mac用户可以在Homebrew的仓库中通过命令行安装R。安装完成后,建议安装RStudio,这是一个流行的R语言集成开发环境(IDE),提供了代码编写、调试和图形界面展示等功能。
### Windows系统的R语言安装步骤:
1. 访问CRAN网站:[***](***
** 选择对应版本的下载链接,例如选择“Download R for Windows”。
3. 下载安装程序并运行,遵循安装向导的提示完成安装。
4. 下载并安装RStudio。
### Mac系统的R语言安装步骤:
1. 打开终端。
2. 输入安装命令:`brew install r`。
3. 下载并安装RStudio。
安装完成后,可以运行RStudio检查是否成功配置。在RStudio的控制台中输入简单的R命令,比如`print("Hello, R!")`,如果显示结果,说明安装配置成功。现在,你已经准备好使用R语言开始数据科学之旅了。
# 2. R语言基础语法和数据结构
## 2.1 R语言的数据类型和变量
R语言是一种强类型语言,这意味着在进行操作之前,必须先声明变量的数据类型。理解R语言中的不同数据类型对于编写有效且高效的代码至关重要。
### 2.1.1 基本数据类型:数值、字符、逻辑
R语言的三种基本数据类型是数值(numeric)、字符(character)、逻辑(logical)。
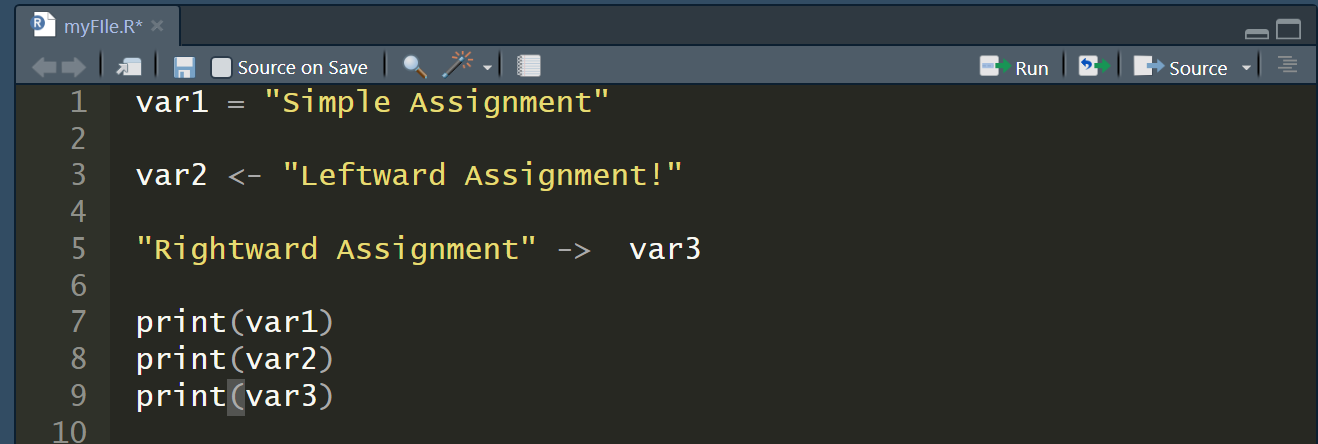
- **数值(Numeric)**:用于表示整数和浮点数。例如,`x <- 10` 和 `y <- 3.14` 均为数值类型。
- **字符(Character)**:用于表示文本信息,字符数据需要用引号括起来。例如,`str <- "R Language"`。
- **逻辑(Logical)**:只有三种可能的值:`TRUE`、`FALSE`和`NA`(表示缺失值)。例如,`bool <- TRUE`。
代码块示例:
```r
# 创建数值、字符和逻辑变量
num <- 5 # 数值变量
char <- "Hello" # 字符变量
logic <- TRUE # 逻辑变量
# 输出变量类型
typeof(num)
typeof(char)
typeof(logic)
```
上述代码块创建了三种基本类型的数据变量,并使用`typeof()`函数来查询它们的数据类型。
### 2.1.2 向量、矩阵、数组的创建与操作
向量、矩阵和数组是R中用于存储数据的结构。它们可以包含数值、字符或逻辑值。
- **向量(Vector)**:是R中最基本的数据结构。它是一维的元素集合。可以使用`c()`函数创建向量。例如,`vec <- c(1, 2, 3)`。
- **矩阵(Matrix)**:是一个二维数组,所有元素都必须是相同的数据类型。可以使用`matrix()`函数创建矩阵。例如,`m <- matrix(1:6, nrow=2, ncol=3)`。
- **数组(Array)**:是多维的数据结构,可以存储多于两维的数据。可以使用`array()`函数创建数组。例如,`ar <- array(1:24, dim=c(2,3,4))`。
代码块示例:
```r
# 创建向量、矩阵和数组
vector <- c(1, 2, 3)
matrix <- matrix(1:9, nrow=3, ncol=3)
array <- array(1:24, dim=c(2,3,4))
# 输出结构信息
length(vector) # 向量长度
dim(matrix) # 矩阵维度
dim(array) # 数组维度
```
在上述代码块中,我们创建了一个向量、一个矩阵和一个数组,并使用`length()`、`dim()`函数来获取它们的维度信息。
## 2.2 R语言的控制结构
R语言提供了控制结构,以实现程序的条件判断和循环控制,以及编写自定义函数。
### 2.2.1 条件判断语句
在R中,可以使用`if`、`else`、`ifelse`等语句来进行条件判断。
- **if语句**:`if (condition) {action}`,如果条件为`TRUE`,则执行动作。
- **if-else语句**:`if (condition) {action1} else {action2}`,条件为`TRUE`时执行`action1`,为`FALSE`时执行`action2`。
- **ifelse函数**:`ifelse(condition, value_if_true, value_if_false)`,它接受向量化的条件,并返回一个相同长度的结果向量。
代码块示例:
```r
# 条件判断示例
if (3 > 2) {
print("3 is greater than 2")
} else {
print("3 is not greater than 2")
}
result <- ifelse(c(1, 2, 3) > 2, "greater", "less")
print(result)
```
上述代码展示了如何使用`if`和`ifelse`语句进行条件判断。`if`语句用于单独的条件判断,而`ifelse`可以应用于向量化的条件判断。
### 2.2.2 循环控制结构
R语言提供了`for`、`while`、`repeat`等循环控制结构。
- **for循环**:`for (i in seq) {do something}`,其中`i`是序列`seq`中的每一个元素。
- **while循环**:`while (condition) {do something}`,只要条件为`TRUE`,就会执行循环体。
- **repeat循环**:`repeat {do something}`,这是一个无限循环,必须在循环体内部使用`break`语句来跳出循环。
代码块示例:
```r
# for循环示例
for (i in 1:3) {
print(i)
}
# while循环示例
count <- 1
while (count <= 3) {
print(count)
count <- count + 1
}
# repeat循环示例
repeat {
print("This is a repeat loop")
break # 使用break退出循环
}
```
上述代码分别展示了如何使用`for`、`while`和`repeat`循环。`for`循环用于已知次数的迭代,`while`循环用于基于条件的迭代,`repeat`循环通常配合`break`使用来控制退出条件。
### 2.2.3 函数的定义与调用
在R中,可以定义自己的函数来执行特定任务,也可以调用系统内置的函数。
- **定义函数**:`function_name <- function(arg1, arg2, ...) {body}`,函数的定义以`function`关键字开始。
- **调用函数**:函数通过它的名字后跟括号来调用。例如,`function_name(arg1, arg2, ...)`。
代码块示例:
```r
# 定义并调用一个简单的函数
add <- function(a, b) {
return(a + b)
}
# 调用函数
result <- add(3, 4)
print(result)
```
上述代码展示了如何定义一个加法函数`add`,并且如何调用它来得到两个数字的和。
## 2.3 R语言的包管理和导入导出
R语言的强大功能在很大程度上归功于其丰富的扩展包。这些包包含了一系列函数和数据集,用于特定任务。
### 2.3.1 包的安装和加载
要使用一个包,首先需要安装它,然后使用`library()`函数加载到R环境中。
- **安装包**:`install.packages("package_name")`,在R控制台或脚本中使用此命令安装包。
- **加载包**:`library(package_name)`,加载安装的包到R的搜索路径,使其函数和数据集可被使用。
代码块示例:
```r
# 安装和加载一个包
install.packages("dplyr") # 安装dplyr包
library(dplyr) # 加载dplyr包
# 使用包中的函数
iris %>%
filter(Species == "setosa") %>%
summarize(mean(Sepal.Width))
```
上述代码首先安装并加载了`dplyr`包,然后使用它提供的管道操作符和`filter`、`summarize`函数来对`iris`数据集进行操作。
### 2.3.2 数据的导入导出方法
在R中,可以导入导出多种格式的数据,例如CSV、Excel、JSON等。
- **导入数据**:使用`read.csv()`、`read_excel()`、`jsonlite::fromJSON()`等函数可以导入不同格式的数据。
- **导出数据**:使用`write.csv()`、`write_excel()`、`jsonlite::toJSON()`等函数可以导出不同格式的数据。
代码块示例:
```r
# 导入CSV数据
data_csv <- read.csv("path/to/data.csv", header=TRUE)
# 导出CSV数据
write.csv(data_csv, "path/to/output.csv", row.names=FALSE)
# 导入Excel数据
data_excel <- readxl::read_excel("path/to/data.xlsx")
# 导出Excel数据
writexl::write_excel(data_excel, "path/to/output.xlsx")
```
上述代码展示了如何使用`read.csv`和`write.csv`函数来导入和导出CSV文件,以及如何使用`readxl`包中的`read_excel`函数导入Excel文件,并用其`write_excel`函数导出Excel文件。
以上是关于R语言基础语法和数据结构的详细介绍。在下一章,我们将进一步探讨R语言的数据处理实战技巧。
# 3. R语言数据处理实战
在数据科学领域,数据处理是至关重要的环节,它关系到分析结果的准确性和可用性。R语言提供了强大的数据处理功能,无论是数据清洗、预处理、分组聚合,还是数据的连接与合并,在R中都有成熟的函数和方法来实现。本章将带你深入掌握R语言在数据处理方面的实战技能。
## 3.1 数据清洗和预处理
数据清洗是数据预处理的第一步,它涉及到删除重复数据、处理缺失值、修正异常值等一系列操作。R语言通过一系列的函数和包,帮助用户高效完成这些任务。
### 3.1.1 缺失值的处理
在数据集中,缺失值是很常见的问题。R语言内置了多种处理缺失值的函数,如`is.na()`, `na.omit()`, 和 `complete.cases()` 等。
```r
# 创建一个包含缺失值的向量
data_vector <- c(1, 2, NA, 4, 5)
# 检测缺失值
missing_values <- is.na(data_vector)
# 移除缺失值
cleaned_vector <- na.omit(data_vector)
# 查看清除缺失值后的数据
print(cleaned_vector)
```
在上述代码中,`is.na()` 函数用于检测向量中的缺失值,返回一个逻辑向量。`na.omit()` 函数移除了含有缺失值的元素。通过这些函数,我们可以对数据集进行初步的清洗。
### 3.1.2 异常值的检测与处理
异常值的检测与处理是数据预处理的重要组成部分。在R中,我们可以使用一些统计方法来识别异常值。例如,使用标准差和均值来定义异常值。
```r
# 创建一个数据框,包含可能的异常值
data_frame <- data.frame(
x = c(10, 12, 15, 14, 120)
)
# 计算均值和标准差
mean_value <- mean(data_frame$x, na.rm = TRUE)
sd_value <- sd(data_frame$x, na.rm = TRUE)
# 定义异常值为均值加减两倍标准差之外的值
threshold_upper <- mean_value + 2 * sd_value
threshold_lower <- mean_value - 2 * sd_value
# 检测异常值
outliers <- data_frame$x[data_frame$x < threshold_lower | data_frame$x > threshold_upper]
# 处理异常值,例如替换为均值
data_frame <- within(data_frame, {
x[x < threshold_lower] <- threshold_lower
x[x > threshold_upper] <- threshold_upper
})
```
在这段代码中,我们首先计算了数据框中数据的均值和标准差。然后,我们定义了异常值的阈值为均值加减两倍标准差。接着,我们用这些阈值检测数据中的异常值。最后,我们选择了将异常值替换为阈值来处理这些值。
### 3.1.3 数据的转换和重构
数据转换和重构通常包括数据类型的转换、数据的标准化、归一化等操作。在R中,`as.factor()`, `scale()` 等函数可以帮助我们完成这些任务。
```r
# 创建一个数据框
data_frame <- data.frame(
name = c("Alice", "Bob", "Charlie"),
score = c(85, 90, 100)
)
# 将字符型数据转换为因子型数据
data_frame$name <- as.factor(data_frame$name)
# 数据标准化
data_frame$score_scaled <- scale(data_frame$score)
```
在此例中,我们首先创建了一个数据框。然后,我们使用`as.factor()`函数将字符型的姓名转换为因子型数据,这在进行分类分析时非常有用。接着,我们使用`scale()`函数对分数进行标准化处理,使得数据处理更加标准化。
数据清洗和预处理是后续数据处理和分析的基础。熟练掌握这些技能对于任何数据科学家来说都是至关重要的。在本章后续内容中,我们将深入探讨数据分组与聚合操作、数据连接与合并等更加高级的数据处理技术。
## 3.2 数据分组与聚合操作
### 3.2.1 分组操作的实现
在数据分析中,根据某些条件对数据进行分组是常见需求。R语言的`dplyr`包提供了`group_by()`函数来实现这一需求。
```r
# 加载dplyr包
library(dplyr)
# 创建数据框
data_frame <- data.frame(
group = c("A", "A", "B", "B", "C"),
value = c(10, 20, 30, 40, 50)
)
# 根据group列对数据进行分组
grouped_data <- group_by(data_frame, group)
# 查看分组后的数据框
print(grouped_data)
```
上述代码中,`group_by()`函数将数据框根据group列进行分组。之后,我们可以对每个分组应用聚合函数。
### 3.2.2 聚合函数的应用
聚合函数用于对分组后的数据进行汇总操作,如求和、计数、平均值等。`summarise()` 函数在`dplyr`包中提供了这种功能。
```r
# 对分组后的数据应用聚合函数
summary_data <- summarise(grouped_data,
count = n(),
sum_value = sum(value),
mean_value = mean(value))
# 查看聚合后的结果
print(summary_data)
```
在这里,`summarise()`函数计算了每个组的行数(`n()`函数)、总和(`sum()`函数)和平均值(`mean()`函数)。通过这种方式,我们可以轻松地对数据进行汇总和分析。
## 3.3 数据连接与合并
### 3.3.1 行列合并
数据连接与合并是数据处理中的重要环节,它涉及到不同数据集之间的数据整合。R语言中的`merge()`函数和`dplyr`包的`left_join()`、`right_join()`、`inner_join()`、`full_join()`等函数可用于执行不同的数据连接操作。
```r
# 创建两个数据框
data_frame1 <- data.frame(
id = c(1, 2, 3),
value1 = c(10, 20, 30)
)
data_frame2 <- data.frame(
id = c(2, 3, 4),
value2 = c(40, 50, 60)
)
# 使用merge()函数进行内连接
merged_inner <- merge(data_frame1, data_frame2, by = "id", all = FALSE)
# 使用dplyr包的inner_join()函数
library(dplyr)
inner_join_result <- inner_join(data_frame1, data_frame2, by = "id")
# 查看连接后的数据框
print(merged_inner)
print(inner_join_result)
```
这段代码演示了如何使用`merge()`函数和`dplyr`的`inner_join()`函数实现内连接。在`merge()`函数中,`by`参数指定用于连接的列,`all = FALSE`表示只返回两个数据集中都有的行。
### 3.3.2 数据表的连接操作
数据表的连接操作有多种类型,除了内连接,还有左连接、右连接、全外连接等。这些操作对于整合来自不同来源的数据非常有用。
```r
# 使用dplyr包进行左连接
left_join_result <- left_join(data_frame1, data_frame2, by = "id")
# 使用dplyr包进行右连接
right_join_result <- right_join(data_frame1, data_frame2, by = "id")
# 使用dplyr包进行全外连接
full_join_result <- full_join(data_frame1, data_frame2, by = "id")
# 查看不同连接类型的结果
print(left_join_result)
print(right_join_result)
print(full_join_result)
```
以上代码使用了`dplyr`包中的连接函数,演示了左连接、右连接和全外连接的使用方法。这些操作根据数据框中的id列将两个数据集连接在一起。在左连接中,所有左侧数据框的行都会被保留,右侧数据框中对应的行如果不存在则会填充为NA;右连接则是保留右侧数据框的所有行;全外连接则会保留两个数据框中的所有行。
通过本章的内容,我们介绍了R语言在数据处理方面的实战技能,从数据清洗、预处理,到数据分组、聚合操作,再到数据连接与合并。掌握了这些技能,你将能够对数据进行有效的准备,为后续的数据分析和建模打下坚实的基础。
# 4. R语言图形绘制技巧
R语言不仅是一个强大的统计分析工具,同时它在图形绘制方面也有着出色的表现。本章节将深入探讨R语言图形绘制的各种技巧,从基础图形的绘制到统计图形的展示,再到图形的高级定制与输出,我们将一步步地了解如何利用R语言制作出美观且信息丰富的图形。
## 4.1 基础图形绘制
### 4.1.1 高级绘图函数概述
在R语言中,基础图形系统提供了大量用于创建和定制图形的函数。这些函数可以分为三大类:高级绘图函数、低级绘图函数和交互式函数。高级绘图函数如`plot()`, `hist()`, `boxplot()`等,用于生成基本图形。低级绘图函数则用于在现有图形基础上添加额外的图形元素,比如点、线、文本等。交互式函数可以用来缩放、旋转图形或对特定区域进行注释。
### 4.1.2 常用图形的绘制和定制
以下将通过例子说明如何使用高级绘图函数绘制常用图形,并进行定制:
```r
# 绘制一个简单的散点图
plot(mtcars$wt, mtcars$mpg,
main="汽车重量与油耗关系图",
xlab="汽车重量(千磅)",
ylab="油耗(英里/加仑)",
pch=19,
col="blue")
# 添加线性回归线
abline(lm(mtcars$mpg~mtcars$wt), col="red")
```
上述代码块首先使用`plot()`函数绘制了一个散点图,然后利用`abline()`函数添加了一条线性回归线。`pch`参数控制点的样式,`col`参数设置颜色。
## 4.2 统计图形展示
### 4.2.1 条形图、直方图的绘制
条形图和直方图是展示分类数据和数据分布最直观的图表类型。R语言中可以通过`barplot()`和`hist()`函数来绘制这两种图形。
```r
# 条形图
counts <- table(mtcars$gear)
barplot(counts,
main="不同档位汽车数量",
xlab="档位",
ylab="数量",
col=c("red", "green", "blue"))
# 直方图
hist(mtcars$mpg,
main="汽车油耗分布图",
xlab="油耗(英里/加仑)",
col="lightblue",
breaks=12)
```
### 4.2.2 散点图和回归线的添加
散点图能够展示两个变量之间的关系,通过`plot()`函数可以轻松绘制,`abline()`函数可以用来添加回归线。
```r
# 散点图
plot(mtcars$wt, mtcars$mpg,
main="汽车重量与油耗关系图",
xlab="汽车重量(千磅)",
ylab="油耗(英里/加仑)",
pch=19,
col="blue")
# 添加线性回归线
abline(lm(mtcars$mpg~mtcars$wt), col="red")
```
## 4.3 图形的高级定制与输出
### 4.3.1 图形参数的详细定制
R语言允许用户对图形的每一个细节进行定制,包括但不限于点的形状、颜色、线型、图例的位置等。R语言内置了很多参数,通过组合这些参数可以制作出满足特定需求的图形。
```r
# 绘制一个带有自定义主题的散点图
plot(mtcars$wt, mtcars$mpg,
main="定制主题的散点图",
xlab="汽车重量(千磅)",
ylab="油耗(英里/加仑)",
pch=20, # 点的样式
col="darkgreen", # 点的颜色
bg="yellow", # 点的填充颜色
cex=1.5, # 点的大小
lwd=2) # 线宽
# 添加自定义轴线
axis(1, at=seq(1,6,0.5), col.axis="blue")
axis(2, at=seq(10,40,5), col.axis="blue")
```
### 4.3.2 图形的导出和保存
制作好的图形可以通过`png()`, `jpeg()`, `pdf()`等函数导出为图像文件。这些函数会创建一个绘图设备,后续的图形会保存在这个文件中。
```r
# 导出为PNG格式的图像文件
png(filename="scatterplot.png")
plot(mtcars$wt, mtcars$mpg,
main="导出的散点图",
xlab="汽车重量(千磅)",
ylab="油耗(英里/加仑)")
dev.off()
```
以上是对R语言在图形绘制方面的详细介绍,它不仅仅可以制作基础的统计图形,还可以通过精细的定制让图形更具表现力,最后还可以方便地导出为不同格式的图像文件。在数据分析和报告中,图形的力量往往比文字更加直观和有效,因此掌握这些图形绘制技巧对于R语言用户来说是非常重要的。
# 5. R语言综合应用案例分析
## 5.1 实际数据分析流程概述
### 5.1.1 数据分析项目的规划和执行
数据分析项目往往需要从项目规划开始,这包括定义业务问题、确定项目目标、收集和清洗数据、分析数据、解释结果并提出建议。在R语言中,这通常涉及以下步骤:
1. **定义问题和目标**:明确业务需求,确保数据分析可以解决实际问题。
2. **数据收集**:使用各种方法(如API调用、网络爬虫、直接从数据库导出)收集数据。
3. **数据清洗**:使用R语言中如`dplyr`、`tidyr`等包进行数据清洗,处理缺失值、异常值、格式不一致等问题。
4. **探索性数据分析**:运用统计图形和描述性统计,寻找数据的潜在模式和关系。
5. **模型构建**:根据数据特性选择合适的算法(如线性回归、决策树、聚类分析等)进行模型构建。
6. **结果解释和报告**:解释模型结果,撰写报告,向非技术背景的利益相关者传达发现。
### 5.1.2 数据挖掘的常用算法和模型
R语言提供了丰富的方法和算法来进行数据挖掘。一些常见的算法包括:
- **线性回归(`lm()`函数)**:用于预测连续值。
- **逻辑回归(`glm()`函数,指定family参数为binomial)**:用于二分类问题。
- **决策树(`rpart`包)**:非参数模型,用于分类和回归问题。
- **随机森林(`randomForest`包)**:集成学习方法,通过构建多个决策树进行预测。
- **聚类分析(`kmeans()`函数)**:无监督学习方法,用于分组数据。
## 5.2 复杂数据集的分析处理
### 5.2.1 大数据集的处理技巧
随着数据量的增加,R语言的单核处理能力可能成为瓶颈。处理大数据集时,可以采用以下技巧:
- **使用`data.table`包**:该包比传统的`data.frame`更高效,尤其适用于大数据集的读写和操作。
- **并行计算(`parallel`包)**:R可以利用多核处理器进行并行计算,提高数据处理速度。
- **数据库连接(`DBI`、`dplyr`包)**:将数据存储在数据库中,并使用SQL语言进行数据操作。
- **内存管理**:定期清理无用对象,利用R的`gc()`函数进行内存垃圾回收。
### 5.2.2 多变量分析方法
分析多个变量之间的关系时,可以使用多元统计方法,其中包括:
- **主成分分析(PCA, `prcomp`或`princomp`函数)**:降维技术,用于探索变量之间的内部结构。
- **因子分析(`factanal`函数)**:用于分析变量之间的潜在关系。
- **聚类分析(`hclust`函数)**:使用层次聚类方法对样本或变量进行分组。
## 5.3 R语言在特定领域的应用
### 5.3.1 生物信息学中的应用实例
R语言在生物信息学领域有着广泛的应用,例如:
- **基因表达分析**:使用`limma`、`edgeR`等包进行差异表达分析。
- **系统生物学**:利用`Bioconductor`项目提供的工具进行基因组、转录组、蛋白质组等数据的分析。
- **生物标志物的识别**:通过统计模型识别疾病相关基因。
### 5.3.2 金融数据分析案例
在金融数据分析中,R语言通常用于:
- **风险管理**:通过`fGarch`、`rugarch`等包构建风险模型,进行VaR计算。
- **时间序列分析**:`forecast`包可用来进行时间序列预测。
- **投资组合优化**:利用`portfolio`包构建最优投资组合。
通过这些案例,我们可以看到R语言在处理实际问题中的强大能力和灵活性。下一章将详细介绍R语言在图形绘制方面的技巧。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 R 语言数据分析和可视化专栏!本专栏将带你从零基础入门 R 语言,一步步掌握数据处理、图形绘制、数据包管理、函数自定义、数据可视化、文本处理、GUI 制作、数据库交互等实用技能。专栏内容涵盖初学者必读的安装和基础绘图教程,以及进阶学习的 dplyr、data.table、shiny、ggvis 等数据包奥秘和实战技巧。此外,还提供探索性数据分析、数据预处理、数据可视化案例研究等进阶内容,帮助你深入挖掘数据价值。无论你是数据分析新手还是经验丰富的专家,都能在这里找到适合你的学习资源,提升你的 R 语言技能,成为一名数据分析高手!
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入理解单站架构:平衡客户体验与服务可靠性的终极指南

# 摘要
随着企业数字化转型的加速,单站架构因其简洁高效的设计而备受青睐。本文首先对单站架构进行定义,阐述其优势,并在理论框架下详细介绍了单站架构的设计原则、技术选型、组件集成、数据管理、用户界面设计、性能优化策略、用户个性化服务、系统可靠性保障、监控机制以及持续集成与部署等多个方面。本文还通过案例研究分析了单站架构在不同行业的成功应用,并提出了应对隐私与合规性挑战的策略。最后,本文展望了单站架构未来可能的发展趋势,特别是新兴技术如何融合进单站架构中,以及服务
PCI Geomatica高级玩家进阶:环境配置优化秘籍

# 摘要
PCI Geomatica是一个功能强大的遥感和地理信息系统(GIS)软件,广泛应用于地球科学数据处理。本文首先介绍了PCI Geomatica的基本概念、安装流程,并重点分析了环境配置的重要性,包括操作系统兼容性、硬件要求以及软件依赖和版本控制。文章还探讨了优化PCI Geomatica性能的实践技巧,涉及性能测试、环境优化及常见错误排除方法。此外,本文深入阐述了集群与分布式计算环境配置、内存与存储管理优化、自
【FANUC与S7-1200数据交换终极指南】:提升效率的关键秘诀

# 摘要
本文详细探讨了FANUC与S7-1200在工业自动化领域进行数据交换的概念、原理、实践指南和案例分析,并对提升效率及维护数据交换的安全性与规范性进行了深入研究。首先解析了FANUC与S7-1200数据交换的基本概念,并介绍了实现数据交换的通信协议基础和硬件连接细节。随后,本文提供了详细的编程交互指南,包括编程环境的准备、实例
TestU01进阶技巧大公开:定制化测试套件的开发与应用指南

# 摘要
本论文对TestU01测试工具进行了全面介绍,并详细阐述了定制化测试套件的理论基础、开发实践以及高级应用。首先,我们探讨了测试套件的设计原则、类型选择和维护更新,为开发高质量的测试套件奠定了理论基础。随后,介绍了TestU01测试套件开发环境的搭建、测试用例的编写、集成和测试过程。在此基础上
【SERDES故障诊断】:一文解决信号完整性问题

# 摘要
本文首先概述了SERDES技术及其在故障诊断中的重要性,接着深入探讨了信号完整性(SI)的基础理论,包括其定义、影响因素、问题表现与分类,以及测量技术。第三章着重于SERDES故障诊断的实践技巧,涵盖诊断流程、工具和案例分析,并讨论了信号完整性问题的定位与修复。第四章介绍了高级故障诊断技术与工具,包括信号完整性分析工具、信号仿真软件的使用
【i386架构与现代编程实践】:融合与创新的5种方法

# 摘要
本文深入探讨了i386架构的历史和技术细节,分析了现代编程语言的发展及与i386架构的兼容性,并讨论了操作系统层面对i386架构的支持与创新融合。同时,本文还考察了i386在嵌入式开发领域的应用,以及软硬件协同设计的实践。最后,本文展望了i386架构的未来挑战与转型策略,特别是在云计算、大数据、人工智能等新兴技术冲击下的适应性与安全
【上位机安全防护】:实战指南教你如何设计固若金汤的安全性策略

# 摘要
上位机安全防护是确保信息技术系统可靠运行的关键领域。本文首先概述了上位机安全防护的概念及其重要性,随后详细探讨了安全策略设计的基础,包括安全性需求分析、理论框架的建立和风险管理。第三章着重于实用安全防护技术,涵盖了端点防护、网络安全和访问控制等领域。第四章阐述了安全策略实施和监控的流程,包括策略的部署、安全监控和事件响应以及审计和合规性。第五章通过案例研究提供了行业安全策略的深入分析和最佳实践。最后,第六章展望了未
【系统稳定关键】:IBM x3650 RAID监控与报警的全面指南
# 摘要
本文详细探讨了IBM x3650服务器中RAID技术的监控和报警机制。首先提供了RAID基础的概览,并阐述了监控RAID系统稳定性的理论与实践。随后,本文深入分析了硬件RAID卡和软件工具的监控参数,以及如何解读监控数据。进一步,文章介绍了设置RAID报警阈值的重
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )