Python讯飞星火LLM算法探秘:5步吃透底层工作原理
发布时间: 2024-11-15 10:14:06 阅读量: 23 订阅数: 29 

实现SAR回波的BAQ压缩功能

# 1. Python讯飞星火LLM算法概览
## 简介
Python作为一门广受欢迎的编程语言,在人工智能领域尤其是自然语言处理(NLP)方面有着广泛的应用。讯飞星火LLM(Xunfei Spark LLM)是科大讯飞推出的一款以大规模语言模型为基础的人工智能算法,专门针对中文语境下的文本理解和生成进行了优化。在本章中,我们将概览Python讯飞星火LLM算法的核心特性和应用场景。
## Python讯飞星火LLM的特点
讯飞星火LLM算法以其强大的中文处理能力著称,它结合了深度学习技术和大量的中文语料库,能够实现高度智能化的文本分析和生成。该算法的特点包括但不限于:
- 高效的中文分词和词性标注
- 自然的文本生成和摘要能力
- 对话管理和情感分析功能
## 应用场景
Python讯飞星火LLM算法广泛应用于多种业务场景中,如智能客服、自动文本摘要、机器翻译、情感分析、内容推荐等。通过利用该算法,开发者可以快速构建起与用户交互的人工智能应用,从而提升产品体验和服务效率。
本章为读者提供了一个对讯飞星火LLM算法整体认知的起点,接下来的章节将深入探讨该算法的理论基础、架构解析、实践应用以及进阶技巧。通过逐步学习,我们旨在帮助读者全面掌握Python讯飞星火LLM算法,并能够将其应用到实际项目中。
# 2. 理解讯飞星火LLM算法的理论基础
## 2.1 语言模型与LLM算法简介
### 2.1.1 语言模型的概念和重要性
在自然语言处理(NLP)领域,语言模型是一类极其重要的技术,它是NLP任务的基础,负责预测一段文本序列中下一个词出现的概率。通过学习大量文本数据,语言模型可以捕捉到语言的统计规律,从而对句子是否自然、语法是否正确、内容是否相关给出概率上的评估。语言模型的发展经历了从简单到复杂的各个阶段,从最初的n-gram模型到现在的深度学习语言模型如BERT、GPT等,技术进步极大地推动了NLP领域的发展。
语言模型的重要性可以从以下几个方面来理解:
- **文本生成**:语言模型能够基于前文生成符合语境的后续文本,广泛应用于聊天机器人、自动写作等领域。
- **语音识别**:在语音识别系统中,语言模型用于提供上下文信息,帮助系统更准确地识别和转录用户的话语。
- **机器翻译**:通过语言模型,机器翻译系统可以生成更加流畅、符合目标语言习惯的翻译结果。
### 2.1.2 LLM算法的工作原理及特点
LLM(Large Language Models)算法通常指的是一类基于大规模数据训练的深度学习语言模型,它们具有数亿到数百亿的参数。这些模型通过处理海量的文本数据,学习语言的复杂模式和关系。在处理任务时,LLM能够生成连贯、语义丰富且语法正确的文本。
LLM算法的特点主要表现在以下几个方面:
- **深度学习架构**:基于深度神经网络,特别是Transformer架构,能够捕捉长距离的依赖关系。
- **大规模训练数据**:需要大量的文本数据进行训练,以覆盖语言的多样性和复杂性。
- **上下文理解能力**:相比传统模型,LLM能够更好地理解上下文信息,提供更准确的预测。
## 2.2 讯飞星火平台的架构解析
### 2.2.1 星火平台的架构布局
讯飞星火平台是一个集成了多种自然语言处理功能的云端服务平台。它通过模块化的设计,允许用户根据需求选择相应的服务组件。平台的整体架构布局通常包括以下几个核心部分:
- **数据层**:负责存储和管理训练数据、用户数据和模型数据。
- **模型训练与服务层**:包括模型训练引擎、模型服务接口和模型版本管理。
- **用户界面**:提供用户交互界面,方便用户操作和使用平台服务。
- **安全与权限控制**:确保数据和模型的安全性,以及用户权限的合理分配。
### 2.2.2 平台中LLM算法的角色与功能
在讯飞星火平台中,LLM算法扮演着核心角色,它为各种NLP任务提供了强大的技术支持。LLM算法在平台中主要承担以下功能:
- **自然语言理解**:LLM算法能够理解复杂的语义信息,并将其转化为可操作的数据形式。
- **文本生成**:利用生成模型的能力,为用户提供高质量的文本生成服务,如自动撰写文章、摘要生成等。
- **语义搜索**:整合文本内容的深层语义,提供精准的信息检索和内容推荐服务。
## 2.3 理解NLP中的Transformer模型
### 2.3.1 Transformer模型的核心组成
Transformer模型是在2017年由Vaswani等人提出的一种全新的深度学习架构,它采用自注意力(Self-Attention)机制处理序列数据。模型的核心组成如下:
- **自注意力机制**:允许模型在序列处理中,同时考虑序列中的所有位置,并为每个位置分配不同的权重。
- **多头注意力**:将自注意力机制扩展到多个“头”,以便模型从不同的子空间捕获信息。
- **位置编码**:由于Transformer不使用循环神经网络结构,需要通过位置编码来提供序列中单词的位置信息。
- **前馈神经网络**:在自注意力机制后,模型通常会有一个前馈神经网络层进行非线性变换。
Transformer模型通过堆叠多个自注意力和前馈神经网络层,形成一个强大的深度学习架构,能够处理复杂的NLP任务。
### 2.3.2 Transformer在LLM中的应用分析
LLM算法中广泛应用了Transformer架构,因为它能够有效地处理长距离依赖问题,并且在大规模数据集上进行训练时表现出色。在LLM中,Transformer的应用分析主要体现在以下几个方面:
- **并行化处理**:Transformer的自注意力机制允许对整个序列进行并行化处理,大幅提高了训练效率。
- **学习效率**:相比传统RNN和LSTM模型,Transformer在处理长序列时学习效率更高,能够更快地收敛。
- **模型泛化能力**:由于Transformer能够捕获序列中复杂的依赖关系,因此在多种NLP任务中具有更好的泛化能力。
Transformer模型的这些特点使它成为了构建现代大型语言模型的基石,特别是在讯飞星火LLM算法中扮演了至关重要的角色。
# 3. ```
# 第三章:讯飞星火LLM算法的实践应用
在本章节中,我们将深入探讨讯飞星火LLM算法在实际中的应用,并通过实战案例揭示其在文本生成任务中的强大能力。此外,我们将重点关注如何构建一个简单的语言模型,优化调整LLM模型性能,并分析如何通过讯飞星火LLM实现高效的文本生成。
## 3.1 构建一个简单的语言模型
### 3.1.1 准备数据集和预处理步骤
在构建语言模型之前,我们需要准备一个适合的语料库。这个语料库通常包含大量的文本数据,这些数据可以来自于公开的语料库,如Wikipedia、新闻文章、书籍等,也可以是特定领域内的文本集合。选择合适的数据集对于构建一个鲁棒的语言模型至关重要。
**数据预处理步骤** 是模型构建过程中的重要一环。它包括文本清洗、分词、去除停用词、词性标注、构建词汇表等步骤。文本清洗会移除不需要的符号、非文本内容等。分词是将文本切分为独立的单词或词素,这对于中文而言尤为重要。去除停用词(如“的”、“是”、“在”等)可以减少模型处理的噪声。词性标注有助于理解单词在句子中的功能和意义,而构建词汇表则是为了统一模型中使用的词汇。
### 3.1.2 训练语言模型的Python实现
以下是使用Python和TensorFlow来训练一个简单的语言模型的基本步骤:
```python
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# 假设我们已经有了预处理后的语料库文本
corpus = [...]
# 设置词汇表大小
vocab_size = 10000
# 设置每个句子的最大长度
max_length = 100
# 设置嵌入向量的维度
embedding_dim = 64
# 使用Tokenizer构建词汇表并进行分词
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_se

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python讯飞星火LLM教程”专栏!本专栏为您提供全面的指南,帮助您掌握讯飞星火LLM的强大功能。通过一系列详细的文章,您将学习如何:
- 优化模型以提高准确性和效率
- 管理模型版本,实现高效的迭代和维护
- 访问最新学习资料和工具,不断提升技能
- 快速解决常见问题,确保模型的顺畅运行
无论您是初学者还是经验丰富的开发者,本专栏都将为您提供宝贵的见解和实用技巧。通过遵循我们的循序渐进的指南,您将能够充分利用讯飞星火LLM,创建出色的自然语言处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RTCM 3.3协议的10大秘密】:精通实时定位技术的终极指南

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议概述
RTCM 3.3是实时差分全球定位系统(GNSS
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
升级你的IS903:固件更新全攻略,提升性能与稳定性的终极指南

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. IS903固件更新的必要性和好处
## 理解固件更新的重要性
固件更新,对于任何智能设备来说,都是一个关键的维护步骤。IS903作为一款高性能的设备,其固件更新不仅仅是为了修
ROST软件高级用户必看:全面掌握工具每一个细节的独家技巧
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
# 1. ROST软件概述与安装指南
## ROST
【cx_Oracle权威指南】:版本升级、环境配置与最佳实践案例解析

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle简介与历史回顾
cx_Oracle 是一个流行的 Python 扩展,用于访问 Oracle 数据库。它提供了一个接口,允许 Python 程序
ZMODEM vs XMODEM vs YMODEM:三者的优劣比较分析及选型建议

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM、XMODEM与YMODEM协议概述
在现代数据通
ARINC664协议的可靠性与安全性:详细案例分析与实战应用

参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. ARINC664协议概述
ARINC664协议,作为一种在航空电子系统中广泛应用的数据通信标准,已经成为现代飞机通信网络的核心技术之一。它不仅确保了
HEC-GeoHMS在洪水风险评估中的应用实战:案例分析与操作技巧

参考资源链接:[HEC-GeoHMS操作详析:ArcGIS准备至流域处理全流程](https://wenku.csdn.net/doc/4o9gso36xa?spm=1055.2635.3001.10343)
# 1. HEC-GeoHMS概述与洪水风险评估基础
## 1.1 HEC-GeoHMS简介
HEC-GeoHMS是一个强大的GIS工具,用于洪水风险评估和洪水模型的前期准备工作。它是HEC-HMS(Hydro
MIPI CSI-2信号传输精髓:时序图分析专家指南
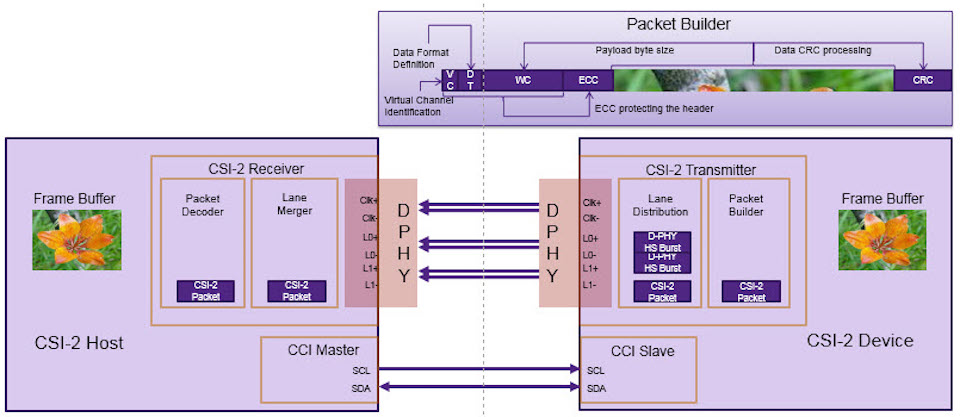
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2信号传输基础
MIPI CSI-2 (Mobile Industry Processor
【系统维护】创维E900 4K机顶盒:更新备份全攻略,保持最佳状态

参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
## 简介
创维E900 4K机顶盒是一款集成了最新技术的家用多媒体设备,支持4K超高清视频播放和多
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )