Kubernetes基础概念与架构解析
发布时间: 2024-02-25 21:54:10 阅读量: 32 订阅数: 21 

Kubernetes概念总结
# 1. Kubernetes简介
Kubernetes是当下流行的容器编排管理平台之一,它的出现极大地改变和优化了传统的部署方式和架构设计。本章将介绍Kubernetes的基本概念和架构,帮助读者更好地了解这一领先的技术。
#### 1.1 Kubernetes的历史和背景
Kubernetes最初由Google开发,是一个开源的容器编排引擎,于2014年首次发布。它源自Google内部的Borg系统和Omega系统,经过多年的实践和经验沉淀,逐渐演变成为Kubernetes。作为一种高效、可扩展和灵活的容器编排解决方案,Kubernetes在云原生应用开发和部署中扮演着重要的角色。
#### 1.2 Kubernetes的重要性和作用
Kubernetes可以帮助开发人员和运维团队更好地管理容器化的应用,实现自动化部署、扩展、更新和监控。通过Kubernetes,用户可以轻松地构建复杂的应用程序,并在不同的环境中(公有云、私有云或混合云)进行部署和管理,提高开发效率和系统稳定性。
#### 1.3 Kubernetes与传统架构的区别
传统的应用部署通常基于虚拟机或物理机,通过手动安装和配置来进行管理。而Kubernetes提倡基于容器的部署方式,将应用程序和其依赖项封装在一个独立的容器中,实现了更高的隔离性和可移植性。此外,Kubernetes通过自动化和集中化的管理,简化了应用的部署和维护流程,为云原生时代的应用开发提供了更加灵活和高效的解决方案。
通过本章介绍,读者可以对Kubernetes的起源、重要性以及与传统架构的区别有一个初步的了解。在接下来的章节中,我们将进一步探讨Kubernetes的基础概念、核心组件以及架构设计,帮助读者全面深入地学习和理解这一先进的容器编排技术。
# 2. Kubernetes基础概念
Kubernetes作为一个开源的容器编排引擎,其基础概念对于理解整个系统的运作原理至关重要。本章将介绍Kubernetes的基础概念,包括容器与Kubernetes的关系,Pod的概念与设计,以及Service和Ingress的作用与区别。让我们一起来深入了解Kubernetes的基础知识。
#### 2.1 容器与Kubernetes
在介绍Kubernetes之前,我们先来了解一下容器。容器是一种轻量级、可移植、自包含的软件打包形式,具有跨平台、快速部署的特点。Docker是目前最为流行的容器化技术之一,它可以帮助开发者打包应用程序及其依赖项到一个可移植的容器中,然后发布到任意Linux服务器上。Kubernetes与Docker等容器技术是相辅相成的关系,Kubernetes利用容器技术来部署、运行和管理应用程序。
Kubernetes利用容器技术解决了传统部署和管理应用程序所遇到的许多挑战,包括应用程序间的依赖冲突、环境一致性、部署效率等问题。通过Kubernetes,我们可以轻松地管理成百上千个容器化的应用程序实例,实现自动化部署、扩展、以及容错等功能。
```python
# 示例代码:使用Kubernetes API创建一个Pod对象
from kubernetes import client, config
# 从默认配置文件加载Kubernetes集群信息
config.load_kube_config()
# 创建一个Pod的配置对象
pod = client.V1Pod()
pod.metadata = client.V1ObjectMeta(name="my-pod")
pod.spec = client.V1PodSpec(containers=[client.V1Container(name="my-container", image="nginx")])
# 在集群中创建该Pod
v1 = client.CoreV1Api()
v1.create_namespaced_pod(body=pod, namespace="default")
```
**代码说明:**
以上代码使用Python的`kubernetes`库通过Kubernetes API创建了一个Pod对象,指定了Pod的名称为`my-pod`,并且在其中运行一个使用`nginx`镜像的容器。这样的代码可以帮助开发者快速创建和管理Kubernetes资源。
**代码总结:**
通过Kubernetes API,开发者可以编写程序动态地管理Kubernetes中的各种资源,包括Pod、Service、Deployment等,为应用程序的自动化部署和运维提供了可能。
#### 2.2 Pod的概念与设计
Pod是Kubernetes中最小的调度和管理单元,它是一个自包含的环境,可以包含一个或多个紧密关联的容器。Pod中的容器共享网络、存储等资源,并且常常一起协同工作来组成一个完整的应用程序。通常情况下,一个Pod中运行的是一组共享生命周期的容器,它们共享相同的IP地址和端口范围。
Pod的设计思想源自于容器编排系统中的需求:相互关联的容器需要共享存储和网络,并且需要一起部署和调度。Pod提供了一种抽象层,解决了容器之间共享资源的问题,为开发者提供了更加灵活和强大的编排能力。
```java
// 示例代码:使用Java客户端创建一个Pod对象
import io.kubernetes.client.openapi.*;
import io.kubernetes.client.openapi.models.*;
// 创建一个Pod的配置对象
V1Pod pod = new V1PodBuilder()
.withNewMetadata().withName("my-pod").endMetadata()
.withNewSpec()
.addNewContainer()
.withName("my-container")
.withImage("nginx")
.endContainer()
.endSpec()
.build();
// 在集群中创建该Pod
CoreV1Api api = new CoreV1Api();
api.createNamespacedPod("default", pod, null, null, null);
```
**代码说明:**
以上代码使用Java的`kubernetes-client`库创建了一个Pod对象,并在集群中将其部署在默认命名空间中。通过Java客户端的调用,开发者可以方便地管理Kubernetes中的各种资源对象。
**结果说明:**
经过上述操作,Kubernetes集群中将会创建一个名为`my-pod`的Pod,并且其中运行一个使用`nginx`镜像的容器。
#### 2.3 Service和Ingress的作用与区别
在Kubernetes中,Service和Ingress是用于解决服务发现和网络路由的重要组件。Service负责为一组Pod提供统一的访问入口,并支持负载均衡、健康检查等功能;而Ingress则是暴露HTTP和HTTPS路由到集群中的服务。
Service和Ingress的主要区别在于作用范围不同,Service负责内部服务发现和负载均衡,而Ingress负责从集群外部暴露服务。在实际应用中,通常会同时使用Service和Ingress来完成对外部和内部服务的管理和路由。
```javascript
// 示例代码:使用JavaScript创建一个Ingress对象
const k8s = require('@kubernetes/client-node');
// 通过Kubernetes REST API创建一个Ingress对象
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.ExtensionsV1beta1Api);
const ingress = {
apiVersion: 'networking.k8s.io/v1beta1',
kind: 'Ingress',
metadata: {
name: 'my-ingress',
annotations: {
'nginx.ingress.kubernetes.io/rewrite-target': '/'
}
},
spec: {
rules: [
{
host: 'example.com',
http: {
paths: [
{
path: '/',
backend: {
serviceName: 'my-service',
servicePort: 80
}
}
]
}
}
]
}
};
k8sApi.createNamespacedIngress('default', ingress, null, null, null);
```
**代码说明:**
以上JavaScript示例代码通过`@kubernetes/client-node`库使用Kubernetes REST API创建了一个Ingress对象,将`example.com`的HTTP请求路由到名为`my-service`的Service上的端口80。这样的代码可以帮助开发者快速创建和配置Kubernetes中的Ingress路由规则。
通过本章的介绍,我们对Kubernetes的基础概念有了更深入的了解,包括容器与Kubernetes的关系,Pod的概念与设计,以及Service和Ingress的作用与区别。这些概念对于后续深入学习和使用Kubernetes非常重要。
# 3. Kubernetes核心组件
Kubernetes作为一个容器编排和管理平台,包含了多个核心组件,它们共同协作,实现了Kubernetes的强大功能。在本章中,我们将重点介绍Kubernetes的核心组件,包括它们的功能、作用以及配置方式。
#### 3.1 控制平面组件的功能与作用
Kubernetes的控制平面由多个组件组成,它们共同协作,负责集群的管理和控制。下面我们将逐个介绍这些控制平面组件的功能与作用:
- **kube-apiserver**:作为Kubernetes集群的统一入口,所有的资源操作都通过kube-apiserver进行,包括创建、更新、删除等操作。它还负责对外提供RESTful API接口,用于与集群交互。
- **kube-scheduler**:负责Pod的调度工作,根据预设的调度策略,将Pod分配到集群中的具体Node节点上。它考虑了诸如资源需求、硬件特性、数据局部性等因素,实现最优的Pod调度方案。
- **kube-controller-manager**:包含多个控制器(如Replication Controller、Node Controller等),负责监控集群状态,并根据期望状态与实际状态的差异进行调节,确保集群中的各个资源处于预期状态。
- **cloud-controller-manager**:在云平台上运行Kubernetes时,用于管理云基础设施相关的控制器,如处理云服务提供商的API调用、云资源的生命周期管理等。
#### 3.2 网络组件的选择与配置
Kubernetes中的网络组件负责实现Pod间通信、跨节点通信等网络功能,不同的网络组件方案对于集群性能、安全性、扩展性等方面有着不同的影响。常用的网络组件包括Flannel、Calico、Weave等,它们各自有着不同的特点和适用场景。
在选择和配置网络组件时,需要考虑集群规模、网络性能要求、安全策略等因素,合理选择网络方案,并进行相应的配置和优化。
#### 3.3 存储组件的作用与集成方式
Kubernetes中的存储组件负责为Pod提供持久化存储支持,常见的存储解决方案包括NFS、Ceph、GlusterFS等,它们可以提供不同的存储类型和访问方式,满足不同应用场景的需求。
在Kubernetes中集成存储解决方案时,需要考虑存储的可靠性、性能、访问控制等方面的要求,选择合适的存储方案,并进行正确的集成配置,以实现对应用程序持久化数据存储的支持。
以上是关于Kubernetes核心组件的介绍,每个组件都扮演着至关重要的角色,它们共同构成了Kubernetes强大的基础设施,为容器化应用的部署与管理提供了坚实的支撑。
# 4. Kubernetes架构解析
在本章中,我们将深入探讨Kubernetes的核心架构,并解析Master节点、Worker节点以及ETCD集群的角色和功能。
## 4.1 Master节点的角色和功能
Kubernetes的Master节点是集群的控制中心,负责管理集群的整体运行和调度。Master节点包含多个关键组件,主要包括以下几个部分:
### 4.1.1 API Server
API Server是Kubernetes集群的统一入口,所有的操作和控制命令都通过API Server进行处理和响应。它负责集群状态的维护和管理,是集群中的核心组件之一。
```python
# 示例代码
# 通过kubectl命令访问API Server
kubectl get pods
```
**代码解释:** 以上代码演示了通过kubectl命令访问API Server,获取集群中所有的Pod信息。
**代码总结:** API Server作为Kubernetes集群的统一入口,承担着非常重要的职责,是集群中的核心组件之一。
**结果说明:** 通过kubectl命令获取的Pod信息将通过API Server进行处理和响应。
### 4.1.2 Controller Manager
Controller Manager负责控制器的管理和维护,它包含多个控制器,用于确保集群中各种资源对象的规范状态。常见的控制器包括ReplicaSet Controller、Deployment Controller等。
```java
// 示例代码
// 查看Controller Manager状态
kubectl get cs
```
**代码解释:** 以上代码演示了通过kubectl命令查看Controller Manager的状态,以确保控制器的正常运行。
**代码总结:** Controller Manager负责管理和维护多个控制器,确保集群中各种资源对象的规范状态。
**结果说明:** 通过kubectl命令可以查看Controller Manager的状态,以便及时发现和处理异常情况。
### 4.1.3 Scheduler
Scheduler负责对集群中的新创建的Pod进行调度和分配工作节点。它根据集群的资源情况和调度策略,将Pod分配到最合适的工作节点上运行。
```go
// 示例代码
// 手动触发Scheduler进行调度
kubectl create -f pod-definition.yaml
```
**代码解释:** 以上代码演示了通过创建Pod定义文件并使用kubectl命令手动触发Scheduler进行调度过程。
**代码总结:** Scheduler根据集群资源情况和调度策略,将新创建的Pod分配到最合适的节点上运行。
**结果说明:** 手动创建Pod并触发Scheduler进行调度后,可通过kubectl命令查看Pod所在节点,以确认调度结果。
## 4.2 Worker节点的角色和功能
Worker节点是Kubernetes集群中负载运行容器的节点,它接收Master节点下发的任务,在本地节点上创建和运行相应的Pod,并定期向Master节点报告节点的状态。
### 4.2.1 Kubelet
Kubelet是运行在每个Worker节点上的代理,负责与Master节点通信,并管理本节点上的Pod和容器。它定期向API Server报告节点状态,并执行由API Server下发的任务。
```javascript
// 示例代码
// 查看Kubelet状态
kubectl get nodes
```
**代码解释:** 以上代码演示了通过kubectl命令查看Kubelet的状态,以确认节点的正常运行情况。
**代码总结:** Kubelet负责与Master节点通信,管理本节点上的Pod和容器,并定期向API Server报告节点状态。
**结果说明:** 通过kubectl命令可以查看Kubelet的状态,以便及时发现节点的异常情况。
### 4.2.2 Kube Proxy
Kube Proxy负责维护每个节点上的网络规则和转发机制,确保集群内部和外部的网络通信正常进行。它支持服务发现和负载均衡等功能。
```java
// 示例代码
// 查看Kube Proxy配置
kubectl get svc --all-namespaces
```
**代码解释:** 以上代码演示了通过kubectl命令查看Kube Proxy的配置,以确保网络规则和转发机制的正常运行。
**代码总结:** Kube Proxy负责维护节点上的网络规则和转发机制,保障集群内外的网络通信正常进行。
**结果说明:** 通过kubectl命令可以查看Kube Proxy的配置,以确认网络规则和转发机制的状态。
### 4.2.3 Container Runtime
Container Runtime负责在节点上运行容器,常见的容器运行时包括Docker、containerd等。它管理容器的生命周期,包括创建、运行、销毁等操作。
```go
// 示例代码
// 查看节点上运行的容器
docker ps
```
**代码解释:** 以上代码演示了通过docker命令查看节点上当前运行的容器情况。
**代码总结:** Container Runtime负责在节点上管理容器的生命周期,包括创建、运行、销毁等操作。
**结果说明:** 通过docker命令可以查看节点上当前运行的容器情况,以确认容器运行时的状态。
## 4.3 ETCD集群的重要性和作用
ETCD是Kubernetes集群中负责存储集群状态和元数据的分布式一致性存储系统。它是集群的“大脑”,为整个集群提供可靠的数据存储和分发服务。ETCD存储了集群的配置信息、状态信息等重要数据。
```python
# 示例代码
# 查看ETCD集群状态
etcdctl endpoint health
```
**代码解释:** 以上代码演示了通过etcdctl命令查看ETCD集群的健康状态。
**代码总结:** ETCD作为分布式一致性存储系统,负责存储集群状态和元数据,为整个集群提供可靠的数据存储和分发服务。
**结果说明:** 通过etcdctl命令可以查看ETCD集群的健康状态,以确保ETCD服务的正常运行。
本章内容详细介绍了Kubernetes架构中Master节点、Worker节点和ETCD集群的角色和功能,深入理解这些核心组件对于理解和使用Kubernetes集群至关重要。
# 5. Kubernetes集群的搭建与管理
Kubernetes集群的搭建是使用Kubernetes的关键步骤之一,它需要经过一系列的配置和管理过程。在本章中,我们将详细介绍Kubernetes集群的搭建流程、高可用性集群的配置与实现,以及Kubernetes集群的日常管理与维护。
#### 5.1 Kubernetes集群的搭建流程
Kubernetes集群的搭建通常包括以下几个步骤:
1. 安装Docker和kubelet: 在所有的节点上安装Docker和kubelet,这是Kubernetes集群所需的基本组件。
2. 配置Master节点: 在Master节点上安装和配置kube-apiserver、kube-controller-manager、kube-scheduler等核心组件,这些组件负责集群的控制和管理。
3. 配置Worker节点: 在Worker节点上安装和配置kubelet,这些节点将负责运行容器应用和处理集群的工作负载。
4. 部署Pod网络: 部署一个用于Pod通信的网络插件,比如Calico、Flannel或者Cilium。
5. 部署负载均衡器: 如果需要外部访问集群内的服务,需要部署负载均衡器,比如Ingress Controller或者Service类型为LoadBalancer的Service。
#### 5.2 高可用性集群的配置与实现
为了确保Kubernetes集群的高可用性,可以采用以下几种方式来配置和实现:
1. ETCD集群的高可用性配置: 使用多个ETCD节点组成一个ETCD集群,确保ETCD数据的冗余和高可用性。
2. 控制平面组件的多节点部署: 将kube-apiserver、kube-controller-manager、kube-scheduler等控制平面组件部署在多个节点上,通过负载均衡器实现这些组件的高可用访问。
3. 使用云服务提供商的托管集群: 选择像AWS EKS、Azure AKS或Google GKE这样的云原生托管服务,由云服务提供商负责集群的高可用性配置。
#### 5.3 Kubernetes集群的日常管理与维护
完成Kubernetes集群的搭建后,需要进行日常的管理与维护工作,包括但不限于:
1. 资源管理: 监控集群资源的使用情况,定期进行资源调整和优化,确保集群的高效利用。
2. 安全与权限: 配置RBAC、网络策略等安全控制机制,及时更新集群组件和系统软件,保障集群的安全性。
3. 故障排查与处理: 定期进行集群的健康巡检,及时发现和处理节点故障、网络故障等问题。
以上是关于Kubernetes集群搭建与管理的一些基本内容,下一节将探讨Kubernetes的未来发展趋势。
# 6. Kubernetes的未来发展趋势
随着云原生技术不断发展,Kubernetes作为容器编排和管理的事实标准,其未来发展趋势备受关注。在未来,Kubernetes将在以下几个方面迎来新的发展趋势:
#### 6.1 Kubernetes生态系统的发展现状
Kubernetes生态系统包括各种周边工具、服务和解决方案,如CI/CD工具、监控与日志系统、安全与治理工具等。未来,Kubernetes生态系统将更加完善和多样化,各类第三方厂商将为Kubernetes生态系统提供更多丰富的解决方案和服务。
在云原生领域,Kubernetes的生态系统正在不断扩大,不仅有云服务商提供的托管服务,还有众多第三方厂商提供的周边产品和服务,如Istio、Prometheus、Envoy等。这些工具的不断涌现丰富了Kubernetes的功能和应用场景,为用户提供了更多选择。
#### 6.2 新技术在Kubernetes中的应用
随着新技术的不断涌现,Kubernetes作为云原生技术的核心技术之一,将不断吸纳和融合新技术,以满足不断变化的业务需求。例如,Serverless、Service Mesh、AI/ML等新兴技术在Kubernetes中的应用将会成为未来的发展趋势。
近年来,Serverless架构逐渐成为云原生技术的热门话题,Kubernetes也在不断完善支持Serverless应用的能力,如Knative等项目的推出,为Kubernetes增加了更多新的应用场景和可能性。
#### 6.3 Kubernetes未来发展的预测与趋势
作为当今最流行的容器编排系统,未来Kubernetes将更加普及和成熟。在企业中,Kubernetes将逐渐成为主流的容器管理工具,越来越多的传统应用将会迁移到Kubernetes上,云原生应用的设计与开发也将更加侧重于Kubernetes的使用。
除此之外,Kubernetes在边缘计算、混合云的应用场景中也有巨大的潜力,未来Kubernetes在这些领域的发展将会成为亮点。同时,Kubernetes社区的不断壮大与完善也为其未来发展奠定了坚实的基础,预计未来Kubernetes将继续保持其领先地位,并扮演着重要的角色。
在未来的发展中,Kubernetes将不断融合和吸收新技术,进一步丰富其功能和应用场景,为企业和开发者提供更加强大、灵活和多样化的容器化解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SAPSD定价策略深度剖析:成本加成与竞对分析,制胜关键解读
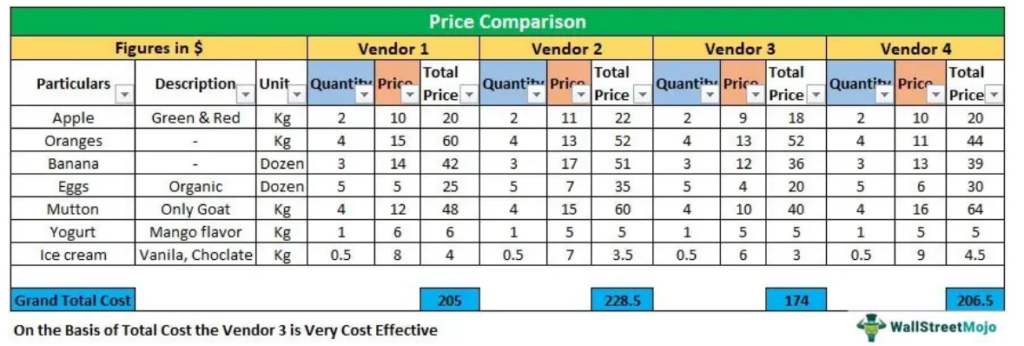
# 摘要
本文首先概述了SAPSD定价策略的基础概念,随后详细介绍了成本加成定价模型的理论和计算方法,包括成本构成分析、利润率设定及成本加成率的计算。文章进一步探讨了如何通过竞争对手分析来优化定价策略,并提出了基于市场定位的定价方法和应对竞争对手价格变化的策略。通过实战案例研究,本文分析了成本加成与市场适应性策略的实施效果,以及竞争对手分析在案例中的应用。最后,探
【指纹模组选型秘籍】:关键参数与性能指标深度解读
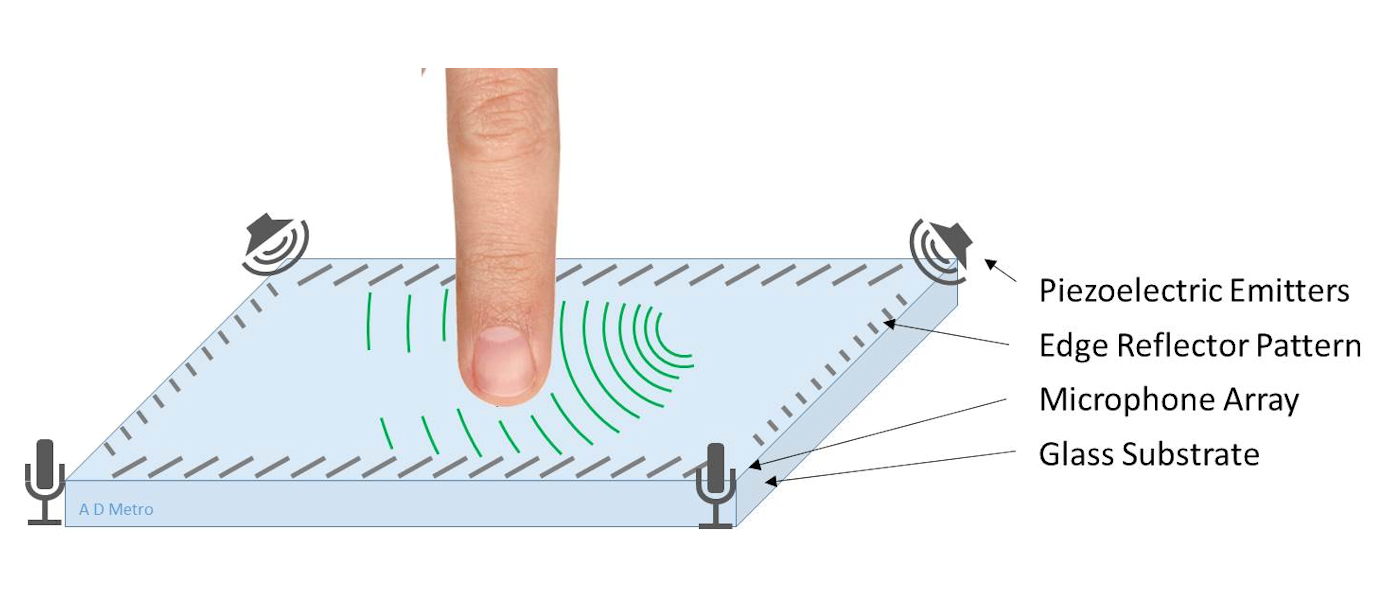
# 摘要
本文系统地介绍了指纹模组的基础知识、关键技术参数、性能测试评估方法,以及选型策略和市场趋势。首先,详细阐述了指纹模组的基本组成部分,如传感器技术参数、识别算法及其性能、电源与接口技术等。随后,文章深入探讨了指纹模组的性能测试流程、稳定性和耐用性测试方法,并对安全性标准和数据保护进行了评估。在选型实战指南部分,根据不同的应用场景和成本效益分析,提供了模组选择的实用指导。最后,
凌华PCI-Dask.dll全解析:掌握IO卡编程的核心秘籍(2023版)
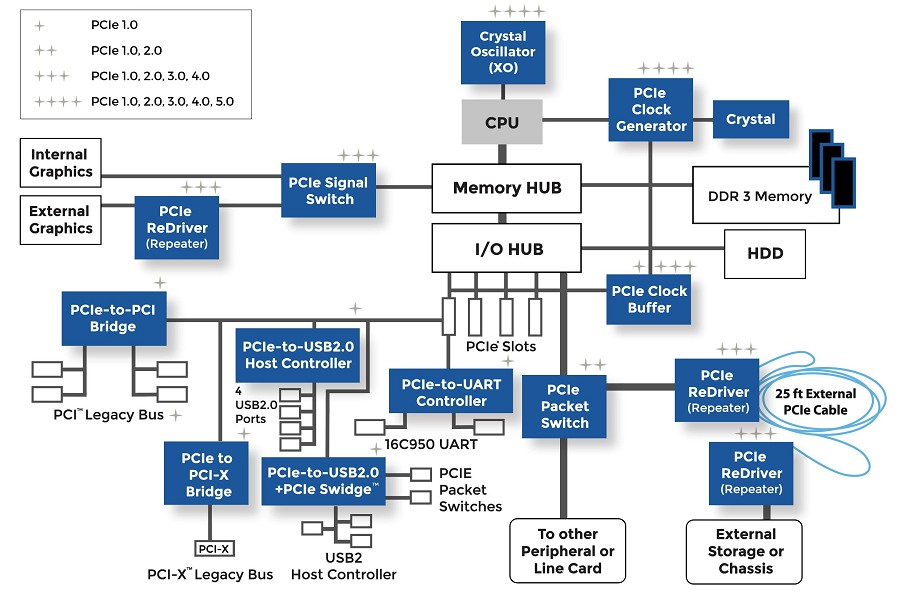
# 摘要
凌华PCI-Dask.dll是一个专门用于数据采集与硬件控制的动态链接库,它为开发者提供了一套丰富的API接口,以便于用户开发出高效、稳定的IO卡控制程序。本文详细介绍了PCI-Dask.dll的架构和工作原理,包括其模块划分、数据流缓冲机制、硬件抽象层、用户交互数据流程、中断处理与同步机制以及错误处理机制。在实践篇中,本文阐述了如何利用PCI-Dask.dll进行IO卡编程,包括AP
案例分析:MIPI RFFE在实际项目中的高效应用攻略

# 摘要
本文全面介绍了MIPI RFFE技术的概况、应用场景、深入协议解析以及在硬件设计、软件优化与实际项目中的应用。首先概述了MIPI RFFE技术及其应用场景,接着详细解析了协议的基本概念、通信架构以及数据包格式和传输机制。随后,本文探讨了硬件接口设计要点、驱动程序开发及芯片与传感器的集成应用,以及软件层面的协议栈优化、系统集成测试和性能监控。最后,文章通过多个项目案例,分析了MIPI RF
Geolog 6.7.1高级日志处理:专家级功能优化与案例研究
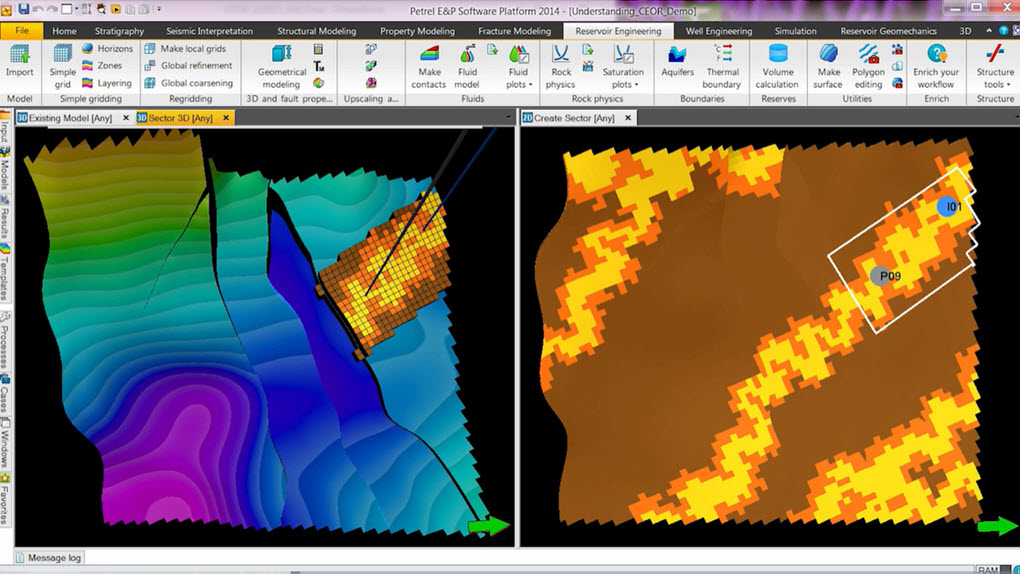
# 摘要
本文全面介绍了Geolog 6.7.1版本,首先提供了该软件的概览,接着深入探讨了其高级日志处理、专家级功能以及案例研究,强调了数据过滤、索引、搜索和数据分析等关键功能。文中分析了如何通过优化日志处理流程,解决日志管理问题,以及提升日志数据分析的价值。此外,还探讨了性能调优的策略和维护方法。最后,本文对Geolog的未来发展趋势进行了展望,包括新版本
ADS模型精确校准:掌握电感与变压器仿真技术的10个关键步骤

# 摘要
本文全面介绍了ADS模型精确校准的理论基础与实践应用。首先概述了ADS模型的概念及其校准的重要性,随后深入探讨了其与电感器和变压器仿真原理的基础理论,详细解释了相关仿真模型的构建方法。文章进一步阐述了ADS仿真软件的使用技巧,包括界面操作和仿真模型配置。通过对电感器和变压器模型参数校准的具体实践案例分析,本文展示了高级仿真技术在提高仿真准确性中的应用,并验证了仿真结果的准确性。最后
深入解析华为LTE功率控制:掌握理论与实践的完美融合

# 摘要
本文对LTE功率控制的技术基础、理论框架及华为在该领域的技术应用进行了全面的阐述和深入分析。首先介绍了LTE功率控制的基本概念及其重要性,随后详细探
【Linux故障处理攻略】:从新手到专家的Linux设备打开失败故障解决全攻略
# 摘要
本文系统介绍了Linux故障处理的基本概念,详细分析了Linux系统的启动过程,包括BIOS/UEFI的启动机制、内核加载、初始化进程、运行级和
PLC编程新手福音:入门到精通的10大实践指南

# 摘要
本文旨在为读者提供一份关于PLC(可编程逻辑控制器)编程的全面概览,从基础理论到进阶应用,涵盖了PLC的工作原理、编程语言、输入输出模块配置、编程环境和工具使用、项目实践以及未来趋势与挑战。通过详细介绍PLC的硬件结构、常用编程语言和指令集,文章为工程技术人员提供了理解和应用PLC编程的基础知识。此外,通过对PLC在自动化控制项目中的实践案例分析,本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )