【Python讯飞星火LLM应用开发】:构建智能应用的10大秘诀
发布时间: 2024-11-15 10:28:15 阅读量: 64 订阅数: 29 

Python调用讯飞星火LLM教程2(共2)

# 1. 讯飞星火LLM概述及其在Python中的应用
## 1.1 讯飞星火LLM简介
讯飞星火LLM是由科大讯飞推出的先进大型语言模型,旨在提供智能交互、内容生成和语言理解等服务。科大讯飞作为中国领先的智能语音技术提供商,其产品已在多个行业获得广泛应用。
## 1.2 讯飞星火LLM在Python中的应用
Python开发者可以在多种场景下借助讯飞星火LLM的强大功能,例如自动化文本分析、智能语音交互、用户对话管理等。Python的易用性和丰富库资源使其成为开发讯飞星火LLM应用的理想选择。
## 1.3 初识讯飞星火LLM的Python接入
要开始使用讯飞星火LLM,开发者首先需要注册讯飞开放平台账号,并创建应用以获取API密钥。完成这些准备工作后,通过安装Python SDK即可快速接入讯飞星火LLM服务,并开始API调用与应用开发。
接下来的内容,我们将进一步深入探讨讯飞星火LLM的架构原理、技术优势以及如何在Python中实现各种功能。
# 2. 讯飞星火LLM理论基础
## 2.1 讯飞星火LLM的架构原理
### 2.1.1 模型的组成与工作流程
讯飞星火LLM(Large Language Model)是基于深度学习技术构建的自然语言处理模型,其结构主要由编码器和解码器组成,编码器负责理解输入的自然语言文本,解码器则负责生成输出的文本。
**模型工作流程:**
1. 输入文本经过预处理后被送入编码器。
2. 编码器通过多层神经网络处理,将文本信息编码为稠密的向量表示。
3. 解码器接收这个向量表示,并逐步生成输出文本。
4. 输出文本同样经过后处理,以确保符合语境和语法规范。
为了更好地理解这一工作流程,可以参考以下简化的代码块展示模型的运行逻辑:
```python
import torch
from transformers import EncoderDecoderModel
# 实例化模型,这里使用了transformers库中的EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained(
'pretrained_encoder_model', 'pretrained_decoder_model')
# 输入文本预处理
input_ids = tokenizer.encode("讯飞星火LLM的架构原理", return_tensors='pt')
# 模型编码与解码
outputs = model.generate(input_ids)
# 输出文本后处理
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
```
**参数说明:**
- `pretrained_encoder_model` 和 `pretrained_decoder_model` 分别是预训练好的编码器和解码器模型名称。
- `tokenizer` 是用于文本处理的分词器。
- `input_ids` 是对输入文本进行编码后的张量表示。
在这一流程中,编码器和解码器都是通过深度学习网络架构,如Transformer,实现的。这种架构能够有效地处理长距离依赖,捕捉文本中的复杂模式和关联。
### 2.1.2 自然语言处理基础
讯飞星火LLM的自然语言处理(NLP)基础涵盖了语言理解、文本表示、生成等关键领域。这需要模型具备以下能力:
- **词嵌入(Word Embedding):**将词汇映射到一个稠密的向量空间中,通过这种方式捕捉词汇之间的语义关系。
- **序列处理:**通过循环神经网络(RNN)或者自注意力机制(如Transformer),模型可以处理序列数据,理解句子的上下文和结构。
- **语义理解:**使用预训练模型进行微调,模型能够理解复杂的语言概念和隐含意义。
- **文本生成:**基于理解的上下文,模型能够生成连贯、自然的文本。
#### 表格:自然语言处理技术对比
| 技术名称 | 适用场景 | 优势 | 劣势 |
| --- | --- | --- | --- |
| RNN | 序列数据建模 | 能够处理不同长度的输入序列 | 易受长期依赖影响 |
| LSTM | 解决RNN的长期依赖问题 | 更好的长期记忆能力 | 结构复杂,计算资源要求高 |
| Transformer | 并行处理能力 | 高效处理长距离依赖问题 | 需要大量数据进行预训练 |
| BERT | 深层语义理解 | 预训练后的模型微调简单 | 对显存和计算资源要求较高 |
通过这些技术,讯飞星火LLM能够有效执行复杂的语言任务,从文本分类到复杂对话系统。
## 2.2 讯飞星火LLM的技术优势
### 2.2.1 与其他LLMs的对比分析
讯飞星火LLM在多个方面与其他大型语言模型(如GPT、BERT等)进行对比分析,凸显其独特优势。其主要技术优势包括:
- **效率:**讯飞星火LLM具有高度优化的算法和数据处理能力,能够以更低的计算成本实现高效的模型训练和推理。
- **准确性:**通过在特定行业数据集上的预训练和微调,讯飞星火LLM在专业领域文本理解上拥有较高的准确性。
- **模型大小与性能平衡:**讯飞星火LLM针对特定应用场景进行了优化,能够用较小的模型大小达到较高的性能。
### 2.2.2 企业应用案例研究
在企业应用案例中,讯飞星火LLM的表现尤为突出。以下是几个实际应用场景的分析:
#### 智能客服系统
- **任务:**通过讯飞星火LLM处理客户咨询,实现24/7不间断服务。
- **实现:**借助预训练模型处理常见问题,对模型进行微调以适应特定的业务需求。
- **结果:**提供快速响应,客户满意度提升,人工客服压力降低。
#### 内容审核
- **任务:**自动识别并过滤掉不合规内容。
- **实现:**通过训练模型识别违规词汇和内容模式,进行内容审核。
- **结果:**提高了审核效率,降低了人工成本。
#### 自动翻译
- **任务:**实现多语言实时翻译服务。
- **实现:**利用讯飞星火LLM进行语料翻译和模型微调,输出高质量翻译结果。
- **结果:**支持多语言交流,提高国际业务的沟通效率。
## 2.3 接入讯飞星火LLM的准备工作
### 2.3.1 注册开发者账号与获取API密钥
为了接入讯飞星火LLM,首先需要注册为讯飞开放平台的开发者,并创建一个应用来获取相应的API密钥。
- 访问讯飞开放平台官网。
- 注册账号并登录。
- 创建一个应用,并填写应用的相关信息,如应用名称、描述等。
- 提交审核后,一旦应用审核通过,就可以在应用详情中找到API密钥。
### 2.3.2 环境搭建与Python包安装指南
成功获取API密钥后,接下来就是环境搭建和安装Python开发包。
#### 环境搭建
1. 安装Python环境,推荐使用最新版本的Python。
2. 使用`pip`安装虚拟环境管理工具,如`virtualenv`。
3. 创建并激活虚拟环境。
```bash
# 安装virtualenv
pip install virtualenv
# 创建虚拟环境
virtualenv venv
# 激活虚拟环境
# Windows环境下使用
venv\Scripts\activate
# macOS/Linux环境下使用
source venv/bin/activate
```
#### 安装Python包
1. 安装讯飞API的Python SDK。
2. 安装其他开发所需依赖库,如`requests`等。
```bash
# 安装讯飞API SDK
pip install iflytek-python-sdk
# 安装requests库
pip install requests
```
接下来,可以通过Python代码示例来验证环境和API密钥是否配置成功。
```python
from iflytek import IflytekApi
# 设置API密钥和应用ID
app_id = 'your_app_id'
api_key = 'your_api_key'
# 实例化API客户端
client = IflytekApi(app_id, api_key)
# 测试API调用
response = client.call('FunctionName', {'key1': 'value1'})
print(response)
```
在执行上述代码前,确保将`your_app_id`和`your_api_key`替换为从讯飞开放平台获取的实际值。如果返回值表示API调用成功,则说明环境搭建和安装均已完成。
本章节涵盖了讯飞星火LLM的基础理论知识,包括模型架构、技术优势和接入准备工作。通过这些内容,读者将对讯飞星火LLM有一个全面的基础了解,并为后续的实践开发和应用优化奠定坚实的理论基础。
# 3. Python中的讯飞星火LLM实践开发
## 3.1 基本功能的开发实践
### 3.1.1 文本分析与理解
在讯飞星火LLM中,文本分析与理解是构建各种应用的基础。开发者可以利用模型提供的API进行文本分类、情感分析、实体识别等任务。下面的代码示例展示了如何使用讯飞星火LLM API进行文本分类:
```python
import requests
# 假设已经获得了API密钥
api_key = 'your_api_key'
url = "***"
headers = {
"Content-Type": "application/json",
"API-Key": api_key
}
data = {
"app_id": "your_app_id",
"text": "我期待明天的天气",
"type": 1
}
response = requests.post(url, json=data, headers=headers)
print(response.text)
```
此段代码首先导入了Python中的`requests`库,用于发送HTTP请求。在请求中,需要提供API密钥、应用ID和要分类的文本。服务器响应后,开发者可以解析响应的JSON对象,获取分类结果。
文本分类的参数`type`在这里设置为1,它指示了API使用特定的分类模型,比如可以设置为2代表另一个分类模型。根据实际需求选择不同的分类模型。
### 3.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python讯飞星火LLM教程”专栏!本专栏为您提供全面的指南,帮助您掌握讯飞星火LLM的强大功能。通过一系列详细的文章,您将学习如何:
- 优化模型以提高准确性和效率
- 管理模型版本,实现高效的迭代和维护
- 访问最新学习资料和工具,不断提升技能
- 快速解决常见问题,确保模型的顺畅运行
无论您是初学者还是经验丰富的开发者,本专栏都将为您提供宝贵的见解和实用技巧。通过遵循我们的循序渐进的指南,您将能够充分利用讯飞星火LLM,创建出色的自然语言处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ROST软件数据可视化技巧:让你的分析结果更加直观动人
:max_bytes(150000):strip_icc()/ScreenShot2019-10-28at1.25.36PM-ab811841a30d4ee5abb2ff63fd001a3b.jpg)
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
RTCM 3.3协议深度剖析:如何构建秒级精准定位系统

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介及其在精准定位中的作用
RTCM (Radio Technical Co
提升航空数据传输效率:AFDX网络数据流管理技巧
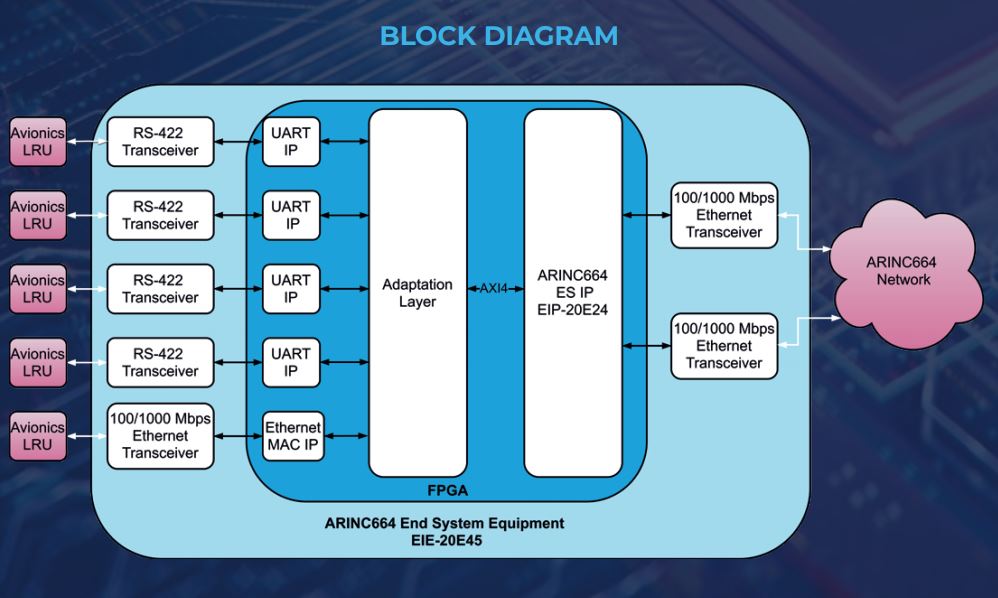
参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. AFDX网络技术概述
## 1.1 AFDX网络技术的起源与应用背景
AFDX (Avionics Full-Duplex Switched Ethernet) 网络技术,是专为航空电子通信设计
软件开发者必读:与MIPI CSI-2对话的驱动开发策略
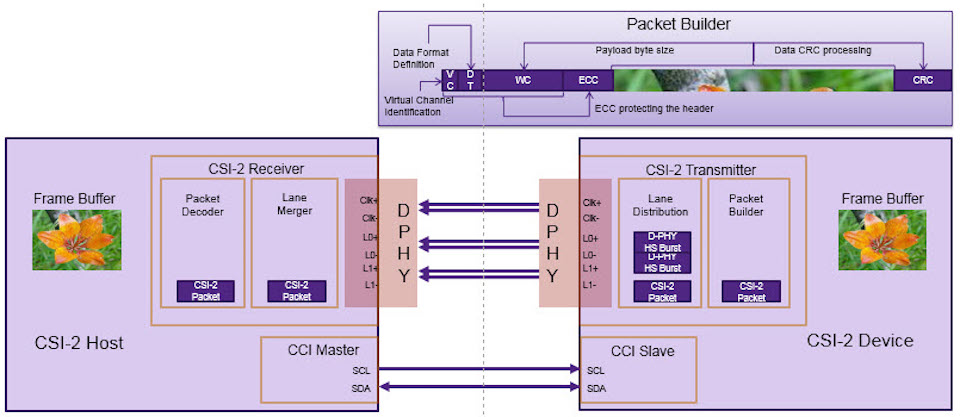
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2协议概述
在当今数字化和移动化的世界里,移动设备图像性能的提升是用户体验的关键部分。为
【PCIe接口新革命】:5.40a版本数据手册揭秘,加速硬件兼容性分析与系统集成
参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/doc/3rfmuard3w?spm=1055.2635.3001.10343)
# 1. PCIe接口技术概述
PCIe( Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,被广泛应用于计算机内部连接高速组件。它以点对点连接的方式,能够提供比传统PCI(Peripheral Component Interconnect)总线更高的数据传输率。PCIe的进
ZMODEM协议的高级特性:流控制与错误校正机制的精妙之处

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM协议简介
## 1.1 什么是ZMODEM协议
ZMODEM是一种在串行通信中广泛使用的文件传输协议,它支持二进制数据传输,并可以对数据进行分块处理,确保文件完整无误地传输到目标系统。与早期的XMODEM和YMODEM协
IS903优盘通信协议揭秘:USB通信流程的全面解读

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. USB通信协议概述
USB(通用串行总线)通信协议自从1996年首次推出以来,已经成为个人计算机和其他电子设备中最普遍的接口技术之一。该章节将概述USB通信协议的基础知识,为后续章节深入探讨USB的硬件结构、信号传输和通信流程等主题打
【功能拓展】创维E900 4K机顶盒应用管理:轻松安装与管理指南
参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
在本章中,我们将揭开创维E900 4K机顶盒的神秘面纱,带领读者了解这一强大的多媒体设备的基本信息。我们将从其设计理念讲起,探索它如何为家庭娱乐带来高清画质和智能功能。本章节将为读者提供一个全面的概览,包括硬件配置、操作系统以及它在市场中的定位,为后续章节中关于设置、应用使用和维护等更深入的讨论打下坚实的基础。
创维E900 4K机顶盒采用先
【cx_Oracle数据库管理】:全面覆盖连接、事务、性能与安全性

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle数据库基础介绍
cx_Oracle 是一个
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )