YOLOv8边缘计算部署优化:针对IoT设备的策略(YOLOv8 IoT设备边缘计算优化)


YOLOv8的跨平台部署:实现多环境目标检测的灵活性与效率
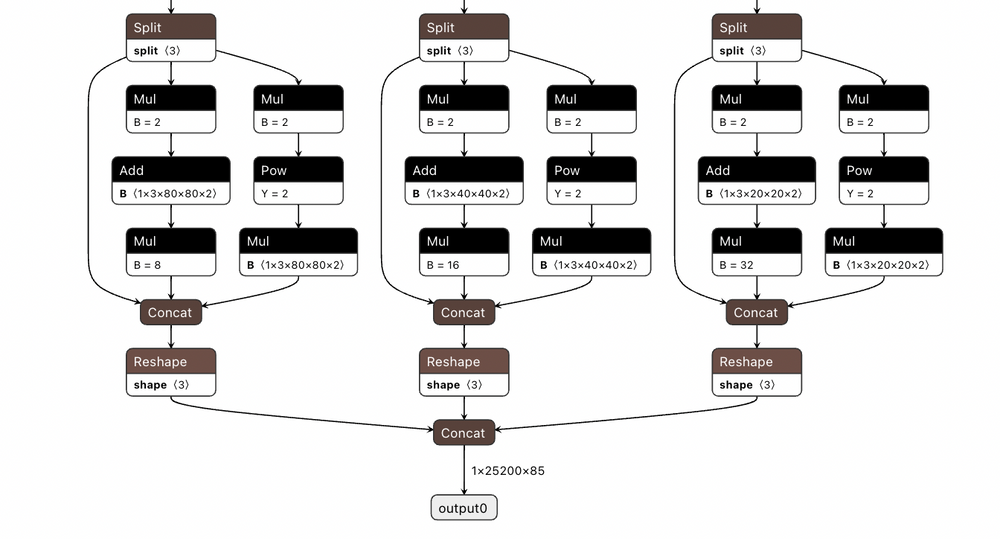
1. YOLOv8边缘计算概述
在当今世界,实时性与数据隐私性的需求日益增长,边缘计算作为一种在数据源附近进行处理的计算方式,正变得越来越重要。YOLOv8(You Only Look Once version 8)作为实时目标检测模型的最新演进版,其对边缘计算的支持为智能系统提供了强大的图像识别能力。本章将探讨YOLOv8如何在边缘计算领域中发挥作用,概述其在实时数据处理中的潜力和应用场景。
1.1 边缘计算的必要性
边缘计算将数据处理转移到网络边缘,靠近数据源,这显著减少了数据传输到云中心的时间,降低了延迟。它对于实时应用场景,如自动驾驶、视频监控和工业自动化等,尤为重要。边缘计算不仅改善了响应速度,还增强了数据隐私性和安全性,因为它允许只在必要时将数据发送到云端。
1.2 YOLOv8模型的引入
YOLOv8在实时性目标检测领域代表着前沿技术,特别是在其架构优化和速度性能方面。YOLOv8模型经过特别设计,以适应边缘设备的资源限制,同时保持高效的检测能力。它能够快速识别图像中的多个对象,并为边缘计算场景提供了一个强大且灵活的解决方案。
1.3 YOLOv8与边缘计算的结合
将YOLOv8集成到边缘计算平台,为各类IoT(物联网)设备提供了即时的、智能化的数据分析能力。例如,在智能安防监控场景,YOLOv8可以在边缘端实时检测和识别安全威胁,快速做出响应。这种结合不仅提高了响应速度,而且由于数据不需要在云端处理,还提升了数据的安全性和隐私性。
2. YOLOv8模型基础与部署要求
2.1 YOLOv8模型架构解析
2.1.1 YOLOv8的网络结构特点
YOLOv8 (You Only Look Once version 8) 代表了这一系列目标检测算法最新进展,它继承了YOLO系列快速准确的核心理念,并加入了多项创新改进。YOLOv8的网络结构主要特点包括:
- 简化的头结构:减少了检测头的复杂性,使用更少的参数,加速了推理时间。
- 改进的特征提取:引入了新的特征提取层,提高了模型对小目标的检测能力。
- 锚框聚类:通过对大量标注数据进行聚类分析,改进了锚框的尺寸和长宽比,使得模型能够更准确地定位不同尺寸的目标。
- 注意力机制:集成了注意力机制,增强对图像关键特征的捕获能力。
YOLOv8 采用了这些改进,使得模型不仅在速度上保持了YOLO系列的优势,同时在精度上也得到了大幅提升。
2.1.2 模型性能与优化策略
为了实现最优的模型性能,YOLOv8不仅在架构上进行了革新,还引入了一系列优化策略,其中包括:
- 损失函数的优化:通过改进损失函数,使得模型在训练过程中更快速地收敛,并更好地泛化到新的数据集。
- 锚框自适应调整:锚框的大小和比例不是固定不变的,而是根据实际数据集中的目标尺寸进行自适应调整。
- 数据增强技术:为了提高模型对各种情况的适应能力,YoloV8采用了多种数据增强技术,如随机裁剪、颜色抖动等。
- 训练技巧:使用诸如学习率退火、权重衰减等训练技巧来优化训练过程。
2.2 针对IoT设备的部署要求
2.2.1 IoT设备性能考量
对于IoT(Internet of Things)设备,由于其硬件资源通常较为有限,对模型的部署提出了更高的要求。部署YOLOv8到IoT设备时,需要考虑以下性能因素:
- 内存占用:YOLOv8模型在运行时的内存占用需要在IoT设备的内存限制之内。
- 计算能力:IoT设备的CPU/GPU计算能力需要能够满足YOLOv8的实时处理需求。
- 功耗限制:IoT设备往往工作在电池供电模式下,因此模型运行时的功耗也需要被考虑进去。
2.2.2 边缘计算的网络与安全需求
在边缘计算环境中部署YOLOv8模型,除了关注性能问题外,还需要考虑网络和安全方面的需求:
- 数据传输效率:保证模型预测结果和相关数据的快速上传与下载。
- 安全性:部署安全协议和加密措施来保护数据不被未授权访问或篡改。
在边缘计算场景中,由于数据处理和存储发生在网络边缘,可以减少对中心云的依赖,降低延迟,并提高数据处理的效率和安全性。这些要求促使我们必须对YOLOv8进行适当的优化,以便能够在IoT设备上有效部署。
根据本章节的内容,接下来的章节将继续深入探讨YOLOv8在边缘计算环境下的优化策略,以及如何在不同IoT设备上进行实际部署。我们将会了解硬件加速技术、软件优化技术、系统级优化策略,以及它们在提升部署效率和性能方面的具体应用。
3. 边缘计算环境下的YOLOv8优化策略
随着边缘计算技术的发展,YOLOv8模型在边缘设备上的实时性能和准确率成为了研究热点。本章将深入探讨如何在边缘计算环境下对YOLOv8进行优化,以实现更低延迟和更高效率的目标。
3.1 硬件加速技术的应用
3.1.1 利用GPU进行加速
在边缘设备上,GPU(图形处理单元)是实现高性能计算的重要硬件资源。利用GPU进行模型加速的主要方式包括利用其并行计算能力和优化的神经网络计算库。
代码示例:
- import torch
- import torchvision.transforms as transforms
- from torchvision.models.detection import fasterrcnn_resnet50_fpn
- from PIL import Image
- # 加载预训练的模型
- model = fasterrcnn_resnet50_fpn(pretrained=True)
- model.eval()
- # 图像预处理
- transform = transforms.Compose([
- transforms.ToTensor()
- ])
- image = Image.open("example.jpg")
- tensor_image = transform(image).unsqueeze(0)
- # 在GPU上执行模型推理
- if torch.cuda.is_available():
- model = model.cuda()
- tensor_image = tensor_image.cuda()
- with torch.no_grad():
- prediction = model(tensor_image)
逻辑分析及参数说明:
上述代码展示了如何使用PyTorch加载一个预训练的 Faster R-CNN 模型,并将其推送到GPU上执行。需要注意的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
简易单片机系统构建:流水灯项目实战技巧
【仿真环境优化】:打造线路阻抗仿真效率新高点
ClustalX与MUSCLE对决:选择最适合你的多序列比对神器
【VMWare vCenter高级配置秘笈】:打造顶级虚拟化平台
【数据预测准确性】:莫兰指数与克里金插值的结合应用
【数据传输效率革命】:压缩与流媒体传输技术在HDP直播中的应用
【电源设计精进】:揭秘LLC开关电源计算的艺术(速学指南)
【AI扩写与SEO优化】:掌握技巧,提高微头条在平台上的曝光率
【IoT专业术语探索】:韦氏词典助你在物联网技术领域一臂之力!
嵌入式C语言数据结构:优化技巧与应用实战


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )