Python解释器深度剖析:揭开Python运行机制的秘密
发布时间: 2024-09-20 08:28:28 阅读量: 421 订阅数: 71 

VSCode配置Python环境全流程解析:从解释器到代码调试的最佳实践
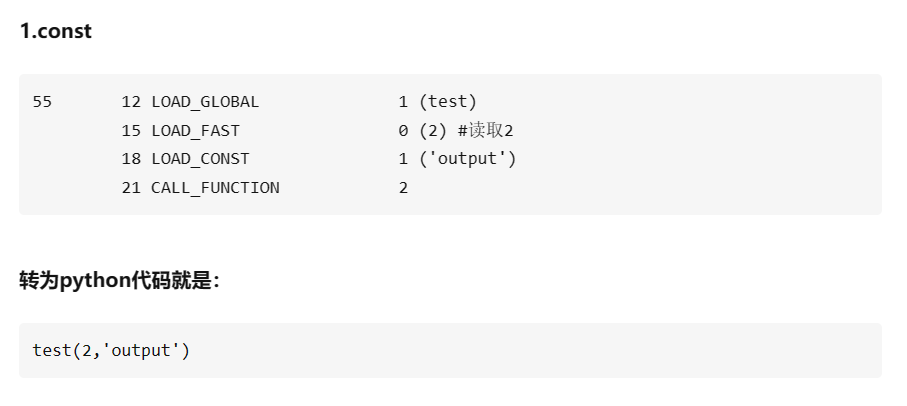
# 1. Python解释器简介
Python是目前世界上最受欢迎的编程语言之一,它之所以被广泛应用,得益于其简洁易懂的语法、强大的标准库以及高效的解释器。Python解释器是Python编程语言的核心组件,负责执行用户编写的Python代码。在这一章中,我们将简要介绍Python解释器的概念、起源、版本以及它与编译语言的区别。
## 1.1 Python解释器的定义
Python解释器可以被看作是一个执行Python代码的软件程序。它按照Python语言的规范,逐行解释执行源代码。解释器是Python语言运行的桥梁,它负责读取源代码,然后进行编译,生成字节码,再执行这些字节码。这一过程无需将代码编译为机器语言,因此Python被称为解释型语言。
## 1.2 Python解释器的种类
Python解释器有多种实现,其中最著名的是CPython,它同时也是官方的标准解释器,用C语言编写。除了CPython之外,还有如PyPy、Jython和IronPython等解释器。这些解释器提供了不同的运行环境和特性,例如Jython运行在Java平台上,而PyPy以性能优化而著称。
## 1.3 Python解释器与编译语言的区别
与编译语言不同,Python代码在运行之前不需要编译成机器码。编译语言如C或C++,通常在程序运行前通过编译器转换成机器语言,而解释型语言则在运行时由解释器逐行转换执行。这使得Python在开发过程中更为灵活,但可能在性能上有所折衷。
在下一章中,我们将深入探讨Python解释器的工作原理,了解它是如何将我们的源代码转换为可执行的程序。
# 2. Python解释器的工作原理
### 2.1 Python代码的执行流程
#### 2.1.1 代码编译与字节码
Python代码在运行之前,首先要经过编译过程,将其转换成中间代码,即字节码。编译是由Python的内置编译器`compileall`或解释器在执行过程中自动完成的。Python源代码通常以`.py`文件形式存在,当Python解释器执行这些源文件时,首先会把它们编译成`.pyc`文件,这些`.pyc`文件包含了字节码。字节码是源代码的低级表示,用于在Python虚拟机上执行。
```python
import dis
import compileall
def test_function():
a = 1
b = 2
c = a + *
***pile_dir('./')
dis.dis(test_function)
```
上面的代码首先使用`compileall`模块编译当前目录下的所有`.py`文件,然后使用`dis`模块查看`test_function`函数的字节码。这个例子展示了Python代码编译和字节码的生成过程。
#### 2.1.2 字节码的解释执行
Python虚拟机(PVM)是一个基于栈的虚拟机,使用字节码指令来执行程序。字节码指令是Python执行模型的基本单位,由操作码(opcode)和参数组成。Python虚拟机逐条读取字节码,对字节码进行解释执行。解释执行的优点是跨平台,因为字节码可以在任何安装了相应Python解释器的机器上运行。解释器为不同平台提供了实现Python虚拟机的代码,而字节码则充当了平台无关性的一层。
```python
import sys
code_object = test_function.__code__
print(f"Instruction set for {test_function.__name__}:")
for instr in code_object.co_code:
print(hex(instr))
```
这段代码展示如何获取一个函数对象的字节码指令集,并打印出来。通过这些字节码,可以看到Python解释器是如何在运行时解释执行这些指令的。
### 2.2 Python内存管理机制
#### 2.2.1 垃圾回收机制
Python使用引用计数(reference counting)机制来追踪内存中的对象,并自动进行内存回收。每个对象都会有一个计数器,用于记录有多少引用指向它。当一个对象的引用计数降到0时,意味着没有任何引用指向该对象,Python的垃圾回收器会回收其占用的内存。Python还提供了一个可选的循环垃圾回收器,用于检测和回收不可达的对象循环引用,提高内存管理的效率。
```python
import sys
def memory_management_example():
a = []
b = a
c = a
return a
my_list = memory_management_example()
print(sys.getrefcount(my_list))
```
这段代码展示了引用计数机制的一个简单例子,`sys.getrefcount`函数返回了对象`my_list`的引用计数。
#### 2.2.2 内存分配策略
Python内存分配策略是其内存管理的一部分,Python使用私有堆空间来管理其内存。所有的Python对象和数据结构都存储在私有堆中,由解释器管理。堆空间由内存分配器在运行时动态地扩展和收缩。Python使用内存池机制来优化小块内存的分配,避免频繁地在操作系统中申请和释放内存,从而提高内存使用的效率。
```python
import gc
def memory_allocation_example():
a = [i for i in range(1000000)]
b = a
gc.set_debug(gc.DEBUG_LEAK)
gc.collect()
print(f"Number of uncollectable objects: {gc.garbage}")
```
上面的代码展示了如何使用垃圾回收器的调试模式来观察内存分配和释放的情况,通过计数器可以检测内存泄漏等问题。
### 2.3 Python虚拟机架构
#### 2.3.1 基本组成与工作原理
Python虚拟机是Python解释器的核心部分,它定义了一个标准的执行模型,所有的Python实现都必须遵循这个模型。虚拟机工作在字节码层面上,解释执行经过编译器编译后的代码。Python虚拟机包括堆栈帧对象(stack frame object)、指令执行循环、内置函数和类型等组成部分。
```mermaid
flowchart LR
A[开始执行字节码] --> B[加载字节码指令]
B --> C[指令解码]
C --> D[执行指令]
D --> E[清理栈帧]
E --> F[返回或跳转]
F --> B
```
以上是一个简化的Python虚拟机工作流程图。在实际虚拟机执行中,每一步都涉及到复杂的状态管理和指令处理。
#### 2.3.2 栈帧结构与函数调用
在Python虚拟机中,函数的调用通过栈帧(stack frame)对象来管理。每个栈帧代表了一个函数调用,包含局部变量、参数、返回地址等信息。当函数被调用时,一个新的栈帧对象会被创建,并被推入到栈帧栈(frame stack)中。当函数返回时,栈顶的栈帧被弹出,返回到上一层函数调用环境中。
```python
import inspect
def function_example():
a = 1
b = 2
return a + b
frame = inspect.currentframe()
print("Function locals:", frame.f_locals)
print("Function globals:", frame.f_globals)
```
上面的代码使用了`inspect`模块来获取当前函数调用的栈帧信息,并打印出局部和全局变量。这个例子可以帮助我们理解栈帧结构在函数调用中的作用。
以上内容涵盖了Python解释器工作原理的第二章节的核心概念,通过对代码编译、内存管理以及虚拟机架构的阐述,进一步深入理解Python解释器的内部机制。在接下来的章节中,我们将继续探讨Python解释器核心组件以及性能优化等关键话题。
# 3. Python解释器的核心组件
## 3.1 Python解释器的解释循环
### 3.1.1 解释循环的工作流程
Python解释器的核心是解释循环,这是一个持续的过程,它读取Python代码,执行,然后继续读取更多的代码。这个循环称为"read-eval-print loop"(REPL),它是Python解释器交互式使用的基础。
- **读取阶段**:解释器首先从源代码读取指令。对于交互式会话,这意味着从标准输入读取,而对于模块和脚本,这意味着从磁盘读取文件。
- **解析阶段**:读取的代码被转换成一个解析树(也称为抽象语法树,AST)。这一过程称为词法分析和语法分析。
- **编译阶段**:AST被编译成字节码。这一步骤并不是传统意义上的编译,它更像是将高级指令转换为一种中间表示(IR)。
- **执行阶段**:解释器的虚拟机执行字节码。字节码是为Python虚拟机设计的一种高度优化的指令集。
### 3.1.2 解释循环优化策略
为了提高效率,Python解释器的解释循环在不同阶段使用了多种优化技术。以下是一些主要的优化策略:
- **局部变量优化**:Python使用局部变量访问来加速变量的查找,减少全局命名空间的使用。
- **字节码缓存**:在Python 3.8之后,引入了字节码缓存(pycache),这可以避免重复的字节码编译过程。
- **快速路径操作**:对于常用的内置操作,如整数加法,解释器使用快速路径代码来加速执行。
**代码块示例**:
```python
# 这是代码块的示例,实际情况下可能会包含复杂的逻辑。
def main():
a = 1
b = 2
return a + b
if __name__ == "__main__":
result = main()
print(result)
```
在这个简单的代码块中,Python解释器会逐行执行并输出结果。这个过程涉及到解释循环的多个步骤,解释器在内部会使用优化的路径来加快这些操作的执行。
## 3.2 Python内置数据结构的实现
### 3.2.1 内置类型对象的内存布局
Python的内置数据结构如列表、字典、集合等,都有各自独特的内存布局。理解这些数据结构的内部工作原理对于编写高效代码至关重要。
- **列表(list)**:列表在内存中是一个数组,可以动态调整大小。它的实现使用了数组操作,这使得它在随机访问元素时非常快。
- **字典(dict)**:字典使用哈希表实现,其目的是提供一个在常数时间复杂度内能够快速查找、插入和删除的数据结构。
- **集合(set)**:集合与字典类似,但是它存储的是唯一元素的集合,而不存储与键相关联的值。
这些结构都必须考虑到内存管理问题,例如如何有效地分配和回收内存空间。
### 3.2.2 内置类型操作的优化
Python的内置类型操作经过精心优化以提高性能。例如,在执行字典操作时,Python会利用哈希表来加速查找和插入。这种优化是通过Python虚拟机的底层实现来完成的,因此对用户来说是透明的。
**代码块示例**:
```python
# 使用字典的性能优化示例
my_dict = {}
for i in range(10000):
my_dict[i] = str(i)
# 在执行上述操作时,字典会使用哈希表来确保快速访问和插入。
```
在这个例子中,当向字典中插入大量的键值对时,哈希表允许我们以接近O(1)的时间复杂度来执行插入操作。
## 3.3 Python标准库的作用与机制
### 3.3.1 标准库模块与解释器的交互
Python标准库提供了一组丰富的模块,用于各种常见的编程任务。这些模块与Python解释器紧密集成,使得它们可以高效地使用解释器的能力。
- **io模块**:该模块提供了一套丰富的接口来处理输入和输出。
- **os模块**:该模块提供了与操作系统交互的功能,例如进程管理、文件系统操作等。
- **itertools模块**:这是一个功能强大的迭代器工具箱,用于高效地进行迭代操作。
这些模块的设计考虑到了性能,并且很多情况下会使用底层的C语言实现来加速执行。
### 3.3.2 核心模块的源码剖析
深入Python核心模块的源码,我们可以看到许多高级优化技术。例如,`itertools`模块广泛使用生成器来优化内存使用和提高性能。
**代码块示例**:
```python
import itertools
# 一个简单的生成器表达式使用例子
gen = (i for i in range(10))
for i in gen:
print(i)
```
生成器是Python中处理大量数据时非常有用的工具,因为它们只在迭代时才产生值,而不是一次性创建整个序列。
以上内容构成了Python解释器核心组件的基础。通过深入理解这些组件的工作原理和优化方式,开发者可以编写出更加高效和专业的Python代码。
# 4. Python解释器的性能优化
## 4.1 Python代码优化策略
### 4.1.1 代码层面的优化技巧
代码层面的优化对于提高Python程序的性能至关重要。优化可以从几个方面入手,比如避免在循环中进行不必要的计算、利用局部变量、减少函数调用的开销等。
**避免全局查找**
在函数中使用局部变量比全局变量要快,因为Python内部的局部变量查找机制更加高效。例如:
```python
def foo():
a = 10
print(a)
foo()
```
在上面的例子中,变量`a`是局部变量,它在函数作用域内,查找速度非常快。
**循环优化**
循环是性能优化的重要关注点,尤其当循环中包含大量迭代时。尽量减少循环内部的计算量,尤其是在循环的每次迭代中,重复的计算是性能瓶颈。
```python
# 不良示例
for i in range(10000):
result = i * i
# 优化示例
squares = [i * i for i in range(10000)]
```
在优化示例中,通过列表推导式在循环外计算并存储结果,避免了在循环中的重复计算。
**列表推导式**
列表推导式(list comprehension)通常比手动创建循环更高效。它们更加简洁,并且在内部实现中进行了优化。
**内置函数与模块**
使用Python的内置函数和标准库中的模块通常比自己编写代码更高效,因为这些内置函数和模块是用更底层的语言实现的(如C语言),并且经过了高度优化。
**参数传递**
避免使用可变类型作为函数默认参数,因为它们在函数调用之间会保持修改状态,这可能会导致意外的副作用。
```python
def append_to(element, to=[]): # 警告:这是一个错误的用法
to.append(element)
return to
append_to(1) # 返回 [1]
append_to(2) # 返回 [1, 2],不是 [2]!
```
正确的方式是使用None作为默认值,然后在函数内部进行检查和初始化。
### 4.1.2 使用cProfile进行性能分析
`cProfile`是Python内置的一个性能分析工具,它可以提供函数调用次数和时间消耗的详细报告。对于复杂的程序,使用`cProfile`可以快速识别性能瓶颈所在。
使用`cProfile`非常简单,可以通过命令行直接运行:
```bash
python -m cProfile -s time script.py
```
这条命令会运行`script.py`,并按照时间排序输出每个函数的调用信息。`-s time`参数表示按照函数消耗的时间排序。
```plaintext
307 function calls (295 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.001 0.001 <stdin>:1(<module>)
1 0.000 0.000 0.001 0.001 script.py:1(append_to)
100 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
100 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {range}
```
使用这些输出信息,开发者可以针对时间消耗最多的函数进行进一步的优化。
## 4.2 Python解释器级别的优化
### 4.2.1 解释器缓存机制
为了提升性能,Python解释器内部实现了一种缓存机制。最著名的例子是对方法解析顺序(Method Resolution Order, MRO)的缓存,这在多重继承的场景下可以显著减少计算量。
```python
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
# 检查D类的MRO
print(D.__mro__)
```
当执行类继承结构中的`__mro__`属性查询时,解释器会缓存计算结果,以避免在后续查询时重复计算。
### 4.2.2 JIT编译器与优化
Python传统上使用传统的解释执行模型,但是随着技术的发展,一些实现如PyPy,引入了即时编译(JIT)技术来提高Python代码的执行速度。
JIT编译器的工作原理是在程序运行时将字节码编译为机器码,这发生在程序运行的热点区域(频繁执行的代码片段)。因为JIT可以在运行时收集执行信息并优化,所以能够显著提高程序的运行速度。
举一个简单的例子:
```python
import time
from numba import jit
@jit(nopython=True)
def compute(x):
return [i * x for i in range(1000)]
start = time.time()
compute(1)
print(f"Time taken in seconds: {time.time() - start}")
```
使用`@jit`装饰器,我们告诉Numba编译器来优化这个函数。`nopython=True`选项让Numba试图编译一个完全不涉及Python C API的函数。这样可以得到最大的性能提升。
## 4.3 扩展Python性能的方法
### 4.3.1 使用C/C++扩展模块
由于Python是一种高级语言,它在性能方面有天生的局限性。为了克服这些局限性,开发者可以使用C或C++编写扩展模块,并将其集成到Python程序中。
**使用ctypes**
Python通过`ctypes`库提供了与C语言兼容的数据类型,允许调用动态链接库(DLLs)中的函数,无需写大量的胶水代码。
```python
from ctypes import cdll
# 加载一个C库
libc = cdll.LoadLibrary('libc.so.6')
# 调用C库中的函数
libc.time.restype = ctypes.c_long
print("Current time is:", libc.time(None))
```
**编写C扩展**
当需要性能时,可以使用C语言编写扩展模块。这通常需要使用Python的C API。这种方式在扩展复杂的库时更加高效。
### 4.3.2 Cython、Numba和PyPy的应用实例
**Cython**
Cython是Python的一个超集,它允许开发者添加类型声明,这在编译时会提高性能。Cython编译器可以将Cython代码转换为C代码,然后编译成Python扩展模块。
```cython
# example.pyx
cdef int a = 1
def test():
global a
a += 1
return a
```
使用Cython编译这个文件,并将其导入到Python中:
```bash
cythonize -i example.pyx
```
然后在Python中导入并使用:
```python
import example
print(example.test())
```
这将输出`2`。
**Numba**
Numba是一个JIT编译器,它可以将Python和NumPy代码转换为快速执行的机器码。它针对数值计算尤其有效。
使用Numba的`@jit`装饰器来加速计算:
```python
from numba import jit
@jit
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x**2 + y**2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
```
这个函数可以计算π的近似值,通过Numba装饰器后执行速度会有显著提升。
**PyPy**
PyPy是Python的一个替代实现,它使用了即时编译技术来提高执行速度。使用PyPy运行Python代码,通常能够得到比CPython更快的速度,尤其是在长时间运行的程序中。
为了使用PyPy,只需下载并安装PyPy解释器:
```bash
curl -L ***
```
然后使用PyPy解释器来运行你的Python脚本:
```bash
./pypy script.py
```
使用PyPy的好处在于,它可以作为CPython的一个几乎透明的替代品,并不需要改变代码。
本章内容介绍了代码层面的优化技巧、解释器缓存机制、JIT编译器,以及如何通过编写C扩展模块,使用Cython、Numba和PyPy等工具来提高Python代码的执行速度。这些优化措施对于改善性能瓶颈和提升Python程序的整体性能非常有用。在下一章节中,我们将深入探讨Python解释器的未来发展趋势,并分析与现代编程语言相比Python的竞争优势。
# 5. Python解释器的未来发展趋势
## 5.1 新版本Python的特性解析
### 5.1.1 新特性的设计理念
Python作为一门不断进化的编程语言,每个新版本的发布都会带来一些创新和改进。新版本的特性往往源于以下几个设计理念:
1. **可读性与简洁性**:Python的设计哲学始终倡导简洁明了的语法。新的特性或者改进通常会关注代码的可读性,使代码更易编写和理解。
2. **性能提升**:随着技术的发展和硬件的进步,新版本会引入优化来提高Python的执行速度和资源使用效率。
3. **功能扩展**:为了满足现代编程的需求,Python不断扩充其标准库和内置功能,以支持更多的应用场景。
4. **改进错误处理和内存管理**:新版本会改进Python的错误处理机制,使之更强大且用户友好。同时,对内存管理的优化也是每次更新的重点。
### 5.1.2 新特性的性能影响
新版本Python引入的特性和优化对性能产生了显著的影响,具体包括但不限于:
- **改进的内置函数和数据结构**:为了提高性能,Python增加了对数据处理能力的内置函数,例如在Python 3.6中引入的有序字典(`collections.OrderedDict`)和格式化字符串字面量(f-string)。
- **异步编程的增强**:Python 3.5引入了`async`和`await`关键字,大幅提升了异步编程的可用性和性能,这对于构建高并发的网络应用尤其重要。
- **优化的解释器和JIT编译器**:随着版本的更新,Python的解释器核心也在不断优化。如Python 3.8中的海象运算符(:=)提高了代码的简洁性。而JIT编译器PyPy等项目也在持续更新,为Python带来更快速的执行体验。
代码示例:
```python
import asyncio
async def main():
# 使用异步特性,提高IO密集型任务的性能
await asyncio.sleep(1)
print("Hello, world!")
asyncio.run(main())
```
在该代码块中,我们演示了异步编程的基本用法,这种特性可以显著提升处理网络请求或IO操作密集型任务的效率。
## 5.2 Python解释器的改进与挑战
### 5.2.1 解释器社区的贡献模式
Python的强大生命力很大程度上来自于其庞大的社区和开放的贡献模式。社区成员通过各种方式参与到Python的发展中,包括但不限于:
1. **核心开发者的贡献**:一组精选的核心开发者负责审查和合并新特性及补丁,这些开发者通常是Python Software Foundation的成员。
2. **社区提案和讨论**:新特性通常会经过社区的提案和长时间的讨论,以确保其符合Python的设计理念和社区需求。
3. **外部贡献**:非核心开发者可以通过提交修复bug的补丁、改进文档、优化代码等方式为Python做出贡献。
### 5.2.2 面临的挑战与解决方案
随着技术的迅速变化,Python解释器在发展中也面临着一些挑战,其中包括:
1. **性能瓶颈**:虽然Python简单易用,但其性能相较于编译语言仍然有差距。解决方案包括引入JIT技术、扩展内置库、使用C/C++模块等。
2. **线程模型的限制**:Python的全局解释器锁(GIL)限制了线程的并行执行。解决这一问题的尝试包括使用多进程、异步编程和第三方的JIT编译器。
3. **类型系统的限制**:Python是动态类型语言,这在某些情况下会限制性能。Python 3.6引入的类型提示系统为静态类型检查和性能优化开辟了新的路径。
代码示例:
```python
from typing import List
def sum_numbers(numbers: List[int]) -> int:
"""计算一个整数列表的和"""
return sum(numbers)
# 使用类型提示,有助于IDE和静态分析工具提供更好的支持
total = sum_numbers([1, 2, 3, 4, 5])
print(total)
```
在上述代码示例中,我们通过类型提示(Type Hinting)来声明变量和函数的类型,这是Python 3.5及以上版本支持的功能,这有助于提高代码的可读性和维护性。
## 5.3 Python与现代编程语言的比较
### 5.3.1 Python的优劣势分析
Python作为一种高级编程语言,与现代其他编程语言相比,其优势和劣势如下:
优势:
- **易读性和易学性**:Python简洁明了的语法让初学者更容易上手。
- **广泛的库支持**:Python有着庞大的标准库和第三方库,几乎涵盖了所有你能想到的领域。
- **良好的社区和生态系统**:Python拥有强大的社区支持,大量的开源项目和文档资源。
劣势:
- **性能问题**:Python的解释执行和动态类型特性导致其性能较弱。
- **内存消耗**:Python对象的内存开销较大,尤其是在处理大量数据时。
- **全局解释器锁**:由于GIL的存在,难以利用多核处理器的并行计算能力。
### 5.3.2 对标其他语言的性能和生态
与其他现代编程语言相比,Python在性能上可能稍逊一筹,但它在开发效率、库生态系统和社区支持方面通常表现更好。例如,尽管Go和Rust在性能上优于Python,但它们的易学性和库支持方面不如Python成熟。
在性能方面,Python采取了多种策略进行优化,包括使用Cython、Numba等工具,或是利用JIT编译器如PyPy来提高性能。这些优化手段让Python在处理高性能任务时表现得更为出色。
表格示例:
| 特性 | Python | Go | Rust |
|--------------|----------|---------|---------|
| 易学性 | 高 | 中 | 低 |
| 性能 | 中等 | 高 | 高 |
| 并行处理能力 | 较弱 | 强 | 强 |
| 应用生态 | 非常丰富 | 相对较少| 增长中 |
通过上表可以看出,Python、Go和Rust在各自的优势领域都有显著的特点。尽管Python可能在性能上不是最优秀的,但在易学性和生态支持方面却有独特的优势。
在这个技术快速发展的时代,Python解释器的未来发展趋势将会继续受到开发者社区的推动和市场需求的引导。Python需要不断地进行自我革新,以适应新的编程范式和挑战。通过对现有特性的优化、新特性的引入以及解决性能瓶颈等问题,Python解释器将有望继续保持其在编程语言领域的领先地位。
# 6. Python解释器的实践应用案例
Python作为一种高级编程语言,因其简洁、易读和易编写的特性而广泛应用于各个领域。在本章中,我们将深入探讨Python解释器如何在大数据处理、机器学习与人工智能、以及Web开发中发挥其独特的实践应用价值。
## 6.1 Python在大数据处理中的应用
在大数据时代背景下,Python凭借其强大的生态系统和灵活性,在数据处理领域中扮演了重要角色。Python解释器为各种大数据框架提供了便利的接口,使得数据科学家可以轻松地进行数据探索、清洗、处理、分析以及可视化。
### 6.1.1 大数据框架与Python的集成
Python与大数据框架(如Hadoop、Spark等)的集成,主要是通过提供易于使用的API接口来实现的。例如,PySpark是Apache Spark的一个Python API,它允许用户利用Python编写Spark程序。
```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# 创建Spark会话
spark = SparkSession.builder.appName("PythonSparkExample").getOrCreate()
# 读取数据集
df = spark.read.csv("hdfs://path/to/dataset.csv", header=True, inferSchema=True)
# 数据处理
df.select(col("name"), col("age") + 1).show(5)
```
以上代码展示了如何使用PySpark读取存储在HDFS中的CSV文件,并进行简单的数据处理操作。
### 6.1.2 实际案例分析
在实际应用中,Python与Hadoop的集成使得企业能够在大数据环境中高效地处理和分析数据。例如,一家电商公司可以使用Python与Hadoop的组合,来分析客户购买行为和趋势预测。
通过使用如Pandas、NumPy、SciPy等库进行数据预处理和初步分析,然后利用PySpark等工具进行大规模数据集上的复杂计算,最终使用机器学习模型预测未来的销售趋势。
## 6.2 Python在机器学习与人工智能中的角色
Python在机器学习与人工智能领域中同样具有举足轻重的地位。其核心原因在于Python拥有丰富的库和框架支持,例如TensorFlow、PyTorch、scikit-learn等,这些工具极大地简化了算法的实现和模型的构建过程。
### 6.2.1 AI库与解释器的集成
这些AI库与Python解释器的紧密集成,使得数据科学家可以无缝地切换工作流程,从数据处理到模型训练再到结果展示。
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用随机森林算法训练模型
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 预测测试集
predictions = clf.predict(X_test)
# 计算准确率
print(f"Model accuracy: {accuracy_score(y_test, predictions)}")
```
上述代码展示了如何使用scikit-learn库来加载一个经典的数据集、训练一个随机森林分类器,并评估其性能。
### 6.2.2 案例研究:构建机器学习模型
在实际的机器学习项目中,Python解释器可以帮助构建和优化复杂的机器学习模型。例如,一家医疗保险公司可能会利用Python来开发一个预测患者患病风险的机器学习模型。通过构建这样的模型,公司能够更好地为患者提供个性化服务,并有效控制保险赔付成本。
## 6.3 Python在Web开发中的实践
Python在Web开发领域同样表现不俗,其众多的Web框架如Django、Flask和 Pyramid 等,使得开发动态网站和网络应用变得快速和简单。
### 6.3.1 Web框架与Python的兼容性
Python的Web框架以其高度的可扩展性和易于上手的特点而受到开发者的青睐。在与Python解释器的结合下,开发者可以使用Python编写出安全、可靠、高效的Web应用。
```python
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
# 处理表单数据
return 'Form data received'
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
```
上面的代码示例展示了如何利用Flask框架创建一个简单的Web应用。这个应用能够响应用户的HTTP请求,并展示不同的响应。
### 6.3.2 实战项目:Web应用的部署与优化
在实际部署中,Python解释器与Web框架的组合使得应用的部署和维护变得更加简便。使用工具如Gunicorn、uWSGI或mod_wsgi,可以将Python应用部署到各种Web服务器上,如Nginx和Apache。
例如,一个电子商务网站可能会使用Django框架,并利用Nginx作为其Web服务器。通过在Nginx中配置Gunicorn作为后端,这个网站就可以处理大量的并发请求,实现高可用性和良好的用户体验。
本章展示了Python解释器在不同领域中的应用,通过具体案例解析了Python如何帮助企业解决问题。Python解释器的灵活性和高效性是其在各个行业中占据一席之地的关键因素。在未来,随着技术的不断发展,Python解释器及其应用将会持续扩展其影响力,并继续引领编程语言发展的新趋势。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Python 解释器的工作原理,揭示 Python 代码执行背后的秘密。它提供了优化 Python 脚本性能的实用技巧,并指导读者在不同 Python 版本之间无缝切换。专栏还涵盖了内存管理的最佳实践,以避免内存泄漏,以及性能监控工具,以帮助识别和解决性能问题。此外,它提供了有关 Python 安全防护、扩展、调试和跨平台部署的全面指南。对于多线程、多进程和网络编程,本专栏提供了深入的见解,帮助读者构建高性能和可扩展的 Python 应用程序。最后,它深入研究了 Python 的内置数据结构、上下文管理器和垃圾回收机制,为读者提供了对 Python 语言内部机制的深刻理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
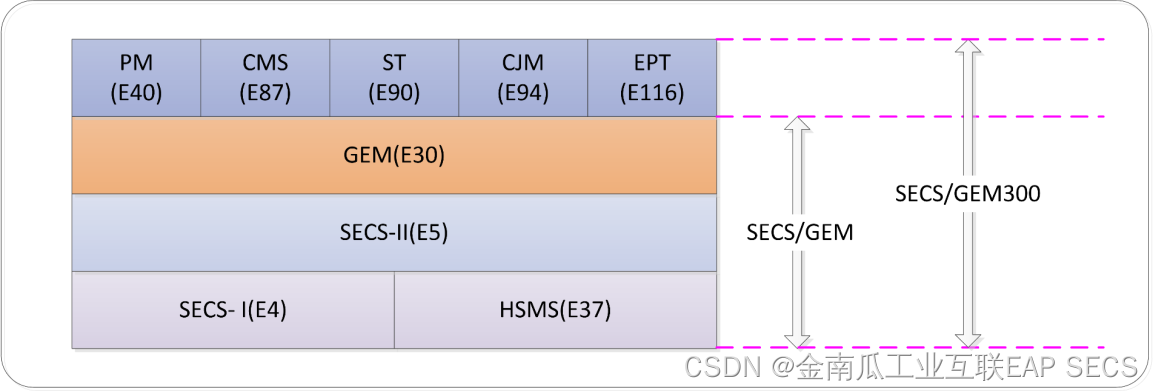
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )