Python代码执行流程:深入浅出解读解释器工作机制
发布时间: 2024-06-17 09:56:46 阅读量: 95 订阅数: 34 

使用 Python 解释器
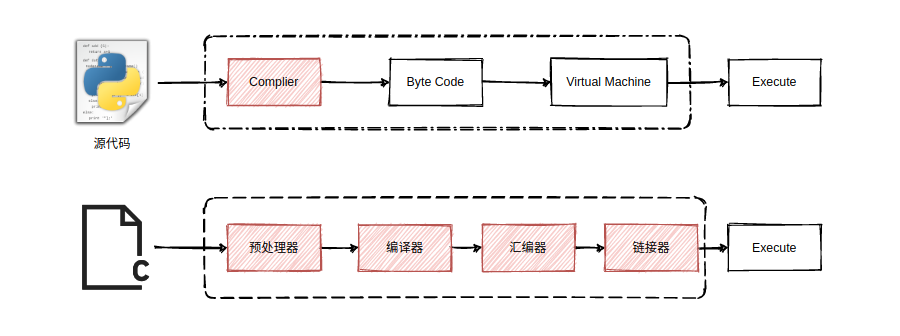
# 1. Python代码执行概述
Python代码执行是一个复杂的过程,涉及多个阶段和组件。本章将概述Python代码执行的流程,包括解释器的工作机制、字节码生成和虚拟机的执行过程。
Python解释器是一个负责执行Python代码的程序。它将源代码编译成字节码,字节码是一种中间表示形式,由Python虚拟机解释和执行。虚拟机是一个抽象机器,它提供了执行字节码所需的运行时环境,包括栈帧、局部变量表和字节码指令。
Python解释器还包含优化技术,例如JIT编译和垃圾回收,以提高代码执行的性能。这些技术可以显著减少代码执行时间,并提高应用程序的整体响应能力。
# 2. Python解释器的工作机制
Python解释器是一个将Python代码转换为机器可执行指令的程序。它负责将Python代码编译成字节码,然后执行字节码以生成结果。
### 2.1 Python代码的编译过程
Python代码的编译过程分为两个阶段:词法分析和语法分析,以及字节码生成。
#### 2.1.1 词法分析和语法分析
词法分析器将Python代码分解成称为标记(token)的基本单位,例如关键字、标识符和运算符。语法分析器将这些标记组合成语法结构,例如语句和表达式。
#### 2.1.2 字节码生成
语法分析器生成一个称为抽象语法树(AST)的中间表示。AST然后被编译器转换为字节码,这是Python虚拟机(VM)可以执行的低级指令集。
### 2.2 Python虚拟机的执行过程
Python虚拟机是一个解释器,它逐行执行字节码指令。它维护一个称为栈帧的数据结构,其中包含局部变量、函数参数和返回地址。
#### 2.2.1 栈帧和局部变量表
每个函数调用都会创建一个新的栈帧。栈帧包含一个局部变量表,其中存储着函数的局部变量。当函数返回时,其栈帧将从栈中弹出。
#### 2.2.2 字节码指令执行
虚拟机执行字节码指令,例如:
```python
LOAD_CONST 10
```
这条指令将常量10加载到栈中。
```python
CALL_FUNCTION 1
```
这条指令调用一个带有1个参数的函数。
### 2.3 Python解释器的优化技术
Python解释器包含几个优化技术来提高执行速度。
#### 2.3.1 JIT编译
JIT(即时编译)编译器将字节码动态编译成机器代码。这可以显着提高经常执行的代码的性能。
#### 2.3.2 垃圾回收
垃圾回收器自动释放不再使用的对象所占用的内存。这有助于防止内存泄漏和提高性能。
# 3. Python代码执行的实践分析
### 3.1 使用调试器跟踪代码执行
#### 3.1.1 pdb调试器
pdb(Python调试器)是一个内置的调试器,允许开发人员逐步执行代码,检查变量值并设置断点。
**使用pdb调试器:**
1. 在要调试的代码中添加断点:```python
import pdb; pdb.set_trace()
```
2. 在命令行中运行代码:```python
python -m pdb <script_name.py>
```
3. 使用以下命令控制调试器:
- `n`:执行下一行代码
- `s`:进入函数
- `l`:列出当前文件中的代码行
- `p`:打印变量值
- `c`:继续执行代码
**示例:**
```python
import pdb
def my_function(a, b):
pdb.set_trace()
c = a + b
return c
my_function(1, 2)
```
运行此代码后,pdb调试器将在`pdb.set_trace()`断点处暂停。开发人员可以使用命令检查变量`a`和`b`的值,并逐步执行代码。
#### 3.1.2 ipdb调试器
ipdb是pdb的一个增强版本,提供了更高级的功能,例如:
- 自动完成变量和命令
- 交互式命令行
- 彩色输出
**使用ipdb调试器:**
1. 安装ipdb:```python
pip install ipdb
```
2. 在要调试的代码中添加断点:```python
import ipdb; ipdb.set_trace()
```
3. 在命令行中运行代码:```python
python -m ipdb <script_name.py>
```
**示例:**
```python
import ipdb
def my_function(a, b):
ipdb.set_trace()
c = a + b
return c
my_function(1, 2)
```
运行此代码后,ipdb调试器将在`ipdb.set_trace()`断点处暂停。开发人员可以使用命令检查变量、设置断点并交互式地执行代码。
### 3.2 使用性能分析工具优化代码
#### 3.2.1 cProfile分析器
cProfile分析器可以分析代码的性能,并生成调用图和统计信息。
**使用cProfile分析器:**
1. 导入cProfile:```python
import cProfile
```
2. 使用`cProfile.run()`包裹要分析的代码:```python
cProfile.run('my_function(1, 2)')
```
3. 生成分析报告:```python
cProfile.print_stats()
```
**示例:**
```python
import cProfile
def my_function(a, b):
c = a + b
return c
cProfile.run('my_function(1, 2)')
```
运行此代码后,cProfile将生成一份报告,其中包含有关函数调用、执行时间和内存使用情况的统计信息。
#### 3.2.2 line_profiler分析器
line_profiler分析器可以分析代码中每行的性能,并生成详细的报告。
**使用line_profiler分析器:**
1. 导入line_profiler:```python
import line_profiler
```
2. 使用`@profile`装饰器装饰要分析的函数:```python
@profile
def my_function(a, b):
c = a + b
return c
```
3. 运行代码:```python
my_function(1, 2)
```
4. 生成分析报告:```python
line_profiler.print_stats()
```
**示例:**
```python
import line_profiler
@profile
def my_function(a, b):
c = a + b
return c
my_function(1, 2)
```
运行此代码后,line_profiler将生成一份报告,其中包含有关每行代码的执行时间和调用次数的统计信息。
# 4. Python代码执行的性能优化
### 4.1 代码结构优化
#### 4.1.1 使用循环和列表推导
循环是Python中执行重复任务的常用方法,但它们可能会导致代码冗长且难以阅读。列表推导提供了一种更简洁、更具可读性的方式来创建列表,同时避免了显式循环。
```python
# 使用显式循环
numbers = []
for i in range(10):
numbers.append(i)
# 使用列表推导
numbers = [i for i in range(10)]
```
在上面的示例中,列表推导将循环和列表创建合并为一行代码,使代码更简洁且更易于理解。
#### 4.1.2 避免不必要的函数调用
函数调用会引入开销,因此在可能的情况下应避免不必要的函数调用。例如,可以将多个函数调用组合到一个函数中,或者使用局部变量存储函数调用的结果以避免重复调用。
```python
# 不必要的函数调用
def get_length(string):
return len(string)
string = "Hello world"
length = get_length(string)
# 避免不必要的函数调用
string = "Hello world"
length = len(string)
```
在上面的示例中,通过直接调用`len`函数,避免了对`get_length`函数的调用。
### 4.2 数据结构优化
#### 4.2.1 使用合适的数据结构
选择合适的数据结构对于代码性能至关重要。例如,对于需要快速查找的集合,字典比列表更合适。对于需要快速插入和删除的集合,列表比字典更合适。
```python
# 使用字典进行快速查找
phone_book = {}
phone_book["Alice"] = "123-456-7890"
# 使用列表进行快速插入和删除
shopping_list = []
shopping_list.append("Milk")
shopping_list.remove("Milk")
```
在上面的示例中,字典用于快速查找电话号码,而列表用于快速插入和删除购物清单中的项目。
#### 4.2.2 优化数据访问方式
优化数据访问方式可以显着提高代码性能。例如,可以使用切片操作一次获取列表中的多个元素,而不是使用循环。可以使用`in`操作符快速检查元素是否在集合中,而不是使用循环。
```python
# 使用切片操作获取多个元素
numbers = [1, 2, 3, 4, 5]
first_three = numbers[:3]
# 使用 in 操作符检查元素是否存在
if "Alice" in phone_book:
print("Alice's phone number is", phone_book["Alice"])
```
在上面的示例中,切片操作用于一次获取列表中的前三个元素,而`in`操作符用于快速检查字典中是否存在一个键。
### 4.3 算法优化
#### 4.3.1 使用高效算法
选择高效算法对于代码性能至关重要。例如,对于需要对列表进行排序,可以使用归并排序或快速排序等高效算法,而不是使用冒泡排序等低效算法。
```python
# 使用归并排序对列表进行排序
def merge_sort(list):
if len(list) <= 1:
return list
mid = len(list) // 2
left_half = merge_sort(list[:mid])
right_half = merge_sort(list[mid:])
return merge(left_half, right_half)
def merge(left, right):
merged = []
left_index = 0
right_index = 0
while left_index < len(left) and right_index < len(right):
if left[left_index] <= right[right_index]:
merged.append(left[left_index])
left_index += 1
else:
merged.append(right[right_index])
right_index += 1
merged.extend(left[left_index:])
merged.extend(right[right_index:])
return merged
```
在上面的示例中,归并排序算法用于对列表进行排序。该算法通过递归将列表分成较小的部分,然后合并排序后的部分来工作。
#### 4.3.2 减少算法复杂度
算法复杂度衡量算法在不同输入大小下的执行时间。为了优化代码性能,应努力减少算法复杂度。例如,可以使用二分搜索算法在排序列表中查找元素,而不是使用线性搜索算法。
```python
# 使用二分搜索在排序列表中查找元素
def binary_search(list, target):
low = 0
high = len(list) - 1
while low <= high:
mid = (low + high) // 2
if list[mid] == target:
return mid
elif list[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
```
在上面的示例中,二分搜索算法用于在排序列表中查找元素。该算法通过将列表分成较小的部分并缩小搜索范围来工作,从而具有对数时间复杂度。
# 5.1 多线程编程
### 5.1.1 线程创建和同步
**线程创建**
在Python中,可以使用`threading`模块创建线程。`threading.Thread`类提供了一个构造函数,它接受一个可调用的对象作为参数。当线程启动时,该对象将被调用。
```python
import threading
def task():
print("Hello from thread")
thread = threading.Thread(target=task)
thread.start()
```
**线程同步**
当多个线程同时访问共享资源时,可能会出现竞争条件。为了防止这种情况,需要使用同步机制来确保线程安全。Python提供了多种同步机制,包括锁、信号量和事件。
**锁**
锁是一种同步机制,它允许一次只有一个线程访问共享资源。要使用锁,可以创建一个`threading.Lock`对象并使用`acquire()`和`release()`方法来获取和释放锁。
```python
import threading
lock = threading.Lock()
def task():
with lock:
# 临界区代码
pass
thread1 = threading.Thread(target=task)
thread2 = threading.Thread(target=task)
thread1.start()
thread2.start()
```
**信号量**
信号量是一种同步机制,它限制可以同时访问共享资源的线程数量。要使用信号量,可以创建一个`threading.Semaphore`对象并使用`acquire()`和`release()`方法来获取和释放信号量。
```python
import threading
semaphore = threading.Semaphore(2)
def task():
with semaphore:
# 临界区代码
pass
thread1 = threading.Thread(target=task)
thread2 = threading.Thread(target=task)
thread3 = threading.Thread(target=task)
thread1.start()
thread2.start()
thread3.start()
```
**事件**
事件是一种同步机制,它允许一个线程等待另一个线程完成任务。要使用事件,可以创建一个`threading.Event`对象并使用`wait()`和`set()`方法来等待和设置事件。
```python
import threading
event = threading.Event()
def task():
# 执行任务
event.set()
thread = threading.Thread(target=task)
thread.start()
event.wait()
```
### 5.1.2 线程池的使用
线程池是一种管理线程的机制,它可以提高线程创建和销毁的效率。Python提供了`concurrent.futures.ThreadPoolExecutor`类,它可以创建和管理线程池。
```python
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.submit(task)
```
线程池可以自动管理线程的生命周期,并根据需要创建和销毁线程。这可以提高性能,并简化多线程编程。
# 6. Python代码执行的异常处理
### 6.1 Python异常体系
#### 6.1.1 异常类型和层次结构
Python中的异常体系采用层次结构,由基类`BaseException`派生出各种异常类型。常见的异常类型包括:
- `Exception`:所有异常的基类。
- `TypeError`:类型错误。
- `ValueError`:值错误。
- `IndexError`:索引错误。
- `KeyError`:键错误。
- `ZeroDivisionError`:零除错误。
- `ImportError`:导入错误。
### 6.1.2 异常捕获和处理
使用`try-except`语句捕获和处理异常:
```python
try:
# 代码块可能引发异常
except Exception as e:
# 异常捕获后处理代码
```
`except`语句可以指定要捕获的异常类型,例如:
```python
try:
# 代码块可能引发异常
except TypeError:
# 捕获类型错误异常
except ValueError:
# 捕获值错误异常
```
### 6.2 自定义异常处理
#### 6.2.1 创建自定义异常类
可通过继承`Exception`类创建自定义异常类:
```python
class MyException(Exception):
def __init__(self, message):
super().__init__(message)
```
#### 6.2.2 捕获和处理自定义异常
使用`try-except`语句捕获和处理自定义异常:
```python
try:
# 代码块可能引发自定义异常
except MyException as e:
# 捕获自定义异常
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 代码执行的各个方面,从输入到输出的奥秘之旅,以及解释器的工作机制。它提供了加速代码执行的秘籍,并详细介绍了异常处理和调试技术。专栏还涵盖了模块和包的构建、文件操作、数据结构的剖析、算法和数据结构的应用、面向对象编程的精髓、多线程和多进程编程、网络编程、数据库操作、Web 开发、机器学习、数据可视化、自动化、安全编程、测试和调试以及设计模式。通过深入浅出的讲解,本专栏旨在帮助读者掌握 Python 代码执行的方方面面,并提升他们的编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效数据分析管理:C-NCAP 2024版数据系统的构建之道
# 摘要
C-NCAP 2024版数据系统是涉及数据采集、存储、分析、挖掘及安全性的全面解决方案。本文概述了该系统的基本框架,重点介绍了数据采集技术、存储解决方案以及预处理和清洗技术的重要性。同时,深入探讨了数据分析方法论、高级分析技术的运用以及数据挖掘在实际业务中的案例分析。此外,本文还涵盖了数据可视化工具、管理决策支持以及系统安全性与可靠性保障策略,包括数据安全策略、系统冗余设计以及遵循相关法律法规。本文旨在为C
RS纠错编码在数据存储和无线通信中的双重大显身手
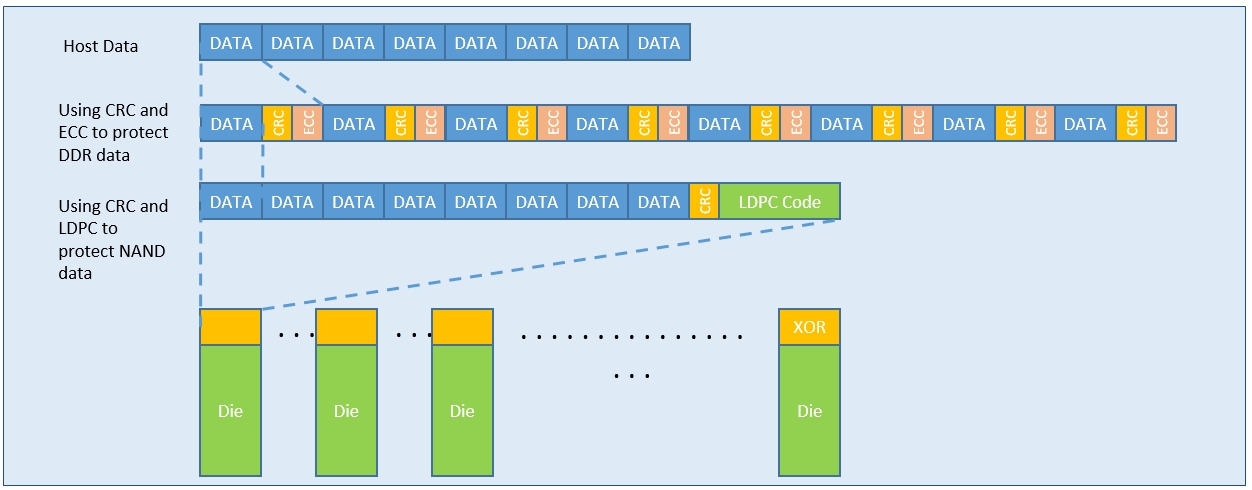
# 摘要
Reed-Solomon (RS)纠错编码是广泛应用于数据存储和无线通信领域的重要技术,旨在提高数据传输的可靠性和存储的完整性。本文从RS编码的理论基础出发,详细阐述了其数学原理、构造过程以及错误检测与纠正能力。随后,文章深入探讨了RS编码在硬盘驱动器、固态存储、内存系统以及无线通信系统中的实际应用和效能优化。最后,文章分析了RS编码技术面临的现代通信挑战,
【模式识别】:模糊数学如何提升识别准确性

# 摘要
模式识别与模糊数学是信息处理领域内的重要研究方向,它们在图像、语音以及自然语言理解等领域内展现出了强大的应用潜力。本文首先回顾了模式识别与模糊数学的基础理论,探讨了模糊集合和模糊逻辑在模式识别理论模型中的作用。随后,本文深入分析了模糊数学在图像和语音识别中的实
【Java异常处理指南】:四则运算错误管理与最佳实践

# 摘要
本文系统地探讨了Java异常处理的各个方面,从基础知识到高级优化策略。首先介绍了异常处理的基本概念、Java异常类型以及关键的处理关键字。接着,文章详细阐释了检查型和非检查型异常之间的区别,并分析了异常类的层次结构与分类。文章第三章专门讨论了四则运算中可能出现的错误及其管理方法,强调了用户交互中的异常处理策略。在最佳实践方面,文章探讨了代码组织、日志
【超效率SBM模型101】:超效率SBM模型原理全掌握

# 摘要
本文全面介绍和分析了超效率SBM模型的发展、理论基础、计算方法、实证分析以及未来发展的可能。通过回顾数据包络分析(DEA)的历史和基本原理,本文突出了传统SBM模型与超效率SBM模型的区别,并探讨了超效率SBM模型在效率评估中的优势。文章详细阐述了超效率SBM模型的计算步骤、软件实现及结果解释,并通过选取不同领域的实际案例分析了模
【多输入时序电路构建】:D触发器的实用设计案例分析

# 摘要
D触发器作为一种基础数字电子组件,在同步和异步时序电路设计中扮演着至关重要的角色。本文首先介绍了D触发器的基础知识和应用背景,随后深入探讨了其工作原理,包括电路组件、存储原理和电气特性。通过分析不同的设计案例,本文阐释了D触发器在复杂电路中实现内存单元和时钟控制电路的实用设计,同时着重指出设计过程中可能遇到的时序问题、功耗和散热问题,并提供了解
【内存管理技巧】:在图像拼接中优化numpy内存使用的5种方法

# 摘要
随着数据处理和图像处理任务的日益复杂化,图像拼接与内存管理成为优化性能的关键挑战。本文首先介绍了图像拼接与内存管理的基本概念,随后深入分析了NumPy库在内存使用方面的机制,包括内存布局、分配策略和内存使用效率的影响因素。本文还探讨了内存优化的实际技
【LDPC优化大揭秘】:提升解码效率的终极技巧
# 摘要
低密度奇偶校验(LDPC)编码与解码技术在现代通信系统中扮演着关键角色。本文从LDPC编码和解码的基础知识出发,深入探讨了LDPC解码算法的理论基础、不同解码算法的类别及其概率传播机制。接着,文章分析了LDPC解码算法在硬件实现和软件优化上的实践技巧,以及如何通过代码级优化提升解码速度。在此基础上,本文通过案例分析展示了优化技巧在实际应用中的效果,并探讨了LDPC编码和解码技术的未来发展方向,包括新兴应用领域和潜在技术突破,如量子计算与机器学习。通过对LDPC解码优化技术的总结,本文为未来通信系统的发展提供了重要的视角和启示。
# 关键字
LDPC编码;解码算法;概率传播;硬件实现
【跨平台开发技巧】:在Windows上高效使用Intel Parallel StudioXE

# 摘要
随着技术的发展,跨平台开发已成为软件开发领域的重要趋势。本文首先概述了跨平台开发的基本概念及其面临的挑战,随后介绍了Intel Parallel Studio XE的安装、配置及核心组件,探讨了其在Windows平台上的
Shape-IoU:一种更精准的空中和卫星图像分析工具(效率提升秘籍)
# 摘要
Shape-IoU工具是一种集成深度学习和空间分析技术的先进工具,旨在解决图像处理中的形状识别和相似度计算问题。本文首先概述了Shape-IoU工具及其理论基础,包括深度学习在图像处理中的应用、空中和卫星图像的特点以及空间分析的基本概念。随后,文章详细介绍了Shape-IoU工具的架构设计、IoU技术原理及其在空间分析中的优势
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )