深度解读OpenCV车牌识别中的图像分割技术:分割车牌区域,提升识别效率
发布时间: 2024-08-12 01:00:17 阅读量: 10 订阅数: 14 

# 1. OpenCV车牌识别概述
车牌识别是计算机视觉领域的一项重要应用,其目的是从图像或视频中识别车牌号码。OpenCV(Open Source Computer Vision Library)是一个流行的开源计算机视觉库,它提供了丰富的图像处理和计算机视觉算法,可用于车牌识别。OpenCV车牌识别通常涉及以下步骤:
- 车牌区域分割:从图像中分割出车牌区域。
- 车牌字符识别:识别车牌区域中的字符。
- 车牌号码拼接:将识别的字符拼接成完整的车牌号码。
车牌区域分割是车牌识别过程中的关键步骤,其精度和速度直接影响车牌识别的整体性能。
# 2. 车牌区域分割理论基础
### 2.1 图像分割算法分类
图像分割是将图像分解为不同区域的过程,每个区域代表图像中不同对象或特征。根据分割算法的原理,可以将图像分割算法分为以下三类:
#### 2.1.1 基于阈值的分割
基于阈值的分割通过设置一个阈值来将图像中的像素分为两类:背景和前景。阈值通常是图像灰度直方图中峰值之间的最小值。
**优点:**
* 简单易实现
* 计算量小,速度快
**缺点:**
* 对于灰度分布不均匀的图像分割效果不佳
* 难以确定合适的阈值
#### 2.1.2 基于区域的分割
基于区域的分割将图像中的像素聚集成具有相似特征的区域。这些特征包括灰度值、纹理和位置。
**优点:**
* 能够分割出复杂形状的区域
* 对噪声和光照变化不敏感
**缺点:**
* 计算量大,速度慢
* 容易产生过分割或欠分割
#### 2.1.3 基于边缘的分割
基于边缘的分割通过检测图像中的边缘来分割图像。边缘是图像中灰度值突然变化的地方。
**优点:**
* 能够分割出细小物体
* 对噪声不敏感
**缺点:**
* 容易产生断裂的边缘
* 计算量大,速度慢
### 2.2 车牌区域分割的评价指标
为了评估车牌区域分割算法的性能,通常使用以下指标:
#### 2.2.1 精度和召回率
* **精度(Precision):**分割出的车牌区域中包含实际车牌区域的比例。
* **召回率(Recall):**实际车牌区域中被分割出的车牌区域的比例。
#### 2.2.2 F1-Score
F1-Score是精度和召回率的调和平均值,综合考虑了精度和召回率。计算公式为:
```
F1-Score = 2 * Precision * Recall / (Precision + Recall)
```
# 3.1 基于阈值的分割
基于阈值的分割是一种简单的图像分割方法,它将图像中的像素分为两类:目标区域和背景区域。目标区域中的像素值高于阈值,而背景区域中的像素值低于阈值。
#### 3.1.1 Otsu阈值法
Otsu阈值法是一种自动阈值选择方法,它通过最大化目标区域和背景区域之间的类间方差来确定阈值。类间方差衡量了两个区域之间像素值分布的差异。
```python
import cv2
import numpy as np
# 读取图像
image = cv2.imread('car_plate.jpg')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 计算 Otsu 阈值
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# 显示分割结果
cv2.imshow('Otsu Thresholding', thresh)
cv2.waitKey(0)
```
**代码逻辑分析:**
* `cv2.threshold()` 函数使用 Otsu 阈值法将图像分割为两类。
* `0` 表示阈值,`255` 表示最大像素值。
* `cv2.THRESH_BINARY + cv2.THRESH_OTSU` 指定使用二值化阈值和 Otsu 方法。
* `[1]` 索引返回分割后的二值图像。
#### 3.1.2 自适应阈值法
自适应阈值法是一种局部阈值选择方法,它为图像的每个像素计算一个阈值。阈值根据像素周围像素值的分布进行调整。
```python
# 使用自适应阈值法
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
# 显示分割结果
cv2.imshow('Adaptive Thresholding', thresh)
cv2.waitKey(0)
```
**代码逻辑分析:**
* `cv2.adaptiveThreshold()` 函数使用自适应阈值法将图像分割为两类。
* `255` 表示最大像素值。
* `cv2.ADAPTIVE_THRESH_MEAN_C` 指定使用均值作为阈值计算方法。
* `cv2.THRESH_BINARY` 指定使用二值化阈值。
* `11` 表示阈值计算窗口的大小。
* `2` 表示从均值中减去的常数。
# 4. 基于深度学习的车牌区域分割
### 4.1 卷积神经网络(CNN)
#### 4.1.1 CNN的结构和原理
卷积神经网络(CNN)是一种深度学习模型,因其在图像识别和处理任务中的出色表现而闻名。CNN的结构通常包括以下层:
- **卷积层:**卷积层使用卷积核对输入图像进行卷积操作,提取图像中的特征。
- **池化层:**池化层通过对卷积层的输出进行下采样,减少特征图的尺寸和计算量。
- **全连接层:**全连接层将池化层的输出展平为一维向量,并使用全连接操作进行分类或回归。
#### 4.1.2 CNN在车牌区域分割中的应用
CNN在车牌区域分割中得到了广泛的应用。通过训练CNN模型,可以自动学习车牌区域的特征,并将其与背景区域区分开来。
### 4.2 U-Net网络
#### 4.2.1 U-Net的结构和原理
U-Net网络是一种用于图像分割的深度学习模型。其结构类似于一个U形,由一个编码器和一个解码器组成。
- **编码器:**编码器由一系列卷积层和池化层组成,用于提取图像中的特征。
- **解码器:**解码器由一系列上采样层和卷积层组成,用于将编码器的特征图恢复到原始图像尺寸。
#### 4.2.2 U-Net在车牌区域分割中的应用
U-Net网络在车牌区域分割中表现出色。其独特的U形结构允许网络同时捕获图像的全局和局部特征,从而实现精确的分割。
### 代码示例:使用U-Net网络进行车牌区域分割
```python
import tensorflow as tf
from tensorflow.keras import layers
# 定义U-Net模型
inputs = tf.keras.Input(shape=(256, 256, 3))
x = layers.Conv2D(32, (3, 3), activation="relu", padding="same")(inputs)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(64, (3, 3), activation="relu", padding="same")(x)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(128, (3, 3), activation="relu", padding="same")(x)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(256, (3, 3), activation="relu", padding="same")(x)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.UpSampling2D((2, 2))(x)
x = layers.Conv2D(128, (3, 3), activation="relu", padding="same")(x)
x = layers.UpSampling2D((2, 2))(x)
x = layers.Conv2D(64, (3, 3), activation="relu", padding="same")(x)
x = layers.UpSampling2D((2, 2))(x)
x = layers.Conv2D(32, (3, 3), activation="relu", padding="same")(x)
outputs = layers.Conv2D(1, (1, 1), activation="sigmoid")(x)
model = tf.keras.Model(inputs, outputs)
# 训练模型
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
model.fit(train_data, train_labels, epochs=10)
# 评估模型
model.evaluate(test_data, test_labels)
```
**代码逻辑分析:**
该代码示例使用Keras构建了一个U-Net模型,用于车牌区域分割。模型包含一个编码器和一个解码器,编码器用于提取图像特征,解码器用于恢复特征图并生成分割掩码。
**参数说明:**
- `inputs`:输入图像,形状为`(256, 256, 3)`。
- `outputs`:分割掩码,形状为`(256, 256, 1)`。
- `optimizer`:优化器,使用Adam优化器。
- `loss`:损失函数,使用二进制交叉熵损失。
- `metrics`:评估指标,使用准确率。
- `train_data`:训练数据集。
- `train_labels`:训练标签。
- `test_data`:测试数据集。
- `test_labels`:测试标签。
# 5. 车牌区域分割在OpenCV车牌识别中的应用
### 5.1 车牌识别流程
车牌识别是一个多步骤的过程,其中车牌区域分割是关键的第一步。车牌识别流程通常包括以下步骤:
- **车牌区域分割:**从图像中分离出车牌区域。
- **车牌字符识别:**识别车牌区域内的字符。
- **车牌号码拼接:**将识别出的字符拼接成完整的车牌号码。
### 5.2 车牌区域分割对车牌识别效率的影响
车牌区域分割的准确性和速度对车牌识别效率有重大影响:
#### 5.2.1 分割精度的影响
分割精度是指分割出的车牌区域与实际车牌区域的重叠程度。如果分割精度低,可能会导致车牌字符识别错误或丢失。例如,如果分割出的车牌区域包含背景区域,则可能会导致字符识别错误;如果分割出的车牌区域不完整,则可能会导致字符丢失。
#### 5.2.2 分割速度的影响
分割速度是指分割算法处理图像所需的时间。如果分割速度慢,可能会影响车牌识别的整体效率。在实时应用中,分割速度尤其重要,因为需要快速处理图像以实现实时车牌识别。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了基于 OpenCV 的车牌识别系统,从零基础到打造高精度应用。它涵盖了图像预处理、特征提取、字符识别、图像分割、图像增强、透视变换、边缘检测、形态学操作、轮廓检测、图像二值化、图像灰度化、图像平滑、图像锐化、图像滤波和图像变换等技术。通过这些内容,读者可以全面了解 OpenCV 车牌识别系统的原理、方法和实践,并掌握提升识别精度和效率的技巧。专栏还对比了 OpenCV 车牌识别系统与其他技术,帮助读者选择最适合其应用场景的技术。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python列表与数据库:列表在数据库操作中的10大应用场景

# 1. Python列表与数据库的交互基础
在当今的数据驱动的应用程序开发中,Python语言凭借其简洁性和强大的库支持,成为处理数据的首选工具之一。数据库作为数据存储的核心,其与Python列表的交互是构建高效数据处理流程的关键。本章我们将从基础开始,深入探讨Python列表与数据库如何协同工作,以及它们交互的基本原理。
## 1.1
Python并发控制:在多线程环境中避免竞态条件的策略

# 1. Python并发控制的理论基础
在现代软件开发中,处理并发任务已成为设计高效应用程序的关键因素。Python语言因其简洁易读的语法和强大的库支持,在并发编程领域也表现出色。本章节将为读者介绍并发控制的理论基础,为深入理解和应用Python中的并发工具打下坚实的基础。
## 1.1 并发与并行的概念区分
首先,理解并发和并行之间的区别至关重要。并发(Concurre
Python列表的函数式编程之旅:map和filter让代码更优雅

# 1. 函数式编程简介与Python列表基础
## 1.1 函数式编程概述
函数式编程(Functional Programming,FP)是一种编程范式,其主要思想是使用纯函数来构建软件。纯函数是指在相同的输入下总是返回相同输出的函数,并且没有引起任何可观察的副作用。与命令式编程(如C/C++和Java)不同,函数式编程
索引与数据结构选择:如何根据需求选择最佳的Python数据结构

# 1. Python数据结构概述
Python是一种广泛使用的高级编程语言,以其简洁的语法和强大的数据处理能力著称。在进行数据处理、算法设计和软件开发之前,了解Python的核心数据结构是非常必要的。本章将对Python中的数据结构进行一个概览式的介绍,包括基本数据类型、集合类型以及一些高级数据结构。读者通过本章的学习,能够掌握Python数据结构的基本概念,并为进一步深入学习奠
【性能对比】:字典还是集合?选择的最佳时机
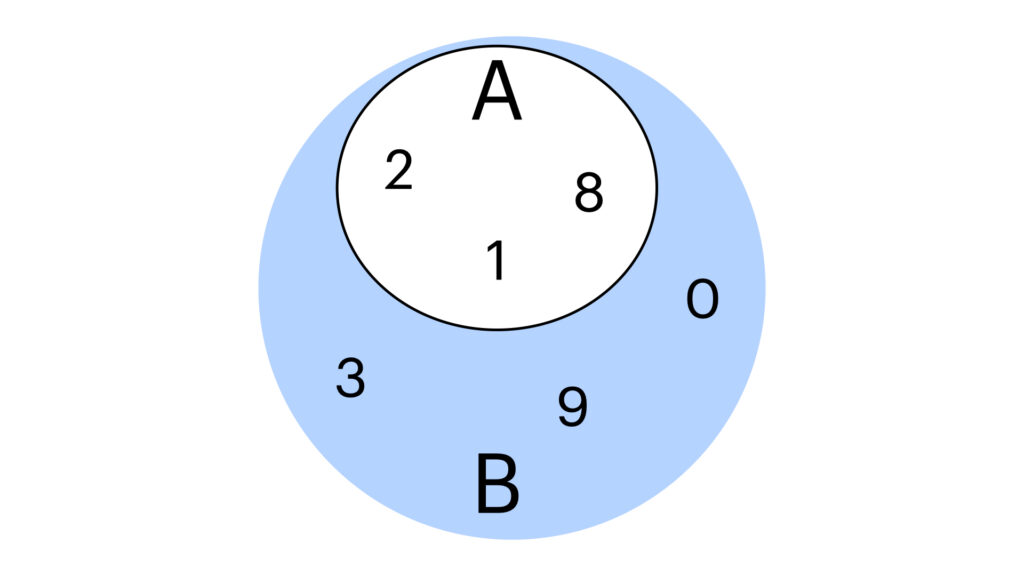
# 1. 字典与集合的基本概念解析
在编程中,字典和集合是两种非常常见的数据结构。它们在数据存储和操作上有着各自的特点和优势。字典,也被称作哈希表,是一种以键值对形式存储数据的结构,允许快速检索、插入和删除操作。而集合是一种包含唯一元素的数据结构,主要用于进行数学上的集合操作,如并集、交集、差集等。
## 字典的概念和应用场景
字典的核心在于键(key)和值(value)的对应关系。每
Python list remove与列表推导式的内存管理:避免内存泄漏的有效策略
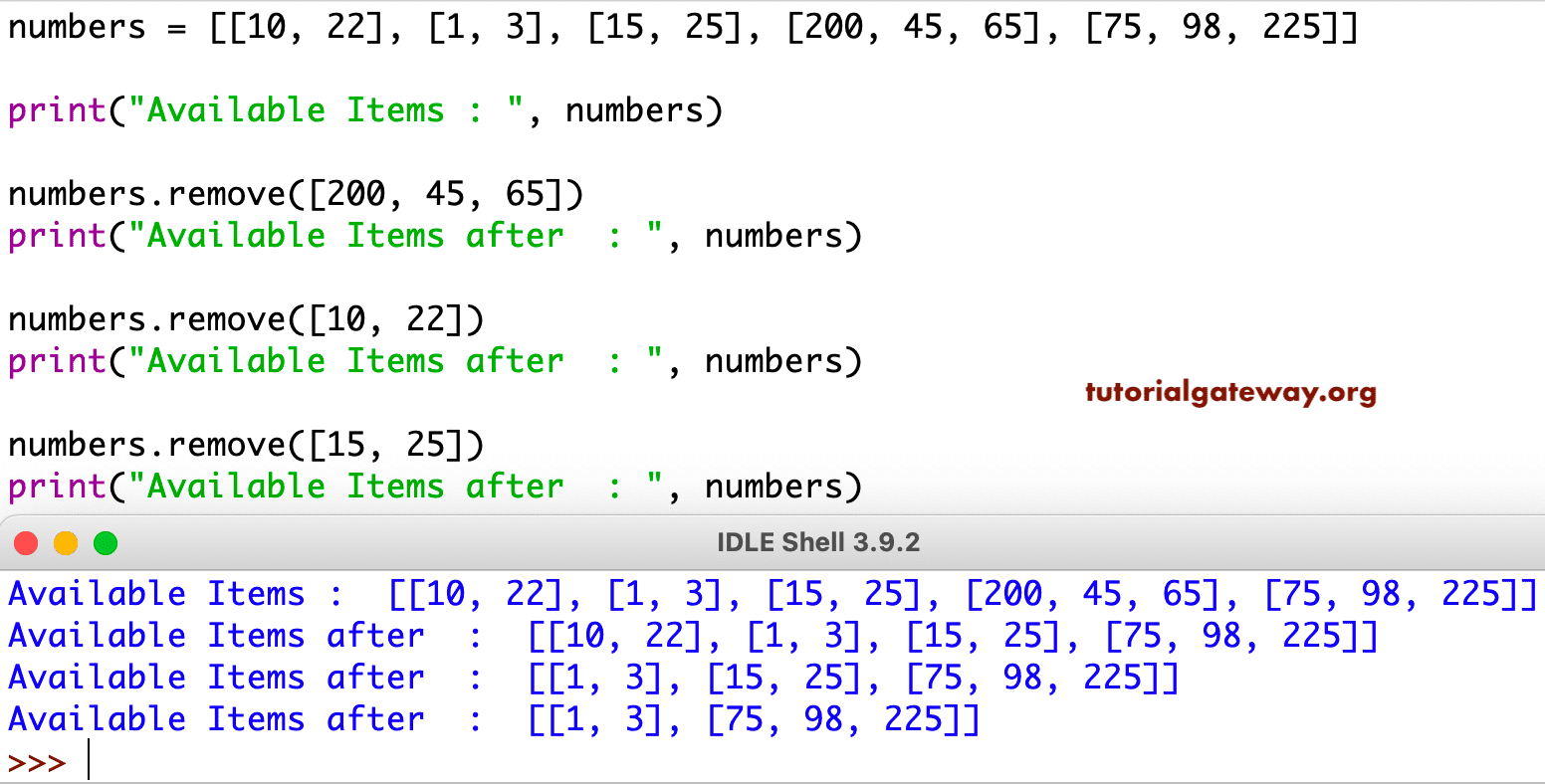
# 1. Python列表基础与内存管理概述
Python作为一门高级编程语言,在内存管理方面提供了众多便捷特性,尤其在处理列表数据结构时,它允许我们以极其简洁的方式进行内存分配与操作。列表是Python中一种基础的数据类型,它是一个可变的、有序的元素集。Python使用动态内存分配来管理列表,这意味着列表的大小可以在运行时根据需要进
【递归与迭代决策指南】:如何在Python中选择正确的循环类型
# 1. 递归与迭代概念解析
## 1.1 基本定义与区别
递归和迭代是算法设计中常见的两种方法,用于解决可以分解为更小、更相似问题的计算任务。**递归**是一种自引用的方法,通过函数调用自身来解决问题,它将问题简化为规模更小的子问题。而**迭代**则是通过重复应用一系列操作来达到解决问题的目的,通常使用循环结构实现。
## 1.2 应用场景
递归算法在需要进行多级逻辑处理时特别有用,例如树的遍历和分治算法。迭代则在数据集合的处理中更为常见,如排序算法和简单的计数任务。理解这两种方法的区别对于选择最合适的算法至关重要,尤其是在关注性能和资源消耗时。
## 1.3 逻辑结构对比
递归
Python函数性能优化:时间与空间复杂度权衡,专家级代码调优
# 1. Python函数性能优化概述
Python是一种解释型的高级编程语言,以其简洁的语法和强大的标准库而闻名。然而,随着应用场景的复杂度增加,性能优化成为了软件开发中的一个重要环节。函数是Python程序的基本执行单元,因此,函数性能优化是提高整体代码运行效率的关键。
## 1.1 为什么要优化Python函数
在大多数情况下,Python的直观和易用性足以满足日常开发
【Python项目管理工具大全】:使用Pipenv和Poetry优化依赖管理

# 1. Python依赖管理的挑战与需求
Python作为一门广泛使用的编程语言,其包管理的便捷性一直是吸引开发者的亮点之一。然而,在依赖管理方面,开发者们面临着各种挑战:从包版本冲突到环境配置复杂性,再到生产环境的精确复现问题。随着项目的增长,这些挑战更是凸显。为了解决这些问题,需求便应运而生——需要一种能够解决版本
Python索引的局限性:当索引不再提高效率时的应对策略

# 1. Python索引的基础知识
在编程世界中,索引是一个至关重要的概念,特别是在处理数组、列表或任何可索引数据结构时。Python中的索引也不例外,它允许我们访问序列中的单个元素、切片、子序列以及其他数据项。理解索引的基础知识,对于编写高效的Python代码至关重要。
## 理解索引的概念
Python中的索引从0开始计数。这意味着列表中的第一个元素
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )