YOLOv8实战演练:从数据预处理到结果分析的完整流程
发布时间: 2024-12-11 16:12:44 阅读量: 4 订阅数: 13 

深圳混泥土搅拌站生产过程中环境管理制度.docx
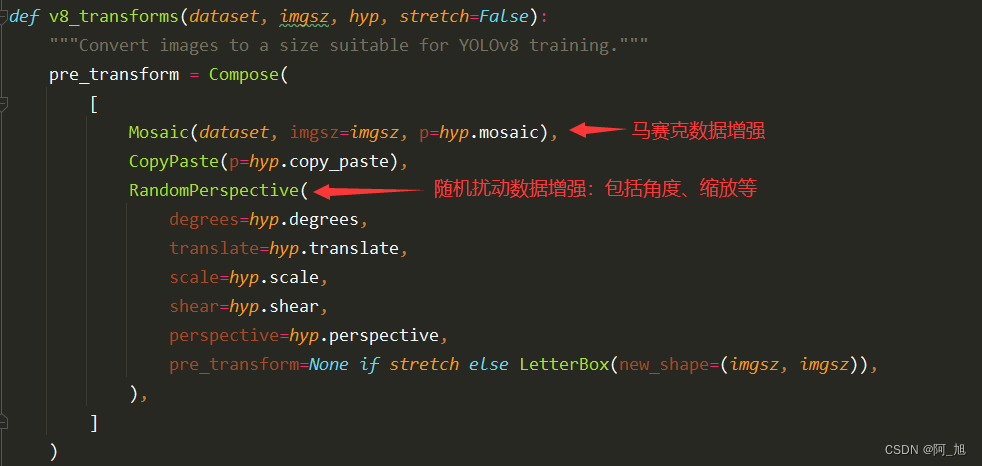
# 1. YOLOv8简介与安装配置
## 1.1 YOLOv8的发展与定位
YOLOv8(You Only Look Once version 8)是一种流行且高效的实时目标检测系统,它继承了YOLO系列算法快速准确的特点。YOLOv8不仅优化了前代的性能瓶颈,还引入了更多创新的特性,如增强的特征提取能力、改进的损失函数设计,以及对多尺度检测的增强等。
## 1.2 YOLOv8的核心优势
YOLOv8的优势在于其能够在一个统一的框架内,同时进行目标检测、分类和定位任务。其核心优势主要表现在:
- **速度与精度的平衡**:YOLOv8在保持高帧率的同时,对检测精度有显著提升。
- **全面的适应性**:适用于多种平台和场景,包括但不限于工业检测、智能视频分析等。
- **简洁的训练和部署流程**:简化了模型训练和部署的复杂度,降低了使用者的技术门槛。
## 1.3 安装与配置YOLOv8
为了充分利用YOLOv8,需要进行一系列的环境配置和安装步骤。这通常包括以下操作:
- **环境准备**:安装Python环境以及对应的依赖库,比如NumPy和OpenCV。
- **获取YOLOv8源码**:可以通过Git克隆YOLOv8的官方仓库。
- **编译和安装**:运行编译脚本进行YOLOv8的编译,并在本地环境中安装。
```bash
git clone https://github.com/ultralytics/yolov8
cd yolov8
pip install -r requirements.txt
```
完成上述步骤后,您就可以开始探索YOLOv8的其他功能,如训练模型、目标检测等。在继续深入之前,确保所有依赖都已正确安装且环境配置无误。
# 2. 数据预处理的艺术
## 2.1 数据集的准备和管理
### 2.1.1 数据集的选择与下载
数据集的选择是计算机视觉项目的基础,根据不同的需求,可能需要选择适合特定场景的数据集。例如,在进行自动驾驶汽车的目标检测时,通常需要使用KITTI、Cityscapes等专业数据集。而在通用的目标检测任务中,可以使用COCO、PASCAL VOC等流行数据集。
选择合适的现成数据集之后,下一步就是下载这些数据。通常,数据集提供方会有详细的下载指南,包括访问权限申请、下载链接以及数据集的组织结构说明等。这些步骤需要仔细阅读文档,确保数据的完整性。在某些情况下,数据集可能会非常庞大,因此需要考虑使用高速网络连接或者下载管理工具来优化下载过程。
### 2.1.2 数据集的标注工具与格式
完成数据集的下载后,我们需要进行数据标注,这是数据预处理的重要组成部分。标注工作通常涉及到为数据集中的每个图像中的对象定义边界框(bounding boxes)和其他可能的注释信息(例如,分割掩码、关键点等)。
有多种标注工具可用于此任务,包括开源的如LabelImg、CVAT等,以及商业产品如LabelBox、MakeSense.ai等。选择合适的工具后,接下来需要熟悉其标注格式。标注格式对后续的训练流程至关重要,因为模型训练通常需要特定格式的数据输入。例如,PASCAL VOC数据集使用XML格式,而YOLO格式通常要求将标注信息保存在文本文件中,每个图像对应一个文件。
### 2.1.2.1 标注工具的使用
以LabelImg工具为例,它的界面相对简洁,拥有直观的图形用户界面。用户可以通过它浏览图片,手动绘制边界框,并为每个边界框分配类别标签。完成标注后,工具可以导出为特定格式的文件,常见的格式有YOLO格式、Pascal VOC格式等。
### 2.1.2.2 标注格式的兼容性
在处理标注数据时,需要确保标注格式与YOLOv8训练脚本兼容。例如,YOLO格式要求每一行代表一个目标,包含以下信息:类别索引、中心点的x坐标、中心点的y坐标、宽度和高度。这些数据必须归一化到0到1的范围内,或者根据图片实际的宽度和高度进行缩放。
## 2.2 数据增强与扩充
### 2.2.1 常见的数据增强技术
数据增强(Data Augmentation)是提高模型泛化能力的重要技术。通过在训练数据上应用一系列随机变化,可以生成新的训练样本,从而增加模型对各种变化的适应能力。
常见数据增强技术包括:
- 随机裁剪(Random cropping)
- 颜色抖动(Color jittering)
- 旋转(Rotation)
- 缩放(Scaling)
- 翻转(Flipping)
- 噪声注入(Noise injection)
例如,旋转增强可以用来模拟目标在不同角度下的检测情况,而颜色抖动则有助于模型识别在不同光照条件下的目标。对于分类问题,颜色抖动特别有用,因为它可以模拟不同光照条件下的颜色变化。
### 2.2.2 数据扩充的策略与实现
数据扩充的一个重要策略是保持类别分布的一致性。这意味着扩充的数据应该与原始数据保持相同的类别比例,以避免引入偏差。实现数据扩充的一个有效方式是编写代码逻辑,使得在每个epoch中,数据通过增强技术随机选择。
下面是一个使用Python的代码示例,演示了如何实现常见的图像数据增强:
```python
import albumentations as A
from albumentations.pytorch import ToTensorV2
from torchvision.transforms import transforms
# 定义数据增强流程
data_transforms = A.Compose([
A.HorizontalFlip(p=0.5), # 以50%的概率进行水平翻转
A.Rotate(limit=45, p=0.7), # 以70%的概率在正负45度之间旋转
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
# 定义数据集类
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, image_paths, transform=None):
self.image_paths = image_paths
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, index):
image = cv2.imread(self.image_paths[index])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.transform:
image = self.transform(image=image)['image']
return image
# 使用自定义的Dataset
train_dataset = CustomDataset(train_image_paths, transform=data_transforms)
```
## 2.3 数据预处理的代码实践
### 2.3.1 编写数据预处理脚本
数据预处理脚本是将原始数据转化为模型可以接受的格式的关键。这通常包括读取图像数据,应用标注,并执行数据增强和格式转换等步骤。脚本通常会将处理后的数据保存为特定格式,以供训练脚本使用。
例如,YOLO格式要求每个图像对应一个.txt文件,文件中包含图像内每个目标的标注信息,下面是一个简单的数据预处理脚本示例:
```python
import os
import glob
import xml.etree.ElementTree as ET
import cv2
import numpy as np
def convert_annotation(xml_file, class_label_map):
# 解析标注文件
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
labels = []
bboxes = []
for obj in root.iter('object'):
cls = obj.find('name').text
label = class_label_map[cls]
difficult = obj.find('difficult').text
difficult = int(difficult)
if not difficult:
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bbox = [b[0]/w, b[1]/w, b[2]/h, b[3]/h]
bboxes.append(bbox)
labels.append(label)
return labels, bboxes
# ... 这里可以定义其他的数据预处理逻辑,比如数据增强和格式转换等
# 最后将处理后的数据保存到指定的文件中
```
### 2.3.2 脚本执行与效果验证
在编写完成数据预处理脚本后,需要执行脚本,并验证输出的数据是否符合预期。验证通常包括检查文件格式是否正确,数据是否完整以及是否能被训练脚本正确读取。
脚本执行可以通过命令行直接运行,例如,在Python中,可以使用如下命令:
```shell
python data_preprocessing_script.py
```
在数据预处理脚本执行后,需要进行验证,可以使用如下步骤:
1. 检查输出的文件是否存在,并且数量正确。
2. 手动检查几个输出文件,确认格式正确,并且数据看起来合理。
3. 尝试用训练脚本读取这些数据,看是否能够无错误地加载。
在验证过程中,可以使用日志文件记录所有步骤,便于追踪和调试。如果发现问题,需要回到脚本中修正,并重新进行验证。这个过程可能会迭代多次,直到确认数据预处理流程可以稳定工作。
# 3. YOLOv8模型训练与优化
## 3.1 训练前的模型配置
### 3.1.1 网络结构的选择与修改
在开始训练YOLOv8模型之前,选择合适的网络结构是至关重要的一步。YOLOv8提供了多种预定义的模型结构,从轻量级的小型网络到强大的大型网络,可以根据不同的应用需求和资源限制来选择。对于需要在边缘设备上部署的场景,小型网络如YOLOv8 Nano或YOLOv8 Tiny能够提供更好的速度和较低的延迟,而大型网络如YOLOv8 X则适合追求高精度的场合。
为了满足特定场景的需求,还可以对现有的网络结构进行修改。常见的修改手段包括改

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“YOLOv8的常见错误及解决方案”是一份全面指南,旨在帮助用户解决使用YOLOv8目标检测模型时遇到的各种问题。从入门基础到高级调试技巧,该专栏涵盖了常见的错误码解析、部署问题解决方案、数据增强策略、边缘设备优化、模型转换、可视化工具使用、模型压缩和自动驾驶应用等方面。通过深入剖析这些问题及其对应的解决方案,该专栏旨在帮助用户充分利用YOLOv8的强大功能,提高模型性能,并将其有效部署在各种场景中。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
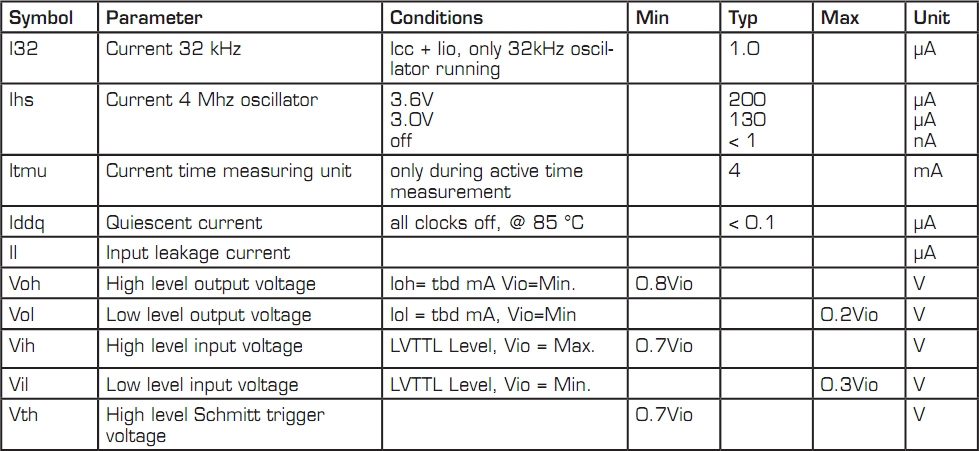
【TDC_GP22寄存器:性能与安全的双重保障】:核心功能深度剖析
# 摘要
TDC_GP22寄存器作为一项先进的技术组件,因其在性能和安全上的显著优势而在现代电子系统中扮演关键角色。本文首先概述了TDC_GP22寄存器的基本概念,随后深入探讨其性能优势,包括寄存器级优化的理论基础、性能特征,以及在高性能计算和实时系统中的应用。接着,本文分析了TDC_GP22的安全机制,涉及安全保护的理论基础、安全特性和
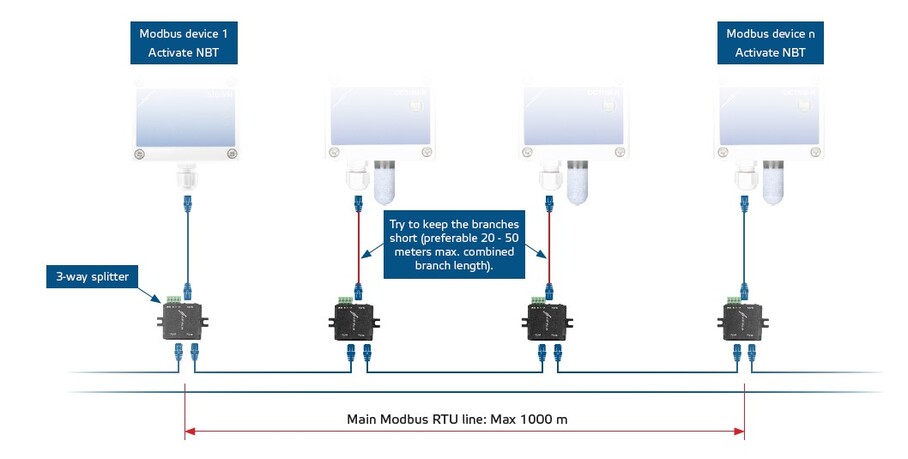
【昆仑通态Modbus RTU性能优化】:提升通信效率的策略
# 摘要
Modbus RTU协议作为一种广泛应用于工业自动化领域的通信协议,其性能优化对于确保系统的稳定性和效率至关重要。本文首先介绍了Modbus RTU协议的基础知识及其面临的性能挑战,随后深入探讨了通信效率的基础理论,包括协议结构、错误检测机制以及影响通信效率的关键因素如网络延迟、带宽和设备性能。在实践篇中,本文详细阐述了软件和硬件层面的性能优化技巧,以及调试工
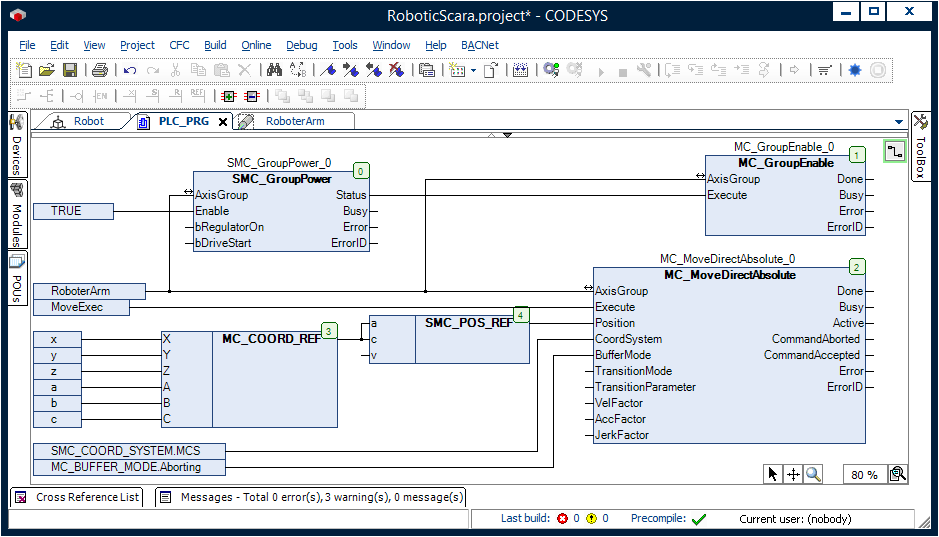
电子电器架构的创新应用:如何实现主机厂产线刷写的智能化演进
# 摘要
本文从电子电器架构与产线刷写的视角出发,探讨了智能化演进的理论基础与实践案例,以及其在主机厂的应用和未来发展趋势。通过对传统与现代电子电器架构的对比、智能化演进的关键驱动因素进行分析,本文阐述了智能化产线刷写的理论模型和实践应用,并着重讨论了实时数据处理、自动化工具的作用以及智能化技术在提升生产效率与客户体验中
TMCL-IDE调试技巧:7大高效解决编程问题的必杀技

# 摘要
本文深入介绍了TMCL-IDE的入门级使用方法和高级调试技巧,旨在帮助开发者和工程师提升编程调试的效率和质量。文章首先概述了TMCL-IDE的基础使用,随后详尽阐述了程序调试的理论基础,包括调试的概念、重要性、常见方法论以及最佳实践。紧接着,文章探讨了高级调试技巧,如使用断点、步进操作、内存和寄存器监控,以
Artix-7 FPGA深入解析:从新手到硬件设计大师

# 摘要
本文系统地介绍了Artix-7 FPGA的技术概览、硬件基础知识、设计流程以及在不同领域的应用实例。首先概述了FPGA的工作原理、关键硬件特性和开发调试工具。接着,详细阐述了Artix-7 FPGA的设计流程,包括需求分析、编码、仿真、综合和布局布线。文章进一步提供了数字信号处理、通信协议实现和自定义处理器核心三个应用实例,展示FPGA技术在实际中的应用和效果。最后,探讨了高级设计技巧、系统级集成方法以及
【移动存储故障快速诊断】:5分钟内解决移动存储连接问题
# 摘要
移动存储设备作为数据传输和备份的重要工具,其故障问题对用户数据安全和使用体验有着直接影响。本文首先概述了移动存储故障的类型和特征,随后介绍了移动存储设备的工作原理及技术标准。通过详细阐述连接与接口技术、数据传输协议,以及故障诊断与排查流程,本文旨在为用户和维护人员提供故障诊断与解决的方法。此外,文章还探讨了快速解决连接问题的实践操作,包括诊断工具的使用和故障修复技巧。高级应用章节专注于数据恢复与备份,提供了原理、工具使用技巧以及备份策略和案例研究,以帮助用户最大限度减少数据丢失的风险。
# 关键字
移动存储故障;工作原理;故障诊断;数据传输;数据恢复;备份策略
参考资源链接:[D
数据同步的艺术:扫号器数据一致性保持策略
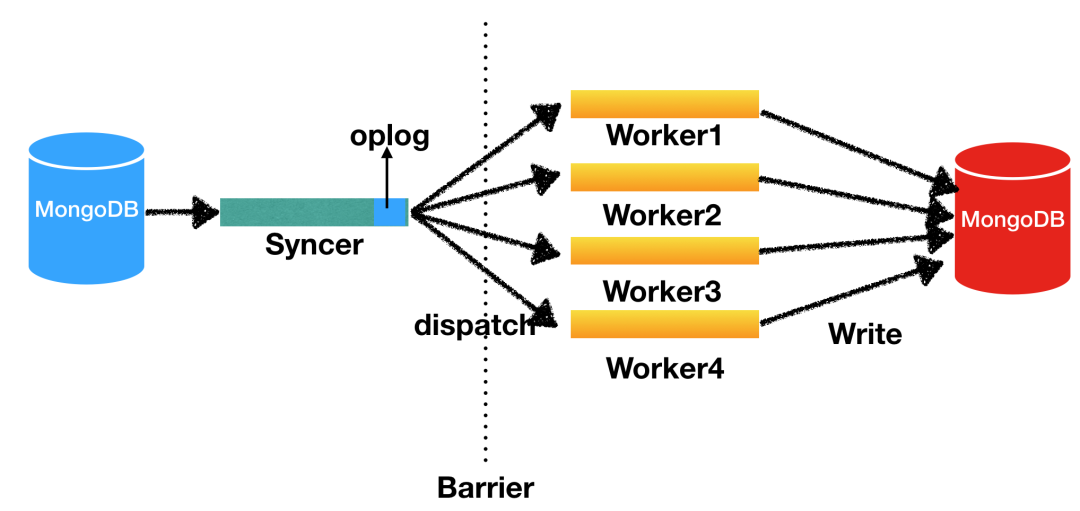
# 摘要
数据同步是确保数据一致性至关重要的过程,对于依赖于数据准确性的
Semtech SX1280 LoRa芯片权威指南
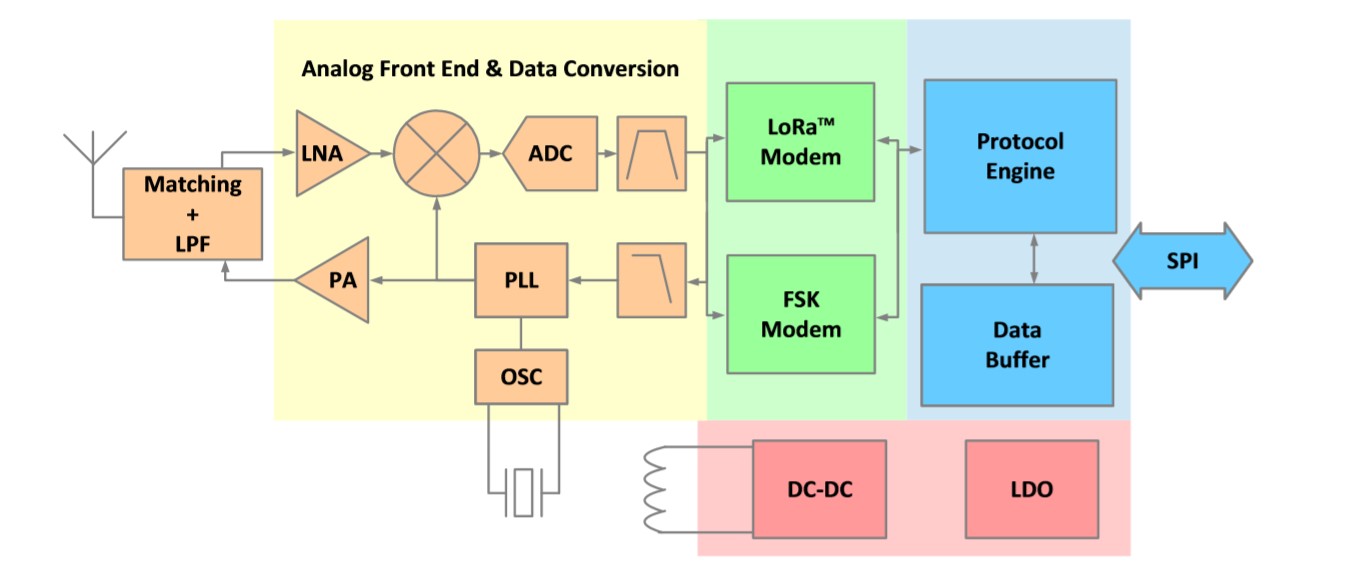
# 摘要
本文全面介绍了Semtech SX1280 LoRa芯片,包括其在LoRa技术中的应用、芯片硬件与软件特性以及在物联网中的实际应用案例。文中首先概述了SX1280芯片的基本信息及其在LoRa通信原理中的角色,深入解析了LoRa调制方式和扩频技术以及协议栈结构。接着,本文详述了SX1280的硬件架构、软件接口和低功耗设计,探讨了如何通过开发环境的搭建、程序设计和调试来实现高效开发
GS+操作基础:新手入门到地质数据分析专家的7步指南

# 摘要
GS+是一款集成了多种数据分析工具的软件,它在地质数据分析领域中扮演着重要的角色。本文介绍了GS+的基础操作、数据处理技巧、高级分析工具以及在地质数据分析中的应用案例。通过对基础数据操作的详尽阐述,包括数据的输入输出、处理流程、绘图技巧,以及更高级的统计分析、地质图件绘制和多变量空间分析方法,本文展示了GS+在地质领域的广泛适用性和强大的
【网络分析新视角】:PowerWorld节点与支路解构,深度应用探索

# 摘要
PowerWorld作为一种电力系统分析软件,广泛应用于电力网络的节点和支路解构、数据处理、故障诊断以及仿真技术研究。本文首先介绍了PowerWorld的基本概念和节点在电力系统中的角色,包括节点的定义、功能、数学模型及数据类型。随后,对支路的定义、电气特性、数据管理及故障处理进行了深入探讨。文章还分析了仿真技术在电力系统中的应用,包括仿真模型的建立
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )