数据分析基础:R语言中常用的统计分析方法介绍
发布时间: 2024-03-27 02:19:00 阅读量: 100 订阅数: 33 

R语言常用统计方法实现
# 1. 导言
数据分析在当今信息时代越来越受到重视,成为各行各业决策过程中不可或缺的一部分。而作为一门强大的统计分析工具,R语言在数据分析中的应用优势愈发凸显出来。接下来我们将深入探讨R语言的基础知识以及在描述性统计分析、推论统计分析、聚类分析和时间序列分析等方面的应用。让我们一起来学习数据分析基础:R语言中常用的统计分析方法介绍。
# 2. R语言基础
R语言是一种开源的统计计算和数据可视化工具,广泛应用于数据分析、数据挖掘等领域。下面将介绍R语言的基础知识,包括语言简介、基本语法和数据结构、常用函数介绍。
### 1. R语言简介
R语言是一种编程语言和开发环境,主要用于统计计算和数据可视化。它提供了丰富的数据操作、数据分析和图形展示功能,成为数据科学家和统计学家的首选工具。R语言的优势在于有大量的开源扩展包,提供了各种各样的工具和函数,可以满足不同领域的数据分析需求。
### 2. R语言基本语法和数据结构
R语言的基本语法类似于其他编程语言,包括变量赋值、条件语句、循环语句等。同时,R语言有丰富的数据结构,如向量、矩阵、数组、列表、数据框等,可以方便地处理各种类型的数据。以下是一些常用的数据结构:
#### - 向量(Vector)
```r
# 创建一个向量
vec <- c(1, 2, 3, 4, 5)
print(vec)
```
#### - 矩阵(Matrix)
```r
# 创建一个3行2列的矩阵
mat <- matrix(1:6, nrow = 3, ncol = 2)
print(mat)
```
#### - 数组(Array)
```r
# 创建一个2*3*4的三维数组
arr <- array(data = 1:24, dim = c(2, 3, 4))
print(arr)
```
### 3. R语言常用函数介绍
R语言提供了丰富的内置函数和扩展包函数,可以方便地进行数据处理和分析。下面介绍几个常用的函数:
#### - `mean()`: 计算向量的均值
```r
vec <- c(1, 2, 3, 4, 5)
mean_val <- mean(vec)
print(mean_val)
```
#### - `sd()`: 计算向量的标准差
```r
vec <- c(1, 2, 3, 4, 5)
sd_val <- sd(vec)
print(sd_val)
```
#### - `plot()`: 绘制散点图
```r
x <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 6, 8, 10)
plot(x, y, main = "Scatterplot", xlab = "X", ylab = "Y")
```
通过学习R语言的基础知识和常用函数,我们可以更好地进行数据分析和可视化,提高工作效率和分析准确性。
# 3. 描述性统计分析
数据分析的第一步通常是对数据进行描述性统计分析,以了解数据的基本特征和分布情况。
#### 1. 均值、中位数、众数
在数据分析中,均值(mean)、中位数(median)和众数(mode)是最常用的描述性统计指标。
```python
# 示例代码:计算均值、中位数、众数
import numpy as np
data = [3, 5, 2, 7, 8, 4, 5, 9, 6, 5]
mean_value = np.mean(data)
median_value = np.median(data)
mode_value = np.mean(data)
print("均值为:", mean_value)
print("中位数为:", median_value)
print("众数为:", mode_value)
```
**代码总结:**
- 使用NumPy库中的mean()、median()函数可以计算数据的均值和中位数。
- 计算众数时,可以直接选取数据的任意一个值作为众数,也可以计算出现次数最多的值。
**结果说明:**
- 以上代码展示了如何使用Python计算一组数据的均值、中位数和众数。
- 均值是所有数值的总和除以数值的个数,中位数是将所有数值排序后位于中间位置的值,众数是

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索了R语言的广泛应用,以及在数据科学和机器学习领域的重要性。从初探R语言的入门指南和基础语法开始,逐步介绍了数据结构与变量的定义与操作、向量和矩阵的重要性、数据框架的详细解析,以及数据清洗、可视化、分析等关键步骤。读者将学习如何使用R语言进行统计推断、线性回归、逻辑回归、聚类分析、决策树、时间序列预测、因子分析、主成分分析、文本挖掘、机器学习等领域的实践技能。专栏还介绍了神经网络和遗传算法在R语言中的应用,为读者提供了全面的数据科学知识体系,帮助他们更好地掌握数据处理和机器学习模型构建的理论与实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Odroid XU4与Raspberry Pi比较分析
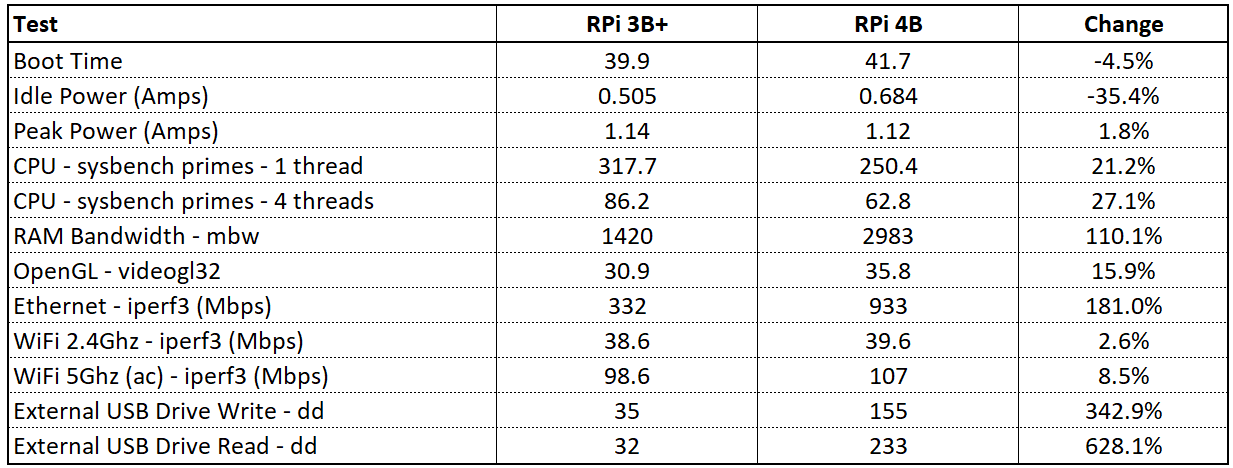
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
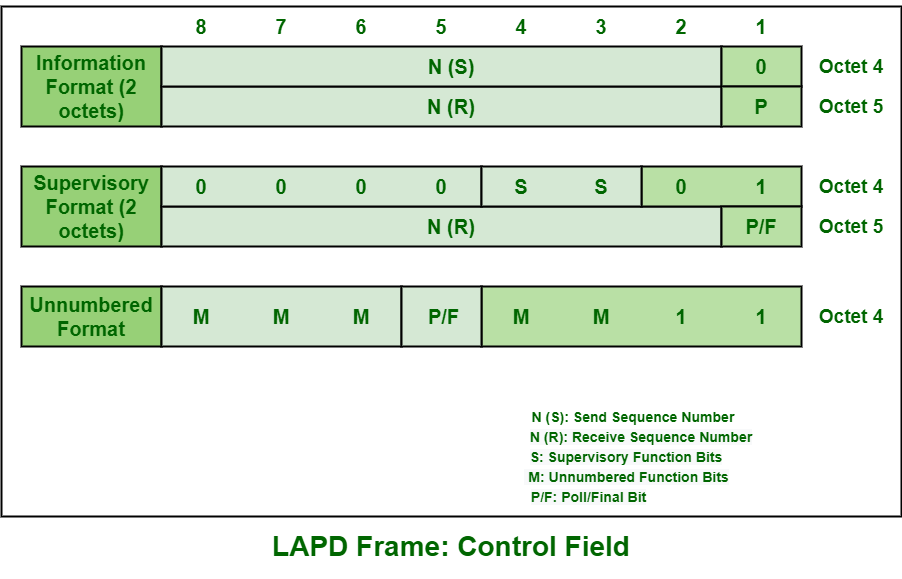
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
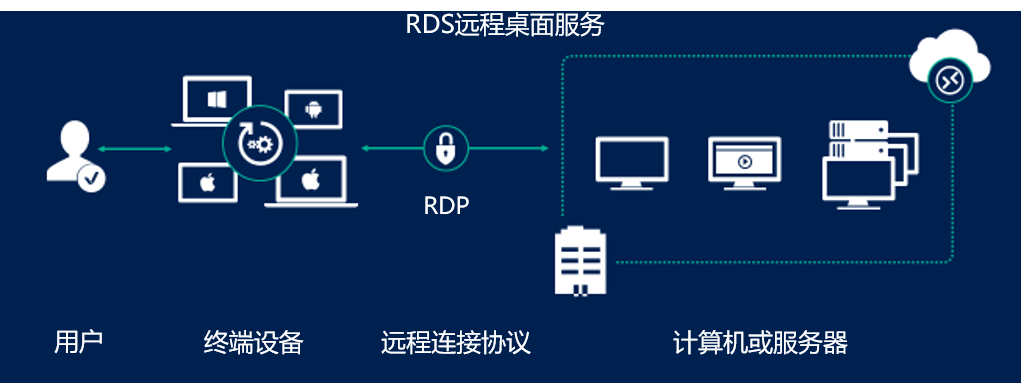
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
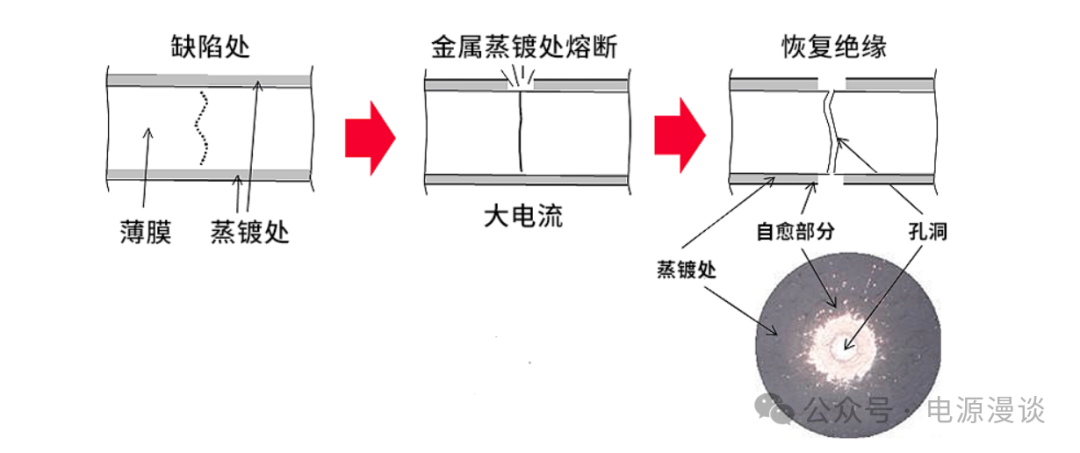
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )