【Python讯飞星火LLM调优指南】:3步骤提升模型的准确率与效率
发布时间: 2024-11-15 10:20:11 阅读量: 19 订阅数: 29 

实现SAR回波的BAQ压缩功能

# 1. Python讯飞星火LLM模型概述
## 1.1 模型简介
Python讯飞星火LLM(Xunfei Spark LLM)是基于Python开发的自然语言处理模型,由北京讯飞公司推出。该模型主要通过大规模语言模型(LLM)技术,提供包括文本分类、命名实体识别、情感分析等自然语言处理任务的解决方案。由于其出色的性能和易用性,讯飞星火LLM在业界获得了广泛的关注。
## 1.2 应用场景
该模型应用场景非常广泛,包括但不限于搜索引擎、智能客服、语音识别、文本审核等。得益于讯飞公司强大的数据处理和AI技术,星火LLM模型在处理中文语境下的任务具有天然的优势。
## 1.3 开发环境与依赖
在使用讯飞星火LLM模型之前,开发者需要确保系统安装了Python环境,并且安装了讯飞提供的SDK包。模型的运行依赖于讯飞提供的API接口,开发者需要获取相应的API密钥进行验证。
```
# 安装讯飞星火LLM SDK的示例代码
pip install xunfei_spark_llm
```
## 1.4 初步使用
开发者可以使用讯飞SDK提供的类和函数来初步使用星火LLM模型。以下是一个简单的例子,展示了如何调用模型进行文本分类任务:
```python
from xunfei_spark_llm import LLM
# 实例化模型
model = LLM(api_key="YOUR_API_KEY")
# 进行文本分类
result = model.classify("我今天心情很好")
print(result)
```
以上代码展示了如何导入模型类,实例化对象,并对一条简单的文本进行分类。这只是星火LLM模型功能的一个冰山一角,更多高级功能和应用将在后续章节中详细介绍。
# 2. 模型性能评估与分析
## 2.1 模型准确率的评估方法
### 2.1.1 正确率、召回率和F1分数
在评估分类模型的性能时,正确率、召回率和F1分数是三个重要的指标。正确率衡量的是模型预测正确的样本占总样本的比例,公式可以表示为:正确率 = TP / (TP + FP)。其中TP是真正类的数量,FP是假正类的数量。召回率衡量的是模型正确识别的正类占所有正类样本的比例,公式为:召回率 = TP / (TP + FN)。FN是假负类的数量。
F1分数是正确率和召回率的调和平均数,它综合考虑了模型预测的准确性和完整性,公式为:F1分数 = 2 * (正确率 * 召回率) / (正确率 + 召回率)。F1分数取值范围在0到1之间,分数越高表示模型性能越好。
在实际应用中,正确率和召回率往往需要根据问题的具体场景来进行权衡。比如在医疗影像识别中,召回率可能更为重要,因为漏诊的后果可能比误诊更严重。
```python
# Python 示例代码计算正确率、召回率和F1分数
from sklearn.metrics import precision_score, recall_score, f1_score
# 假设y_true是真实标签,y_pred是模型预测标签
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 0, 1, 0, 1]
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"正确率: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1分数: {f1:.2f}")
```
### 2.1.2 混淆矩阵的解读
混淆矩阵是一个表格,用来可视化分类器的性能,尤其是当分类器不完美时,可以清晰展示出分类器正确和错误分类的情况。在二分类问题中,混淆矩阵由四个部分组成:
- 真正类(True Positive, TP):被正确预测为正类的样本数量。
- 假正类(False Positive, FP):被错误预测为正类的样本数量。
- 真负类(True Negative, TN):被正确预测为负类的样本数量。
- 假负类(False Negative, FN):被错误预测为负类的样本数量。
```python
# Python 示例代码生成混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 混淆矩阵数据
cm = confusion_matrix(y_true, y_pred)
# 使用seaborn绘制热力图
sns.heatmap(cm, annot=True, fmt="d")
plt.ylabel('实际标签')
plt.xlabel('预测标签')
plt.show()
```
## 2.2 模型效率的评估指标
### 2.2.1 计算时间与资源消耗
模型效率的评估通常关注计算时间(或响应时间)和资源消耗(包括内存和CPU/GPU利用率)。计算时间是指模型从输入数据处理到输出结果所需的时间,它直接关联到用户体验和实时处理能力。资源消耗是模型运行时占用的内存、硬盘和处理器资源,它是影响模型部署成本的重要因素。
评估计算时间和资源消耗时,可以记录模型训练和预测的时间戳,以及在运行时监控内存和处理器使用率。在实际应用中,往往需要在准确率和效率之间做权衡。
```python
# Python 示例代码评估模型的计算时间和资源消耗
import time
import torch
# 假设一个简单模型的预测函数
def model_predict(input_data):
# 这里用一个简单的计算来模拟预测过程
output = torch.matmul(input_data, torch.rand(10, 10))
return output
# 记录开始时间
start_time = time.time()
# 进行多次预测模拟
for _ in range(1000):
input_data = torch.randn(10, 10)
model_predict(input_data)
# 计算结束时间
end_time = time.time()
# 打印计算时间
print(f"模型计算时间: {(end_time - start_time):.4f}秒")
```
### 2.2.2 并行处理与分布式计算
并行处理和分布式计算是提高模型效率的重要手段。并行处理是指在多个处理器上同时执行计算任务,以减少完成任务所需的总时间。分布式计算则是在多台计算机上分配计算任务,适用于大规模数据集或复杂的模型。
在实际应用中,可以使用多线程或多进程来实现并行处理。而分布式计算通常会用到一些成熟的框架,如Apache Spark或Dask。通过合理地设计并行和分布式策略,可以显著提升模型的处理效率和扩展性。
```python
# Python 示例代码使用多线程进行并行处理
import concurrent.futures
def process_data(data):
# 这里简化为一个计算过程
return sum(data)
data_sets = [list(range(1000)) for _ in range(10)]
# 使用线程池进行并行处理
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(process_data, data_sets))
print(f"并行处理结果: {results}")
```
## 2.3 模型误差分析与诊断
### 2.3.1 过拟合与欠拟合的识别
过拟合是指模型在训练数据上拟合得太好,以至于丢失了泛化能力,不能很好地推广到新的数据上。欠拟合则是指模型过于简单,不能捕捉到数据的真实分布,导致在训练和测试数据上的表现都不佳。识别过拟合和欠拟合,可以采用以下方法:
- **绘制学习曲线**:通过绘

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python讯飞星火LLM教程”专栏!本专栏为您提供全面的指南,帮助您掌握讯飞星火LLM的强大功能。通过一系列详细的文章,您将学习如何:
- 优化模型以提高准确性和效率
- 管理模型版本,实现高效的迭代和维护
- 访问最新学习资料和工具,不断提升技能
- 快速解决常见问题,确保模型的顺畅运行
无论您是初学者还是经验丰富的开发者,本专栏都将为您提供宝贵的见解和实用技巧。通过遵循我们的循序渐进的指南,您将能够充分利用讯飞星火LLM,创建出色的自然语言处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RTCM 3.3协议的10大秘密】:精通实时定位技术的终极指南

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议概述
RTCM 3.3是实时差分全球定位系统(GNSS
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
升级你的IS903:固件更新全攻略,提升性能与稳定性的终极指南

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. IS903固件更新的必要性和好处
## 理解固件更新的重要性
固件更新,对于任何智能设备来说,都是一个关键的维护步骤。IS903作为一款高性能的设备,其固件更新不仅仅是为了修
ROST软件高级用户必看:全面掌握工具每一个细节的独家技巧
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
# 1. ROST软件概述与安装指南
## ROST
【cx_Oracle权威指南】:版本升级、环境配置与最佳实践案例解析

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle简介与历史回顾
cx_Oracle 是一个流行的 Python 扩展,用于访问 Oracle 数据库。它提供了一个接口,允许 Python 程序
ZMODEM vs XMODEM vs YMODEM:三者的优劣比较分析及选型建议

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM、XMODEM与YMODEM协议概述
在现代数据通
ARINC664协议的可靠性与安全性:详细案例分析与实战应用

参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. ARINC664协议概述
ARINC664协议,作为一种在航空电子系统中广泛应用的数据通信标准,已经成为现代飞机通信网络的核心技术之一。它不仅确保了
HEC-GeoHMS在洪水风险评估中的应用实战:案例分析与操作技巧

参考资源链接:[HEC-GeoHMS操作详析:ArcGIS准备至流域处理全流程](https://wenku.csdn.net/doc/4o9gso36xa?spm=1055.2635.3001.10343)
# 1. HEC-GeoHMS概述与洪水风险评估基础
## 1.1 HEC-GeoHMS简介
HEC-GeoHMS是一个强大的GIS工具,用于洪水风险评估和洪水模型的前期准备工作。它是HEC-HMS(Hydro
MIPI CSI-2信号传输精髓:时序图分析专家指南
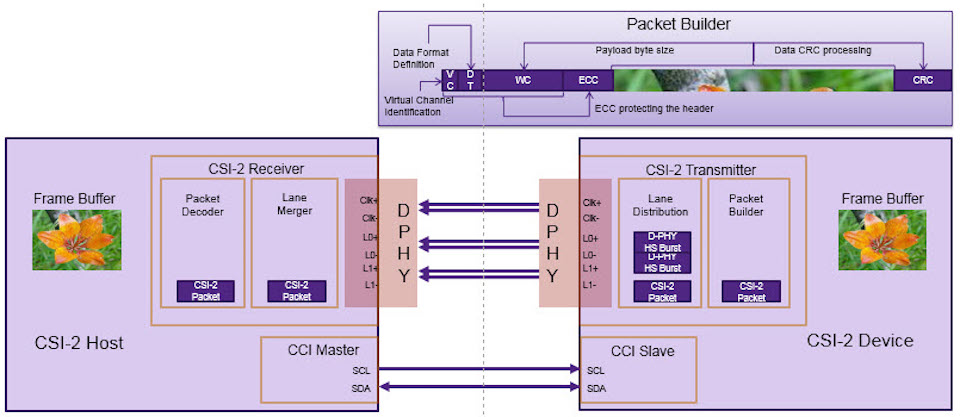
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2信号传输基础
MIPI CSI-2 (Mobile Industry Processor
【系统维护】创维E900 4K机顶盒:更新备份全攻略,保持最佳状态

参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
## 简介
创维E900 4K机顶盒是一款集成了最新技术的家用多媒体设备,支持4K超高清视频播放和多
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )