【MySQL水平扩展】:分区与分表技术深度解析
发布时间: 2024-12-07 10:24:31 阅读量: 9 订阅数: 12 

玉米病叶识别数据集,可识别褐斑,玉米锈病,玉米黑粉病,霜霉病,灰叶斑点,叶枯病等,使用voc对4924张照片进行标注
# 1. MySQL水平扩展的基础概念
在数据库管理领域,MySQL水平扩展是一个关键概念,它涉及通过增加更多服务器来分担数据库负载的技术。这种方式主要解决单体数据库服务器处理能力和存储空间的限制。与垂直扩展(提升单个服务器的硬件性能)不同,水平扩展依赖于在多个服务器之间分散数据和请求。
基础的水平扩展策略包括两种主要形式:分库和分表。分库是将数据分布在多个数据库实例中,每个实例处理不同范围的数据。分表则是将一个数据库的表分解为多个更小、更易于管理的表。在本章节中,我们将先介绍这些基础概念,并进一步深入探讨如何通过分区技术和分表技术来实现MySQL的水平扩展。
在下一章节中,我们将详细探讨分区技术,这是水平扩展中的一项基础且重要的技术,它可以通过逻辑划分数据来简化数据管理和查询优化。
# 2. 分区技术详解
## 2.1 分区的基本原理和类型
### 2.1.1 分区的概念和作用
分区是将一个大表逻辑上划分为多个小表的过程,这些小表在物理存储上相互独立,但逻辑上仍属于原表的组成部分。分区的主要作用是提高数据库的管理效率和性能,特别是在处理大量数据和高并发读写场景时,通过分区可以分散数据和访问压力,优化查询性能。
在分区表中,数据是根据分区键(partitioning key)被分配到不同的分区中。查询时,数据库只会在相关的分区中执行操作,这样可以减少I/O操作次数和提高查询速度。同时,分区还便于数据的维护管理,比如定期清理旧数据或进行分区级别的备份和恢复,从而提升数据操作的效率。
### 2.1.2 常见分区类型:Range, List, Hash, Key
MySQL支持多种分区类型,包括Range分区、List分区、Hash分区和Key分区。每种分区类型适用于不同场景和需求:
- **Range分区**:根据指定的连续区间来分配数据。例如,可以按照日期范围对销售数据进行分区。
- **List分区**:通过明确的值列表来分配数据,通常用于有序的数据集合。它与Range分区类似,但是List分区是明确指定的数据点,而不是一个区间。
- **Hash分区**:使用一个哈希函数来决定数据分配到哪个分区,通常用于均匀分布数据的场景。
- **Key分区**:类似于Hash分区,但是Key分区使用MySQL服务器提供的哈希函数。
每种分区类型都有其适用场景,选择合适的分区策略可以使分区操作更加高效,并且能够提高查询性能。
## 2.2 分区的实践操作
### 2.2.1 创建分区表的语法
创建分区表的基本语法如下:
```sql
CREATE TABLE table_name (
column_list
)
PARTITION BY partition_type (
PARTITION partition_name VALUES LESS THAN (value) [, ...]
);
```
其中,`partition_type`可以是`RANGE`, `LIST`, `HASH`或`KEY`,`partition_name`是分区的名称,`value`是分区的边界值。
举个例子,我们可以创建一个按月份分区的表:
```sql
CREATE TABLE sales (
order_id INT,
order_date DATE,
amount DECIMAL(10, 2),
...
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
```
在这个例子中,`sales`表根据订单日期的年份被分为了三个分区:`p0`包含1990年以前的数据,`p1`包含1990年到1999年之间的数据,`p2`包含2000年及以后的数据。
### 2.2.2 分区维护和管理技巧
分区的维护和管理是确保数据库稳定运行和提高性能的重要环节。以下是几个分区管理的常见操作:
- **添加新分区**:向分区表中添加新的分区以存储更多数据。
- **删除分区**:删除不再需要的数据分区,以释放空间。
- **合并分区**:将多个分区合并为一个分区,用于数据整理和优化。
- **拆分分区**:将一个分区拆分为两个,用于增加分区的灵活性。
执行添加、删除分区的操作可以使用ALTER TABLE语句:
```sql
-- 添加分区
ALTER TABLE table_name ADD PARTITION ...
-- 删除分区
ALTER TABLE table_name DROP PARTITION ...
```
### 2.2.3 分区表的性能考量
分区虽然在很多情况下能提高性能,但并不意味着分区越多越好。分区操作本身是有成本的,它需要在数据访问时决定数据的存储位置,这个过程会带来一定的开销。因此,分区数量应该适度,具体取决于表中的数据量、访问模式和数据库服务器的能力。
另外,合理的分区策略能够减少备份和恢复时间,提高数据迁移的效率,这些都是分区表性能考量的重要方面。
## 2.3 分区应用案例分析
### 2.3.1 数据分布和查询优化
分区的一个典型应用场景是数据分布和查询优化。在一个销售数据表中,我们可能需要分析每个月的销售数据,如果表中存储了多年的数据,没有分区的情况下,查询特定月份的数据效率可能不高。通过按月份进行分区,我们可以把查询限定在特定的分区,大大提高了查询效率。
比如,查询2019年12月的销售数据,查询会仅限于存储2019年12月数据的分区,而不会涉及到其他分区,这样可以显著减少扫描的数据量。
### 2.3.2 分区对备份与恢复的影响
分区对数据库的备份与恢复也有很大的影响。在没有分区的情况下,对大表进行全量备份会占用大量时间和存储资源。而在分区表的情况下,可以针对单个或少量分区进行备份,不仅提高了备份的速度,还降低了存

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据库的使用案例和最佳实践,涵盖广泛的主题,包括:
* 架构设计:打造高效可扩展的数据库系统
* 迁移策略:升级和迁移 MySQL 数据库的最佳实践
* 数据保护:备份和恢复 MySQL 数据的核心策略
* 查询优化:提升查询效率的黄金规则
* 数据库调优:使用分析和调优工具的实战指南
* 高可用性:主从复制和故障转移的实用指南
* 水平扩展:分区和分表技术的深入解析
* 索引管理:高效索引创建和维护的实用技巧
* 日志分析:故障诊断和性能调优的秘密武器
* NoSQL 与 MySQL 融合:混合架构下的数据管理和优化策略
* 数据库逆向工程:从应用代码推导数据库设计
* 数据字典管理:构建高效数据管理平台的方法论
本专栏旨在为数据库管理员、开发人员和架构师提供全面的指导,帮助他们有效地使用 MySQL 数据库,提高性能、可靠性和可扩展性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达PLC DVP32ES2-C终极指南:从安装到高级编程的全面教程
参考资源链接:[台达DVP32ES2-C PLC安装手册:256点I/O扩展与应用指南](https://wenku.csdn.net/doc/64634ae0543f8444889c0bcf?spm=1055.2635.3001.10343)
# 1. 台达PLC DVP32ES2-C基础介绍
台达电子作为全球知名的自动化与电子组件制造商,其PLC(可编程逻辑控制器)产品广泛应用于工业自动化领域。DVP32ES2-C作为台达PL
【九齐8位单片机基础教程】:NYIDE中文手册入门指南
参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐8位单片机概述
九齐8位单片机是一种广泛应用于嵌入式系统和微控制器领域的设备,以其高性能、低功耗、丰富的外设接口以及简单易用的编程环境而著称。本章将概览九齐8位单片机的基础知识
【西门子840 CNC报警速查秘籍】:快速诊断故障,精确锁定PLC变量

参考资源链接:[标准西门子840CNC报警号对应的PLC变量地址](https://wenku.csdn.net/doc/6412b61dbe7fbd1778d45910?spm=1055.2635.3001.10343)
# 1. 西门子840 CNC报警系统概述
## 1.1 CNC报警系统的作用
CNC(Computer Numerical Contro
数据结构基础精讲:算法与数据结构的7大关键关系深度揭秘
参考资源链接:[《数据结构1800题》带目录PDF,方便学习](https://wenku.csdn.net/doc/5sfqk6scag?spm=1055.2635.3001.10343)
# 1. 数据结构与算法的关系概述
数据结构与算法是计算机科学的两大支柱,它们相辅相成,共同为复杂问题的高效解决提供方法论。在这一章中,我们将探讨数据结构与算法的紧密联系,以及为什么理解它
QSGMII性能稳定性测试:掌握核心测试技巧

参考资源链接:[QSGMII接口规范:连接PHY与MAC的高速解决方案](https://wenku.csdn.net/doc/82hgqw0h96?spm=1055.2635.3001.10343)
Nginx HTTPS转HTTP:24个安全设置确保兼容性与性能

参考资源链接:[Nginx https配置错误:https请求重定向至http问题解决](https://wenku.csdn.net/doc/6412b6b5be7fbd1778d47b10?spm=1055.2635.3001.10343)
# 1. Nginx HTTPS转HTTP基础
在这一章中,我们将探索Nginx如何从HTTPS过渡
JVPX连接器设计精要:结构、尺寸与装配的终极指南
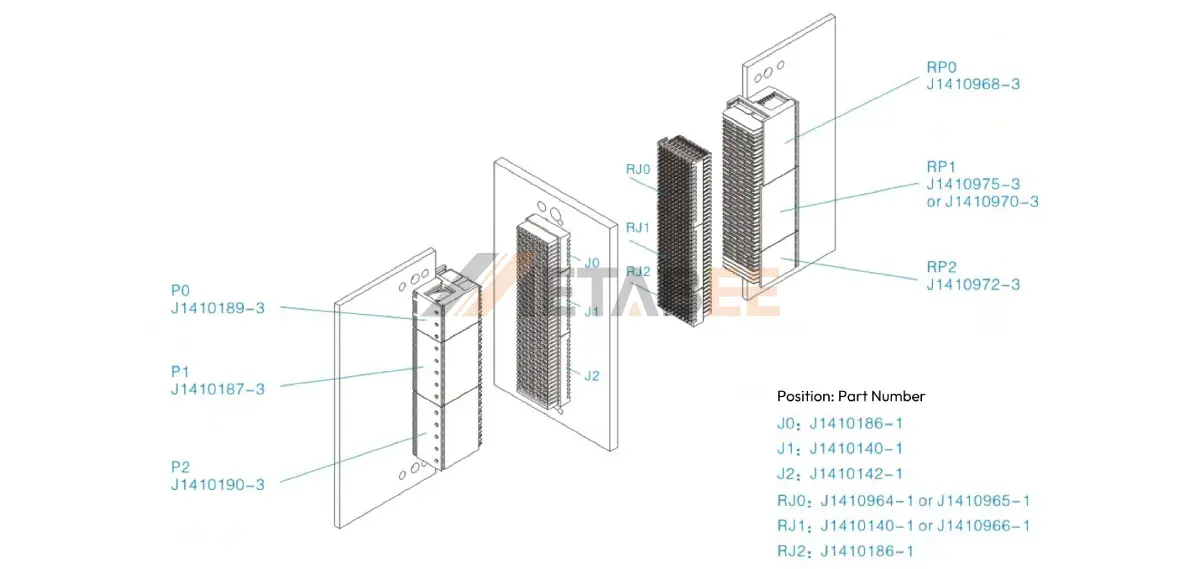
参考资源链接:[航天JVPX加固混装连接器技术规格与优势解析](https://wenku.csdn.net/doc/6459ba7afcc5391368237d7a?spm=1055.2635.3001.10343)
# 1. JVPX连接器概述与市场应用
JVPX连接器作为军事和航天领域广泛使用的一种精密连接器,其设计与应用展现了电子设备连接技术的先进性。本章节将首先探讨JVPX连接
STM32F405RGT6性能全解析:如何优化核心架构与资源管理
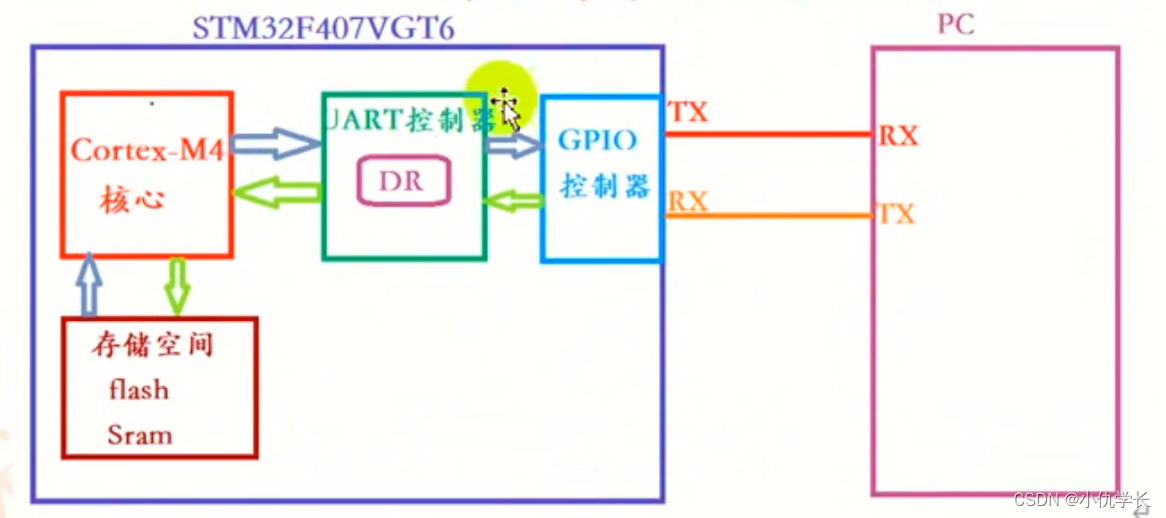
参考资源链接:[STM32F405RGT6中文参考手册:Cortex-M4 MCU详解](https://wenku.csdn.net/doc/6401ad30cce7214c316ee9da?spm=1055.2635.3001.10343)
# 1. STM32F405RGT6核心架构概览
STM32F405RGT6作为ST公司的一款高性能ARM Cortex-M4微控制器,其核心架构的设计是提升整体性能和效
数字集成电路设计实用宝典:第五章应用技巧大公开
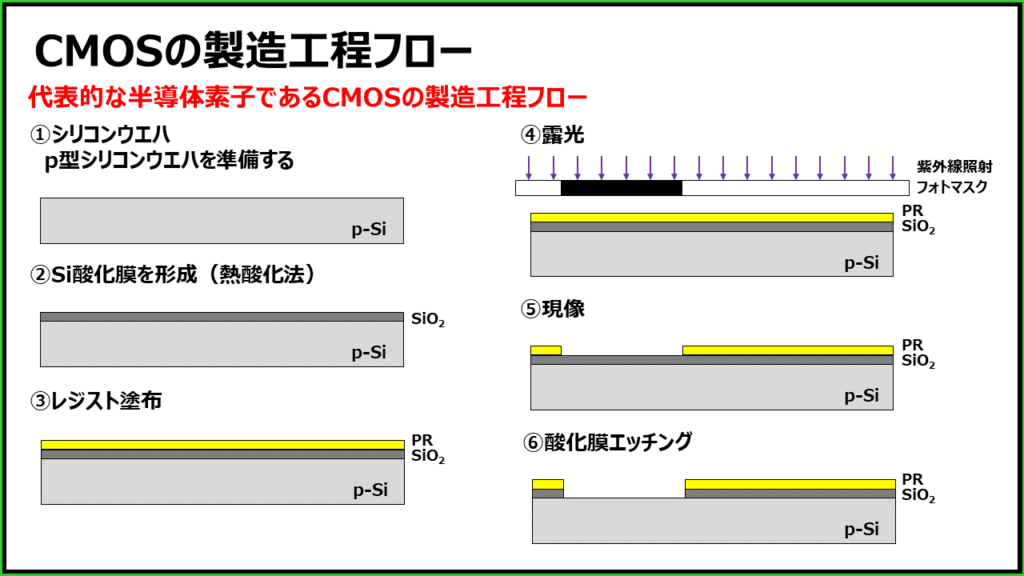
参考资源链接:[数字集成电路设计 第五章答案 chapter5_ex_sol.pdf](https://wenku.csdn.net/doc/64a21b7d7ad1c22e798be8ea?spm=1055.2635.3001.10343)
# 1. 数字集成电路设计基础
## 1.1 概述
数字集成电路是现代电子技术中的核心组件,它利用晶体管的开关特性来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )