GPU加速深度学习:选择与优化硬件的终极指南
发布时间: 2024-12-22 11:25:17 阅读量: 9 订阅数: 7 

基于纯verilogFPGA的双线性差值视频缩放 功能:利用双线性差值算法,pc端HDMI输入视频缩小或放大,然后再通过HDMI输出显示,可以任意缩放 缩放模块仅含有ddr ip,手写了 ram,f

# 摘要
GPU在深度学习领域扮演了不可或缺的角色,它不仅在硬件基础上提供了强大的并行处理能力,还通过优化策略大幅提升了深度学习模型的训练和推理速度。本文详细介绍了GPU的架构、性能指标以及不同品牌和型号之间的对比,并探讨了多GPU并行计算的优势与挑战,以及GPU内存与存储技术的演进。同时,本文还深入分析了多种深度学习框架与GPU的兼容性问题,包括CUDA、OpenCL和DirectCompute等GPU加速技术的选择和实践优化。此外,文章还总结了算法层面和系统层面的GPU优化策略,并通过实际案例分析了GPU优化的成功与失败经验。最后,本文展望了未来GPU技术与深度学习的发展趋势,包括新兴GPU架构的预测、GPU云服务与边缘计算的进展,以及模型压缩、量化技术和自动化机器学习(AutoML)的未来方向。
# 关键字
GPU;深度学习;硬件基础;优化策略;并行计算;深度学习框架
参考资源链接:[深度学习500问:详尽数学基础与核心知识点解析](https://wenku.csdn.net/doc/3ep1kb8j6u?spm=1055.2635.3001.10343)
# 1. GPU在深度学习中的作用
## 1.1 GPU与CPU的对比
在深度学习领域,GPU(图形处理单元)相比于传统的CPU(中央处理单元),提供了更为强大的并行计算能力。CPU擅长处理复杂的逻辑运算,而GPU专为图形渲染和大量的并行数据处理设计。深度学习模型训练过程中涉及大量的矩阵乘法和向量运算,这些都是GPU擅长的领域。
## 1.2 GPU在深度学习中的具体作用
深度学习模型通常包含成千上万甚至数亿个参数,这需要强大的计算能力进行训练。GPU通过其大量的核心(通常以成百上千计),能够同时处理数以千计的并行计算任务,显著加速深度学习模型的训练和推理过程。此外,GPU的可扩展性允许研究者和开发者通过增加更多的GPU来线性提升训练速度,这一点在大数据集上尤为重要。
## 1.3 GPU的经济性与环境适应性
随着深度学习模型变得越来越复杂,对计算资源的需求也日益增长。虽然高性能计算集群提供了巨大的计算能力,但成本也相对较高,这限制了它们的普及性。相比之下,GPU具有更高的成本效益,可以在相对较低的预算内提供必要的计算性能,这使得许多研究者和小型企业也能够进行尖端的深度学习研究。同时,随着数据中心和云服务提供商推出GPU计算服务,深度学习应用得以在更加灵活和环保的环境中运行。
# 2. GPU硬件基础
## 2.1 GPU的架构与性能指标
### 2.1.1 GPU架构简介
GPU(图形处理器)是一种专为大量并行处理而设计的微处理器。它起初是用于加速图形渲染,以处理3D游戏中大量顶点和像素计算。随着时间的推移,GPU架构逐渐发展成为一个强大的计算平台,尤其适用于深度学习中的大规模矩阵运算。
从架构的角度来看,GPU包含有数以百计的核心,能够同时处理多个任务。这些核心被组织成多个Streaming Multiprocessors (SM)或Compute Units。每个SM/CU都包含一组较小的处理单元,如NVIDIA的CUDA核心或AMD的Stream处理器。GPU通过并行处理多个数据集(或称作线程束,warp)来实现高速计算。现代GPU还集成了高级功能,如快速共享内存、高速缓存、以及跨越多个GPU的内存访问。
### 2.1.2 关键性能指标解析
在评估GPU时,有几个关键性能指标需要特别注意:
- **核心数量**:直接影响计算能力,更多的核心能够并行执行更多的任务。
- **时钟速度**:决定GPU每秒可执行指令的次数,以GHz为单位。
- **内存带宽**:GPU处理数据的速度很大程度上取决于它可以多快地读写其专用内存,以GB/s为单位。
- **内存大小**:决定了GPU可以存储和处理的数据量,以GB为单位。
- **浮点运算性能**:在深度学习中,浮点运算能力尤为重要,通常使用TFLOPS(每秒万亿次浮点运算)来衡量。
为了确保GPU能够有效地加速深度学习训练和推理,我们需要选择与任务相匹配的GPU架构,并且充分考虑这些性能指标。
## 2.2 GPU品牌与型号对比
### 2.2.1 主流GPU品牌介绍
目前,市场上主要的GPU品牌有NVIDIA、AMD和Intel(通过收购Habana Labs进入市场)。NVIDIA的GPU以其CUDA技术和针对AI优化的Tensor Core获得了广泛的使用。AMD的GPU虽然市场份额较小,但其开放的ROCm软件平台逐渐吸引了开发者社区的关注。Intel则借助其广泛的CPU生态系统,试图在GPU领域中构建新的计算优势。
### 2.2.2 不同型号GPU的性能对比
不同型号的GPU在性能方面存在显著差异,主要体现在处理能力和能效比上。以NVIDIA为例,高端产品如A100提供了超高的浮点运算能力与内存带宽,适用于大规模深度学习模型训练;而入门级GPU如RTX 2060更侧重于性价比,适合初学者和预算有限的用户。
从AMD和Intel的产品线来看,AMD的Radeon RX 6000系列和Intel的Ponte Vecchio分别提供了在某些方面能与NVIDIA竞争的性能。用户在选择GPU时,需要考虑自己的具体需求,包括成本预算、算法优化需求以及生态系统的兼容性。
## 2.3 GPU扩展与存储
### 2.3.1 多GPU并行计算的优势与挑战
多GPU并行计算能够显著提高深度学习的训练速度,因为数据可以被分布在多个GPU上,每个GPU独立处理一部分数据,然后再同步结果。这种计算模式尤其适合大规模深度学习模型的训练,比如那些需要大规模数据集进行训练的卷积神经网络。
然而,多GPU并行计算也存在挑战。首先是编程复杂性。开发者需要处理GPU之间的数据同步和通信,这需要精心设计算法和数据流。其次是扩展性问题。不同任务的并行化程度不一,对于某些算法而言,简单的数据并行无法实现性能的线性扩展。最后是成本问题。多GPU系统通常需要较高的投资,并且对于维护和电力消耗也提出了更高的要求。
### 2.3.2 GPU内存与存储技术的演进
随着深度学习模型的日益庞大,GPU内存的大小和速度成了性能瓶颈之一。传统的GPU使用GDDR显存,但内存大小有限,速度虽快但价格昂贵。为了突破这一限制,新一代的GPU开始采用更先进的存储技术。
以NVIDIA的A100为例,它采用了HBM2e高带宽内存技术,相比于传统的GDDR显存,HBM技术可以提供更高的内存带宽和更大的内存容量。此外,通过NVLink和PCIe等高速互联技术,可以实现GPU之间的高速内存共享,这在多GPU系统中尤为重要。
在更长远的视角来看,新的内存技术如3D堆叠存储和非易失性内存(NVM)可能会逐步加入GPU架构中,进一步提高内存性能和容量,让深度学习模型能处理更大规模的数据集。这将对整个深度学习领域的发展产生深远的影响。
```mermaid
flowchart LR
A[开始] --> B[了解GPU架构]
B --> C[核心数量]
B --> D[时钟速度]
B --> E[内存带宽]
B --> F[内存大
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《深度学习 500 PDF》专栏提供了全面的深度学习资源,涵盖从数据预处理到模型调优、GPU 加速和正则化等各个方面。它还深入探讨了深度学习在图像识别和自然语言处理中的应用,并比较了 TensorFlow、PyTorch 和 Keras 等流行的深度学习框架。通过该专栏,读者可以获得深入的知识和实用的技巧,以掌握深度学习技术,并将其应用于实际问题。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【国赛C题模型评估全解析】:专家教你如何评价模型性能与准确性

# 摘要
模型评估是机器学习和数据科学中至关重要的环节,它决定了模型的可信度和实际应用的有效性。本文系统地介绍了模型评估的基础知识,包括准确性评估方法、性能验证技术以及模型泛化能力的测试。准确性评估方法涵盖分类和回归模型的性能指标,例如准确率、召回率、F1分数、均方误差和相关系数。验证方法部分详细探讨了交叉验证技术、超参数调优的影响以及模型部署前的最终
【OpenWRT Portal认证速成课】:常见问题解决与性能优化
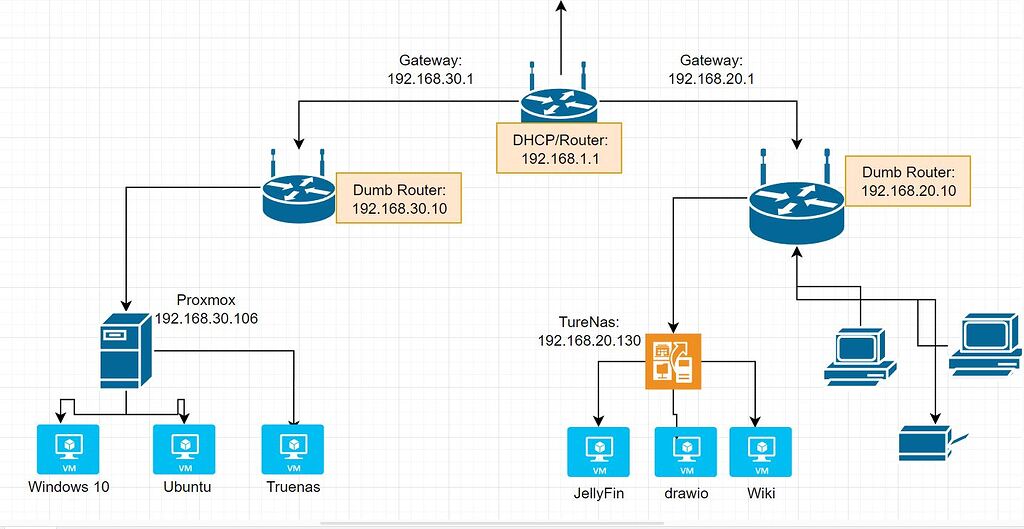
# 摘要
OpenWRT作为一款流行的开源路由器固件,其Portal认证功能在企业与家庭网络中得到广泛应用。本文首先介绍了OpenWRT Portal认证的基本原理和应用场景,随后详述了认证的配置与部署步骤,包括服务器安装、认证页面定制、流程控制参数设置及认证方式配置。为了应对实际应用中可
DROID-SLAM视觉前端详解:视觉里程计与特征提取技术全掌握
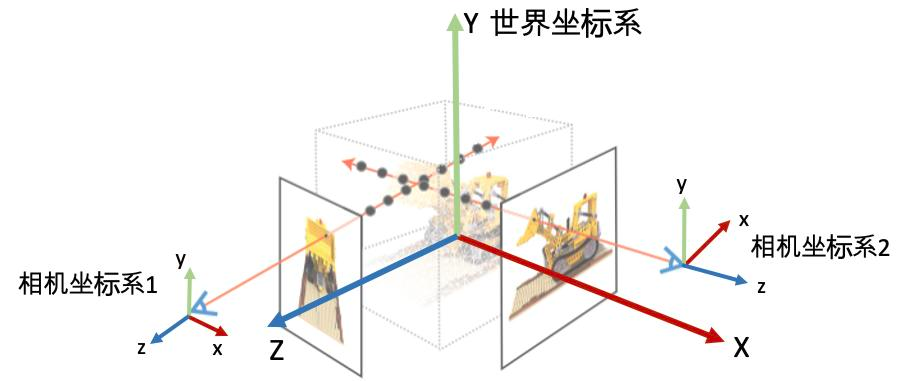
# 摘要
本文全面介绍了DROID-SLAM视觉前端的技术原理与实现方法,并对特征提取技术进行了深入分析。首先概述了DROID-SLAM视觉前端的架构和视觉里程计的基础理论,包括相机成像模型和运动估计基本概念。随后,详细探讨了视觉里程计的关键技术,如特征点检测与匹配,以及相机位姿估计,并通过实际数据集验证了其在真实场景中的应用效果。文中还解析了特征提取技术,包括SIFT和SURF算法原理,特
Tosmana脚本自动化秘技:简化网络管理的高效脚本编写

# 摘要
本文深入探讨了Tosmana脚本自动化技术及其在不同领域的应用。首先,概述了Tosmana脚本自动化的基本概念和配置方法,然后详细介绍了其在网络管理、网络安全和合规性管理方面的具体应用。文章提供了自动化监控、网络设备配置、故障排除、安
S32K SPI驱动开发高级教程:实现高效通信与低功耗设计
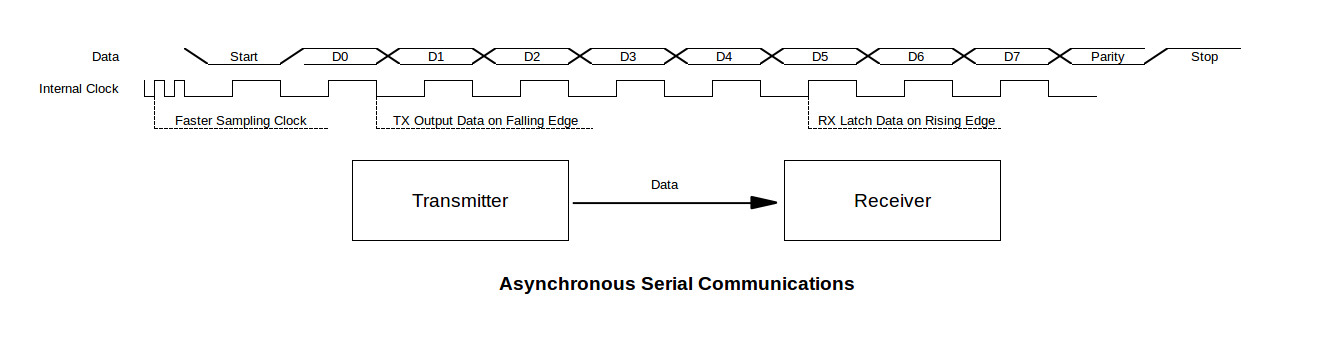
# 摘要
本文全面介绍了基于S32K平台的SPI驱动开发过程,涵盖了硬件接口和寄存器配置、高效通信实践、低功耗设计原理与实践,以及驱动开发的进阶技巧。文章首先介绍了SPI的总线概念、通信协议以及S32K平台下SPI的引脚和电气特性,接着深入探讨了寄存器的配置、性能优化设置和数据传输机制。在此基础上,文章进一步阐述了如何实现高效通信和低功耗策略,并在进阶技巧章节中提供了调试测试、安全性和
兼容性问题克星:让Windows 7 SP1与旧软件无缝协作的秘诀
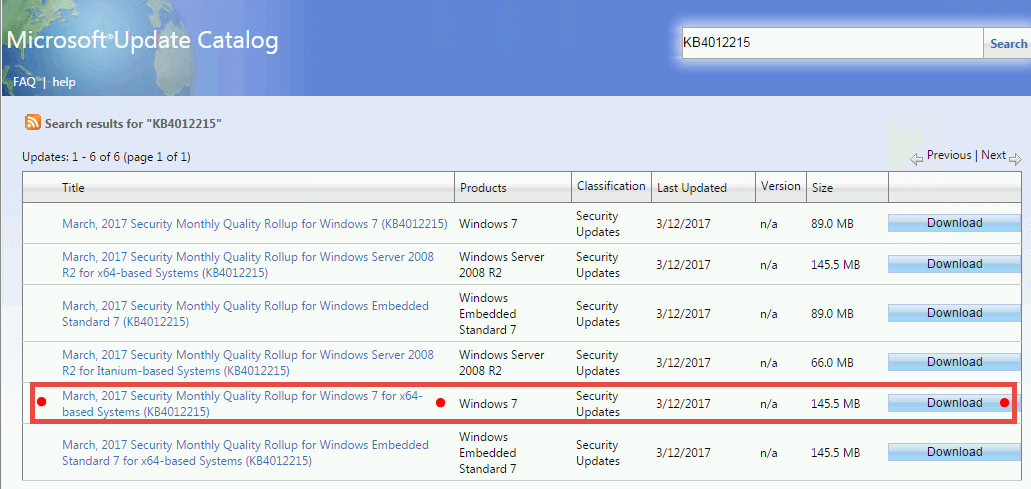
# 摘要
随着技术的不断进步,旧软件在新操作系统上的兼容性问题日益凸显,尤其是在Windows 7 SP1系统中。本文全面分析了旧软件与Windows 7 SP1之间的兼容性问题成因,涵盖基本交互原理、系统更新影响、用户反馈以及安全性和补丁带来的挑战。同时,探讨了解决旧软件兼容性的理论基础,包括兼容性模式、虚拟化技术应用,以及兼容性工具的实际运用。
【Putty与SSH代理】:掌握身份验证问题的处理艺术
# 摘要
随着网络技术的发展,Putty与SSH代理已成为远程安全连接的重要工具。本文从Putty与SSH代理的简介开始,深入探讨了SSH代理的工作原理与配置,包括身份验证机制和高级配置技巧。文章还详细分析了身份验证问题的诊断与解决方法,讨论了密钥管理、安全强化措施以及无密码SSH登录的实现。在高级应用方面,探讨了代理转发、端口转发和自动化脚本中的应用。通过案例研究展示了这些技术在企业环境中的应
【数值计算案例研究】:从速度提量图到性能提升的全过程分析
# 摘要
数值计算是解决科学与工程问题的关键技术,涉及基本概念、理论基础、工具选择、实战案例及性能优化。本文首先介绍数值计算的基本原理、误差、稳定性和离散化方法,然后探讨不同数值算法的分类、选择标准及其设计原则。接着,文章分析了在数值计算中编程语言和计算库的选择、开源工具的优势。通过实战案例分析,本文展示了如何建立数值模型、执行计算过程并评估结果。最后,文章详述了性能
动态规划与购物问题:掌握算法优化的黄金法则

# 摘要
本文全面介绍了动态规划算法的基础知识、理论基础和优化技巧,同时深入探讨了该算法在购物问题中的应用和实践。首先从动态规划的基本概念出发,解析了购物问题并引出理论基础,包括数学原理、经典案例分析以及问题复杂度的计算和优化。随后,文章重点讨论了动态规划算法的优化技巧,如记忆化搜索、剪枝策略和扩展应用。第四章将理论应用于购物问题,包括模型构建、优化策略和实际案例
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )