Ruby on Rails中模型(Model)的定义与操作
发布时间: 2024-02-21 20:28:07 阅读量: 40 订阅数: 15 
# 1. Ruby on Rails中模型(Model)概述
## 1.1 什么是模型(Model)?
在Ruby on Rails中,模型是指对应数据库表的对象表示。它包含了处理数据逻辑和与数据库交互的方法。
## 1.2 模型在Ruby on Rails中的作用
模型在Rails中起着关键作用,它负责处理数据操作、数据验证以及与数据库的交互。
## 1.3 模型和数据库之间的关系
模型和数据库是紧密相关的,每个模型都对应着数据库中的一个表,模型的属性代表了表中的字段。通过模型,我们可以方便地进行对数据库表的操作和管理。
# 2. 创建和定义模型(Model)
在Ruby on Rails中,模型是应用程序的核心部分之一,负责与数据库交互、处理数据逻辑等重要任务。本章我们将深入探讨如何创建和定义模型,包括生成模型的命令、模型属性的定义和数据类型、以及模型关联关系的定义。
### 2.1 生成模型的命令及语法
在Rails中,我们可以使用以下命令来生成一个新的模块:
```ruby
rails generate model ModelName attribute:type attribute:type
```
其中,ModelName表示模型的名称,attribute:type表示模型的属性和数据类型。通过这个命令,Rails会自动生成对应的模型文件、迁移文件以及测试文件。
### 2.2 模型属性的定义和数据类型
在定义模型时,我们需要指定每个属性的数据类型,常用的数据类型包括:
- `string`:字符串类型
- `text`:文本类型
- `integer`:整数类型
- `float`:浮点数类型
- `boolean`:布尔类型
- `datetime`:日期时间类型
- `date`:日期类型
我们可以在模型文件中使用以下语法定义属性:
```ruby
class User < ApplicationRecord
validates :name, presence: true
end
```
在上面的代码中,我们定义了一个User模型,并指定了name属性为必填项。
### 2.3 模型关联关系的定义
在Rails中,模型之间可以建立各种类型的关联关系,包括一对一、一对多、多对多等。我们可以通过以下方式定义关联关系:
```ruby
class User < ApplicationRecord
has_many :posts
end
class Post < ApplicationRecord
belongs_to :user
end
```
在上面的代码中,我们定义了User模型拥有多个Post模型的关联关系,而Post模型属于一个User模型。
通过以上内容,我们学习了如何在Ruby on Rails中创建和定义模型,下一章节将介绍模型的数据操作。
# 3. 模型的数据操作
在Ruby on Rails中,模型是处理应用程序的数据逻辑的关键部分。在这个章节中,我们将详细介绍如何使用Active Record进行模型的数据操作,包括查询、创建、更新和删除数据等操作。
#### 3.1 查询数据:使用Active Record进行数据库查询
在Rails中,我们可以使用Active Record提供的方法来进行数据库查询。比如,要查询名为User的模型中年龄大于18岁的所有用户,可以使用以下代码:
```ruby
# 查询年龄大于18岁的所有用户
@adult_users = User.where('age > ?', 18)
```
在上面的例子中,`User`是模型名,`where`是Active Record提供的查询方法。在实际使用中,我们可以根据需要使用不同的查询方法来获取需要的数据,比如`find_by`、`order`、`pluck`等。
#### 3.2 创建数据:向数据库表中插入新的记录
如果我们想要向数据库中的表插入新的记录,可以使用模型的`create`方法。例如,如果我们有一个名为`Article`的模型,可以使用以下代码创建一篇新的文章:
```ruby
# 创建一篇新的文章
@new_article = Article.create(title: 'Ruby on Rails Guide', content: 'This is a guide to Ruby on Rails.')
```
上面的代码中,`create`方法会在数据库中插入一条新的记录,并返回创建的对象。
#### 3.3 更新数据:修改数据库中已有的记录
要更新数据库中已有的记录,我们可以使用模型实例的`update`方法。假设我们需要把上面创建的文章的标题进行修改,可以使用以下代码:
```ruby
# 修改文章的标题
@new_article.update(title: 'Ruby on Rails Tutorial')
```
在上面的例子中,`update`方法会修改数据库中对应记录的数据。
#### 3.4 删除数据:从数据库中删除记录
最后,要从数据库中删除记录,可以使用模型实例的`destroy`方法。例如,如果我们想要删除某篇文章,可以使用以下代码:
```ruby
# 删除文章
@new_article.destroy
```
以上就是在Ruby on Rails中对模型进行数据操作的基本方法,下一节我们将进一步讨论模型的验证与回调方法。
# 4. 模型的验证与回调
在Ruby on Rails中,模型的验证与回调是非常重要的概念,可以确保数据的有效性并且在操作数据时执行相应的逻辑。下面我们将详细讨论模型的验证与回调方法:
#### 4.1 数据验证
在模型中进行数据验证是一种保证数据完整性和有效性的重要方式。通过在模型中定义验证规则,我们可以确保数据库中存储的数据符合特定的条件。下面是一个简单的例子,假设我们有一个`User`模型,需要确保`name`字段不能为空:
```ruby
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true
end
```
在上面的例子中,我们通过`validates`方法定义了对`name`字段的验证规则,即不能为空。当我们创建或更新`User`记录时,Rails会自动执行这些验证规则。
#### 4.2 回调方法
与数据验证类似,回调方法是在模型生命周期中特定时间点执行的方法。这些方法可以在记录保存、更新或删除时执行,以便执行相应的逻辑。下面是一个示例,假设在`User`保存之前需要执行某些逻辑:
```ruby
# app/models/user.rb
class User < ApplicationRecord
before_save :do_something
private
def do_something
# 在保存用户之前执行的逻辑
puts "Do something before save"
end
end
```
在上面的例子中,我们使用`before_save`回调方法在保存`User`记录之前执行`do_something`方法。这样我们就可以在模型中控制记录保存前后的处理逻辑。
#### 4.3 自定义验证器和回调方法
除了内置的验证器和回调方法外,我们还可以定义自己的验证器和回调方法来满足特定需求。例如,我们可以编写自定义的验证器来验证字段的复杂规则,或者定义自定义的回调方法来执行特定的业务逻辑。
```ruby
# app/models/user.rb
class User < ApplicationRecord
validate :custom_validation
private
def custom_validation
errors.add(:base, "Custom validation error message") if some_condition
end
end
```
在上面的例子中,我们定义了一个自定义的验证方法`custom_validation`,根据特定条件判断是否添加错误信息。这样我们可以灵活地定义各种验证规则来确保数据的有效性。
通过合理使用数据验证和回调方法,我们可以在Ruby on Rails中构建健壮的模型,确保数据的正确性并实现业务逻辑的处理。
# 5. 模型操作的进阶技巧
在这一章节中,我们将探讨Ruby on Rails中模型操作的一些进阶技巧,让我们更加高效地处理数据和业务逻辑。
### 5.1 使用作用域(scope)进行数据过滤
作用域(scope)是一种非常强大的功能,它允许我们定义特定的查询逻辑,以便在多个地方重复使用。通过定义作用域,我们可以将常见的查询逻辑封装起来,提高代码的可复用性和可维护性。
```ruby
# 在模型中定义作用域
class Post < ApplicationRecord
scope :published, -> { where(published: true) }
scope :recent, -> { where('created_at > ?', 1.week.ago) }
end
# 在控制器中使用作用域
class PostsController < ApplicationController
def index
@published_posts = Post.published
@recent_posts = Post.recent
end
end
```
**代码总结:**
- 通过定义作用域,可以轻松过滤出符合条件的数据集。
- 作用域可以链式调用,组合多个条件来获取更精确的数据集。
- 作用域可以提高代码的可读性和可维护性。
**结果说明:**
- 通过作用域过滤数据,可以更轻松地实现对特定数据集的操作,提高代码的效率和可维护性。
### 5.2 模型方法的定义和使用
除了使用作用域外,我们还可以在模型中自定义方法来处理一些特定的业务逻辑。这些方法可以用于数据处理、逻辑计算等操作。
```ruby
# 在模型中定义自定义方法
class User < ApplicationRecord
def full_name
"#{self.first_name} #{self.last_name}"
end
def can_edit_post?(post)
self == post.author
end
end
# 在控制器或视图中使用自定义方法
@user = User.find(1)
puts @user.full_name
@post = Post.find(1)
puts @user.can_edit_post?(@post)
```
**代码总结:**
- 可以在模型中定义自定义方法来处理特定的业务逻辑。
- 自定义方法可以直接在实例对象上调用,执行相关操作。
- 自定义方法可以让代码更加模块化和易于维护。
**结果说明:**
- 通过自定义方法,可以实现模型的更加灵活和具有定制性的功能,提高代码的可读性和可维护性。
### 5.3 对模型进行测试的最佳实践
在开发过程中,对模型进行测试是非常重要的,可以确保模型方法的正确性和稳定性。下面是一些对模型进行测试的最佳实践:
- 使用测试框架(如RSpec、Minitest)编写单元测试和集成测试。
- 涵盖模型的所有方法和边界情况,确保覆盖率高。
- 使用fixture或factory_bot创建测试数据,保持测试的独立性和可重复性。
- 使用assertions(断言)验证模型方法的预期行为,确保代码的准确性。
通过遵循这些最佳实践,可以有效地保证模型的质量和稳定性,提高代码的可靠性和可维护性。
# 6. 性能优化和安全性考虑
在开发Ruby on Rails应用程序时,除了功能实现之外,性能优化和安全性考虑也是非常重要的方面。通过合理的优化和安全策略,可以提升应用程序的用户体验和数据安全性。
#### 6.1 数据库索引的优化
数据库索引是提高数据库查询性能的重要手段之一。在模型中使用索引可以加快查询速度,尤其对于大型数据集来说效果更为明显。在Rails中,可以通过迁移文件来为特定的字段添加索引,例如:
```ruby
class AddIndexToUsersEmail < ActiveRecord::Migration[6.0]
def change
add_index :users, :email, unique: true
end
end
```
上面的例子中为用户表的email字段添加了唯一索引,确保email的唯一性,提高查询效率。
#### 6.2 防止数据注入和XSS攻击
在处理用户输入数据时,务必要防止数据注入和跨站脚本攻击(XSS)等安全问题。Rails提供了强大的参数过滤和安全验证机制,如参数化查询、表单验证等,可以有效防范潜在的安全风险。例如,在控制器中使用Strong Parameters对用户提交的参数进行过滤:
```ruby
class UsersController < ApplicationController
def create
@user = User.new(user_params)
# ...
end
private
def user_params
params.require(:user).permit(:username, :email, :password)
end
end
```
上述代码中使用Strong Parameters只允许传入user模型中的指定参数,避免不必要的参数被提交。
#### 6.3 缓存技巧和数据库查询优化
为了提高应用程序的性能,我们可以利用缓存技巧和数据库查询优化策略。Rails内置了缓存机制,如Fragment Caching、Page Caching等,可以缓存页面片段或整个页面,减少数据库访问次数,优化性能。同时,可以通过N+1查询问题解决方案,如includes或joins方法来减少不必要的数据库查询。
综上所述,通过合理配置和优化数据库索引、防止安全漏洞、利用缓存和提高查询效率,可以有效改善Ruby on Rails应用程序的性能和安全性,提升用户体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Ruby on Rails网络框架》专栏深入探讨了在Web开发中广泛应用的Ruby on Rails框架。通过一系列文章,专栏全面介绍了在Ruby on Rails中的关键概念和技术,包括路由配置、控制器的作用与使用、模型的定义与操作、数据迁移与数据库操作、表单处理与验证技巧、关联模型与数据关系建立、性能优化与缓存机制、异常处理与日志记录技术、前端框架整合与开发实践、持续集成与部署流程,以及安全防护与漏洞修复。读者将通过本专栏全面了解如何在Ruby on Rails框架下构建高效、可靠、安全的Web应用程序,从而提升他们的开发技能和实践经验。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【formatR包兼容性分析】:确保你的R脚本在不同平台流畅运行
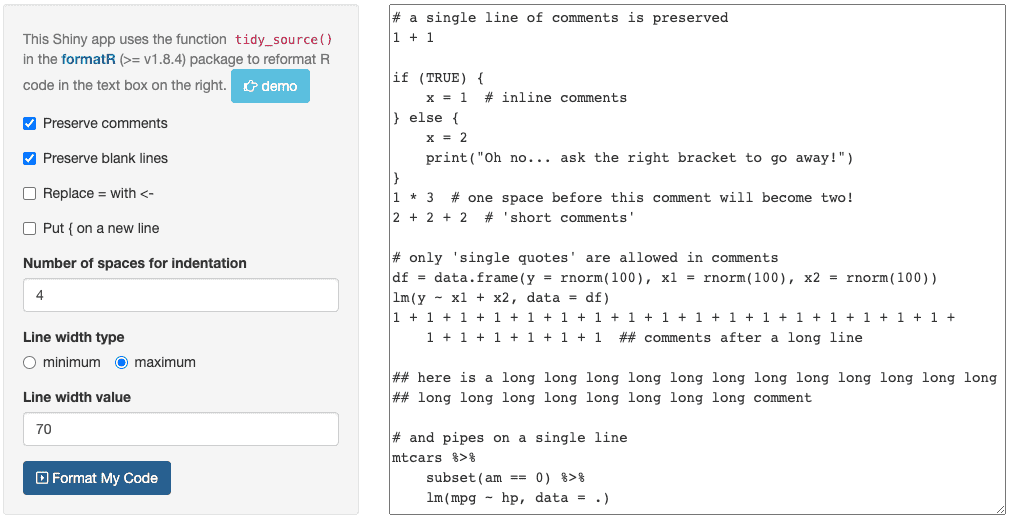
# 1. formatR包简介与安装配置
## 1.1 formatR包概述
formatR是R语言的一个著名包,旨在帮助用户美化和改善R代码的布局和格式。它提供了许多实用的功能,从格式化代码到提高代码可读性,它都是一个强大的辅助工具。通过简化代码的外观,formatR有助于开发人员更快速地理解和修改代码。
## 1.2 安装formatR
安装formatR包非常简单,只需打开R控制台并输入以下命令:
```R
install.pa
R语言数据处理高级技巧:reshape2包与dplyr的协同效果
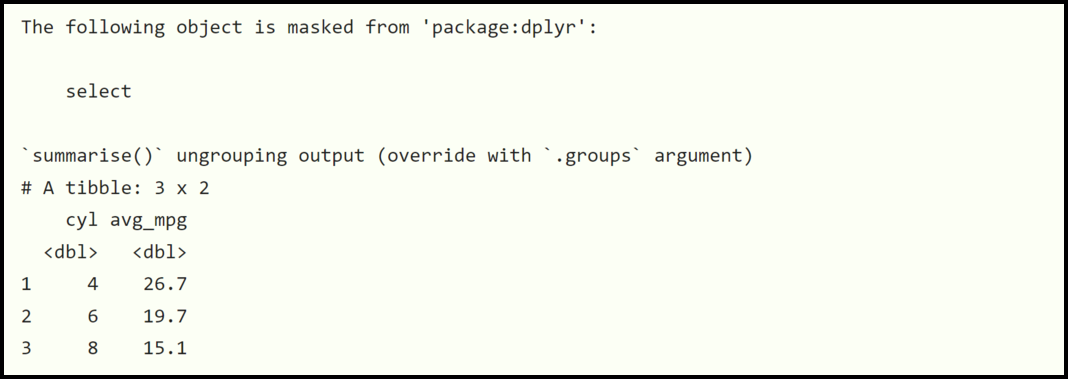
# 1. R语言数据处理概述
在数据分析和科学研究中,数据处理是一个关键的步骤,它涉及到数据的清洗、转换和重塑等多个方面。R语言凭借其强大的统计功能和包生态,成为数据处理领域的佼佼者。本章我们将从基础开始,介绍R语言数据处理的基本概念、方法以及最佳实践,为后续章节中具体的数据处理技巧和案例打下坚实的基础。我们将探讨如何利用R语言强大的包和
【R语言Capet包集成挑战】:解决数据包兼容性问题与优化集成流程
# 1. R语言Capet包集成概述
随着数据分析需求的日益增长,R语言作为数据分析领域的重要工具,不断地演化和扩展其生态系统。Capet包作为R语言的一个新兴扩展,极大地增强了R在数据处理和分析方面的能力。本章将对Capet包的基本概念、功能特点以及它在R语言集成中的作用进行概述,帮助读者初步理解Capet包及其在
时间数据统一:R语言lubridate包在格式化中的应用

# 1. 时间数据处理的挑战与需求
在数据分析、数据挖掘、以及商业智能领域,时间数据处理是一个常见而复杂的任务。时间数据通常包含日期、时间、时区等多个维度,这使得准确、高效地处理时间数据显得尤为重要。当前,时间数据处理面临的主要挑战包括但不限于:不同时间格式的解析、时区的准确转换、时间序列的计算、以及时间数据的准确可视化展示。
为应对这些挑战,数据处理工作需要满足以下需求:
R语言数据透视表创建与应用:dplyr包在数据可视化中的角色

# 1. dplyr包与数据透视表基础
在数据分析领域,dplyr包是R语言中最流行的工具之一,它提供了一系列易于理解和使用的函数,用于数据的清洗、转换、操作和汇总。数据透视表是数据分析中的一个重要工具,它允许用户从不同角度汇总数据,快速生成各种统计报表。
数据透视表能够将长格式数据(记录式数据)转换为宽格式数据(分析表形式),从而便于进行
从数据到洞察:R语言文本挖掘与stringr包的终极指南

# 1. 文本挖掘与R语言概述
文本挖掘是从大量文本数据中提取有用信息和知识的过程。借助文本挖掘,我们可以揭示隐藏在文本数据背后的信息结构,这对于理解用户行为、市场趋势和社交网络情绪等至关重要。R语言是一个广泛应用于统计分析和数据科学的语言,它在文本挖掘领域也展现出强大的功能。R语言拥有众多的包,能够帮助数据科学
R语言复杂数据管道构建:plyr包的进阶应用指南

# 1. R语言与数据管道简介
在数据分析的世界中,数据管道的概念对于理解和操作数据流至关重要。数据管道可以被看作是数据从输入到输出的转换过程,其中每个步骤都对数据进行了一定的处理和转换。R语言,作为一种广泛使用的统计计算和图形工具,完美支持了数据管道的设计和实现。
R语言中的数据管道通常通过特定的函数来实现
【R语言数据包mlr的深度学习入门】:构建神经网络模型的创新途径

# 1. R语言和mlr包的简介
## 简述R语言
R语言是一种用于统计分析和图形表示的编程语言,广泛应用于数据分析、机器学习、数据挖掘等领域。由于其灵活性和强大的社区支持,R已经成为数据科学家和统计学家不可或缺的工具之一。
## mlr包的引入
mlr是R语言中的一个高性能的机器学习包,它提供了一个统一的接口来使用各种机器学习算法。这极大地简化了模型的选择、训练
【R语言MCMC探索性数据分析】:方法论与实例研究,贝叶斯统计新工具
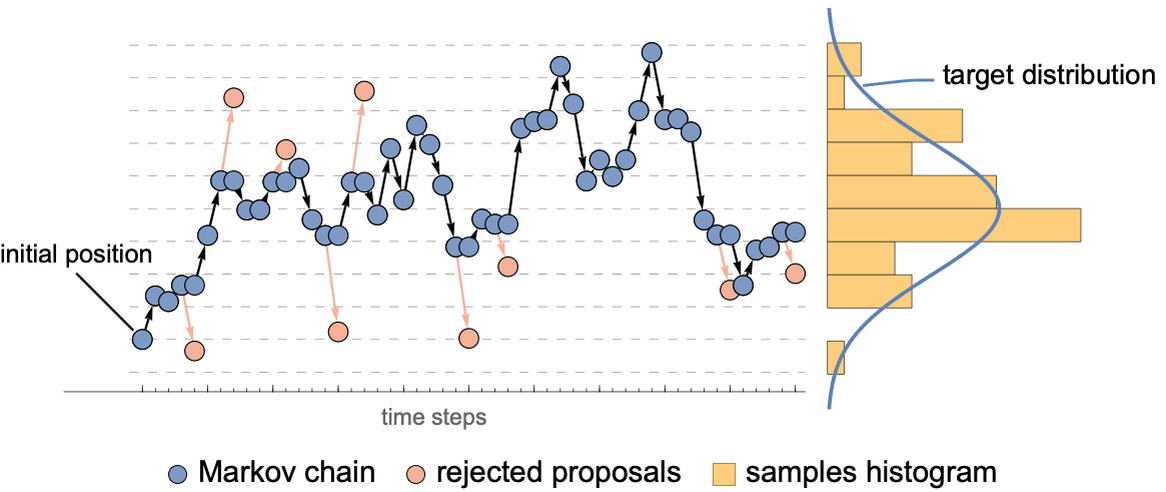
# 1. MCMC方法论基础与R语言概述
## 1.1 MCMC方法论简介
**MCMC (Markov Chain Monte Carlo)** 方法是一种基于马尔可夫链的随机模拟技术,用于复杂概率模型的数值计算,特别适用于后验分布的采样。MCMC通过构建一个马尔可夫链,
【R语言高级技巧】:data.table包的进阶应用指南

# 1. data.table包概述与基础操作
## 1.1 data.table包简介
data.table是R语言中一个强大的包,用于高效数据处理和分析。它以`data.table`对象的形式扩展了数据框(`data.frame`)的功能,提供了更快的数据读写速度,更节省内存的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )