Kubernetes中Job与CronJob的任务调度与管理
发布时间: 2024-02-25 22:05:07 阅读量: 47 订阅数: 24 
# 1. 简介
在Kubernetes集群中,任务调度是一个至关重要的组成部分,它可以帮助我们高效地管理和执行各种任务。其中,Job和CronJob是Kubernetes中用于任务调度的两种主要对象。本文将介绍它们的概念、特点以及如何应用于实际场景中。
## 介绍Kubernetes中任务调度的概念和重要性
任务调度是指根据一定的规则和策略,将任务分配给集群中的可用资源,并管理任务的执行过程。在一个复杂的分布式系统中,合理的任务调度可以提高系统的效率和稳定性,避免资源的浪费和任务的冲突。
Kubernetes作为一个领先的容器编排平台,提供了强大的任务调度机制,可以帮助用户在集群中管理各种类型的任务,包括短暂的一次性任务和周期性的定时任务。
## 简要说明Job和CronJob的作用和区别
在Kubernetes中,Job和CronJob是用来管理任务调度的两种资源对象。它们分别针对不同的任务调度需求,具有各自独特的特点和用途:
- Job: 用于在集群中运行一次性任务,保证任务成功完成后退出,适用于需要精确控制任务执行次数和顺序的场景。
- CronJob: 用于周期性地执行任务,可以根据预定义的时间表重复运行任务,适用于需要定时执行任务的场景。
# 2. II. Job任务调度
A. 什么是Job对象?
在Kubernetes中,Job是一种用于管理短暂任务(即一次性任务)的资源对象。它确保一个或多个Pod成功完成任务,并且不会重复执行。一旦任务完成,Job对象会标记为完成,而不会保持运行状态。
B. Job的特点与使用场景
Job适用于需要执行一次且仅一次的任务,比如数据处理、批量计算等。它确保任务成功完成,如果Pod发生故障会重启新的Pod,直到任务成功为止。
C. 创建和管理单次性任务的实例
下面是一个使用Python编写的简单示例,演示如何创建一个Job对象来运行任务:
```python
from kubernetes import client, config
config.load_kube_config()
api_instance = client.BatchV1Api()
def create_job_object():
container = client.V1Container(
name="job-container",
image="busybox",
command=["echo", "Hello from the Job!"]
)
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(labels={"app": "job"}),
spec=client.V1PodSpec(restart_policy="Never", containers=[container])
)
spec = client.V1JobSpec(template=template, backoff_limit=4)
job = client.V1Job(api_version="batch/v1", kind="Job", spec=spec)
return job
def create_job(api_instance, namespace):
job = create_job_object()
api_response = api_instance.create_namespaced_job(body=job, namespace=namespace)
return api_response
namespace = "default"
response = create_job(api_instance, namespace)
print("Job created. Status='%s'" % str(response.status))
```
此示例使用Python的Kubernetes客户端库,创建了一个Job对象来执行简单的任务“echo Hello from the Job!”。您可以根据实际需求修改容器镜像、命令等内容。当Job成功运行后,您会看到打印出“Job created. Status='...'"的消息。
通过这样的代码示例,您可以更好地了解如何在Kubernetes中使用Job对象来管理单次性任务。
# 3. III. CronJob任务调度
在Kubernetes中,CronJob是一种用于定期执行任务的调度器。它允许用户在指定的时间间隔或特定时间点上运行作业。下面我们将深入探讨CronJob的相关内容。
A. 什么是CronJob对象?
CronJob是Kubernetes中的一种资源对象,用于管理周期性任务的调度和执行。它基于类似于Linux系统中的cron表达式的时间调度规则,可以指定任务运行的时间计划。
B. CronJob的特点与使用场景
与Job不同,CronJob适用于需要定期执行的任务,例如每天、每小时或每周执行一次的任务。它非常适合用于定时备份、日志清理、定期数据处理等场景。
C. 如何基于时间表调度任务?
在定义CronJob时,需要使用Cron表达式来指定任务的调度规则。Cron表达式由5个时间字段组成,分别表示分钟、小时、日期、月份和星期几。例如,`0 0 * * *`表示每天的零点执行任务,`*/5 * * * *`表示每5分钟执行一次任务。通过这种方式,可以灵活地配置CronJob以满足不同的调度需求。
希望以上内容能够满足您的需求,如果有其他要求或需要进一步细节的补充,请随时告诉我!
# 4. IV. Job与CronJob的比较
在Kubernetes中,Job和CronJob都是用来执行任务调度的对象,它们各自有着不同的特点和适用场景。接下来我们将分别比较Job和CronJob,以便更好地理解它们之间的异同点。
#### A. Job与CronJob的异同点
1. **调度方式**:
- Job: 适用于执行一次性任务,当任务完成后即终止。
- CronJob: 适用于周期性地执行任务,可以根据时间表设定定时调度。
2. **执行方式**:
- Job: 创建一个Pod并执行任务,任务完成后Pod自动终止。
- CronJob: 根据时间表设定定时执行任务,可以定期执行指定的Job。
3. **适用场景**:
- Job: 适合执行一次性且不需要定期执行的任务,如批量数据处理、定时备份等。
- CronJob: 适合需要定期执行的任务,如定时清理任务、周期性统计等。
4. **任务调度方式**:
- Job: 通过创建单次性任务实例来执行任务。
- CronJob: 通过时间表设置来定期执行任务。
#### B. 选择Job还是CronJob的考虑因素
在实际应用中,选择使用Job还是CronJob需要考虑以下因素:
- 任务执行频率
- 任务的持续性
- 任务的执行时刻
- 任务的容错与重试机制
通过比较Job和CronJob的异同点以及考虑因素,可以更好地选择适合特定场景的任务调度对象,从而提高任务的执行效率和可靠性。
希望以上内容能够为您提供清晰的Job与CronJob比较信息。接下来,我们将继续深入探讨任务调度的实际案例分析。
# 5. V. 实际案例分析
在本节中,我们将结合实际案例,分别使用Job和CronJob来展示它们在Kubernetes中任务调度与管理的应用。
#### A. 使用Job实现特定任务的调度
我们将以一个简单的示例来演示如何使用Job对象来实现特定任务的调度。假设我们有一个需要定期清理日志文件的应用,我们可以通过创建一个Kubernetes Job来实现这一定期任务。下面是一个用Python编写的清理任务的示例代码:
```python
import os
import shutil
from datetime import datetime, timedelta
# 定义要清理的日志目录
log_dir = '/var/log/app_logs'
# 计算30天前的日期
thirty_days_ago = datetime.now() - timedelta(days=30)
# 遍历日志目录,删除30天前的日志文件
for root, dirs, files in os.walk(log_dir):
for file in files:
file_path = os.path.join(root, file)
create_time = datetime.fromtimestamp(os.path.getctime(file_path))
if create_time < thirty_days_ago:
os.remove(file_path)
```
以上代码是一个简单的Python脚本,用于定期清理指定目录下30天前的日志文件。
#### 结果说明:
1. 该脚本首先定义了要清理的日志目录路径为'/var/log/app_logs';
2. 然后计算了30天前的日期,并遍历日志目录下的所有文件;
3. 对于创建日期早于30天前的文件,将其删除。
通过将上述Python脚本制作成Docker镜像并创建相应的Kubernetes Job对象,我们就可以在Kubernetes集群中实现定期清理日志文件的任务调度。
#### B. 使用CronJob定期执行任务的例子
与上述定期清理日志文件的例子类似,假设我们需要在每天凌晨1点执行某个数据备份任务。这时就可以使用CronJob对象来实现定期执行任务的调度。下面是一个简单的数据备份任务的示例代码:
```python
import os
import shutil
import datetime
# 定义源数据目录和备份目录
source_dir = '/data'
backup_dir = '/backup'
# 生成备份文件夹名
backup_folder_name = datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
# 执行数据备份
shutil.copytree(source_dir, os.path.join(backup_dir, backup_folder_name))
```
以上代码是一个简单的Python脚本,实现了在每天凌晨1点将指定目录下的数据进行备份。
#### 结果说明:
该脚本定义了源数据目录为'/data',备份目录为'/backup',然后通过shutil.copytree()函数实现了数据的备份操作。通过将该脚本制作成Docker镜像并创建相应的Kubernetes CronJob对象,我们就可以实现每天凌晨1点自动执行数据备份的调度任务。
通过以上两个实际案例的分析,我们可以更加深入地理解和应用Kubernetes中的Job和CronJob对象,以实现各种任务调度与管理需求。
# 6. Ⅵ. 任务调度的最佳实践
在Kubernetes中,设计可靠的任务调度策略至关重要。以下是一些建议帮助您确保您的任务按时、按需正确执行,并避免常见的任务调度错误:
A. 如何设计可靠的任务调度策略
1. **明确任务需求**:在创建Job或CronJob之前,确保清楚了解任务的需求和执行频率。
2. **设置适当的重试机制**:在Job或CronJob中设置适当的重试次数和间隔,以应对可能的执行失败情况。
3. **监控与日志**:及时监控任务执行情况,记录任务执行的日志,便于排查和分析问题。
4. **资源限制**:根据任务复杂度和资源需求,设置合理的资源限制,避免任务过度占用资源导致集群性能下降。
B. 避免常见任务调度错误的建议
1. **忽略任务执行时间**:确保任务的执行时间不会与其他关键任务产生冲突,避免影响整体系统的稳定性。
2. **不合理的重试策略**:避免过于频繁或过于稀少的重试设置,应根据具体场景和任务特性合理配置。
3. **忽略任务执行日志**:日志是排查问题的关键信息来源,务必及时记录任务执行的详细日志,方便随时跟踪和分析问题。
以上最佳实践和建议将有助于您在Kubernetes中实现高效、稳定的任务调度管理。通过合理规划和持续优化任务调度策略,您可以更好地利用Kubernetes提供的强大功能,实现任务的自动化管理和高效执行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
编译器优化算法探索:图着色与寄存器分配详解
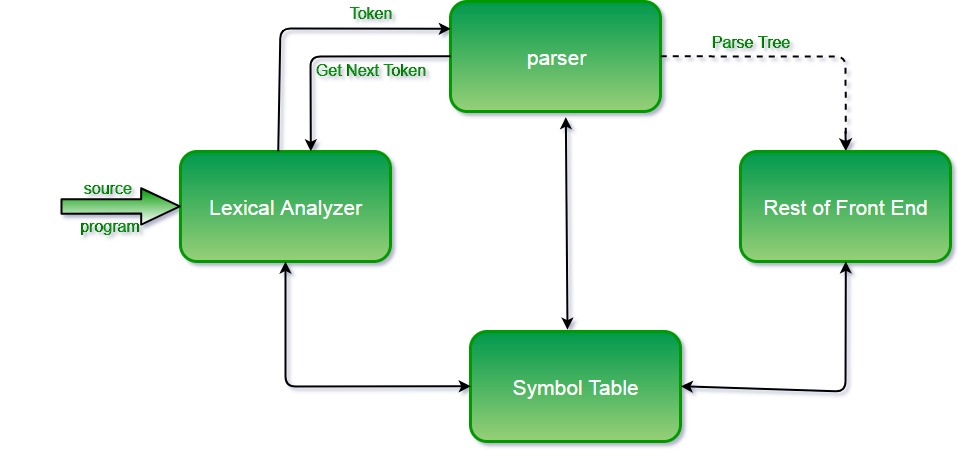
# 摘要
编译器优化是提高软件性能的关键技术之一,而图着色算法在此过程中扮演着重要角色。本文系统地回顾了编译器优化算法的概述,并深入探讨了图着色算法的基础、在寄存器分配中的应用以及其分类和比较。接着,本文详细分析了寄存器分配策略,并通过多种技术手段对其进行了深入探讨。此外,本文还研究了图着色算法的实现与优化方法,并通过实验评估了这些方法的性能。通过对典型编程语言编译器中寄存器分配案例的分析,本文展示了优化策略的实际
时间序列季节性分解必杀技:S命令季节调整手法

# 摘要
时间序列分析是理解和预测数据动态的重要工具,在经济学、气象学、工商业等多个领域都有广泛应用。本文首先介绍了时间序列季节性分解的基本概念和分类,阐述了时间序列的特性,包括趋势性、周期性和季节性。接着,本文深入探讨了季节调整的理论基础、目的意义以及常用模型和关键假设。在实践环节,本文详细说明了如何使用S命令进行季节调整,并提供了步骤和技巧。案例分析部分进一步探讨了
【SAP MM高级定制指南】:4个步骤实现库存管理个性化

# 摘要
本文旨在深入探讨SAP MM(物料管理)模块的高级定制策略与实践。首先对SAP MM模块的功能和库存管理基础进行了概述。随后,介绍了定制的理论基础,包括核心功能、业务流程、定制概念及其类型、以及定制的先决条件和限制。文章接着详细阐述了实施高级定制的步骤,涉及需求分析、开发环境搭建、定制对象开发和测试等关键环节。此外,本文还探讨了SAP MM高级
【ParaView过滤器魔法】:深入理解数据预处理
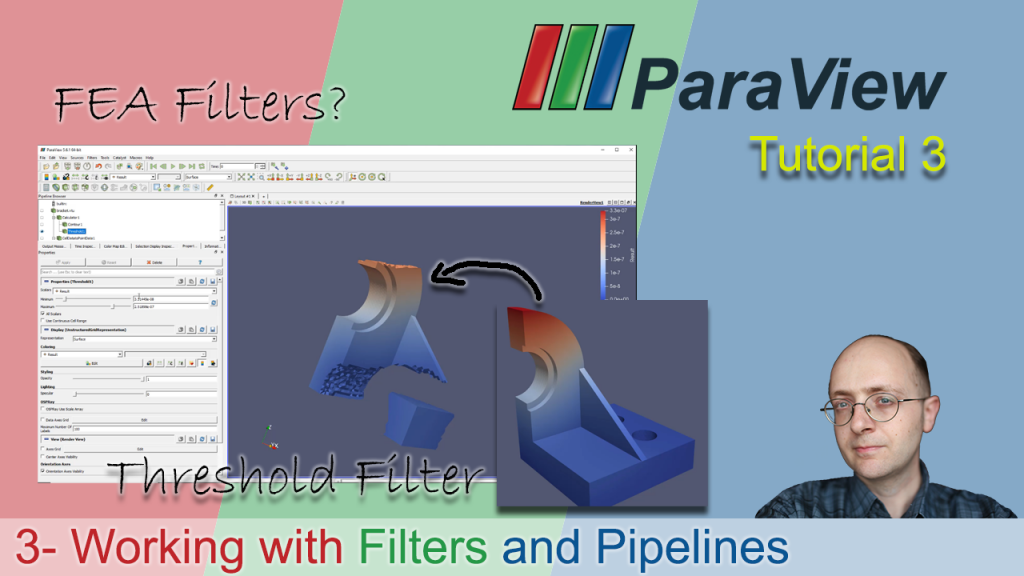
# 摘要
本文全面介绍了ParaView在数据预处理和分析中的应用,重点阐述了过滤器的基础知识及其在处理复杂数据结构中的作用。文章详细探讨了基本过滤器的使用、参数设置与管理、以及高级过滤技巧与实践,包括性能优化和数据流管理。此外,还对数据可视化与分析进行了深入研究,并通过实际案例分析了ParaView过滤器在科
【扩展Strip功能】:Visual C#中Strip控件的高级定制与插件开发(专家技巧)
# 摘要
Strip控件作为用户界面的重要组成部分,广泛应用于各种软件系统中,提供了丰富的定制化和扩展性。本文从Strip控件的基本概念入手,逐步深入探讨其高级定制技术,涵盖外观自定义、功能性扩展、布局优化和交互式体验增强。第三章介绍了Strip控件插件开发的基础知识,包括架构设计、代码复用和管理插件生命周期的策略。第四章进一步讲解了数据持久化、多线程处理和插件间交互等高级开发技巧。最后一章通过实践案例分析,展示了如何根据用户需求设计并开发出具有个性化功能的Strip控件插件,并讨论了插件测试与迭代过程。整体而言,本文为开发者提供了一套完整的Strip控件定制与插件开发指南。
# 关键字
S
【数据处理差异揭秘】

# 摘要
数据处理是一个涵盖从数据收集到数据分析和应用的广泛领域,对于支持决策过程和知识发现至关重要。本文综述了数据处理的基本概念和理论基础,并探讨了数据处理中的传统与现代技术手段。文章还分析了数据处理在实践应用中的工具和案例,尤其关注了金融与医疗健康行业中的数据处理实践。此外,本文展望了数据处理的未来趋势,包括人工智能、大数据、云计算、边缘计算和区块链技术如何塑造数据处理的未来。通过对数据治理和
【C++编程高手】:精通ASCII文件读写的最佳实践
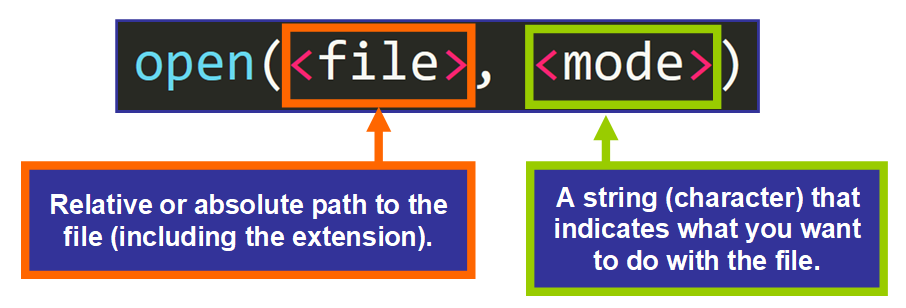
# 摘要
C++作为一门强大的编程语言,其在文件读写操作方面提供了灵活而强大的工具和方法。本文首先概述了C++文件读写的基本概念和基础知识,接着深入探讨了C++文件读写的高级技巧,包括错误处理、异常管理以及内存映射文件的应用。文章进一步分析了C++在处理ASCII文件中的实际应用,以及如何在实战中解析和重构数据,提供实用案例分析。最后,本文总结了C++文件读写的最佳实践,包括设计模式的应用、测试驱动开发(TDD)的
【通信信号分析】:TTL电平在现代通信中的关键作用与案例研究
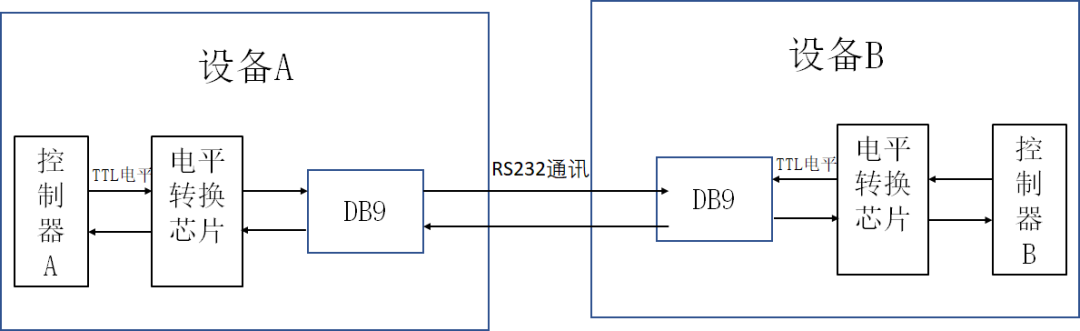
# 摘要
TTL电平作为电子和通信领域中的基础概念,在数字逻辑电路及通信接口中扮演着至关重要的角色。本文深入探讨了TTL电平的基础作用、技术细节与性能分析,并比较了TTL与CMOS电平的差异及兼容性问题。接着,本文着重分析了TTL电平在现代通信系统中的应用,包括其在数字逻辑电路、微处理器、通信接口协议中的实际应用以及
零基础Pycharm教程:如何添加Pypi以外的源和库

# 摘要
Pycharm作为一款流行的Python集成开发环境(IDE),为开发人员提供了丰富的功能以提升工作效率和项目管理能力。本文从初识Pycharm开始,详细介绍了环境配置、自定义源与库安装、项目实战应用以及高级功能的使用技巧。通过系统地讲解Pycharm的安装、界面布局、版本控制集成,以及如何添加第三方源和手动安装第三方库,本文旨在帮助读者全面掌握Pycharm的使用,特
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )