【Python库文件入门篇】:快速掌握Python库文件的基本用法
发布时间: 2024-10-15 05:23:08 阅读量: 9 订阅数: 3 
# 1. Python库文件基础介绍
## 1.1 什么是库文件?
在Python中,库文件通常是指一组预编译的代码模块,它们提供了额外的功能,使得开发者无需从头开始编写代码。这些模块可以包含函数、类、变量等定义,并且通过Python的标准库或第三方库的形式存在。
## 1.2 库文件的重要性
库文件的重要性在于它们的复用性。通过库文件,开发者可以轻松地在不同项目中重复使用同一组代码,从而提高开发效率和代码的可维护性。此外,库文件还促进了代码的标准化,使得团队成员之间的协作更加高效。
## 1.3 如何使用库文件?
使用库文件通常涉及到导入机制。在Python中,我们通过`import`语句来导入所需的模块或包。例如,要使用标准库中的`math`模块,我们可以编写`import math`,之后就可以通过`math.sqrt()`来调用其平方根函数。对于第三方库,我们可能需要先使用包管理工具如`pip`进行安装,然后再进行导入。
通过以上内容,我们可以看到Python库文件的基础概念、重要性以及如何在实际项目中使用它们。接下来的章节将深入探讨库文件的结构和组织,以及如何加载和运行它们,最终达到高级应用并掌握最佳实践。
# 2. 库文件的结构和组织
在本章节中,我们将深入探讨Python库文件的结构和组织,这是构建高效、可维护代码的基础。我们将从模块的定义和组成开始,逐步了解包的概念和使用,以及Python库文件的路径和搜索机制。
## 2.1 Python模块的定义和组成
### 2.1.1 模块的概念和作用
Python模块是包含Python定义和语句的文件。模块可以定义函数、类和变量,也可以包含可执行的代码。模块的概念是Python中重用代码的基本单元,它们使得代码组织更加模块化,便于维护和扩展。
### 2.1.2 模块的内部结构
模块通常包含以下几个部分:
1. **文档字符串(Docstring)**:模块的开头通常包含一个多行字符串,用于描述模块的功能、作者、版权和使用方法等信息。
2. **导入语句(Import Statements)**:用于导入其他模块中的内容,这些语句通常位于模块的顶部。
3. **变量定义(Variable Definitions)**:模块中可以定义各种变量,包括常量和全局变量。
4. **函数定义(Function Definitions)**:模块可以包含一个或多个函数定义,这些函数可以被其他模块调用。
5. **类定义(Class Definitions)**:模块可以定义类,这些类可以在模块外部被实例化和使用。
一个简单的模块示例如下:
```python
"""这是一个简单的模块文档字符串"""
import math
# 变量定义
VERSION = '1.0'
# 函数定义
def say_hello(name):
"""Say hello to a person."""
print(f'Hello {name}!')
# 类定义
class Greeter:
def __init__(self, name):
self.name = name
def greet(self):
print(f'Hello, {self.name}!')
```
## 2.2 包的概念和使用
### 2.2.1 包的基本定义
Python包是一种包含多个模块的命名空间。包的主要目的是为了提供一种结构化的模块命名方式,避免模块名之间的冲突。包实际上是一个包含特殊文件`__init__.py`的目录,该文件可以为空,也可以包含包的初始化代码。
### 2.2.2 命名空间和导入机制
当导入一个包时,Python会执行包中的`__init__.py`文件。这意味着我们可以在这个文件中定义包级别的变量和函数,以及初始化代码。
导入模块时,可以使用点号`.`来访问包中的子模块或子包。例如,假设我们有一个名为`mypackage`的包,它包含一个名为`submodule`的子模块,我们可以通过以下方式导入这个子模块:
```python
import mypackage.submodule
```
## 2.3 Python库文件的路径和搜索
### 2.3.1 模块搜索路径
Python在导入模块时会在一系列目录中搜索,这些目录被存储在一个名为`sys.path`的列表中。这个列表包含了以下路径:
1. 包含输入脚本的目录(或当前目录)。
2. `PYTHONPATH`环境变量中的目录。
3. 安装依赖时安装的默认路径。
### 2.3.2 模块的编译和缓存
当Python首次导入一个模块时,它会编译这个模块并将编译后的版本保存在一个名为`__pycache__`的目录中。编译后的模块以`.pyc`为后缀,这样可以加快后续导入的速度。
为了更好地理解这些概念,我们可以通过一个简单的例子来展示模块的导入过程。假设我们有以下目录结构:
```
mypackage/
__init__.py
submodule/
__init__.py
module.py
```
在`module.py`中定义一个函数:
```python
def example_function():
print("Example function from submodule.module")
```
现在我们可以在`mypackage.submodule`目录下创建一个`__init__.py`文件,并在其中导入`module.py`:
```python
from .module import example_function
```
在另一个脚本中,我们可以这样导入并使用这个函数:
```python
import mypackage.submodule
mypackage.submodule.example_function()
```
在本章节的介绍中,我们已经了解了Python模块和包的基本概念、内部结构以及它们的导入机制。接下来,我们将探讨模块加载和运行的机制,以及如何创建自定义模块和包。
# 3. 库文件的加载和运行
## 3.1 模块的加载机制
### 3.1.1 import语句的工作原理
在Python中,`import`语句是模块加载的核心。当我们执行`import module_name`时,Python会按照以下步骤来加载模块:
1. **检查内置模块**:Python首先会检查该模块是否为内置模块,如果是,则直接加载。
2. **搜索模块**:如果不是内置模块,Python会在`sys.path`列表中搜索模块。`sys.path`是一个字符串列表,包含了模块搜索的路径。
3. **模块编译**:找到模块文件后,Python会根据文件后缀名(`.pyc`为编译后的字节码文件)来决定是直接加载源代码还是加载编译后的字节码。
4. **执行模块代码**:加载模块后,Python会执行模块中的顶层代码,这些代码只会执行一次。如果再次`import`同一个模块,Python会从`sys.modules`字典中获取已经加载的模块对象。
```python
import sys
print(sys.path) # 查看模块搜索路径
import math # 导入math模块
print(math.sqrt(16)) # 使用math模块中的sqrt函数
```
在上述代码中,我们首先打印了模块搜索路径,然后导入了`math`模块并使用了其`sqrt`函数来计算平方根。
### 3.1.2 模块加载过程中的常见问题
在模块加载过程中,可能会遇到一些常见的问题:
- **模块不存在**:如果尝试导入一个不存在的模块,Python会抛出`ImportError`。
- **循环导入**:如果两个模块相互导入对方,就会发生循环导入的问题,这通常会导致代码执行到一半时抛出异常。
- **包结构错误**:如果包的结构不正确,例如缺少`__init__.py`文件,Python会将该目录视为普通目录而非包。
- **导入冲突**:如果不同模块中有同名的类或函数,使用时可能会引起冲突。
```python
# 示例:循环导入的错误
import module_a
class B:
pass
module_b = __import__('module_b')
module_a.module_b = module_b
# module_b.py
import module_a
class A:
pass
module_a = __import__('module_a')
module_a.module_a = module_a
```
在上述示例中,`module_a`和`module_b`相互导入对方,这将导致Python解释器抛出`ImportError`。
## 3.2 模块和包的运行模式
### 3.2.1 模块的编译和执行
Python模块的执行流程涉及两个阶段:编译和执行。当Python解释器加载一个`.py`文件时,它会先将源代码编译成字节码,然后执行这些字节码。这个过程主要涉及以下几个步骤:
1. **解析源代码**:解释器会先对源代码进行解析,生成一个抽象语法树(AST)。
2. **编译为字节码**:然后将AST编译成字节码。
3. **执行字节码**:最后,Python虚拟机会执行编译后的字节码。
```python
# 示例:模块的编译和执行
import sys
import dis
def test():
x = 1
y = 2
return x + y
# 可以通过sys.modules来查看模块是否已经被加载
print(sys.modules.keys())
# 使用dis模块来查看字节码
dis.dis(test)
```
在上述代码中,我们使用`dis`模块来查看`test`函数的字节码。
### 3.2.2 包的初始化过程
包是一个包含`__init__.py`文件的目录,它可以让目录被视为Python的包。当包中的模块被首次导入时,`__init__.py`文件会被执行。这个过程涉及以下几个步骤:
1. **创建包的命名空间**:在导入包的模块之前,解释器会创建一个空的命名空间。
2. **执行`__init__.py`文件**:如果存在`__init__.py`文件,解释器会执行其中的代码,这些代码通常用于初始化包的状态。
3. **设置`__all__`变量**:如果`__init__.py`中定义了`__all__`变量,它将被用作`from package import *`语句时要导入的模块列表。
```python
# 示例:包的初始化过程
# package/__init__.py
print("Initializing package...")
__all__ = ["module_a", "module_b"]
# package/module_a.py
def a():
return "Module A"
# package/module_b.py
def b():
return "Module B"
```
在上述示例中,我们创建了一个名为`package`的包,它包含两个模块`module_a`和`module_b`,以及一个`__init__.py`文件。
## 3.3 实践:创建自定义模块和包
### 3.3.1 编写模块
创建一个自定义模块很简单,只需编写一个`.py`文件即可。例如,创建一个名为`my_module.py`的文件,内容如下:
```python
# my_module.py
def greet(name):
print(f"Hello, {name}!")
def farewell(name):
print(f"Goodbye, {name}!")
```
在这个模块中,我们定义了两个函数`greet`和`farewell`。之后,我们可以在其他Python代码中导入并使用这个模块。
### 3.3.2 创建和使用包
创建一个包需要一个包含`__init__.py`文件的目录。例如,创建一个名为`my_package`的包,结构如下:
```
my_package/
├── __init__.py
├── module_a.py
└── module_b.py
```
在`my_package/__init__.py`中,我们可以添加初始化代码:
```python
# my_package/__init__.py
from .module_a import *
from .module_b import *
```
在`my_package/module_a.py`和`my_package/module_b.py`中,我们可以定义各自的函数和类。之后,我们可以在其他模块中通过`import my_package`来导入整个包。
通过本章节的介绍,我们深入了解了Python中模块和包的加载机制、运行模式以及如何创建和使用自定义模块和包。这些知识对于编写可重用、模块化的Python代码至关重要。在下一章节中,我们将探讨库文件的高级应用,包括标准库和第三方库的使用和管理,以及如何在项目中集成和使用这些库。
# 4. 成功的Python库项目
在本章节中,我们将深入探讨一些成功的Python库项目,分析它们的设计、实现、测试和维护过程。通过对这些案例的学习,我们可以更好地理解如何构建高质量的Python库,并将这些知识应用到我们自己的项目中。
#### 5.3.1 项目背景和需求分析
在开始构建一个Python库之前,深入理解项目背景和需求分析是至关重要的。这个阶段涉及到收集用户需求、确定项目目标以及定义项目的范围。例如,假设我们要为数据分析构建一个库,我们需要了解数据分析的主要工作流程、常见的数据处理任务以及目标用户群体。
**需求分析的关键步骤**包括:
1. **用户访谈**:与潜在用户进行交流,了解他们的痛点和需求。
2. **市场调研**:研究现有的解决方案,确定市场缺口。
3. **功能定义**:基于收集到的信息,定义库的核心功能和附加特性。
4. **优先级排序**:对功能进行优先级排序,确定初期开发的重点。
**案例分析**:
假设我们正在为机器学习工程师开发一个库,名为`MLUtils`,它旨在简化机器学习任务的预处理步骤。经过用户访谈和市场调研,我们发现以下需求:
- 数据清洗功能,如缺失值处理和异常值检测。
- 特征工程工具,包括标准化、归一化和编码器。
- 快速实验框架,以支持快速原型设计和模型迭代。
#### 5.3.2 实现方案和关键点讲解
在确定了项目的需求之后,下一步是设计实现方案。在这个阶段,我们需要决定如何构建库的架构,以及如何实现具体的功能。
**实现方案的关键步骤**包括:
1. **模块化设计**:将库分解为多个模块,每个模块负责一组相关的功能。
2. **接口定义**:为每个模块定义清晰的API,确保易用性和一致性。
3. **性能优化**:针对性能瓶颈进行优化,例如使用Cython加速关键代码段。
4. **测试和文档**:编写单元测试和文档,确保库的可靠性和易用性。
**案例分析**:
对于`MLUtils`库,我们决定采用以下实现方案:
- **模块化设计**:`MLUtils`被分为三个主要模块:`data_cleaning`、`feature_engineering`和`experimentation`。
- **接口定义**:每个模块都提供了一组函数和类,例如`data_cleaning`模块提供了`remove_missing_values()`和`detect_outliers()`函数。
- **性能优化**:对于数据清洗模块中的复杂操作,如缺失值插补,我们使用了Numba进行加速。
- **测试和文档**:为每个功能编写了详细的单元测试,并且为每个模块编写了用户指南。
**代码块示例**:
```python
# data_cleaning.py 模块示例
def remove_missing_values(data):
"""
Remove missing values from the dataset.
Parameters:
- data: pandas.DataFrame, the dataset to clean.
Returns:
- pandas.DataFrame, the cleaned dataset without missing values.
"""
# Implementation goes here...
pass
def detect_outliers(data, threshold=3):
"""
Detect outliers in the dataset.
Parameters:
- data: pandas.DataFrame, the dataset to analyze.
- threshold: float, the threshold for detecting outliers.
Returns:
- pandas.Series, a boolean series indicating outliers.
"""
# Implementation goes here...
pass
```
在本章节中,我们通过案例分析的方式,详细探讨了成功的Python库项目的背景、需求分析、实现方案和关键点。通过深入分析这些实际案例,我们可以学习到如何将理论知识应用到实践中,并构建出高质量的Python库。
# 5. 库文件的最佳实践和案例分析
## 5.1 库文件设计的最佳实践
### 5.1.1 模块和包的设计原则
在设计Python库文件时,遵循一些最佳实践可以帮助我们创建出更加优雅、可维护和可扩展的代码。首先,模块和包的设计应当遵循单一职责原则,即一个模块或包只做一件事情,并且做得很好。这样做的好处是,当需求变化时,我们可以更容易地修改或替换特定的模块,而不会影响到整个系统的其他部分。
其次,模块和包应当具有清晰的接口和文档。这意味着我们应当为每个模块和包定义清晰的API,并且提供足够的文档来说明如何使用它们。这不仅有助于其他开发者理解和使用我们的代码,也为将来的维护提供了便利。
最后,模块和包应当具有良好的封装性。我们应该隐藏内部实现细节,只暴露必要的接口供外部使用。这样可以减少外部代码对内部实现的依赖,使得我们可以在不影响外部代码的情况下修改内部实现。
### 5.1.2 代码的可重用性和维护性
为了提高代码的可重用性,我们应当尽量避免代码重复。这可以通过编写通用的函数和类来实现,以便它们可以在多个地方被重用。此外,我们还应当设计通用的接口,使得我们的模块和包可以容易地集成到不同的项目中。
为了提高代码的维护性,我们应当编写清晰、简洁的代码,并且遵循一致的编码风格。此外,我们还应当编写单元测试来验证代码的正确性,并且在修改代码时运行这些测试来确保新的修改没有破坏原有功能。
## 5.2 库文件的测试和调试
### 5.2.* 单元测试的编写
单元测试是检查代码中的各个最小单元(通常是函数或类的方法)是否按照预期工作的测试。在Python中,我们通常使用`unittest`模块来编写单元测试。一个基本的单元测试示例如下:
```python
import unittest
class TestStringMethods(unittest.TestCase):
def test_upper(self):
self.assertEqual('foo'.upper(), 'FOO')
def test_isupper(self):
self.assertTrue('FOO'.isupper())
self.assertFalse('Foo'.isupper())
if __name__ == '__main__':
unittest.main()
```
在这个示例中,我们定义了一个`TestStringMethods`类,它继承自`unittest.TestCase`。然后我们定义了两个测试方法:`test_upper`和`test_isupper`,它们分别测试字符串的`upper`方法和`isupper`方法是否工作正常。
### 5.2.2 调试技巧和工具的使用
在开发过程中,我们不可避免地会遇到bug。Python提供了多种调试工具来帮助我们定位和修复这些bug。其中最常用的工具之一是`pdb`,即Python调试器。`pdb`允许我们在代码中设置断点,然后逐步执行代码来观察程序的行为。
例如,以下是一个使用`pdb`进行调试的示例:
```python
import pdb
def find_sum_of_numbers(numbers):
total = 0
for number in numbers:
pdb.set_trace()
total += number
return total
print(find_sum_of_numbers([1, 2, 3, 4]))
```
在这个示例中,我们定义了一个`find_sum_of_numbers`函数,它计算传入列表的数字总和。我们使用`pdb.set_trace()`在循环体内部设置了一个断点。当程序运行到这个断点时,它会暂停,并且我们可以在`pdb`提示符下检查变量的值,执行命令等。
## 5.3 案例分析:成功的Python库项目
### 5.3.1 项目背景和需求分析
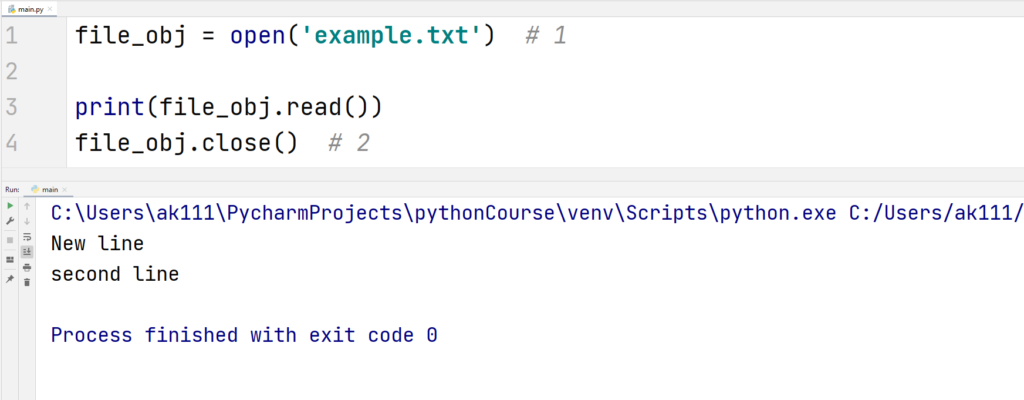
让我们考虑一个简单的Python库项目,该库的目的是提供一组工具函数来处理文本文件。用户希望能够轻松读取文本文件的内容,并执行一些基本的操作,如统计单词数量、查找特定单词等。
### 5.3.2 实现方案和关键点讲解
为了满足这些需求,我们决定创建一个名为`textutils`的库。该库将包含以下模块:
- `file_ops.py`:包含读取和写入文件的函数。
- `word_count.py`:包含统计单词数量的函数。
- `search.py`:包含搜索特定单词或模式的函数。
下面是`file_ops.py`模块的一个简单实现:
```python
def read_file(path):
with open(path, 'r') as ***
***
*** 'w') as ***
***
```
在这个模块中,我们定义了两个函数:`read_file`和`write_file`,分别用于读取和写入文件。
我们还需要编写单元测试来确保这些函数的正确性。以下是`file_ops.py`模块的单元测试示例:
```python
import unittest
from textutils.file_ops import read_file, write_file
class TestFileOperations(unittest.TestCase):
def setUp(self):
self.test_file_path = 'test_file.txt'
self.test_content = 'Hello, world!'
def test_read_file(self):
write_file(self.test_file_path, self.test_content)
self.assertEqual(read_file(self.test_file_path), self.test_content)
def test_write_file(self):
write_file(self.test_file_path, self.test_content)
with open(self.test_file_path, 'r') as ***
***
*** '__main__':
unittest.main()
```
在这个测试中,我们使用`setUp`方法来准备测试环境,即写入一个测试文件。然后我们测试`read_file`和`write_file`函数是否按照预期工作。
通过这种方式,我们不仅确保了代码的正确性,还提供了一个可扩展的库项目基础,未来可以添加更多的功能和模块。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Twisted.application服务发现策略】:微服务架构中的Twisted应用探索
# 1. Twisted.application服务发现策略概述
## 1.1 Twisted.application简介
Twisted.application是一个基于Twisted框架的应用开发和管理工具,它提供了构建复杂网络应用所需的高级抽象。在微服务架构中,服务发现策略是确保服务间高效
【部署秘籍】:从零开始的***ments.forms项目生产环境部署指南
# 1. 项目概述与部署准备
## 1.1 项目简介
在当今快速发展的IT行业中,高效和可靠的项目部署是至关重要的。本章将概述项目的基本信息,包括项目的目标、预期功能和部署的基本要求。我们将讨论为何选择特定的技术栈,以及如何确保项目从一开始就能沿着正确的轨道前进。
## 1.2 部署准备的重要性
在实际的项目部
【数据库操作最佳实践】:Win32serviceutil服务程序中的数据库集成
# 1. 数据库操作与Win32serviceutil服务程序概述
数据库操作是现代软件开发中不可或缺的一部分,它涉及到数据的存储、检索、更新和删除等核心功能。而在Windows环境下,Win32serviceutil服务程序提供了一种将数据库操作集成到后台服务中去的方法,使得应用程序可以更加稳定和高效地运
【py_compile与自定义编译器】:创建自定义Python编译器的步骤

# 1. py_compile模块概述
## 1.1 Python编译过程简介
Python作为一种解释型语言,其源代码在执行前需要被编译成字节码。这个编译过程是Python运行时自动完成的,但也可以通过`py_compile`模块手动触发。编译过程主要是将`.py`文件转换为`.pyc`文件,这些字节码文件可以被Python解释器更高效地加载和执行。
##
【性能调优】:优化SimpleXMLRPCServer内存和CPU使用的专家指南

# 1. 性能调优概述
性能调优是确保软件系统高效运行的关键环节。在本章中,我们将概述性能调优的基本概念,其重要性以及如何制定有效的性能优化策略。我们将从性能调优的目的出发,探讨其在软件开发周期中的作用,以及如何在不同阶段应用性能调优的实践。
## 1.1 性能调优的目
Numpy.Testing模拟对象:模拟外部依赖进行测试(模拟技术深入讲解)

# 1. Numpy.Testing模拟对象概述
在本章节中,我们将对Numpy.Testing模块中的模拟对象功能进行一个基础的概述。首先,我们会了解模拟对象在单元测试中的作用和重要性,以及它们如何帮助开发者在隔离环境中测试代码片段。接下来,我们将探索Numpy.Testing模块的主要功能,并简要介绍如何安装和配置该模块以供使用。
##
Python Win32Service模块的安全最佳实践:构建安全可靠的Windows服务
# 1. Win32Service模块概述
## 1.1 Win32Service模块简介
Win32Service模块是Windows操作系统中用于管理本地服务的核心组件。它允许开发者以编程方式创建、配置、启动和停止服务。在系统和网络管理中,服务扮演着至关重要的角色,
【Python与Win32GUI】:绘图和控件自定义的高级技巧
# 1. Python与Win32GUI概述
在IT行业中,Python以其简洁、易用的特点广受欢迎,特别是在自动化脚本和快速原型开发方面。Win32GUI是Windows操作系统中用于创建图形用户界面的一种技术,它为Python提供了强大的GUI开发能力。本章我们将探讨Python与Win32GUI的基础知识,为深入学习Win32GUI的绘图技术和控件自定义打下坚实的
【Django GIS日常维护】:保持django.contrib.gis.maps.google.overlays系统健康运行的秘诀

# 1. Django GIS概述与安装配置
## 1.1 Django GIS简介
Django GIS是Django框架的一个扩展,它为Web应用提供了强大的地理信息系统(GIS)支持。GIS技术能够帮助
【Python终端性能基准测试】:如何评估tty模块性能
# 1. Python终端性能基准测试概述
## 1.1 性能基准测试的意义
在软件开发和维护过程中,性能基准测试是确保应用性能和稳定性的关键步骤。对于Python这种广泛使用的编程语言来说,终端性能的基准测试尤其重要,因为它直接影响到开发者和用户的交互体验。通过对Python程序的性能基准测试,可以量化程序的运行效率,发现问题和瓶颈,进而指导性能优化。
## 1.2 基准测试的类型和方法
性能基准测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )