HBase数据迁移与复制方案
发布时间: 2024-01-11 08:51:15 阅读量: 49 订阅数: 23 

数据库迁移方案
# 1. 介绍
## 1.1 什么是HBase数据迁移与复制
在大数据领域中,HBase作为NoSQL数据库的一种重要实现,广泛应用于海量数据的存储和实时查询。随着业务需求的变化和技术发展的进步,对于HBase数据的迁移和复制变得越来越重要。
HBase数据迁移是指将数据从一个HBase集群迁移到另一个HBase集群或从其他存储系统迁移到HBase的过程。而HBase数据复制则是指在HBase集群之间实现数据的复制,以实现数据备份、数据灾难恢复、数据分发等功能。
## 1.2 为什么需要数据迁移与复制方案
在实际应用中,存在多种原因需要进行HBase数据迁移与复制,包括但不限于以下几点:
1. 扩容和迁移:随着业务规模的扩大,当现有HBase集群的容量不再满足需求时,需要通过数据迁移的方式将数据迁移到新的集群,以实现集群的扩容和迁移。
2. 备份和灾难恢复:为了保障数据的安全性,需要定期对HBase中的数据进行备份。当遭受意外灾难或数据丢失时,可以通过备份数据进行快速恢复。
3. 数据分发和同步:在分布式系统中,可能存在多个HBase集群需要共享相同的数据。通过数据复制的方式,可以实现数据在多个集群之间的同步和分发。
4. 数据迁移和升级:在HBase升级或更换存储技术时,需要将现有数据迁移到新的系统中,以保证数据的连续性和一致性。
综上所述,数据迁移与复制方案对于保障数据安全、提高系统可用性和扩展能力具有重要意义。接下来,我们将介绍常用的HBase数据迁移方案。
# 2. 常用的HBase数据迁移方案
## 2.1 SQOOP工具
[SQOOP](https://sqoop.apache.org/)是Apache Hadoop生态系统中的一款开源工具,用于在Hadoop和关系型数据库之间进行数据传输。通过使用SQOOP,可以将关系型数据库中的数据导入到HBase中,实现数据迁移的目的。
SQOOP提供了丰富的参数和选项,可以根据需求进行定制化配置。以下是一个使用SQOOP将关系型数据库中的数据导入到HBase的示例代码:
```java
import org.apache.sqoop.SqoopOptions;
import org.apache.sqoop.SqoopRunner;
public class HBaseDataImport {
public static void main(String[] args) {
SqoopOptions options = new SqoopOptions();
options.setConnectString("jdbc:mysql://localhost:3306/mydatabase");
options.setTableName("mytable");
options.setHBaseTable("hbase_table");
options.setHBaseColFamily("cf");
options.setUsername("username");
options.setPassword("password");
SqoopRunner runner = new SqoopRunner(options);
runner.runSqoop(null);
}
}
```
通过以上代码,使用SQOOP将关系型数据库中的`mytable`表的数据导入到HBase中的`hbase_table`表,并指定列族为`cf`。
## 2.2 Hadoop文件系统(HDFS)命令
另一种常用的HBase数据迁移方案是使用Hadoop文件系统(HDFS)命令。HDFS作为Hadoop分布式文件系统,可以通过命令行或脚本方式进行数据的导入和导出。
对于HBase表的数据导入,可以使用以下命令:
```
$ hbase org.apache.hadoop.hbase.mapreduce.Import [options] <tablename> <inputdir>
```
例如,将HDFS上的某个目录中的文件导入到HBase表`mytable`中:
```bash
$ hbase org.apache.hadoop.hbase.mapreduce.Import -Dimporttsv.separator=, mytable /user/hadoop/input/
```
使用HDFS命令进行数据导入的好处是灵活性较高,可以根据需求进行复杂的数据过滤和转换操作。
## 2.3 HBase表间数据导入导出工具
HBase提供了自带的工具类`TableDataImport`和`TableDataExport`用于实现表间数据的导入和导出。
使用`TableDataExport`导出数据的示例代码如下:
```java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.Export;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseTableExport {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "localhost");
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1"));
Export export = new Export(conf, TableName.valueOf("mytable"), new Path("/user/hadoop/output/"));
export.setScan(scan);
export.run();
}
}
```
以上代码将HBase表`mytable`中的数据导出到HDFS的`/user/hadoop/output/`目录中。
## 2.4 其他开源工具的比较
除了上述提到的SQOOP、HDFS命令和HBase自带的工具,还存在一些其他的开源工具可用于HBase数据迁移,如[HBaseImport](https://github.com/apache/hbase/blob/branch-2.4/hbase-server/src/main/java/org/apache/hadoop/hbase/mapreduce/HBaseImport.java)和[Phoenix Bulk Load](https://phoenix.apache.org/bulk_dataload.html)等。选择合适的工具要根据具体需求和场景进行评估和比较,选取性能和可靠性较高的工具进行数据迁移操作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《大数据之hbase详解》深度剖析HBase的各个方面,涵盖了HBase的安装与环境搭建、CRUD操作指南、数据模型详解与实际案例分析、表设计最佳实践、数据写入与读取性能优化策略、数据存储结构解析等多个主题。此外,还包括了HBase的读写原理、数据一致性与并发控制、数据压缩与存储空间优化策略、数据版本管理与数据生命周期控制、数据的过期清理与自动转移、数据备份与恢复策略等内容。同时,本专栏还涉及了HBase集群架构与节点角色、高可用性与故障恢复策略、与Hadoop生态系统的集成与优化、与其他分布式数据库的对比与性能评估、以及与NoSQL数据库的比较与选择指南等内容。无论您是初学者还是有一定经验的HBase用户,本专栏都将为您提供全面深入的专业指导,帮助您更好地理解和运用HBase。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VC709开发板原理图进阶】:深度剖析FPGA核心组件与性能优化(专家视角)

# 摘要
本论文首先对VC709开发板进行了全面概述,并详细解析了其核心组件。接着,深入探讨了FPGA的基础理论及其架构,包括关键技术和设计工具链。文章进一步分析了VC709开发板核心组件,着重于FPGA芯片特性、高速接口技术、热管理和电源设计。此外,本文提出了针对VC709性能优化
IP5306 I2C同步通信:打造高效稳定的通信机制

# 摘要
本文系统地阐述了I2C同步通信的基础原理及其在现代嵌入式系统中的应用。首先,我们介绍了IP5306芯片的功能和其在同步通信中的关键作用,随后详细分析了实现高效稳定I2C通信机制的关键技术,包括通信协议解析、同步通信的优化策略以及IP5306与I2C的集成实践。文章接着深入探讨了IP5306 I2C通信的软件实现,涵盖软件架
Oracle数据库新手指南:DBF数据导入前的准备工作
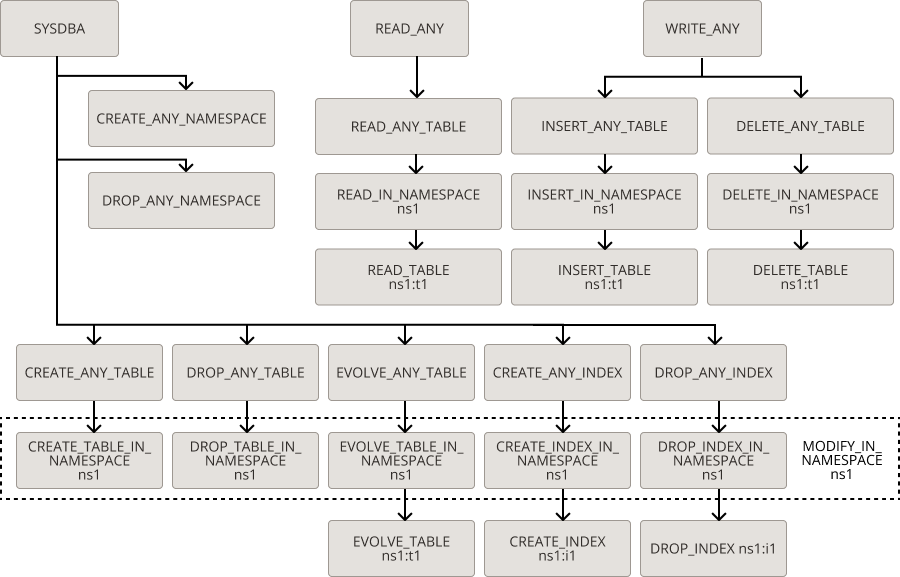
# 摘要
本文旨在详细介绍Oracle数据库的基础知识,并深入解析DBF数据格式及其结构,包括文件发展历程、基本结构、数据类型和字段定义,以及索引和记录机制。同时,本文指导读者进行环境搭建和配置,包括Oracle数据库软件安装、网络设置、用户账户和权限管理。此外,本文还探讨了数据导入工具的选择与使用方法,介绍了SQL
FSIM对比分析:图像相似度算法的终极对决
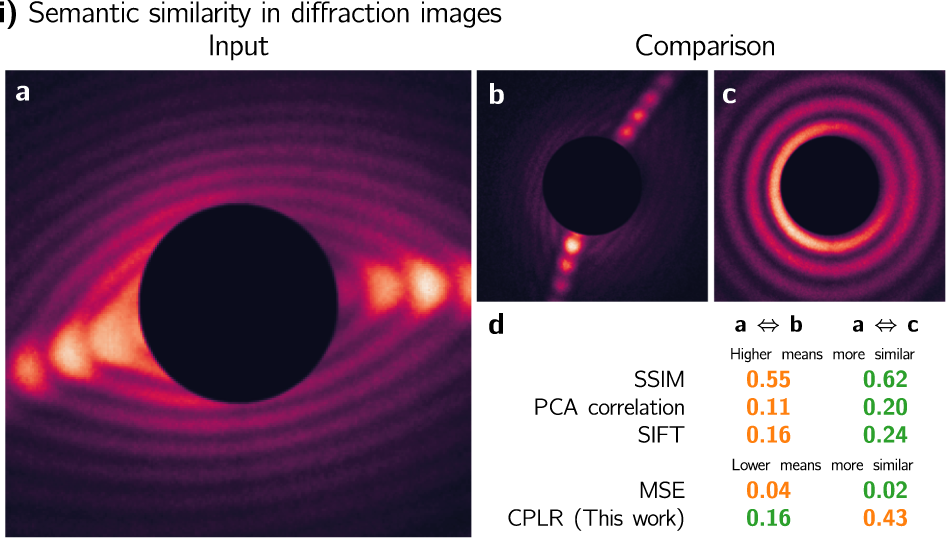
# 摘要
本文首先概述了图像相似度算法的发展历程,重点介绍了FSIM算法的理论基础及其核心原理,包括相位一致性模型和FSIM的计算方法。文章进一步阐述了FSIM算法的实践操作,包括实现步骤和性能测试,并探讨了针对特定应用场景的优化技巧。在第四章中,作者对比分析了FSIM与
应用场景全透视:4除4加减交替法在实验报告中的深度分析
# 摘要
本文综合介绍了4除4加减交替法的理论和实践应用。首先,文章概述了该方法的基础理论和数学原理,包括加减法的基本概念及其性质,以及4除4加减交替法的数学模型和理论依据。接着,文章详细阐述了该方法在实验环境中的应用,包括环境设置、操作步骤和结果分析。本文还探讨了撰写实验报告的技巧,包括报告的结构布局、数据展示和结论撰写。最后,通过案例分析展示了该方法在不同领域的应用,并对实验报告的评价标准与质量提升建议进行了讨论。本文旨在
电子设备冲击测试必读:IEC 60068-2-31标准的实战准备指南
# 摘要
IEC 60068-2-31标准为冲击测试提供了详细的指导和要求,涵盖了测试的理论基础、准备策划、实施操作、标准解读与应用、以及提升测试质量的策略。本文通过对冲击测试科学原理的探讨,分类和方法的分析,以及测试设备和工具的选择,明确了测试的执行流程。同时,强调了在测试前进行详尽策划的重要性,包括样品准备、测试计划的制定以及测试人员的培训。在实际操作中,本
【神经网络】:高级深度学习技术提高煤炭价格预测精度

# 摘要
随着深度学习技术的飞速发展,该技术已成为预测煤炭价格等复杂时间序列数据的重要工具。本文首先介绍了深度学习与煤炭价格预测的基本概念和理论基础,包括神经网络、损失函数、优化器和正则化技术。随后,文章详细探讨了深度学习技术在煤炭价格预测中的具体应用,如数据预处理、模型构建与训练、评估和调优策略。进一步,本文深入分析了高级深度学习技术,包括卷积神经网络(CNN)、循环神经网络(RNN)和长
电子元器件寿命预测:JESD22-A104D温度循环测试的权威解读
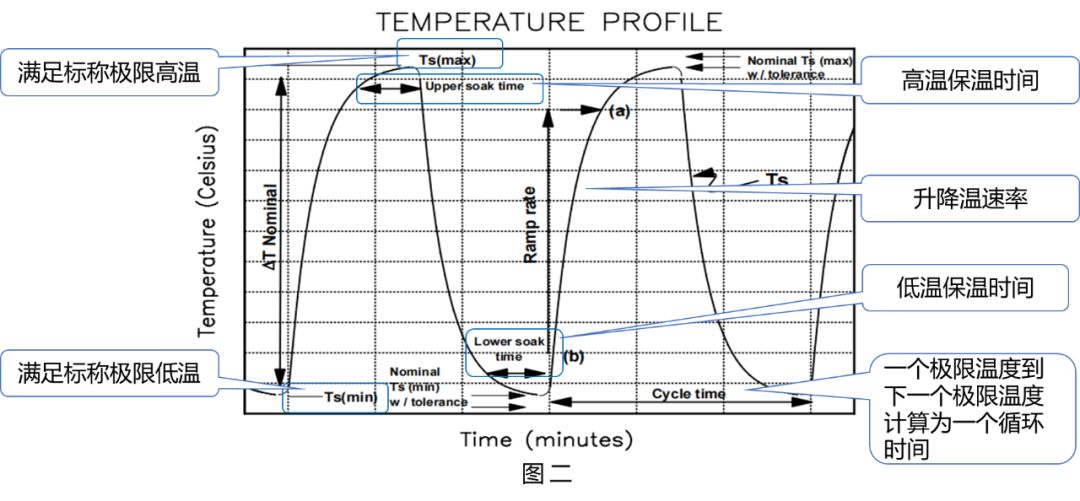
# 摘要
电子元器件在各种电子设备中扮演着至关重要的角色,其寿命预测对于保证产品质量和可靠性至关重要。本文首先概述了电子元器件寿命预测的基本概念,随后详细探讨了JESD22-A104D标准及其测试原理,特别是温度循环测试的理论基础和实际操作方法。文章还介绍了其他加速老化测试方法和寿命预测模型的优化,以及机器学习技术在预测中的应用。通过实际案例分析,本文深入讨论了预测模型的建立与验证。最后,文章展望了未来技术创新、行
【数据库连接池详解】:高效配置Oracle 11gR2客户端,32位与64位策略对比
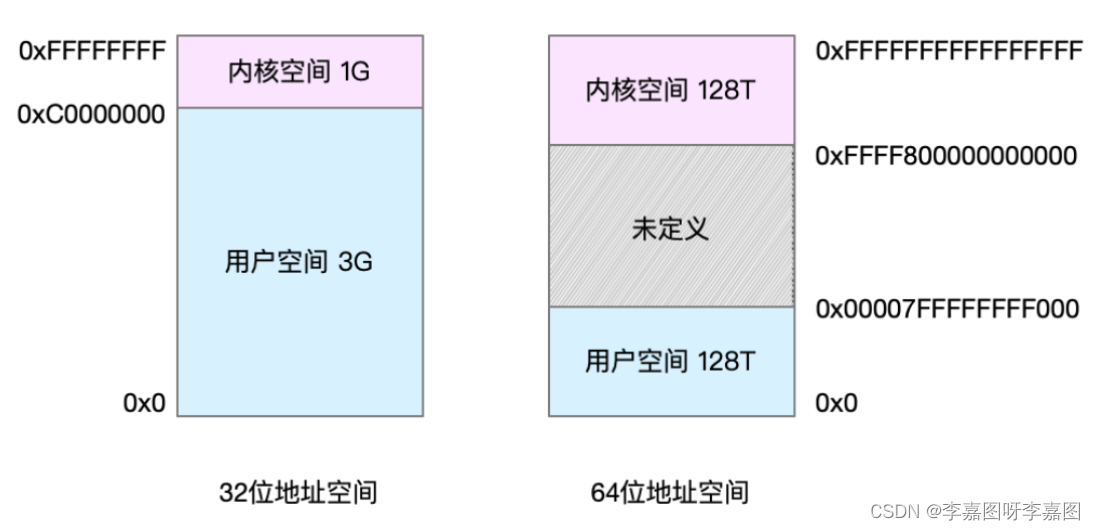
# 摘要
本文对Oracle 11gR2数据库连接池的概念、技术原理、高效配置、不同位数客户端策略对比,以及实践应用案例进行了系统的阐述。首先介绍了连接池的基本概念和Oracle 11gR2连接池的技术原理,包括其架构、工作机制、会话管理、关键技术如连接复用、负载均衡策略和失效处理机制。然后,文章转向如何高效配置Oracle 11gR2连接池,涵盖环境准备、安装步骤、参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )