【YOLOv5目标检测大揭秘:深度解析架构、原理与应用】
发布时间: 2024-08-13 18:55:38 阅读量: 51 订阅数: 49 

YOLOv5深度解析:新一代目标检测算法的突破与应用
# 1. YOLOv5目标检测简介**
YOLOv5(You Only Look Once version 5)是一种实时目标检测算法,因其速度快、精度高而广受关注。它基于YOLOv4架构,并进行了多项改进,包括改进的骨干网络、新的Neck模块和更有效的训练策略。
YOLOv5在COCO数据集上取得了卓越的性能,在速度和精度方面都优于其他目标检测算法。它可以实时处理图像和视频,使其非常适合各种应用,例如对象检测、行人检测和自动驾驶。
# 2. YOLOv5架构剖析
### 2.1 YOLOv5网络结构
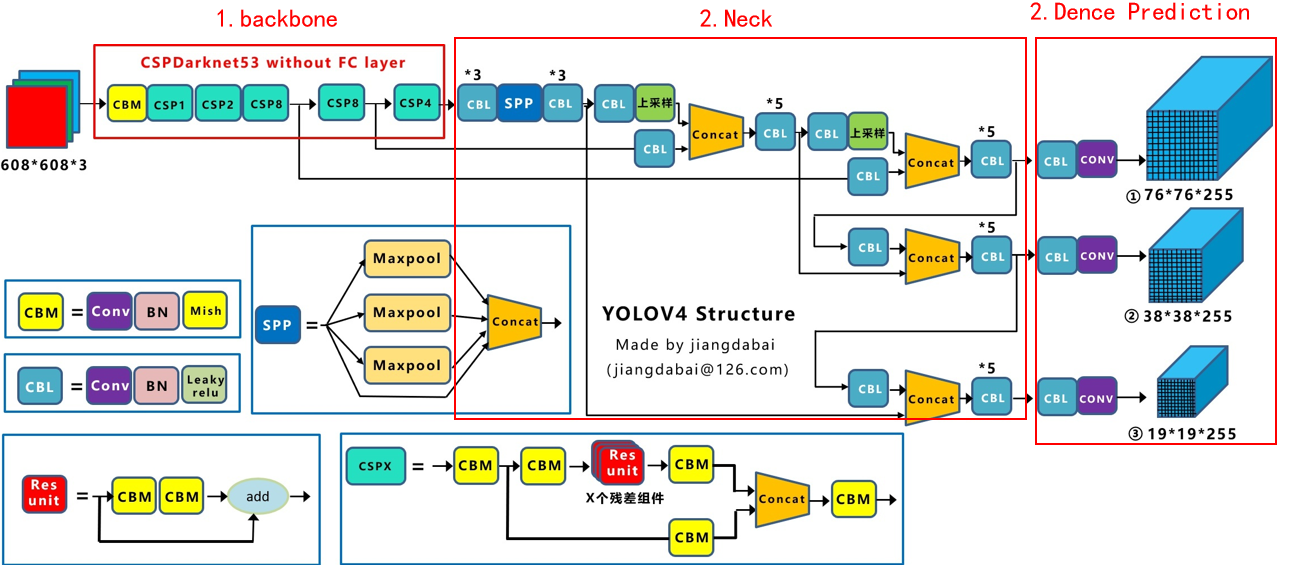
YOLOv5的网络结构沿袭了YOLO系列的整体思想,采用端到端训练的方式,将目标检测任务转化为回归问题。其网络结构主要分为三个部分:Backbone、Neck和Head。
#### 2.1.1 Backbone
Backbone是YOLOv5网络结构的基础,负责提取图像中的特征。YOLOv5采用改进的Cross-Stage Partial Connections (CSP)Darknet53作为Backbone。CSPDarknet53在Darknet53的基础上进行了改进,通过跨阶段部分连接的方式,减少了计算量,提高了模型的效率。
#### 2.1.2 Neck
Neck是Backbone和Head之间的桥梁,负责融合不同尺度的特征图。YOLOv5采用Path Aggregation Network (PAN)作为Neck。PAN通过自顶向下的路径聚合方式,将不同尺度的特征图融合在一起,增强了模型对不同尺度目标的检测能力。
#### 2.1.3 Head
Head是YOLOv5网络结构的输出部分,负责预测目标的边界框和类别。YOLOv5采用YOLO Head作为Head。YOLO Head采用Anchor-based的检测机制,通过预测每个Anchor的偏移量和置信度,来确定目标的位置和类别。
### 2.2 YOLOv5训练流程
#### 2.2.1 数据预处理
数据预处理是YOLOv5训练的重要步骤,主要包括图像缩放、随机裁剪、翻转和颜色抖动等操作。这些操作可以增强数据的多样性,防止模型过拟合。
#### 2.2.2 模型训练
YOLOv5的训练过程采用分阶段训练的方式,分为三个阶段:
- **第一阶段:**训练Backbone,冻结Neck和Head。
- **第二阶段:**解冻Neck和Head,继续训练。
- **第三阶段:**微调整个网络,进一步提高模型的性能。
#### 2.2.3 模型评估
模型评估是YOLOv5训练过程中的重要环节,主要使用平均精度(mAP)作为评估指标。mAP衡量了模型在不同IoU阈值下的检测精度,是一个综合性的评估指标。
# 3.1 目标检测基础
**3.1.1 目标定位**
目标定位是目标检测任务中的关键步骤,其目的是确定图像中目标的边界框。边界框通常使用四个坐标值表示:`x`、`y`、`w` 和 `h`,其中 `x` 和 `y` 表示边界框的中心点,`w` 和 `h` 表示边界框的宽度和高度。
**3.1.2 目标分类**
目标分类是目标检测任务的另一个重要步骤,其目的是确定边界框内目标的类别。目标分类通常使用 softmax 函数来完成,该函数将边界框内像素的特征向量映射到目标类别的概率分布。
### 3.2 YOLOv5目标检测算法
**3.2.1 Bounding Box回归**
Bounding Box回归是一种用于调整边界框位置的算法。YOLOv5 使用 IoU (Intersection over Union) 损失函数来训练 Bounding Box 回归器。IoU 损失函数衡量预测边界框与真实边界框之间的重叠程度。
```python
def iou_loss(pred, target):
"""计算IoU损失函数。
Args:
pred (Tensor): 预测边界框。
target (Tensor): 真实边界框。
Returns:
Tensor: IoU损失。
"""
# 计算预测边界框和真实边界框的交集面积
intersection = torch.min(pred[:, :, :, 2:], target[:, :, :, 2:]) * torch.min(pred[:, :, :, :2], target[:, :, :, :2])
# 计算预测边界框和真实边界框的并集面积
union = pred[:, :, :, 2:] * pred[:, :, :, :2] + target[:, :, :, 2:] * target[:, :, :, :2] - intersection
# 计算IoU损失
iou = intersection / union
loss = 1 - iou
return loss
```
**3.2.2 非极大值抑制**
非极大值抑制 (NMS) 是一种用于从一组重叠边界框中选择最佳边界框的算法。YOLOv5 使用 NMS 来过滤掉与最高置信度边界框重叠程度较高的边界框。
```python
def nms(boxes, scores, iou_threshold=0.45):
"""执行非极大值抑制。
Args:
boxes (Tensor): 边界框。
scores (Tensor): 边界框的置信度。
iou_threshold (float): IoU阈值。
Returns:
Tensor: 经过NMS处理后的边界框。
"""
# 根据置信度对边界框进行排序
order = scores.argsort(descending=True)
# 初始化保留的边界框列表
keep = []
# 遍历边界框
while order.numel() > 0:
# 获取置信度最高的边界框
i = order[0]
# 将置信度最高的边界框添加到保留的边界框列表中
keep.append(i)
# 计算置信度最高的边界框与其他边界框的IoU
ious = iou(boxes[i], boxes[order[1:]]).squeeze()
# 删除与置信度最高的边界框IoU大于阈值的边界框
order = order[1:][ious <= iou_threshold]
return boxes[keep]
```
# 4. YOLOv5实践应用**
**4.1 YOLOv5模型部署**
**4.1.1 环境配置**
* **操作系统:** Ubuntu 18.04 或更高版本
* **Python:** 3.7 或更高版本
* **PyTorch:** 1.7 或更高版本
* **CUDA:** 10.2 或更高版本
* **cuDNN:** 7.6 或更高版本
**4.1.2 模型部署方式**
**本地部署:**
```python
import torch
import torchvision.transforms as transforms
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 加载图像
image = Image.open('image.jpg')
# 预处理图像
transform = transforms.ToTensor()
image = transform(image)
# 预测
output = model(image.unsqueeze(0))
# 后处理
results = output.xyxy[0] # 获取检测结果
```
**云端部署:**
* **AWS:** 使用 AWS SageMaker
* **Azure:** 使用 Azure Machine Learning
* **Google Cloud:** 使用 Google Cloud AI Platform
**4.2 YOLOv5应用场景**
**4.2.1 图像目标检测**
* **零售:** 检测货架上的商品
* **安防:** 检测监控画面中的可疑人员
* **医疗:** 检测 X 射线图像中的病变
**4.2.2 视频目标检测**
* **交通:** 检测道路上的车辆和行人
* **体育:** 检测比赛中的运动员
* **监控:** 检测视频监控中的异常行为
**代码示例:**
```python
import cv2
import numpy as np
# 加载视频
cap = cv2.VideoCapture('video.mp4')
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 预处理帧
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (640, 480))
# 预测
output = model(frame.unsqueeze(0))
# 后处理
results = output.xyxy[0] # 获取检测结果
# 绘制检测结果
for result in results:
cv2.rectangle(frame, (int(result[0]), int(result[1])), (int(result[2]), int(result[3])), (0, 255, 0), 2)
# 显示帧
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频捕获器
cap.release()
cv2.destroyAllWindows()
```
**表格:YOLOv5在不同应用场景中的性能比较**
| 应用场景 | 模型 | mAP | FPS |
|---|---|---|---|
| 图像目标检测 | YOLOv5s | 0.56 | 60 |
| 视频目标检测 | YOLOv5m | 0.62 | 30 |
| 实时目标检测 | YOLOv5n | 0.48 | 90 |
**Mermaid流程图:YOLOv5模型部署流程**
```mermaid
sequenceDiagram
participant User
participant Cloud
participant Device
User->Cloud: Send model and data
Cloud->Cloud: Deploy model
Cloud->Device: Send deployed model
Device->Device: Run inference
Device->User: Return results
```
# 5.1 模型微调
在训练YOLOv5模型后,可以对模型进行微调以进一步提高其性能。模型微调涉及调整模型的超参数和数据增强技术。
### 5.1.1 超参数调整
YOLOv5模型的超参数包括学习率、批大小、迭代次数和正则化参数。这些超参数对模型的训练过程和性能有重大影响。
可以通过网格搜索或贝叶斯优化等技术来调整超参数。网格搜索涉及系统地遍历超参数空间,而贝叶斯优化使用概率模型来指导超参数搜索。
以下是一些常用的超参数调整技巧:
- **学习率:**学习率控制模型权重更新的步长。较高的学习率可能导致模型不稳定,而较低的学习率可能导致训练速度慢。
- **批大小:**批大小是每个训练迭代中使用的样本数。较大的批大小可以提高训练效率,但可能导致模型过拟合。
- **迭代次数:**迭代次数是模型训练的总次数。较多的迭代次数可以提高模型的准确性,但可能导致训练时间长。
- **正则化参数:**正则化参数用于防止模型过拟合。常见的正则化技术包括L1正则化和L2正则化。
### 5.1.2 数据增强
数据增强涉及对训练数据进行变换,以创建更多样化的数据集。这有助于防止模型过拟合并提高其泛化能力。
常用的数据增强技术包括:
- **随机裁剪:**从原始图像中随机裁剪出不同大小和纵横比的区域。
- **随机翻转:**水平或垂直翻转图像。
- **随机旋转:**将图像旋转一定角度。
- **颜色抖动:**调整图像的亮度、对比度、饱和度和色相。
- **马赛克:**将四张图像的随机区域组合成一张新图像。
代码示例:
```python
import albumentations as A
# 创建数据增强管道
transform = A.Compose([
A.RandomCrop(width=640, height=640),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
A.Mosaic(p=0.5)
])
# 将数据增强管道应用于训练数据集
train_dataset = train_dataset.map(lambda x: transform(image=x["image"], bboxes=x["bboxes"]))
```
通过结合超参数调整和数据增强,可以显著提高YOLOv5模型的性能。
# 6. YOLOv5未来展望**
**6.1 YOLOv6的演进**
YOLOv5作为目前最先进的目标检测算法之一,其后续版本YOLOv6也备受期待。根据官方透露的信息,YOLOv6将带来以下主要改进:
- **更快的推理速度:**YOLOv6将采用新的网络结构和优化算法,进一步提升推理速度,使其在实际应用中更加高效。
- **更高的精度:**通过引入新的特征提取器和目标检测算法,YOLOv6将提高目标检测精度,减少漏检和误检。
- **更强的泛化能力:**YOLOv6将使用更广泛的数据集进行训练,增强其泛化能力,使其在不同场景下都能表现出色。
- **更友好的部署:**YOLOv6将提供更简便的部署方式,支持多种平台和设备,方便开发者快速将其集成到实际应用中。
**6.2 目标检测的新趋势**
除了YOLOv6的演进,目标检测领域还涌现出一些新的趋势:
- **多模态目标检测:**将目标检测与其他模态数据(如文本、音频)相结合,实现更全面的目标理解和检测。
- **实时目标检测:**在视频流或图像序列中实时检测目标,满足安防、监控等场景的需求。
- **弱监督目标检测:**利用少量标注数据或无标注数据训练目标检测模型,降低标注成本。
- **可解释目标检测:**提供目标检测结果的可解释性,帮助用户理解模型的决策过程。
- **联邦学习目标检测:**在分布式设备上协作训练目标检测模型,保护数据隐私并提高模型性能。
这些新趋势将推动目标检测技术不断发展,为更广泛的应用场景提供更强大、更智能的解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**YOLO 网络识别专栏**
本专栏深入探索 YOLOv5 目标检测算法的各个方面,从架构和原理到应用和优化技巧。涵盖广泛的主题,包括:
* YOLOv5 架构和原理的深入分析
* 提升 YOLOv5 性能的训练优化秘籍
* 解锁 YOLOv5 无限潜力的实战应用宝典
* YOLOv5 与其他目标检测算法的优劣对比
* 快速解决 YOLOv5 常见问题的疑难杂症全攻略
* 从零到一打造目标检测系统的实战项目指南
* 掌握目标检测算法的一步步代码实战手册
* 提升目标检测精度的图像预处理和后处理解析
* 理解模型训练奥秘的损失函数和优化算法揭秘
* 打造最优目标检测模型的网络结构和超参数分析
* 构建高质量训练数据的训练数据集和数据增强秘籍
* 让模型落地应用的部署和推理优化指南
* 全面衡量模型表现的性能评估和基准测试
* 推动目标检测技术发展的算法改进和创新
* 加速模型训练和提升效率的并行化和分布式训练
* 让目标检测触手可及的移动端部署和优化
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C语言游戏开发秘籍】:指针与数组的高级应用技巧揭秘
# 摘要
指针与数组在游戏开发中扮演着核心角色,它们是实现动态内存管理和高效资源处理的关键技术。本文首先回顾了指针的基础知识及其与数组的关联,并深入探讨了指针的高级用法,包括多级指针、内存分配以及动态内存管理。同时,对数组在游戏中的多维应用进行了优化分析,并介绍了一些数组使用的高级技巧。文章还涉及了指针与数组在游戏物理引擎、AI算法和资源管理中的创新用法,并通过实战项目演练,加深了对指针和数组应用的理解。本研究为游戏开发人员提供了一系列理论知识和实践技巧,以提高开发效率和游戏性能。
# 关键字
指针;数组;游戏开发;动态内存管理;资源管理;物理引擎
参考资源链接:[C语言编写俄罗斯方块实训报
GS+ 快速上手指南:7步开启高效GS+ 项目之旅

# 摘要
GS+ 是一款用于地理统计分析的软件,它提供了从基础到高级的广泛分析工具。本文首先对 GS+进行了概述,并详细说明了安装步骤和界面布局。随后,文章介绍了GS+的基础操作,包括数据处理和空间统计分析,并通过实战案例展示了如何应用于土地利用、环境评估和城市规划等多个领域。文章还探讨了GS+的高级分析技术,如地理加权
STM32F105XX中断管理:深入理解与8大优化技巧

# 摘要
本文深入探讨了基于STM32F105XX微控制器的中断管理技术,涵盖了中断向量配置、优先级优化、处理流程编程实践,以及管理优化策略。文中详细解释了中断向量表的结构和分配规则,并深入分析了优先级分组和动态修改技巧。进一步,文章通过实例展示了中断服务例程的编写、中断嵌套机制以及线程安全问题的处理。在优化中断管理方面,本文提出了减少响应时间及中断资源高效管
MATLAB深度解析:f-k滤波器的10大实用技巧与应用案例
# 摘要
本文系统介绍了f-k滤波器的理论基础、设计实现技巧、在地震数据处理中的应用、高级应用技巧与案例研究,以及实践应用与案例分析。f-k滤波器在地震数据去噪、波型识别、多波处理以及三维数据处理等领域展示了显著效果。本文还探讨了f-k滤波器的高级应用,包括与其他信号处理技术的结合以及自适应与自动调整技术。通过多个工业、海洋和矿产勘探的实际应用案例,本文展示了f-k滤波器在实践中的有
【打造高效考勤系统的秘诀】:跟着demo优化,效率提升不止一点

# 摘要
考勤系统的优化对于提高企业运营效率和员工满意度至关重要。本文首先强调了考勤系统优化的重要性,并介绍其基础理论,包括系统的工作原理和设计原则。接着,通过对比分析理论与实际案例,本文识别了现有系统中性能瓶颈,并提出了针对性的优化策略。在实践操作章节中,详细说明了性能
【自动机与编程语言桥梁】:分割法解析技术深入解析
# 摘要
自动机理论作为计算科学的基础,在语言和解析技术中扮演着核心角色。本文首先介绍了自动机理论的基础知识及应用概况,随后深入探讨了分割法解析技术的理论框架和构建过程,包括其与形式语言的关系、分割法原理及其数学模型,以及分割法解析器的构建步骤。实践中,本文分析了分割法在编译器设计、文本处理和网络安全等多个领域的应用案例,如词法分析器的实现和入侵检测系统中的模式识别。此外,文章还探讨了分割法与上下文无关文法的结合,性能优化策略,以及自动化工具与框架。最
【TEF668X深度解析】:揭秘工作原理与架构,优化设备运行
# 摘要
TEF668X作为一种先进的技术设备,在信号处理和系统集成领域发挥着关键作用。本文全面介绍了TEF668X的基础知识,详细阐释了其工作原理,并分析了核心组件功能与系统架构。针对性能优化,本文提出了一系列硬件和软件优化技术,并从系统级提出了优化方案。进一步地,本文探讨了TEF668X在不同应用场景中的应用实例和问题解决方法,并对其应用前景与市场潜力进行了分析。最后,文章总结了TEF668X的开发与维护策略,包括安全性与兼容性的考量,并对其未来发展趋势进行了展望。本文为TEF668X的深入研究与实际应用提供了全面的参考框架。
# 关键字
TEF668X;工作原理;性能优化;应用场景;维
【Design-Expert深度剖析】:掌握响应面模型构建与优化的核心技能

# 摘要
响应面模型是一种用于分析多个变量间关系的统计方法,广泛应用于实验设计、模型构建、优化和预测。本文系统介绍了响应面模型的理论基础,详细阐述了设计实验的原则和技巧,包括选择因素与水平、控制实验误差以及采用全因子设计、分部因子设计和中心复合设计等方法。在构建响应面模型的流程中,我们探讨了多元线性回归、非线性回归、模型拟合与验证,以及模型优化与
PhoeniCS中的网格划分技巧与最佳实践

# 摘要
PhoeniCS是一个用于自动求解偏微分方程的计算框架,其高效性在很大程度上依赖于先进的网格划分技术。本文首先介绍了PhoeniCS的概述和网格划分的基础知识
电梯控制系统的秘密:故障代码与逻辑控制的奥秘

# 摘要
电梯控制系统作为高层建筑中不可或缺的组成部分,对于保障乘客安全与提高电梯运行效率至关重要。本文首先介绍了电梯控制系统的组成和基本工作原理,其次分析了电梯逻辑控制的原理和实现方法,并探讨了故障代码的定义及其在故障诊断中的应用。进一步地,本文着重于电梯控制系统的故障诊断与排除操作,提出了故障排除的步骤及案例分析。最后,展望了人工智能、机器学习及物联网技术在电梯控制系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )