大数据处理:海量数据的存储、处理与应用
发布时间: 2024-01-26 19:49:04 阅读量: 63 订阅数: 55 
# 1. 简介
## 1.1 什么是大数据处理
大数据处理是指对海量、高维、异构的数据进行收集、存储、处理和分析的过程。传统的数据处理方法已经无法有效处理大数据,因为大数据的特点包括数据量巨大、数据种类多样、数据生成速度快、数据价值潜力大等。
## 1.2 大数据存储与处理的挑战
大数据存储与处理面临以下挑战:
- 存储能力:大数据的存储需求巨大,传统的存储系统无法满足。
- 数据管理:大数据具有多样化的数据类型和格式,需要能够有效管理和组织数据。
- 数据安全:大数据涉及的个人隐私和商业机密需要得到有效的保护。
- 数据处理速度:大数据需要快速处理和分析,传统的数据处理方法效率低下。
## 1.3 大数据应用的价值和影响
大数据应用具有重要的价值和影响:
- 挖掘商业价值:通过对大数据的分析,可以获取有关市场趋势、用户行为等关键信息,帮助企业做出更明智的决策。
- 改进产品和服务:通过分析大数据,企业可以了解用户对产品和服务的需求和反馈,从而优化产品设计和提供更好的客户体验。
- 优化运营效率:大数据分析可以帮助企业识别和解决运营中的问题,提高效率并减少成本。
- 改善社会治理:大数据分析可以帮助政府或组织更好地了解社会问题,制定更有针对性的政策和措施。
大数据应用的影响已经深入到各个行业和领域,成为推动经济和社会发展的重要力量。
# 2. 大数据的存储技术
大数据存储技术是大数据处理的重要组成部分,能够有效地存储和管理海量的数据。常见的大数据存储技术包括分布式文件系统、NoSQL数据库、数据仓库和数据湖等。
### 2.1 分布式文件系统
分布式文件系统是一种能够跨多台计算机存储数据的文件系统。它能够提供高容量、高性能、以及高可靠性的数据存储解决方案。Hadoop分布式文件系统(HDFS)是其中最为经典的代表。以下是HDFS的Java示例:
```java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSExample {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem fs = FileSystem.get(conf);
// 创建文件
fs.create(new Path("/data/file1.txt"));
// 读取文件
InputStream in = fs.open(new Path("/data/file1.txt"));
// ... 读取文件内容
// 关闭FileSystem
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
通过以上示例,可以看出HDFS的基本使用流程,包括配置连接信息、创建文件和读取文件等操作。
### 2.2 NoSQL数据库
NoSQL数据库是一类非关系型的数据库,能够存储和处理大规模的无结构或半结构化数据。常见的NoSQL数据库包括MongoDB、Cassandra、HBase等。以下是使用MongoDB进行数据存储的Python示例:
```python
from pymongo import MongoClient
# 连接MongoDB
client = MongoClient('localhost', 27017)
# 创建数据库和集合
db = client['mydatabase']
collection = db['mycollection']
# 插入数据
data = {'name': 'Alice', 'age': 25}
collection.insert_one(data)
# 查询数据
result = collection.find_one({'name': 'Alice'})
print(result)
# 关闭连接
client.close()
```
以上示例演示了使用Python连接MongoDB,进行数据插入和查询的操作。
### 2.3 数据仓库和数据湖
数据仓库和数据湖是用于存储和管理结构化、半结构化和非结构化数据的存储系统。数据仓库一般用于存储清洗好的结构化数据,而数据湖则更加灵活,可以接收各种类型的数据。常见的数据仓库包括Amazon Redshift、Snowflake等,数据湖则有Amazon S3、Azure Data Lake等。以下是使用Amazon S3进行数据存储的Java示例:
```java
import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import java.io.File;
public class S3Example {
public static void main(String[] args) {
Region region = Region.US_WEST_1;
S3Client s3 = S3Client.builder()
.region(region)
.credentialsProvider(DefaultCredentialsProvider.create())
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《计算机导论》专栏全面介绍了计算机科学与技术的基础知识和原理。文章内容涵盖了计算机分类、特性、工作原理,以及数制转换、机器数表示等内容。文章以通俗易懂的方式介绍了计算机在各个领域的应用,包括逻辑运算、算术运算,二进制小数的表示方式,字符编码原理,以及计算思维和数据管理等方面的基本概念。此外,该专栏还深入介绍了数据库技术、大数据处理以及操作系统原理和网络通信概念等诸多内容。通过本专栏的阅读,读者可以全面了解计算机科学与技术的基础知识,对计算机领域有一个系统化的认识和理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【BAT脚本高级解析】:解锁持续运行脚本的秘密

参考资源链接:[Windows下让BAT文件后台运行的方法](https://wenku.csdn.net/doc/32duer3j7y?spm=1055.2635.3001.
STEP7 GSD文件安装:兼容性分析,确保不同操作系统下的正确安装
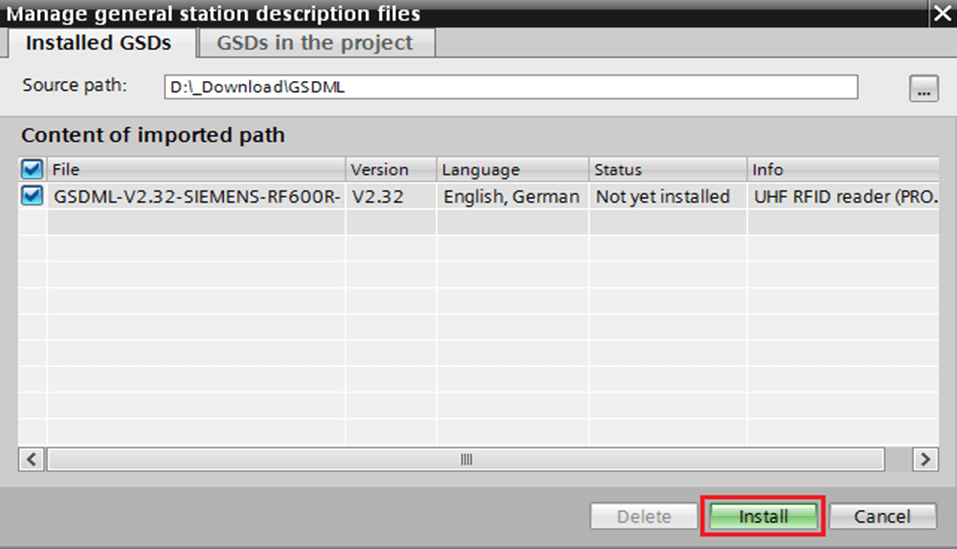
参考资源链接:[解决STEP7中GSD安装失败问题:解除引用后重装](https://wenku.csdn.net/doc/6412b5fdbe7fbd1778d451c0?spm=1055.2635.3001.10343)
# 1. STEP7 GSD文件简介
在自动化和工业控制系统领域,STEP7(也称为TIA Portal)是西门子广泛
【GX Works3与工业物联网】:连接智能设备与工业云的策略,开启工业4.0之旅

参考资源链接:[三菱GX Works3编程手册:安全操作与应用指南](https://wenku.csdn.net/doc/645da0e195996c03ac442695?spm=1055.2635.3001.10343)
# 1. GX Works3与工业物联网概述
在工业自动化领域,GX Works3软件与工业物联网技术的结合日益紧密。GX Works3作为三菱电机推出
【绿色计算】:DDR4 SODIMM功耗管理,性能与环保兼顾

参考资源链接:[DDR4_SODIMM_SPEC.pdf](https://wenku.csdn.net/doc/6412b732be7fbd1778d496f2?spm=1055.2635.3001.10343)
# 1. 绿色计算的概念与发展
## 1.1 绿色计算的定义
绿色计算,也被称为环保计算或绿色IT,是一种旨在减少计算机硬件、软件及相关设备在生产、使用和废弃
GNSS高程数据质量控制大揭秘:确保数据结果无懈可击

参考资源链接:[GnssLevelHight:高精度高程拟合工具](https://wenku.csdn.net/doc/6412b6bdbe7fbd1778d47cee?spm=1055.2635.3001.10343)
# 1. GNSS高程数据概述
GNSS(全球导航卫星系统)技术在全球范围内被
【DDR Margin测试深度解析】:从理论到实践,掌握内存性能优化的终极武器
参考资源链接:[DDR Margin测试详解与方法](https://wenku.csdn.net/doc/626si0tifz?spm=1055.2635.3001.10343)
# 1. DDR Margin测试概述
在IT行业,尤其是在内存技术领域,DDR Margin测
【OptiXstar V173路由协议大师】:BGP_OSPF配置案例解析
参考资源链接:[华为OptiXstar V173系列Web界面配置指南(电信版)](https://wenku.csdn.net/doc/442ijfh4za?spm=1055.2635.3001.10343)
# 1. 路由协议基础与分类
路由协议是网络中数据传输的基石,负责决定数据包在网络中如何传输。它通过复杂的算法和策略来优化网络流
【高级电路故障排除】:PIN_delay设置错误的诊断与修复,恢复系统稳定性
参考资源链接:[Allegro添加PIN_delay至高速信号的详细教程](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f6b?spm=1055.2635.3001.10343)
# 1. PIN_delay设置的重要性与影响
在当今的IT和电子工程领域,PIN_delay参数的设置对于确保系统稳定性和
【防止过拟合】机器学习中的正则化技术:专家级策略揭露

参考资源链接:[《机器学习(周志华)》学习笔记.pdf](https://wenku.csdn.net/doc/6412b753be7fbd1778d49
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )