【Twisted.application服务发现策略】:微服务架构中的Twisted应用探索
发布时间: 2024-10-15 08:41:05 阅读量: 20 订阅数: 17 
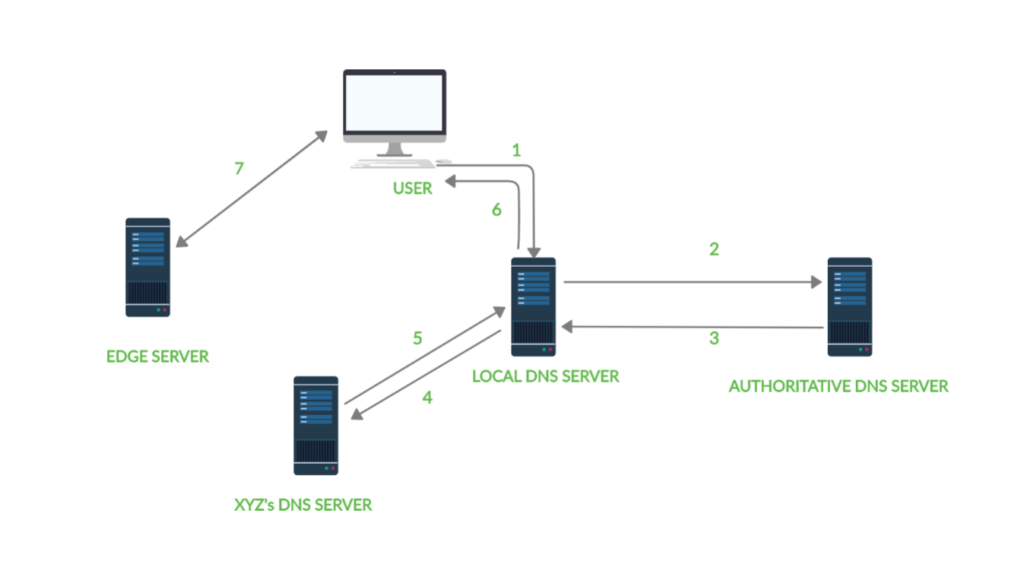
# 1. Twisted.application服务发现策略概述
## 1.1 Twisted.application简介
Twisted.application是一个基于Twisted框架的应用开发和管理工具,它提供了构建复杂网络应用所需的高级抽象。在微服务架构中,服务发现策略是确保服务间高效通信的关键。Twisted.application通过提供服务注册和发现机制,帮助开发者实现服务的动态发现,从而提高系统的可扩展性和灵活性。
## 1.2 服务发现策略的重要性
服务发现策略在微服务架构中扮演着至关重要的角色。它不仅需要能够快速准确地定位服务实例,还要能够适应服务实例的动态变化。Twisted.application通过其服务发现机制,使得服务间的通信更加高效,同时降低了开发和维护的复杂性。
## 1.3 本章内容结构
本章将首先介绍服务发现策略的基本概念,然后深入探讨Twisted.application如何实现服务注册和发现,最后通过实例演示如何在实际项目中应用这些策略。接下来的章节将详细讨论Twisted框架的基础知识,以及如何在微服务架构中应用Twisted.application,从而为读者提供一个全面的理解和实践指南。
# 2. Twisted框架与微服务架构基础
## 2.1 Twisted框架的核心概念
### 2.1.1 Twisted框架简介
Twisted是Python中一个非常知名的事件驱动网络引擎,它支持广泛的网络协议,包括TCP, UDP, SSL/TLS, HTTP, IMAP, SSH等。Twisted为网络编程提供了一种独特的编程范式,即事件驱动编程。这种编程范式允许开发者以非阻塞的方式处理网络通信,从而使得应用程序能够更高效地处理大量并发连接。
Twisted的核心是一个事件循环,它负责监听事件源,并在事件发生时触发相应的回调函数。开发者通过编写回调函数来处理网络事件,如数据接收、连接建立和断开等。这种模式避免了传统的多线程或多进程模型中的线程管理开销,尤其是在处理大量并发连接时。
### 2.1.2 异步编程模型与事件循环
异步编程模型是一种非阻塞的编程方式,它允许程序在等待一个长时间的操作(如网络请求)完成时,继续执行其他任务。这种模型在处理IO密集型操作时特别有用,因为它可以显著提高程序的响应性和吞吐量。
Twisted的事件循环是实现异步编程的关键。事件循环维护着一个待处理事件的队列,当事件发生时,事件循环会从队列中取出事件,并执行与之关联的回调函数。回调函数通常是非阻塞的,并且可能产生新的事件,这些新事件也会被加入队列中等待处理。
Twisted框架使用Deferred对象来处理异步操作。Deferred对象代表了一个尚未完成的异步操作,并提供了回调函数链式调用的能力。开发者可以注册回调函数到Deferred对象,当异步操作完成时,这些回调函数将按顺序被调用。
```python
from twisted.internet import reactor, defer
def callback(result):
print("Operation completed successfully:", result)
def errback(failure):
print("Operation failed:", failure)
deferred = Deferred()
deferred.addCallback(callback) # 注册成功回调
deferred.addErrback(errback) # 注册失败回调
# 模拟异步操作完成
reactor.callLater(1, deferred.callback, "Result") # 1秒后调用回调函数
reactor.run()
```
在上述代码中,我们创建了一个Deferred对象,并为其添加了成功和失败的回调函数。我们使用`reactor.callLater`来模拟异步操作的完成。这种模式允许我们在不阻塞主程序流程的情况下处理异步事件。
## 2.2 微服务架构的基本原理
### 2.2.1 微服务定义及特点
微服务架构是一种将单一应用程序构建成一组小服务的方式,每个服务运行在其独立的进程中,并通过轻量级的通信机制(通常是HTTP RESTful API)进行交互。每个微服务围绕特定的业务功能构建,并可以独立部署、扩展和更新。
微服务架构的主要特点包括:
- **服务自治**:每个服务独立管理自己的代码库、运行时环境和版本。
- **分布式治理**:服务可以使用不同的技术栈,并且各自拥有不同的部署策略。
- **容错性**:服务的失败不会导致整个系统的崩溃。
- **弹性**:服务可以根据需求自动扩展或缩减资源。
- **去中心化**:没有单个的控制点或服务总线。
### 2.2.2 微服务架构中的服务注册与发现机制
在微服务架构中,服务实例可能会频繁地启动和关闭,因此需要一种机制来追踪服务的当前状态。服务注册与发现机制是微服务架构中的关键组成部分,它允许服务实例注册自己的位置(如IP地址和端口号),并且使其他服务能够发现并访问这些实例。
服务注册中心通常由一个注册表组成,服务实例在启动时会将自己的网络位置信息注册到注册中心,并在关闭时注销。服务发现则是服务消费者查询注册中心以获取可用服务实例的过程。
### 2.3 Twisted.application的角色和功能
#### 2.3.1 Twisted.application的组件结构
Twisted.application是一个管理Twisted服务的应用程序框架。它提供了一种方式来组织和启动Twisted服务,使得开发人员可以更容易地构建复杂的网络应用程序。
Twisted.application的组件结构主要包括:
- **Service**:代表一个服务,它定义了服务的生命周期方法,如启动和停止。
- **Application**:代表整个应用程序,它可以包含多个服务,并负责协调这些服务的生命周期。
- **Site**:代表一个Web服务,它管理Web服务器和相关的Web应用程序。
- **Factory**:用于创建服务实例,如TCP服务器和客户端。
#### 2.3.2 Twisted.application在服务发现中的作用
在服务发现中,Twisted.application可以作为服务注册中心的客户端。服务实例可以注册为Twisted.application的一部分,并将自身信息(如服务名、IP地址和端口号)注册到服务注册中心。服务消费者可以通过Twisted.application提供的API来发现这些服务实例,并与它们建立连接。
Twisted.application可以通过其组件结构来管理服务的注册和发现流程,使得服务实例能够更加容易地与服务注册中心集成。此外,Twisted.application还可以通过事件循环机制来处理服务发现过程中的异步操作,如查询服务注册中心并等待响应。
```python
from twisted.application import service, internet
from twisted.internet import reactor
from twisted.protocols.basic import StringReceiver
class EchoService(service.Service):
def startService(self):
self.factory = EchoFactory()
self.server = internet.TCPServer(1234, self.factory)
return self.server.startService()
def stopService(self):
return self.server.stopService()
class EchoFactory(StringReceiver):
def connectionMade(self):
self.transport.write("Hello, world!")
application = service.Application("EchoServer")
service = EchoService()
service.setServiceParent(application)
reactor.listenTCP(1234, EchoFactory())
reactor.run()
```
在上述代码中,我们创建了一个简单的Echo服务,它监听TCP端口1234,并向连接的客户端发送"Hello, world!"消息。这个服务可以注册到Twisted.application中,使其能够作为服务发现的一部分。通过这种方式,其他服务可以发现并连接到Echo服务,与之进行交互。
# 3. Twisted.application服务发现策略的实现
在本章节中,我们将深入探讨Twisted.application服务发现策略的实现细节。服务发现是微服务架构中的核心组件,它允许服务相互查找并进行通信。Twisted.application提供了一套机制来实现服务的注册与发现,这使得开发者能够在Twisted框架的基础上构建复杂的服务网络。
## 3.1 服务注册与发现机制的理论基础
### 3.1.1 服务注册的原理
服务注册是服务发现的第一步。在这个过程中,服务实例将其网络位置(如IP地址和端口号)注册到一个中央注册表中。这个注册表通常是一个服务注册中心,它可以是一个简单的数据库,也可以是一个更复杂的分布式系统,如Consul、Etcd或Zookeeper。
### 3.1.2 服务发现的策略类型
服务发现策略决定了服务消费者如何找到服务提供者。常见的策略包括:
- **客户端发现**:服务消费者负责查询服务注册中心以获取服务提供者的位置信息。
- **服务端发现**:服务消费者通过与服务代理(如负载均衡器)通信来找到服务提供者,服务代理负责与服务注册中心通信并转发请求。
## 3.2 Twisted.application的服务注册过程
### 3.2.1 服务注册的API实现
在Twisted.application中,服务注册可以通过定义特定的API来实现。这些API允许服务实例在启动时向注册中心注册自己,并在停止时注销自己。
```python
from twisted.application import service
from twisted.python import log
from myservice import MyService
class MyRegistrant(service.Service):
def __init__(self, registrar, **kwargs):
self.registrar = registrar
def startService(self):
self.registered = False
# 注册服务逻辑
d
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 Twisted.application 库,指导开发者构建高效、可扩展的 Python 网络应用程序。从入门速成到事件循环、任务调度、异常处理、日志记录、插件机制、配置管理、部署策略、RESTful API 构建、网络框架集成、资源管理、监控维护、服务发现等方面,全面揭秘 Twisted.application 的核心技术。通过一系列深入浅出的文章,本专栏旨在帮助开发者掌握 Twisted.application 的精髓,打造稳定可靠、性能卓越的网络应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
【Python讯飞星火LLM调优指南】:3步骤提升模型的准确率与效率

# 1. Python讯飞星火LLM模型概述
## 1.1 模型简介
Python讯飞星火LLM(Xunfei Spark LLM)是基于Python开发的自然语言处理模型,由北京讯飞公司推出。该模型主要通过大规模语言模型(LLM)技术,提供包括文本分类、命名实体识别、情感分析等自然语言处理任务的解决方案。由于其出色的性能和易用性,讯飞星火LLM在业界获得了广泛的
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【数据分片技术】:实现在线音乐系统数据库的负载均衡
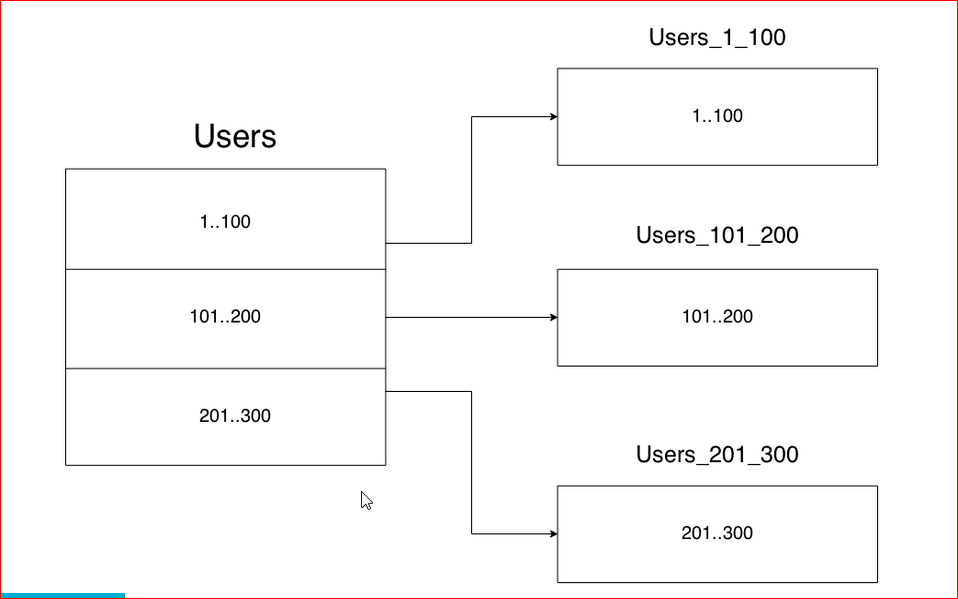
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )