【ElementTree实战案例分析】:Python处理复杂XML结构的奥秘
发布时间: 2024-10-12 09:02:23 阅读量: 23 订阅数: 23 

# 1. ElementTree库的简介与安装
## 1.1 ElementTree库简介
ElementTree是一个强大的XML处理库,广泛应用于Python编程中。它提供了简单易用的API,用于解析和创建XML数据。ElementTree不仅能够进行基本的XML操作,如节点的增删改查,还能够处理复杂的XML结构,支持命名空间管理,并可与XPath等高级查询工具结合使用。
## 1.2 安装ElementTree库
通常情况下,Python标准库中已经内置了`xml.etree.ElementTree`模块,因此无需额外安装即可直接使用。如果您的Python环境未预装ElementTree,也可以通过包管理工具pip进行安装。以下是使用pip安装ElementTree的命令:
```bash
pip install elementtree
```
通过上述命令安装的ElementTree会包括`lxml`,这是ElementTree的一个高效实现。然而在大多数情况下,您可以直接使用内置的ElementTree。
在Python脚本中,导入ElementTree模块通常以下列方式进行:
```python
import xml.etree.ElementTree as ET
```
导入后即可开始使用ElementTree进行XML数据的处理。接下来的章节将深入探讨ElementTree库的安装及其基础使用方法,包括如何创建和解析XML、节点操作、元素属性处理等。
# 2. ElementTree基础操作详解
## 2.1 ElementTree的节点操作
### 2.1.1 创建和解析XML
ElementTree库可以轻松创建新的XML文档,同时也能解析现有的XML文件。以下是一个基本的示例,展示如何创建一个新的XML文档,并使用ElementTree库将其保存到文件中。
```python
import xml.etree.ElementTree as ET
# 创建根节点
root = ET.Element("root")
# 创建子节点
child = ET.SubElement(root, "child")
child.text = "Hello, World!"
# 创建另外一个子节点
ET.SubElement(root, "child").text = "Example"
# 将树的内容写入XML文件
tree = ET.ElementTree(root)
tree.write("example.xml")
```
以上代码首先创建了一个根节点,并添加了两个带有文本内容的子节点。之后,我们创建了一个树结构(`ElementTree`对象),并将其保存到了名为"example.xml"的文件中。
### 2.1.2 节点的查找与选择
ElementTree库提供了多种方法来查找和选择XML文档中的节点。这包括使用XPath表达式进行精确查找。
```python
# 加载已存在的XML文件
tree = ET.parse("example.xml")
root = tree.getroot()
# 查找所有的子节点
for child in root.findall('child'):
print(child.tag, child.text)
# 使用XPath表达式查找特定节点
target_node = root.find('child[@text="Example"]')
print(target_node.tag, target_node.text)
```
在这段代码中,`findall`方法用于获取所有匹配给定路径的节点列表,而`find`方法则返回与提供的XPath表达式匹配的第一个节点。
### 2.1.3 节点的增删改查
ElementTree库提供了丰富的方法来修改XML文档结构,包括添加、删除、修改节点,以及查询节点信息。
```python
# 添加新节点
new_child = ET.SubElement(root, "newchild")
new_child.text = "New Node"
# 删除节点
target_node = root.find('child[@text="Example"]')
root.remove(target_node)
# 修改节点文本
for child in root.findall('child'):
child.text = "Updated text"
# 查询节点信息
for child in root.iter('child'):
print(child.tag, child.text)
```
通过这些操作,可以灵活地对XML文档进行修改,并获取需要的信息。
## 2.2 ElementTree的元素属性处理
### 2.2.1 属性的添加与修改
在处理XML文档时,元素的属性也非常重要。ElementTree提供了方法来添加和修改元素的属性。
```python
# 获取已经存在的节点
node = root.find('child')
# 添加属性
node.set('attr', 'value')
# 修改已有的属性
node.set('attr', 'new_value')
```
使用`set`方法可以添加或修改属性,这使得我们可以根据需要调整元素的属性。
### 2.2.2 属性的遍历与使用
获取元素的所有属性,可以使用`attrib`属性,该属性返回一个字典。我们可以通过遍历这个字典来使用元素的属性。
```python
# 遍历元素的所有属性
for attr, value in node.attrib.items():
print(f"Attribute: {attr}, Value: {value}")
```
通过这种方式,可以轻松地访问和利用元素的所有属性。
## 2.3 ElementTree的命名空间管理
### 2.3.1 命名空间的定义与作用
XML命名空间允许你区分具有相同名称的元素,使元素在不同的上下文中表示不同的事物。ElementTree库支持命名空间的处理。
```python
# 使用命名空间的示例
namespaces = {'ns': '***'}
node = root.find('ns:child', namespaces)
```
在这个示例中,我们定义了一个命名空间字典,并在查找时指定了命名空间。
### 2.3.2 命名空间在查询中的应用
在使用XPath表达式查询时,正确处理命名空间非常关键。
```python
# 使用命名空间的XPath查询
for child in root.findall('ns:child', namespaces):
print(child.text)
```
这段代码展示了如何在XPath查询中应用命名空间,确保查询的准确性。
以上节内容介绍了ElementTree库在基本节点操作、元素属性处理和命名空间管理方面的应用。通过对这些基础功能的深入理解和实践,可以为更高级的XML处理打下坚实的基础。接下来的章节将会探讨ElementTree的高级特性与应用,进一步扩展我们处理XML文档的能力。
# 3. ElementTree高级特性与应用
## 3.1 XPath与ElementTree的结合
### 3.1.1 XPath的基础知识
XPath(XML Path Language)是一种在XML文档中查找信息的语言,提供了一种灵活的方式来导航XML文档的结构。XPath使用路径表达式来选择XML文档中的节点或节点集。这些路径表达式看起来类似于文件系统中的文件路径。XPath表达式可以用来匹配XML文档中的元素、属性、文本内容等。
XPath的基本语法包括节点选择(如选取属性、文本内容)、谓词(用于过滤节点集)、轴(定义节点与节点之间的关系)等。例如,表达式`/bookstore/book[1]`用于选择第一个`book`元素,而`/bookstore/book/title`则选取所有的`title`元素。
### 3.1.2 XPath在ElementTree中的应用
在ElementTree中,XPath可以通过`find()`和`findall()`方法来使用。`find()`方法返回匹配的第一个元素,而`findall()`方法返回一个元素列表。这些方法通常会传入一个XPath表达式作为参数。
例如:
```python
import xml.etree.ElementTree as ET
tree = ET.parse('books.xml')
root = tree.getroot()
# 使用XPath选择第一个book元素
first_book = root.find('.//book[1]')
print(ET.tostring(first_book, encoding='utf8').decode('utf8'))
# 使用XPath选择所有的title元素
titles = root.findall('.//title')
for title in titles:
print(ET.tostring(title, encoding='utf8').decode('utf8'))
```
### 3.1.3 利用XPath进行复杂的查询
XPath的强大之处在于它能够构造复杂的查询语句,以匹配特定的节点模式。这些查询可以包括轴的使用,谓词的使用,以及对节点的属性和文本内容的条件过滤。
例如,如果我们想要找到所有`price`元素其文本内容低于`30`的`book`元素,可以构造如下XPath表达式:
```python
cheap_books = root.findall(".//book[price<30]")
for book in cheap_books:
print(ET.tostring(book, encoding='utf8').decode('utf8'))
```
利用XPath的谓词,我们还可以进一步过滤结果,比如选择特定的属性值:
```python
# 选择语言为"en"的所有book元素
english_books = root.findall(".//book[@lang='en']")
for book in english_books:
print(ET.tostring(book, encoding='utf8').decode('utf8'))
```
## 3.2 高级解析技巧
### 3.2.1 事件驱动解析
事件驱动解析是一种处理XML的方式,解析器逐个读取XML文档,遇到开始标签、结束标签、文本内容等事件时触发相应的处理函数。这种方法通常用于处理大型文件,因为它不需要将整个XML文档加载到内存中。
在Python中,可以使用`xml.etree.ElementTree`模块的`iterparse()`方法来实现事件驱动解析。下面是一个示例:
```python
import xml.etree.ElementTree as ET
# 定义事件处理函数
def handle_start_element(tag, attrs):
print('Start elem
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中用于 XML 处理的 ElementTree 库。从基础概念到高级用法,涵盖了 ElementTree 的方方面面。专栏包含多个章节,包括:
* ElementTree 的深度解析,掌握 XML 树结构和节点操作。
* 高效解析 XML 实战指南,掌握数据提取技巧。
* 探索 XPath 与 ElementTree 的结合,实现精准数据定位。
* ElementTree 的高级用法,包括 XML 数据转换秘籍。
* 构建和修改 XML 文档的终极技巧,精通 ElementTree。
* ElementTree 与其他 XML 处理库的对比分析,了解优缺点。
* 处理大型 XML 的策略,揭秘进阶技巧。
* XML 序列化和反序列化教程,掌握 ElementTree 的深度应用。
* 处理复杂 XML 结构的实战案例分析,深入理解 ElementTree 的能力。
* 属性和命名空间处理策略指南,解决常见问题。
* 错误处理和调试技巧,提升代码质量。
* 最佳实践指南,编写清晰可维护的 XML 处理代码。
* 数据分析中的 ElementTree 应用,提取和转换数据。
* ElementTree 与 JSON 交互,掌握数据格式转换。
* SubElement 元素嵌套技巧,探索 ElementTree 的高级功能。
* Web 爬虫中的 ElementTree 应用,解析网页 XML 数据。
* XSD 与 XML 校验,提升代码健壮性。
* ElementTree 与 DOM 解析比较,帮助选择最合适的 XML 解析方法。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
【MySQL大数据集成:融入大数据生态】
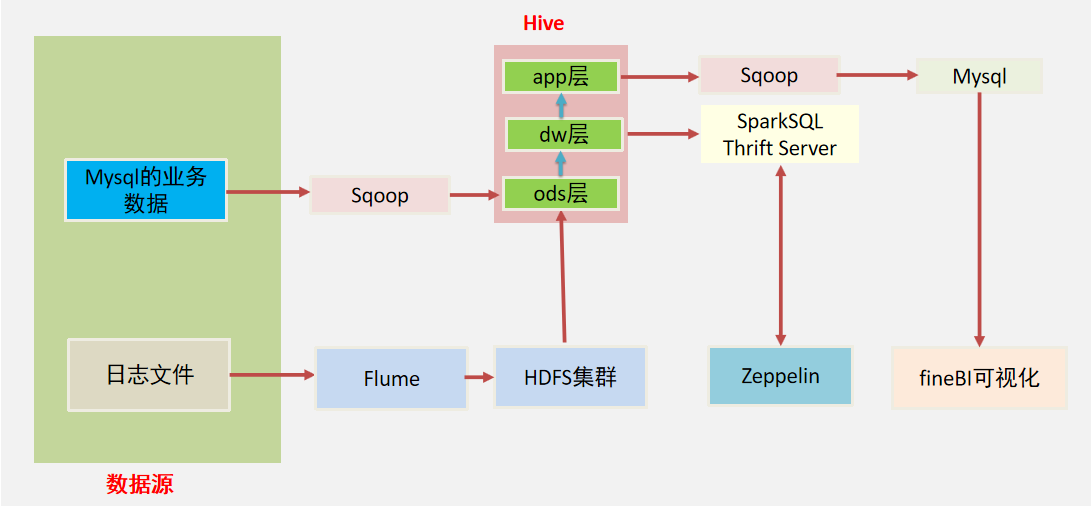
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
【数据分片技术】:实现在线音乐系统数据库的负载均衡
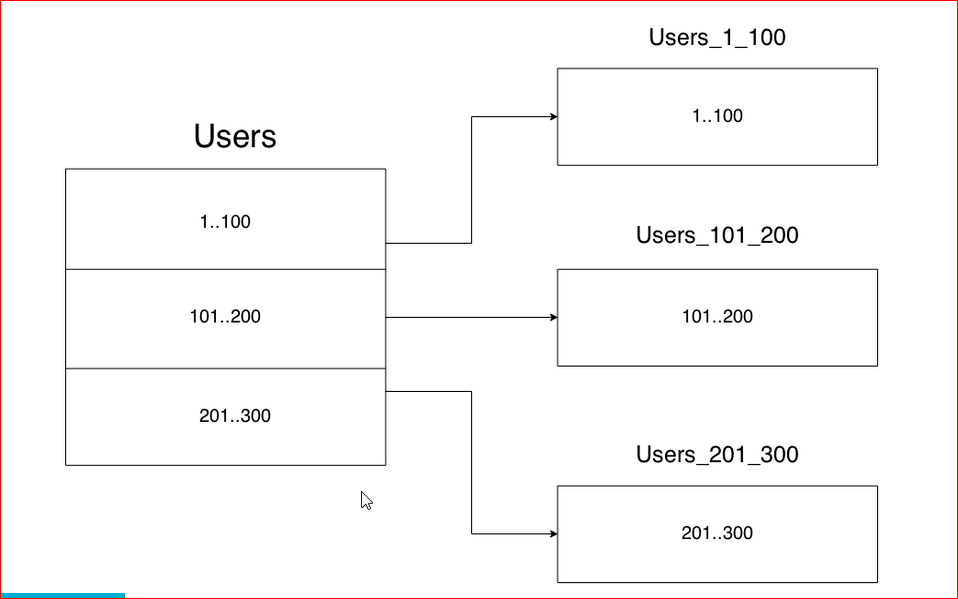
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【面向对象编程:终极指南】:破解编程的神秘面纱,掌握23种设计模式及实践案例
# 1. 面向对象编程基础
## 1.1 面向对象编程简介
面向对象编程(Object-Oriented Programming,简称OOP)是一种通过对象来组织程序的编程范式。它强调将数据和操作数据的行为封装在一起,构成对象,以实现程序的模块化和信息隐藏。面向对象的四大基本特性包括:封装、继承、多态和抽象。
## 1.2 OOP基本
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )