FusionInsight大数据平台架构与组件介绍
发布时间: 2024-02-25 17:53:39 阅读量: 51 订阅数: 19 
# 1. 简介
- FusionInsight大数据平台的概述
- 大数据技术在企业中的重要性
- FusionInsight的发展历程及特点
在当今信息爆炸的时代,各行各业都在积累越来越多的数据。如何有效地管理、存储、处理和分析这些海量数据成为企业面临的一项重要挑战。大数据技术应运而生,成为解决这一难题的有效工具之一。而华为推出的FusionInsight大数据平台,则为企业提供了一套全面的大数据解决方案。
## FusionInsight大数据平台的概述
FusionInsight是华为推出的基于Hadoop生态环境的大数据平台解决方案。它集成了各种大数据技术组件,提供了统一的管理平台和数据分析工具,帮助企业实现对海量数据的高效管理、存储、处理和分析。
## 大数据技术在企业中的重要性
随着互联网的飞速发展,传统的数据处理方式已经无法满足企业对海量数据的需求。大数据技术的出现,为企业提供了更快速、更精准地获取洞察力的方式,有助于提升企业的决策能力和竞争力。
## FusionInsight的发展历程及特点
FusionInsight从诞生至今,经历了多个版本的迭代和升级,不断完善其功能和性能。其特点包括高可靠性、高性能、易扩展性和灵活性,可以满足不同规模企业的需求,并在各行各业得到广泛应用。
在下一章节中,我们将深入探讨FusionInsight大数据平台的整体架构,以及分布式架构的优势和应用。
# 2. 架构概述
大数据平台通常采用分布式架构,FusionInsight大数据平台也不例外。其整体架构包括存储层、计算层、资源管理和调度层、数据接入和集成层、安全认证层等组件。下面将就这些组件进行详细介绍。
### 分布式架构的优势与应用
分布式架构通过将数据存储和计算任务分布到多台计算机节点上,提高了系统的可靠性和扩展性。数据分布存储在多个节点上,不仅提高了数据的容错能力,还能实现水平扩展,满足大规模数据存储和处理的需求。同时,分布式架构也能够充分利用集群中的计算资源,实现高效的数据处理和分析。
### 硬件环境要求和扩展性设计
FusionInsight大数据平台对硬件环境有一定的要求,要求服务器节点具备一定的计算能力和存储容量,并且要求服务器之间的网络连接具备一定的带宽和稳定性。此外,FusionInsight还具备良好的扩展性设计,可以根据业务需求,灵活地扩展集群规模和存储容量,满足不断增长的数据处理需求。
以上就是FusionInsight大数据平台架构概述的内容。在下一个章节中,我们将详细介绍FusionInsight的各个组件及其作用。
# 3. 组件介绍
在FusionInsight大数据平台中,包含多个核心组件,它们各自承担着不同的功能和角色,共同构建起一个完整的大数据处理和分析环境。接下来我们将对几个主要组件进行介绍。
#### Hadoop分布式文件系统(HDFS)
HDFS是FusionInsight大数据平台的基础存储系统,它采用分布式存储的方式,能够将大规模数据存储在集群中,提供高容错性和高吞吐量。HDFS通过将文件划分为多个数据块,并存储在不同的节点上,实现了数据的分布式存储与管理。
```java
// 示例代码:HDFS文件读写操作
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://namenode:9000"), conf);
// 从本地文件系统上传文件到HDFS
fs.copyFromLocalFile(new Path("/local/path/file.txt"), new Path("/hdfs/path/file.txt"));
// 从HDFS下载文件到本地文件系统
fs.copyToLocalFile(new Path("/hdfs/path/file.txt"), new Path("/local/path/file.txt"));
```
HDFS的特点包括高容错性、高可靠性和扩展性好,适合存储大规模数据,并提供了适用于大数据处理的基础设施。
#### YARN资源管理器
YARN是FusionInsight大数据平台中的资源管理系统,负责集群资源的分配和调度。它采用了分层的架构,包括资源管理器和应用程序管理器两个主要组件,能够有效地管理集群资源,并支持多种数据处理应用的并发执行。
```java
// 示例代码:提交一个MapReduce作业到YARN集群
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// ... 其他作业配置
job.submit();
```
YARN的引入使得FusionInsight大数据平台能够更好地支持多种数据处理框架,如MapReduce、Spark等,并能够更灵活地适应不同的数据处理场景。
#### Hive
Hive是基于Hadoop的数据仓库工具,提供类SQL查询语言HiveQL,能够将结构化数据映射到HDFS上,并支持数据的交互式查询。Hive通过将HiveQL语句转换为MapReduce作业来执行查询操作,适用于大规模数据的分析和查询。
```sql
-- 示例代码:HiveQL查询
SELECT department, AVG(salary) FROM employee GROUP BY department;
```
Hive的特点包括易用性和扩展性好,适合处理大规模的结构化数据,并提供了数据分析和查询的便利。
以上是FusionInsight大数据平台中几个核心组件的简要介绍,它们分别承担着不同的角色,在大数据处理和分析中发挥着重要作用。
# 4. 数据处理与存储
在FusionInsight大数据平台中,数据的处理与存储是至关重要的环节,本章将介绍数据采集与清洗、流式处理技术、大数据存储策略以及数据安全保障措施等内容。
### 数据采集与清洗在FusionInsight中的实现方式
数据采集是大数据平台的重要组成部分,可以通过各种方式实现,比如日志收集、数据同步等。在FusionInsight中,可以利用Flume、Kafka等工具进行数据采集。下面以Flume为例,演示数据采集及清洗的实现方式:
首先,需要配置Flume Agent,示例配置如下:
```properties
# 定义Agent名字和组件
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置Source
agent1.sources.source1.type = netcat
agent1.sources.source1.bind = 0.0.0.0
agent1.sources.source1.port = 44444
# 配置Sink
agent1.sinks.sink1.type = logger
# 配置Channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 1000
agent1.channels.channel1.transactionCapacity = 100
# 绑定Source、Sink和Channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
```
然后启动Flume Agent进行数据采集:
```bash
$ bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
```
### 流式处理技术与实时计算框架的应用
FusionInsight大数据平台支持流式处理技术,可以实现实时计算和数据处理。其中,Storm和Flink是两个常用的流式计算框架。用户可以根据实际需求选择合适的框架进行应用。
下面以Storm为例,展示一个简单的实时计算拓扑示例:
```java
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new WordReaderSpout(), 1);
builder.setBolt("split", new SplitSentenceBolt(), 4).shuffleGrouping("spout");
builder.setBolt("count", new WordCountBolt(), 2).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
```
### 大数据存储策略及数据安全保障措施
在FusionInsight中,数据存储是至关重要的,HDFS、HBase等组件提供了可靠的存储解决方案。同时,数据安全也是必须关注的问题,用户可以通过权限控制、加密等手段保障数据的安全性。
总结:数据处理与存储是大数据平台的核心环节,通过数据采集、清洗、流式处理和存储,实现对海量数据的管理和分析。同时,数据安全保障措施也是不可或缺的一部分,确保数据的完整性和保密性。
# 5. 数据分析与可视化
在FusionInsight大数据平台中,数据分析与可视化是至关重要的环节,通过对海量数据的处理、挖掘和分析,企业可以更好地理解业务状况,发现潜在机会和问题。以下是关于数据分析与可视化的内容:
1. **FusionInsight支持的数据分析工具及库介绍**
FusionInsight平台集成了一系列常用的数据分析工具和库,如:
- **Spark**:快速通用型集群计算框架,适用于大规模数据处理和复杂的分析任务。
- **Hive**:基于Hadoop的数据仓库工具,可进行结构化数据的查询和分析。
- **HBase**:非关系型分布式数据库,适用于实时读写大规模数据。
- **Flink**:流式处理引擎,支持高吞吐量和低延迟的流处理应用。
2. **机器学习和人工智能在大数据分析中的角色**
FusionInsight平台提供了机器学习和人工智能相关的工具和库,如:
- **TensorFlow**:开源的人工智能开发框架,支持深度学习模型的构建和训练。
- **Scikit-learn**:Python机器学习库,提供各种机器学习算法和工具。
- **Mahout**:分布式机器学习库,支持大规模机器学习任务的并行计算。
3. **可视化分析工具的应用与优势**
数据可视化在大数据分析中起着至关重要的作用,FusionInsight平台支持多种可视化工具,如:
- **ECharts**:基于JavaScript的开源可视化库,支持各种图表类型和交互功能。
- **Tableau**:商业智能和数据可视化工具,提供直观的数据展示和分析功能。
- **Power BI**:微软推出的商业分析工具,支持数据连接、报表生成和信息共享。
通过数据分析工具和可视化工具的结合,用户可以更直观地理解数据的含义,从而为业务决策提供更有力的支持。
# 6. 部署与维护
在本章中,我们将深入探讨FusionInsight的部署方式以及最佳实践,同时介绍集群监控与故障排查的方法,以及安全性与合规性管理在FusionInsight中的重要性。
#### 6.1 FusionInsight的部署方式及最佳实践
FusionInsight的部署方式包括离线部署(离线安装)和在线部署(自动化部署)。在离线部署中,需要提前下载安装包,并手动配置和安装各组件;而在线部署则通过自动化部署工具,可以简化部署流程,提高效率。
以下是一个简单的离线部署Python脚本示例,用于安装FusionInsight组件:
```python
# 导入安装所需的库
import os
import subprocess
def install_fusion_insight():
# 设置安装路径
install_path = "/opt/fusioninsight"
if not os.path.exists(install_path):
os.makedirs(install_path)
# 下载安装包
subprocess.run(["wget", "http://example.com/fusioninsight.tar.gz", "-P", install_path])
# 解压安装包
subprocess.run(["tar", "-zxvf", "fusioninsight.tar.gz", "-C", install_path])
# 执行安装脚本
subprocess.run([install_path + "/install.sh"])
if __name__ == "__main__":
install_fusion_insight()
```
在实际部署中,需要根据不同环境和需求进行详细配置和参数调整,确保部署过程顺利进行并达到最佳性能。
#### 6.2 集群监控与故障排查的方法
一旦FusionInsight集群部署完成,监控与排查故障是必不可少的一项工作。FusionInsight提供了丰富的监控指标和工具,如Ganglia、Ambari等,可以帮助管理员实时监控集群状态并快速诊断问题。
以下是一个简单的故障排查Python脚本示例,用于检测HDFS集群状态:
```python
# 导入所需的库
import subprocess
def check_hdfs_status():
# 执行HDFS状态检查命令
subprocess.run(["hdfs", "dfsadmin", "-report"])
if __name__ == "__main__":
check_hdfs_status()
```
通过定期运行类似的脚本,管理员可以及时发现集群中的异常情况并采取相应措施进行修复。
#### 6.3 安全性与合规性管理在FusionInsight中的重要性
随着大数据的广泛应用,数据安全和合规性管理变得尤为重要。FusionInsight提供了丰富的安全性管理功能,包括用户认证、权限控制、加密传输等,可以帮助企业建立完善的数据安全体系。
同时,FusionInsight也支持多种合规性要求,如GDPR、HIPAA等,管理员可以根据实际需求进行配置和调整,确保数据处理符合法律法规。
总之,部署与维护是FusionInsight大数据平台运行过程中至关重要的环节,只有做好了部署与维护工作,才能保证集群稳定运行并发挥最大价值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《FusionInsight大数据平台》专栏深入探讨了华为公司开发的大数据平台FusionInsight的架构和各个组件的介绍。从MapReduce到Spark再到Flink,专栏讨论了在FusionInsight中优化数据处理的技巧和最佳实践。同时,专栏涵盖了Hive数据仓库设计、数据安全与隐私保护、数据治理与元数据管理、数据可视化与报表技术以及监控与告警系统构建等主题。读者将通过本专栏全面了解如何在FusionInsight平台上高效管理和处理海量数据,同时保障数据的安全性和隐私性,进而实现数据可视化、智能化的应用。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
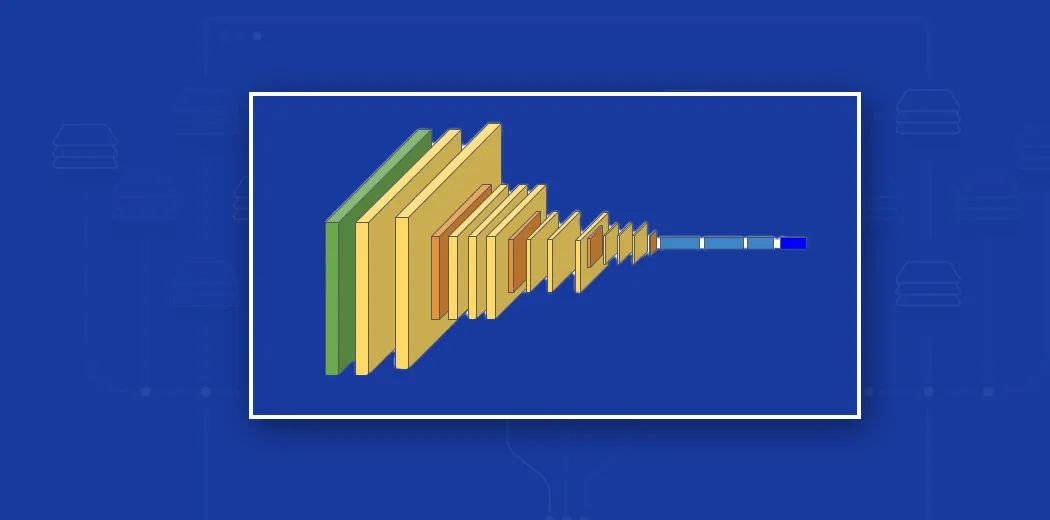
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
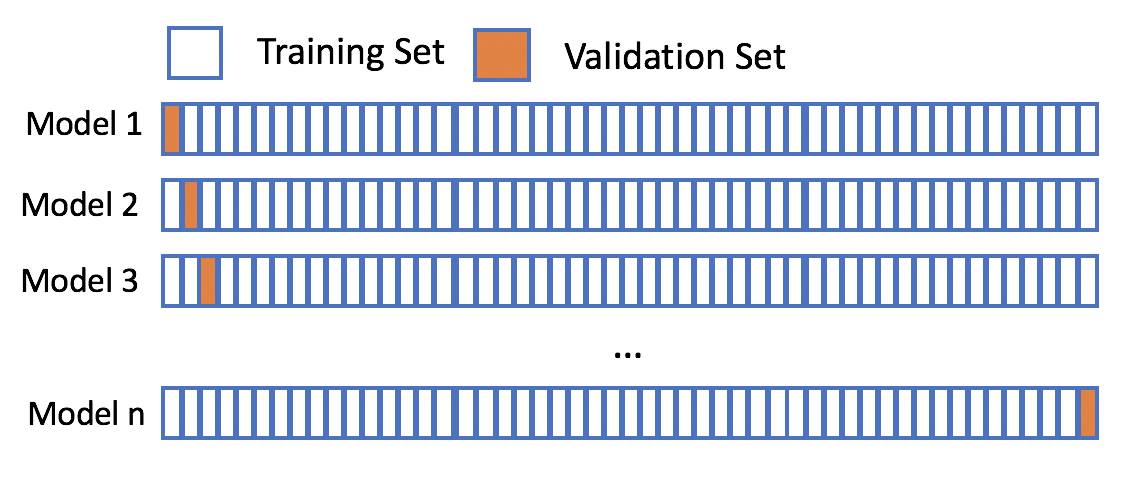
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
机器学习调试实战:分析并优化模型性能的偏差与方差
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
激活函数在深度学习中的应用:欠拟合克星
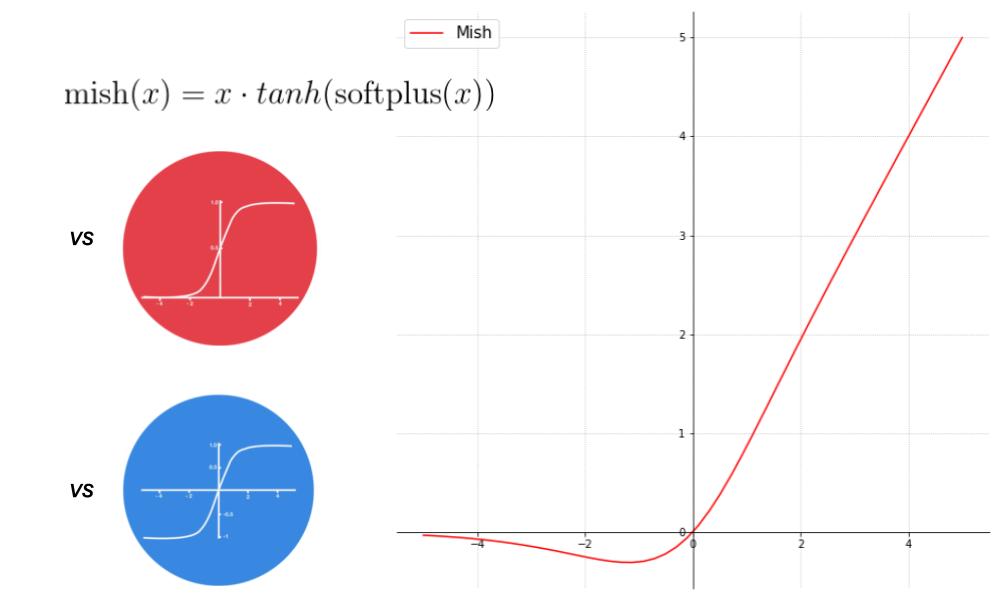
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
注意力机制与过拟合:深度学习中的关键关系探讨

# 1. 深度学习的注意力机制概述
## 概念引入
注意力机制是深度学习领域的一种创新技术,其灵感来源于人类视觉注意力的生物学机制。在深度学习模型中,注意力机制能够使模型在处理数据时,更加关注于输入数据中具有关键信息的部分,从而提高学习效率和任务性能。
## 重要性解析
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )