Python脚本效率提升秘籍:20个优化技巧教你如何飞速执行
发布时间: 2024-09-20 08:32:06 阅读量: 170 订阅数: 66 

LABVIEW程序实例-DS写属性数据.zip

# 1. Python脚本优化概览
Python因其简洁明了的语法和强大的功能库支持,已成为众多开发者首选的编程语言。然而,随着项目的不断增长和复杂化,代码的运行效率成为了不少开发者头疼的问题。在这一章中,我们将从宏观角度审视Python脚本优化的必要性和优化策略。本章的核心目标是为读者提供一个全面的优化视野,为后续章节中深入探讨代码结构优化、数据处理提速、内存与资源管理以及并发编程提升性能等具体优化措施打下基础。
Python脚本优化不仅仅是提升代码的执行速度,还包括优化开发效率、代码的可读性和可维护性等多个方面。通过优化,可以让Python脚本更高效地运行,同时降低资源消耗,提高应用性能和稳定性。本章将引导读者理解优化的长远价值,并激发起对后续章节中更深入内容的学习兴趣。
# 2. 代码结构优化
## 2.1 理解Python的GIL
### 2.1.1 全局解释器锁的概念
Python中的全局解释器锁(GIL)是一个设计上的特性,它确保了任一时刻,只有一个线程可以执行Python字节码。这个机制最初是为了防止对Python内存进行多线程并发写操作,从而避免了复杂且难以发现的bug。然而,这也意味着即使在多核处理器上,多线程程序也无法有效地并行执行Python代码。
由于GIL的存在,在CPU密集型任务中,多线程可能无法提供预期的性能提升。在这些情况下,多进程编程往往是一个更好的选择,因为它能够利用多核处理器的优势。然而,多进程编程也有其自身的复杂性和资源消耗。
### 2.1.2 多线程中的限制及其应对策略
当使用Python进行多线程编程时,遇到GIL的限制时,可以通过以下策略来优化性能:
- **使用多进程**:对于CPU密集型任务,可以使用`multiprocessing`模块来创建多个进程,每个进程拥有自己的Python解释器和内存空间,从而绕过GIL的限制。
- **利用I/O密集型优化**:由于GIL在等待I/O操作时会释放,因此对于I/O密集型任务,多线程仍然是有效的,可以提升整体性能。
- **使用线程池**:对于频繁进行I/O操作的场景,可以使用`concurrent.futures`模块中的线程池(ThreadPoolExecutor),这样可以减少线程创建和销毁的开销。
- **结合C扩展**:将计算密集型代码用C语言重写,并作为Python扩展使用,可以绕过GIL的限制,因为C代码可以释放GIL,利用多线程进行并行计算。
### 2.1.2 多线程中的限制及其应对策略代码示例
以下示例展示了如何使用多进程来解决因GIL导致的性能瓶颈问题:
```python
import multiprocessing
def cpu_bound_task(n):
return sum(i * i for i in range(n))
def main():
with multiprocessing.Pool(processes=4) as pool:
# 假设有一个非常耗CPU的任务
result = pool.map(cpu_bound_task, [***, ***, ***, ***])
print(result)
if __name__ == '__main__':
main()
```
在这个例子中,我们创建了一个进程池,并将耗时的CPU任务分配给多个进程去执行,从而绕过了GIL的限制。每个进程都可以在其自己的Python解释器上独立运行,充分利用多核CPU的优势。
## 2.2 利用列表推导式简化代码
### 2.2.1 列表推导式的基础使用
列表推导式是Python中一种简洁且高效的数据处理方式,它提供了一种从其他列表派生新列表的优雅方法。列表推导式的基本语法是使用方括号包含一个表达式,后面跟一个`for`语句,然后是零个或多个`for`或`if`语句。
其基本结构为:
```python
[expression for item in iterable if condition]
```
列表推导式不仅代码更加简洁,而且通常比等效的传统`for`循环更快,因为它内部使用了底层的C语言优化。
### 2.2.2 列表推导式与常规循环的性能对比
为了比较列表推导式和常规循环的性能,我们来看看一个简单的示例:
```python
import timeit
# 使用列表推导式
list_comp_time = timeit.timeit(
setup="lst = range(1000000)",
stmt="[x * x for x in lst]",
number=100
)
# 使用传统循环
traditional_loop_time = timeit.timeit(
setup="lst = range(1000000); result = []",
stmt="for x in lst: result.append(x * x)",
number=100
)
print(f"列表推导式执行时间: {list_comp_time:.2f}秒")
print(f"传统循环执行时间: {traditional_loop_time:.2f}秒")
```
在上述代码中,我们使用`timeit`模块来测量两种方法的执行时间。通常情况下,列表推导式的执行时间会更短。
## 2.3 函数化编程
### 2.3.1 函数化编程的优势
函数化编程是一种编程范式,其中函数被用作程序中的基本构造块。Python支持高阶函数,即可以接受其他函数作为参数,或者返回函数的函数。这种编程方式的优势在于:
- **无副作用**:函数只依赖于输入的参数,并且不会改变外部变量,这使得函数的行为更容易预测和理解。
- **易于并行化**:没有共享状态的函数更容易并行执行。
- **代码复用性高**:由于函数是独立和通用的,可以轻松地在不同部分的代码中复用。
- **提高代码的可测试性**:由于函数的独立性,可以更容易地为函数编写单元测试。
### 2.3.2 实现函数化编程的策略与技巧
要实现函数化编程,可以遵循以下策略:
- **编写纯函数**:纯函数是指没有副作用,且相同的输入总是返回相同输出的函数。
- **使用函数作为一等公民**:这意味着可以将函数赋值给变量,作为参数传递给其他函数,或者作为返回值。
- **利用高阶函数**:如`map()`, `filter()`, `reduce()`等,这些都是函数化编程的核心工具。
- **避免使用全局变量**:全局变量可能会导致函数间的依赖,增加副作用的可能性。
### 2.3.2 实现函数化编程的策略与技巧代码示例
```python
# 使用map和filter函数化方式处理数据
numbers = range(-5, 5)
squared_numbers = list(map(lambda x: x**2, filter(lambda x: x > 0, numbers)))
# 使用reduce实现一个求和函数
from functools import reduce
numbers = [1, 2, 3, 4, 5]
sum_of_numbers = reduce(lambda x, y: x + y, numbers)
```
在这个示例中,`map`和`filter`是函数化编程的核心工具,它们接收一个函数和一个可迭代对象,返回一个迭代器。`reduce`函数接收一个带有两个参数的函数,并应用它到可迭代对象的元素上,从而将多个值“归约”到一个单一值。
通过以上章节的介绍,我们逐步深入了Python代码结构优化的多个方面。在下一章,我们将继续探讨数据处理提速的方法,包括字符串处理、NumPy和Pandas等强大的数据处理库的使用技巧。
# 3. 数据处理提速
数据处理是任何软件应用的核心部分,无论是在数据分析、机器学习还是网络应用中,高效处理数据都是提升应用性能的关键。Python作为一种高级编程语言,提供了多种方式来处理数据,其中字符串处理、数值计算以及数据处理库Pandas的使用都对性能有重要影响。本章将探讨如何通过这些方法提升数据处理的速度。
## 3.1 字符串处理的高效方法
字符串是程序中常见的数据类型之一,处理字符串的能力对于提升应用程序的性能至关重要。Python提供了多种字符串处理的方法,其中格式化字符串和正则表达式的使用,可以帮助开发者更加高效地进行数据清洗和转换。
### 3.1.1 格式化字符串的多种方式
在Python中,格式化字符串(f-string)是一种非常方便且高效的方法来构建带有变量插值的字符串。它自Python 3.6起被引入,并且在性能上优于传统的`str.format()`方法和百分号(%)格式化。
```python
name = "Alice"
age = 30
# 使用f-string格式化
formatted_str = f"Hello, {name}. You are {age} years old."
# 使用str.format()方法
formatted_str_format = "Hello, {}. You are {} years old.".format(name, age)
# 使用百分号(%)格式化
formatted_str_percent = "Hello, %s. You are %s years old." % (name, age)
```
性能测试表明,f-string在大多数情况下比其他两种方式都要快,尤其是在涉及到复杂格式化逻辑时。这主要是因为f-string在运行时能够被更快地解析和执行。
### 3.1.2 正则表达式在数据清洗中的应用
数据清洗是数据处理的重要步骤,而正则表达式(Regular Expressions)是进行复杂文本匹配的强大工具。Python通过`re`模块提供了对正则表达式的支持。
正则表达式在处理文本数据时能够匹配特定模式的字符串,这对于数据清洗尤为重要。例如,去除不规则的空白字符、提取特定格式的日志信息、验证电话号码或电子邮件地址等。
```python
import re
# 示例:清理字符串中的所有非字母数字字符
text = "Hello, World! 123."
cleaned_text = re.sub(r'[^a-zA-Z0-9]', '', text)
print(cleaned_text) # 输出: HelloWorld123
```
正则表达式可以用来执行快速且复杂的数据预处理步骤,从而为后续的数据分析提供准确和干净的数据集。
## 3.2 利用NumPy加速数值计算
在数据科学领域,NumPy是一个广泛使用的库,它提供了高性能的多维数组对象和相关工具。NumPy的数组比Python内置的列表类型拥有更优的性能,特别是对于数值计算密集型任务。
### 3.2.1 NumPy数组与原生Python列表的对比
Python列表是一种动态数组,可以存储不同类型的对象,而NumPy数组是同质的数据结构,它在内存中连续存储数据,并且只存储一种数据类型。这种设计使得NumPy在执行数学运算时,能够利用现代CPU的SIMD(单指令多数据流)指令集,从而大幅提高性能。
```python
import numpy as np
# 创建一个Python列表
py_list = [i for i in range(10000)]
# 创建一个NumPy数组
np_array = np.arange(10000)
# 乘以2
%timeit [i * 2 for i in py_list] # 使用列表推导式
%timeit np_array * 2 # 使用NumPy数组操作
# 输出结果将展示NumPy操作的速度远超Python原生列表操作
```
上述代码展示了NumPy数组在执行批量数学运算时,与Python列表相比,速度上的明显优势。
### 3.2.2 NumPy的向量化操作及其效率优势
向量化是NumPy提供的一种无需显式循环即可对数组执行操作的能力。向量化可以应用于数组上所有的算术运算和逻辑运算。
向量化操作的效率优势主要体现在它减少了Python层面的循环调用,转而使用高度优化的C语言循环。这不仅减少了循环的开销,而且避免了Python解释器的多次函数调用开销。
```python
# 使用向量化操作进行数组的逐元素乘法
vectorized_result = np_array * np_array
# 对比传统循环实现
result_loop = np.zeros_like(np_array)
for i in range(len(np_array)):
result_loop[i] = np_array[i] * np_array[i]
# 结果展示两种方法获得相同的结果,但向量化操作更快
```
向量化操作不仅提高了执行速度,还使得代码更加简洁易读。
## 3.3 使用Pandas优化数据处理
Pandas是Python中用于数据处理和分析的库,它提供了DataFrame和Series这两种主要的数据结构,这些结构被设计用来处理表格型或异质数据。
### 3.3.1 Pandas与传统数据处理方法的比较
与传统的数据处理方法相比,Pandas提供了更高级的数据操作功能,如自动对齐、缺失数据处理、分组和聚合操作等。这些功能不仅使得数据处理更为方便,而且由于其内部优化,执行速度也快于许多其他方法。
```python
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': range(10000),
'B': range(10000, 20000)
})
# 使用Pandas进行数据操作
%timeit df['A'] + df['B'] # 使用Pandas进行向量加法
```
上述代码展示了Pandas在执行向量操作时的简洁性和高效性。
### 3.3.2 利用Pandas的内置函数提升效率
Pandas提供了许多内置函数和方法来处理数据,比如`groupby`、`merge`、`apply`等。这些函数在内部进行了优化,通常比手动实现相同逻辑的代码更加高效。
```python
# 使用groupby进行分组聚合
grouped = df.groupby('A')['B'].sum()
# 使用merge进行数据合并
merged_df = pd.merge(df, df, on='A', suffixes=('_left', '_right'))
# 使用apply应用自定义函数
def add_one(x):
return x + 1
result_apply = df['A'].apply(add_one)
# 以上方法展示了Pandas如何简化复杂的数据操作并保持高效执行
```
这些内置函数不仅提升了代码的可读性和可维护性,还保证了数据处理的速度。
本章通过分析字符串处理、数值计算及使用Pandas库的数据处理方法,展示了如何优化数据处理流程,以达到提升应用程序性能的目的。接下来的章节将探讨内存与资源管理的优化,这是另一个对应用程序性能产生重大影响的领域。
# 4. 内存与资源管理
## 4.1 优化内存使用的策略
### 内存管理基础
内存是程序运行时存储数据的有限资源,Python通过自动内存管理来简化开发者的任务。然而,不合理的内存使用会减慢程序运行速度,甚至引发内存泄漏。理解Python内存管理的工作机制,有助于提升程序性能。
Python的内存管理主要通过引用计数器(Reference Counting)来追踪内存中的对象何时可以安全地被回收。一旦对象的引用计数降到零,Python的垃圾回收器就会将其占用的内存释放。然而,循环引用(circular references)会导致垃圾回收器无法释放内存,因此需要特别注意。
为了优化内存使用,开发者应该采取以下策略:
- 尽可能使用不可变数据结构,减少不必要的内存分配。
- 使用`__slots__`优化类的内存占用。
- 采用生成器(Generators)进行数据流处理,而不是将大量数据一次性加载到内存中。
- 利用`del`语句删除不再需要的大对象引用,以立即释放内存。
### 对象池和缓存机制
对象池和缓存机制是减少内存分配次数、提高访问速度的有效手段。对象池适用于创建成本较高,且生命周期固定的小对象;而缓存则针对重复使用的数据。
对象池能够重用已经创建的对象,避免频繁的内存分配和回收操作,从而提高性能。一个简单的例子是数据库连接池,它可以减少数据库连接建立和关闭的开销。
缓存机制则通过存储计算结果或从数据库、网络等资源检索的数据来避免重复计算。Python的`functools.lru_cache`装饰器提供了一个非常方便的缓存实现。
```python
from functools import lru_cache
@lru_cache(maxsize=128)
def compute昂贵的函数(arg):
# 这里是昂贵的计算过程
return result
```
在上述代码中,`compute昂贵的函数`定义了一个带有缓存的函数。`maxsize`参数限制了缓存项的数量,当达到最大值时,最早添加的项会被删除。
## 4.2 利用缓存减少计算负载
### 缓存的概念及其重要性
缓存是一种存储数据的临时解决方案,目的是为了减少数据访问时间。在内存资源相对有限的情况下,通过将频繁访问的数据存储在内存中,可以减少对磁盘或网络资源的依赖,加快数据访问速度。
缓存的重要性在于它能够显著提升系统的整体性能。通过减少I/O操作,缓存可以降低延迟并提高吞吐量。在Web开发中,缓存可以用来存储数据库查询的结果,避免对数据库进行重复且昂贵的查询操作。
### 实现缓存的几种方法
实现缓存有多种方式,包括内存缓存、磁盘缓存、分布式缓存等。在Python中,可以使用如`cachetools`或`Beaker`等库来实现缓存。
一个简单的内存缓存示例使用了`lru_cache`:
```python
import functools
def expensive_computation(key):
# 这里是昂贵的计算过程
return result
# 创建一个有100个条目的缓存
@functools.lru_cache(maxsize=100)
def cached_computation(key):
return expensive_computation(key)
```
对于更复杂的缓存需求,`cachetools`提供了更多的缓存策略,比如`TTLCache`可以设置条目的最大存活时间(TTL):
```python
from cachetools import TTLCache
cache = TTLCache(maxsize=100, ttl=300) # 最多100个条目,每个条目最长存活300秒
def compute_with_cache(key):
if key not in cache:
cache[key] = expensive_computation(key)
return cache[key]
```
## 4.3 理解垃圾回收机制
### 垃圾回收的工作原理
Python使用引用计数来跟踪内存中的对象,而垃圾回收机制则用于处理那些引用计数变为零的对象。Python的垃圾回收器会定期检查所有对象的引用计数,并回收那些不再被引用的对象。
Python的垃圾回收器还引入了循环垃圾回收(Generational Garbage Collection),它将对象分为三代,根据对象的存活时间来调整垃圾回收的频率。新的对象属于第一代,如果在一轮垃圾回收中存活下来,就会被提升到第二代。这种机制有助于提高垃圾回收的效率。
### 如何通过代码减少垃圾回收的开销
要减少垃圾回收带来的开销,首先需要减少不必要的对象创建和增加对象的重用。此外,可以手动触发垃圾回收:
```python
import gc
# 手动触发垃圾回收
gc.collect()
```
手动触发垃圾回收通常不是必须的,因为Python的垃圾回收器会自动运行。但在某些情况下,例如在内存使用达到极限前,提前触发垃圾回收可以避免程序在关键时期产生延迟。
另一个可采取的措施是,对于需要存储大量数据的对象,采用弱引用(weakref)以避免增加它们的引用计数:
```python
import weakref
class SomeExpensiveObject:
...
# 使用弱引用
weakref_object = weakref.ref(SomeExpensiveObject)
```
通过以上方法,开发者可以有效地管理内存和资源,减少垃圾回收的开销,从而提升应用程序的整体性能。
# 5. 并发编程提升性能
## 5.1 多线程编程的正确打开方式
### 5.1.1 理解Python中的线程与进程
在Python中,线程和进程是实现并发的两种主要方式。进程是系统资源分配的基本单位,拥有自己独立的内存空间。线程则是进程中的执行单元,共享进程的资源,因此线程间的上下文切换成本要低于进程间的切换。
Python中的多线程受限于全局解释器锁(GIL),导致同一时刻只能有一个线程执行Python字节码。这一特点使得多线程在CPU密集型任务中优势不明显,但在I/O密集型任务中,如网络请求和文件读写,能够显著提高程序的效率。
### 5.1.2 实用的多线程编程实践
要实现多线程编程,我们可以使用Python的`threading`模块。以下是创建线程并启动的一个简单示例:
```python
import threading
def print_numbers():
for i in range(1, 6):
print(i)
def print_letters():
for letter in ['a', 'b', 'c', 'd', 'e']:
print(letter)
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_letters)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
```
在这个例子中,我们定义了两个函数`print_numbers`和`print_letters`,分别在两个线程中执行。使用`threading.Thread`创建线程对象,并通过`start()`方法启动线程。最后,我们调用`join()`方法来等待线程执行完毕。
为了更加深入理解Python多线程,我们可以使用`threading`模块中的`Lock`来解决多线程中的资源竞争问题。
```python
lock = threading.Lock()
def thread_task():
global counter
lock.acquire() # 请求获取锁
try:
counter += 1
finally:
lock.release() # 释放锁
counter = 0
threads = []
for i in range(10):
thread = threading.Thread(target=thread_task)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print("Counter should be 10:", counter)
```
在这个例子中,多个线程共同操作全局变量`counter`。为了防止数据竞争,我们引入了`Lock`。线程在修改`counter`之前必须先获得锁,在修改完毕后释放锁,确保同一时刻只有一个线程能够修改`counter`。
## 5.2 多进程与异步IO
### 5.2.1 进程间的通信与同步
由于GIL的存在,Python中的多线程并不适合执行CPU密集型任务,此时我们可以使用多进程来提升程序性能。Python的`multiprocessing`模块允许我们创建多个进程,它们之间可以进行通信。
进程间的通信可以通过管道(Pipe)、队列(Queue)和共享内存(Value和Array)等方式实现。同步机制如锁(Lock)和信号量(Semaphore)用于控制对共享资源的访问,防止数据竞争和不一致。
下面是一个使用`multiprocessing.Queue`来在多个进程间传递数据的例子:
```python
from multiprocessing import Process, Queue
def print_numbers(q):
for i in range(1, 6):
q.put(i) # 将数字放入队列
def print_letters(q):
while True:
item = q.get() # 从队列中取出一个项目
if item is None:
break
print(item)
q.task_done()
if __name__ == '__main__':
q = Queue()
process_numbers = Process(target=print_numbers, args=(q,))
process_letters = Process(target=print_letters, args=(q,))
process_numbers.start()
process_numbers.join()
for i in range(5):
q.put(i)
q.put(None) # 使用None来通知队列结束
process_letters.start()
process_letters.join()
print("Main process exiting")
```
在这个示例中,`print_numbers`进程向队列中添加数字,而`print_letters`进程则从队列中取出数字并打印它们。我们使用`None`作为结束信号来确保`print_letters`能够正确地结束工作。
### 5.2.2 异步IO的优势及其使用场景
异步IO(也称为非阻塞IO)允许在等待IO操作完成的同时执行其他任务。Python 3.4中引入的`asyncio`模块支持异步编程模型。相比传统的多线程和多进程模型,异步IO在处理I/O密集型任务时更加高效,因为它减少了线程或进程的上下文切换开销。
异步IO适用于需要大量等待时间的场景,例如网络请求、数据库操作和文件I/O操作。使用`asyncio`可以编写出既可读又高效的代码。
下面是一个使用`asyncio`进行异步任务处理的简单示例:
```python
import asyncio
async def fetch_data():
print('Start fetching')
await asyncio.sleep(2) # 模拟IO等待时间
print('Finished fetching')
return {'data': 1}
async def main():
data = await fetch_data()
print(data)
asyncio.run(main())
```
在这个例子中,`fetch_data`函数模拟了一个异步的网络请求。使用`async`关键字声明异步函数,`await`用于等待异步操作完成。`asyncio.run(main())`启动了事件循环,并运行主函数。
## 5.3 利用协程提升效率
### 5.3.1 协程的工作原理
协程是一种比线程更加轻量级的并发编程模型。在Python中,协程通过生成器(`generator`)和`yield`关键字实现,它允许函数在执行过程中暂停和恢复。`asyncio`中的协程使用`async`和`await`关键字,它是基于协程的高层次抽象。
协程的工作原理与线程不同,它不会创建系统线程,也不受GIL限制。协程的调度是由Python解释器内部完成的,因此它有着非常低的上下文切换成本和资源消耗。
### 5.3.2 在Python中实现和使用协程
通过`asyncio`模块,我们可以创建协程并通过`async`关键字来定义。使用`await`可以暂停当前协程的执行,并等待异步操作完成。这里是一个使用协程的例子:
```python
import asyncio
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello')
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
```
在这个示例中,`say_after`是一个异步函数,它使用`await`等待`asyncio.sleep`,该函数模拟一个异步延时操作。`main`函数启动了事件循环,并顺序执行了两个协程。这里虽然看起来是顺序执行,但在等待期间,事件循环可以处理其他任务,提高了程序的效率。
协程特别适合于I/O密集型和高并发场景。通过`asyncio`模块,我们能够编写出既高效又简洁的并发程序,这对于需要处理大量网络请求或I/O操作的应用尤为重要。
# 6. 实践案例与总结
在前面的章节中,我们深入了解了多种优化Python脚本的技术和策略。在本章,我们将通过分析一个真实世界的代码案例来展示如何识别性能瓶颈,并应用我们所学的优化技巧。
## 6.1 分析与优化真实代码案例
### 6.1.1 识别性能瓶颈
识别性能瓶颈是优化过程的第一步。假设我们有一个处理大规模数据集的Python脚本,该脚本在运行时显示出明显的延迟。为了找出瓶颈,我们通常首先使用Python的内置性能分析工具如`cProfile`。通过性能分析,我们可能发现特定的函数或代码段消耗了大部分的执行时间。
#### 使用 cProfile 分析代码性能
为了分析代码,可以使用以下命令:
```shell
python -m cProfile -o profile_output.prof my_script.py
```
之后,可以使用`pstats`模块读取分析结果,并找出耗时最多的函数:
```python
import pstats
p = pstats.Stats('profile_output.prof')
p.sort_stats('cumulative').print_stats(10)
```
这将打印出消耗时间最多的前10个函数。
### 6.1.2 应用优化技巧的实战演练
一旦我们识别出了性能瓶颈所在,下一步就是应用相应的优化技巧来改进代码。假设分析结果表明,一个处理文本文件的函数非常耗时。为了优化这个函数,我们可以考虑以下步骤:
1. **应用缓存**:如果该函数有重复的计算过程,使用缓存可以显著提高效率。
2. **使用多线程或异步IO**:如果瓶颈在于I/O操作,可以使用`asyncio`库或`threading`库来异步处理I/O。
3. **利用NumPy和Pandas**:如果处理的是数值数据,转换为NumPy数组或使用Pandas的DataFrame可能会更快。
4. **优化数据结构**:确保使用合适的数据结构,例如在某些情况下将列表转换为集合(set)以减少查找时间。
## 6.2 总结与展望
### 6.2.1 性能优化的黄金法则
性能优化不是一成不变的规则,但是遵循一些黄金法则可以让我们更接近目标。首先,永远不要假设你已经知道瓶颈在哪里,始终使用数据驱动的方法来验证你的假设。其次,优化应该是逐步的,频繁地度量改进以确保方向正确。最后,代码的可读性和可维护性不应该因为性能优化而被牺牲。
### 6.2.2 面向未来的Python编程展望
Python社区不断发展,新工具和库的出现,如PyPy、Numba、Cython等,提供了额外的性能优化途径。未来,我们可以预见Python将在保持易用性的同时,不断优化运行时性能。对于开发者来说,掌握性能分析和优化工具,以及持续学习最新的技术动态,是提高代码质量和工作效率的关键。
通过本章的分析与优化案例,我们希望能激发你对自己代码性能瓶颈的思考,并鼓励你将优化技巧应用到日常编程实践中。在结束本章之前,我们已经一起走过了从理论到实践的旅程,现在是时候将你的知识应用到实际问题中去了。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Python 解释器的工作原理,揭示 Python 代码执行背后的秘密。它提供了优化 Python 脚本性能的实用技巧,并指导读者在不同 Python 版本之间无缝切换。专栏还涵盖了内存管理的最佳实践,以避免内存泄漏,以及性能监控工具,以帮助识别和解决性能问题。此外,它提供了有关 Python 安全防护、扩展、调试和跨平台部署的全面指南。对于多线程、多进程和网络编程,本专栏提供了深入的见解,帮助读者构建高性能和可扩展的 Python 应用程序。最后,它深入研究了 Python 的内置数据结构、上下文管理器和垃圾回收机制,为读者提供了对 Python 语言内部机制的深刻理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
IPMI标准V2.0与物联网:实现智能设备自我诊断的五把钥匙
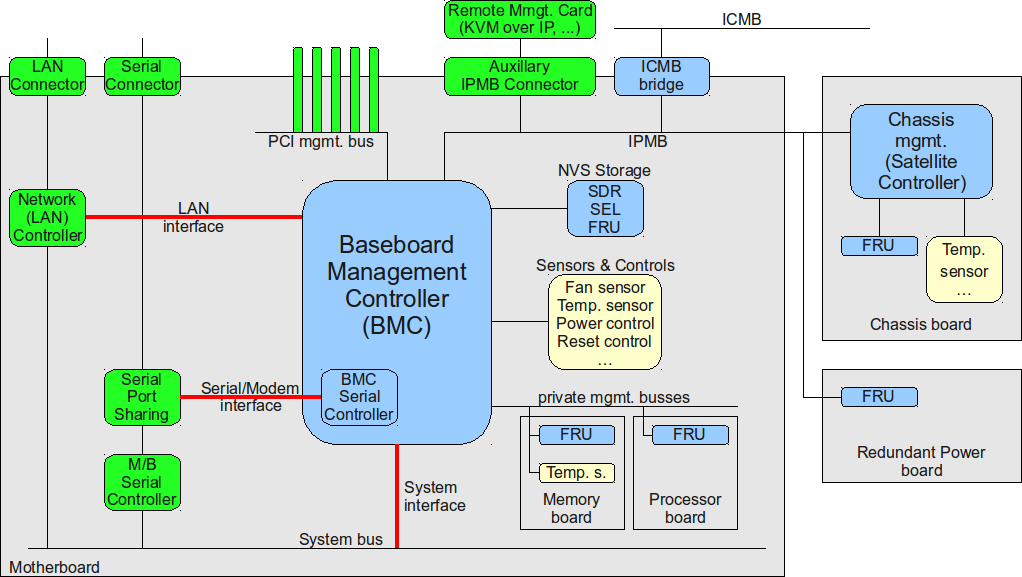
# 摘要
本文旨在深入探讨IPMI标准V2.0在现代智能设备中的应用及其在物联网环境下的发展。首先概述了IPMI标准V2.0的基本架构和核心理论,重点分析了其安全机制和功能扩展。随后,本文讨论了物联网设备自我诊断的必要性,并展示了IPMI标准V2.0在智能硬件设备和数据中心健康管理中的应用实例。最后,本文提出了实现智能设备IPMI监控系统的设计与开发指南,
【EDID兼容性高级攻略】:跨平台显示一致性的秘诀

# 摘要
电子显示识别数据(EDID)是数字视频接口中用于描述显示设备特性的标准数据格式。本文全面介绍了EDID的基本知识、数据结构以及兼容性问题的诊断与解决方法,重点关注了数据的深度解析、获取和解析技术。同时,本文探讨了跨平台环境下EDID兼容性管理和未来技术的发展趋势,包括增强型EDID标准的发展和自动化配置工具的前景。通过案例研究与专家建议,文章提供了在多显示器设置和企业级显示管理中遇到的ED
PyTorch张量分解技巧:深度学习模型优化的黄金法则

# 摘要
PyTorch张量分解技巧在深度学习领域具有重要意义,本论文首先概述了张量分解的概念及其在深度学习中的作用,包括模型压缩、加速、数据结构理解及特征提取。接着,本文详细介绍了张量分解的基础理论,包括其数学原理和优化目标,随后探讨了在PyTorch中的操作实践,包括张量的创建、基本运算、分解实现以及性能评估。论文进一步深入分析了张量分解在深度学习模型中的应用实例,展示如何通过张量分解技术实现模型
【参数校准艺术】:LS-DYNA材料模型方法与案例深度分析
# 摘要
本文全面探讨了LS-DYNA软件在材料模型参数校准方面的基础知识、理论、实践方法及高级技术。首先介绍了材料模型与参数校准的基础知识,然后深入分析了参数校准的理论框架,包括理论与实验数据的关联以及数值方法的应用。文章接着通过实验准备、模拟过程和案例应用详细阐述了参数校准的实践方法。此外,还探
系统升级后的验证:案例分析揭秘MAC地址修改后的变化

# 摘要
本文系统地探讨了MAC地址的基础知识、修改原理、以及其对网络通信和系统安全性的影响。文中详细阐述了软件和硬件修改MAC地址的方法和原理,并讨论了系统升级对MAC地址可能产生的变化,包括自动重置和保持不变的情况。通过案例分析,本文进一步展示了修改MAC地址后进行系统升级的正反两面例子。最后,文章总结了当前研究,并对今后关于MAC地址的研究方向进行了展望。
# 关键字
华为交换机安全加固:5步设置Telnet访问权限
# 摘要
随着网络技术的发展,华为交换机在企业网络中的应用日益广泛,同时面临的安全威胁也愈加复杂。本文首先介绍了华为交换机的基础知识及其面临的安全威胁,然后深入探讨了Telnet协议在交换机中的应用以及交换机安全设置的基础知识,包括用户认证机制和网络接口安全。接下来,文章详细说明了如何通过访问控制列表(ACL)和用户访问控制配置来实现Telnet访问权限控制,以增强交换机的安全性。最后,通过具体案例分析,本文评估了安
【软硬件集成测试策略】:4步骤,提前发现并解决问题
# 摘要
软硬件集成测试是确保产品质量和稳定性的重要环节,它面临诸多挑战,如不同类型和方法的选择、测试环境的搭建,以及在实践操作中对测试计划、用例设计、缺陷管理的精确执行。随着技术的进步,集成测试正朝着性能、兼容性和安全性测试的方向发展,并且不断优化测试流程和数据管理。未来趋势显示,自动化、人工智能和容器化等新兴技术的应用,将进一步提升测试效率和质量。本文系统地分析了集成测试的必要性、理论基础、实践操作
CM530变频器性能提升攻略:系统优化的5个关键技巧

# 摘要
本文综合介绍了CM530变频器在硬件与软件层面的优化技巧,并对其性能进行了评估。首先概述了CM530的基本功能与性能指标,然后深入探讨了硬件升级方案,包括关键硬件组件选择及成本效益分析,并提出了电路优化和散热管理的策略。在软件配置方面,文章讨论了软件更新流程、固件升级准备、参数调整及性能优化方法。系统维护与故障诊断部分提供了定期维护的策略和故障排除技巧。最后,通过实战案例分析,展示了CM530在特定应用中的优化效果,并对未来技术发展和创新
CMOS VLSI设计全攻略:从晶体管到集成电路的20年技术精华
# 摘要
本文对CMOS VLSI设计进行了全面概述,从晶体管级设计基础开始,详细探讨了晶体管的工作原理、电路模型以及逻辑门设计。随后,深入分析了集成电路的布局原则、互连设计及其对信号完整性的影响。文章进一步介绍了高级CMOS电路技术,包括亚阈值电路设计、动态电路时序控制以及低功耗设计技术。最后,通过VLSI设计实践和案例分析,阐述了设计流程、
三菱PLC浮点数运算秘籍:精通技巧全解

# 摘要
本文系统地介绍了三菱PLC中浮点数运算的基础知识、理论知识、实践技巧、高级应用以及未来展望。首先,文章阐述了浮点数运算的基础和理论知识,包括表示方法、运算原理及特殊情况的处理。接着,深入探讨了三菱PLC浮点数指令集、程序设计实例以及调试与优化方法。在高级应用部分,文章分析了浮点数与变址寄存器的结合、高级算法应用和工程案例。最后,展望了三菱PLC浮点数运算技术的发展趋势,以及与物联网的结合和优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )