YOLOv8架构革新解析:新框架下的性能提升机制(YOLOv8架构革新与性能提升)
发布时间: 2024-12-12 05:56:30 阅读量: 10 订阅数: 19 

YOLOv8:锚框设计的革新与实践
# 1. YOLOv8架构革新概述
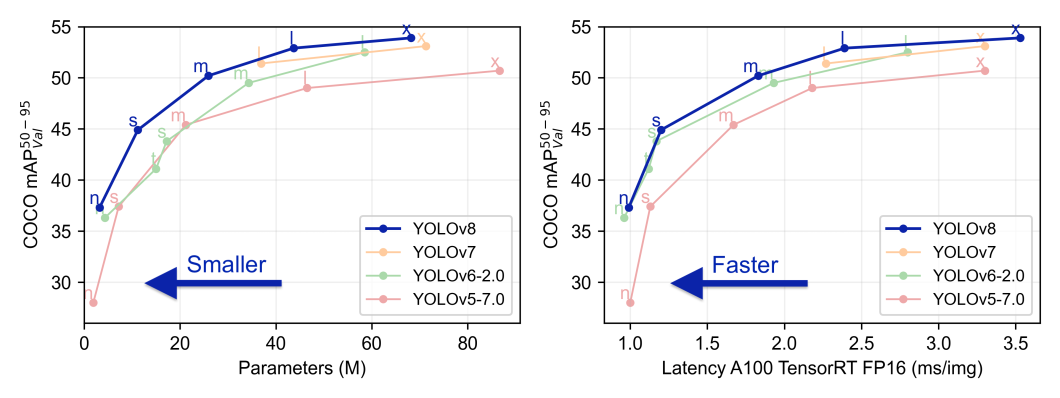
YOLOv8作为实时目标检测领域的新星,它的发布标志着该领域的一次重大技术进步。与前一代的YOLO模型相比,YOLOv8不仅提升了检测的精度和速度,还在架构上实现了创新性的突破。本章将介绍YOLOv8的核心架构,并简要探讨它与以往版本的主要区别。
## 1.1 简述YOLOv8的创新点
YOLOv8的一个主要创新点在于其新型的网络架构设计,该设计显著提高了模型处理大规模数据集时的效率。其主要优化包括:
- 精简且高效的特征提取网络结构;
- 改进的损失函数,以更好地适应各类目标检测场景;
- 强化了模型在不同尺度目标上的识别能力。
YOLOv8在保持实时性的同时,通过这些改进显著增强了模型的鲁棒性和泛化能力,这对于推进计算机视觉在实际应用中的落地具有重要的意义。
# 2. YOLOv8的理论基础与关键技术
## 2.1 理解YOLOv8的基础架构
### 2.1.1 YOLOv8的基本组成与工作流程
YOLOv8作为目标检测领域中的佼佼者,其架构设计充分体现了效率与准确性的结合。YOLOv8的基础架构由输入图像预处理、特征提取网络、目标检测头和后处理等主要模块构成。
- **输入图像预处理**:对于输入图像进行必要的调整,比如尺寸缩放、归一化等,以便进行后续的处理。
- **特征提取网络**:YOLOv8使用了深度卷积神经网络(CNN)作为其核心的特征提取器。较之前版本,YOLOv8可能引入了新的网络架构或改进现有结构,以提取更为丰富的图像特征。
- **目标检测头**:在特征提取基础上,YOLOv8增加了专门用于目标定位和分类的检测头。此检测头包含多个输出分支,每个分支负责不同的检测任务,例如边界框回归、类别概率计算以及锚点尺寸的预测。
- **后处理**:包括非极大值抑制(NMS)和置信度阈值过滤等步骤,用于最终生成的目标边界框和类别。
```python
# 示例代码:YOLOv8的输入预处理函数
def preprocess_image(image, target_size):
# 将图像缩放到目标尺寸
image_resized = cv2.resize(image, target_size)
# 归一化图像数据
image_normalized = image_resized / 255.0
# 增加一个维度,适配网络输入
image_batch = np.expand_dims(image_normalized, axis=0)
return image_batch
# 预处理输入图像
input_image = cv2.imread("path_to_image.jpg")
preprocessed_image = preprocess_image(input_image, (640, 640))
```
### 2.1.2 YOLOv8与其他版本的对比分析
从YOLO系列的发展来看,YOLOv8代表了最新的一代技术演进。它在继承了YOLOv5的高效架构基础上,进一步在精度和速度上取得提升。
- **YOLOv5对比**:YOLOv5已经非常注重推理速度,主要体现在模型参数的减少和网络结构的简化。而YOLOv8可能通过引入新的深度学习技巧,例如注意力机制、更有效的锚点策略,以及可能的模型剪枝等技术,进一步提升了模型性能。
- **YOLOv7对比**(假设存在):如果YOLOv7存在的话,YOLOv8可能会更进一步提升动态尺度预测(DyHead)的效率,增强特征融合机制,以及增加端到端的学习能力。
```mermaid
graph LR
A[YOLOv4] -->|继承| B[YOLOv5]
B -->|改进| C[YOLOv6]
C -->|创新| D[YOLOv7]
D -->|升级| E[YOLOv8]
```
## 2.2 YOLOv8的关键技术突破
### 2.2.1 锚点策略的改进
锚点(anchor)是目标检测中用于定义边界框的先验知识。它们的形状和尺寸对于检测的精度有着直接影响。YOLOv8针对锚点策略进行了创新性改进。
- **自适应锚点**:YOLOv8可能使用数据驱动的方式,自适应地调整锚点大小和形状,以适应不同尺寸和比例的目标。
- **锚点聚类**:对大量数据集进行聚类分析,找到最优锚点配置,从而提高检测的准确度。
```python
# 示例代码:使用K-means聚类确定锚点
from sklearn.cluster import KMeans
# 假设 ground_truth_boxes 是一系列真实边界框
ground_truth_boxes = ...
# 使用K-means确定最佳锚点
kmeans = KMeans(n_clusters=9)
anchors = kmeans.fit_predict(ground_truth_boxes)
print("确定的锚点为:", anchors)
```
### 2.2.2 动态尺度预测(DyHead)的引入
动态尺度预测(DyHead)是YOLOv8中的一个创新点,它能够动态地调整检测头的尺度以适应不同大小的目标。
- **多尺度特征融合**:DyHead将来自不同尺度的特征图进行融合,使得网络能够更好地处理尺度变化多端的目标。
- **尺度感知机制**:通过引入尺度感知的注意力机制,DyHead让网络能够更加专注于关键的尺度信息。
### 2.2.3 多尺度特征融合策略
多尺度特征融合是YOLOv8的另一个关键创新点,它允许模型综合不同尺度上的信息,增强对目标的识别能力。
- **特征金字塔网络(FPN)**:通过构建特征金字塔,不同层次的特征图可以携带不同尺度的上下文信息,有效提高小目标的检测性能。
- **上下文感知**:通过融合高层语义信息和低层细节信息,模型能够对目标的上下文环境有更全面的理解。
## 2.3 YOLOv8的性能优化
### 2.3.1 训练速度与推理效率的优化
YOLOv8在设计上非常注重效率。通过减少模型参数、优化网络结构设计等方式,YOLOv8实现了在保证精度的同时提升训练速度和推理效率。
- **更高效的网络架构**:YOLOv8可能采用了类似MobileNet、ShuffleNet等轻量级网络结构,以减少计算量。
- **模型剪枝**:通过移除冗余或不重要的参数来简化模型,同时保持性能不变。
```python
# 示例代码:模型剪枝后对模型大小和速度的影响
import torch.nn.utils.prune as prune
# 假设 model 是需要剪枝的模型
prune.l1_unstructured(model, name="weight", amount=0.1)
# 测试剪枝后的模型大小
total_size = sum(p.numel() for p in model.parameters())
print("剪枝后的模型大小:", total_size)
# 测试推理速度
input = torch.randn(1, 3, 224, 224) # 输入数据
output = model(input) # 前向传播
```
### 2.3.2 模型压缩与加速技术
为了进一步提高模型的部署效率,YOLOv8引入了多种模型压缩和加速技术。
- **量化**:将模型中的浮点数权重转换为低精度的整数表示,减少模型大小,加快计算速度。
- **知识蒸馏**:将大型、复杂的模型的"知识"转移到更小的模型中,保持精度的同时加速推理。
```mermaid
graph TD
A[训练大型模型] --> B[知识蒸馏]
B --> C[得到小型模型]
C --> D[量化模型]
D --> E[部署到边缘设备]
```
以上就是对YOLOv8基础架构和技术突破的深入分析,下一部分将介绍YOLOv8在实践应用与案例分析中的表现。
# 3. YOLOv8的实践应用与案例分析
## 3.1 YOLOv8在目标检测任务中的应用
### 3.1.1 YOLOv8在静态图像检测的实践
在静态图像检测的实践中,YOLOv8表现出了比以往版本更高的准确度和更快的处理速度。YOLOv8采用了更为复杂的网络结构和先进的特征提取技术,使其在检测静态图像中的对象时,不仅能够快速识别出对象的位置和类别,而且还能准确地划分出对象的轮廓。下面的代码块展示了如何使用YOLOv8模型进行静态图像的目标检测。
```python
import torch
import cv2
from PIL import Image
# 加载YOLOv8模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov8.pt', force_reload=True)
# 读取静态图像
img = Image.open('static_image.jpg')
# 进行目标检测
results = model(img)
# 结果处理
results.print()
results.show()
# 获取检测框坐标及类别信息
results.xyxy[0].shape # 输出:(num_detections, 6),其中6个参数分别是:类别索引、置信度、x1、y1、x2、y2
```
在上述代码中,首先通过PyTorch Hub加载了预训练的YOLOv8模型,并通过自定义参数路径`custom`指定了本地模型文件。之后,使用PIL库加载静态图像,并将图像传递给模型进行检测。`results`对象包含了检测结果,包含了检测框、置信度、类别等信息。通过访问`results.xyxy[0]`可以获取检测到的对象的坐标和类别信息。
### 3.1.2 YOLOv8在视频流检测的实践
视频流目标检测是YOLOv8的另一个重要应用场景。与静态图像检测类似,YOLOv8能够实时处理视频帧,并对每一帧图像进行目标检测。这为实时监控、视频分析等应用提供了强大的技术支持。下面的代码块展示了如何使用YOLOv8模型进行视频流目标检测。
```python
import cv2
# 加载YOLOv8模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov8.pt', force_reload=T
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《YOLOv8与其他版本YOLO的比较》深入探讨了YOLOv8与前代版本以及竞争对手之间的性能差异。它涵盖了YOLOv8的全面解析、从YOLOv1到YOLOv8的演进、与YOLOv7和v5的深入对比、优化策略分析、TensorRT优化比较、架构革新、跨平台部署指南、多GPU性能调优、边缘计算优化、多任务学习策略、量化训练指南、超参数调优方法、对抗样本防御和NPU部署挑战。通过对这些主题的全面分析,专栏为读者提供了对YOLOv8及其在目标检测领域的地位的深入了解。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电力驱动系统安全风险评估】:IEC 61800-5-1标准下的风险分析技巧

参考资源链接:[最新版IEC 61800-5-1标准:电力驱动系统安全要求](https://wenku.csdn.net/doc/7dpwnubzwr?spm=1055.2635.3001.10343)
# 1. IEC 61800-5-1标准概述
IEC 6
【硬件更新与维护攻略】:TIA博途V16维护经验分享

参考资源链接:[TIA博途V16仿真问题全解:启动故障与解决策略](https://wenku.csdn.net/doc/4x9dw4jntf?spm=1055.2635.3001.10343)
# 1. TIA博途V16基础介绍
## 1.1 TIA博途V16概览
TIA博途(Totally Integrated Automation Portal)是西门子公司
Altium 设计者的挑战:15分钟内解决元器件间距过小问题
参考资源链接:[altium中单个元器件的安全间距设置](https://wenku.csdn.net/doc/645e35325928463033a48e73?spm=1055.2635.3001.10343)
# 1. Altium Designer中的元器件布局挑战
在当今的电子设计自
MATLAB信号处理全攻略:一步到位掌握入门到高级技巧(限时免费教程)

参考资源链接:[MATLAB信号处理实验详解:含源代码的课后答案](https://wenku.csdn.net/doc/4wh8fchja4?spm=1055.2635.3001.10343)
# 1. MATLA
【BMC管理控制器深度剖析】:戴尔服务器专家指南

参考资源链接:[戴尔 服务器设置bmc](https://wenku.csdn.net/doc/647062d0543f844488e4644b?spm=1055.2635.3001.10343)
# 1. BMC管理控制器概述
BMC(Baseboard Management Controller)管理控制器是数据中心和企业级计算领域的核心组件之一。它负责监控和管理服务器的基础硬
PSCAD C语言接口实战秘籍:从零到精通的7天速成计划

参考资源链接:[PSCAD 4.5中C语言接口实战:简易积分器开发教程](https://wenku.csdn.net/doc/6472bc52d12cbe7ec306319f?spm=1055.2635.3001.10343)
# 1. PSCAD软件概述与C语言接口简介
在现代电力系统仿真领域,PSCAD(Power Systems Computer Aide
RK3588射频设计与布局:提升无线通信性能的关键技巧
参考资源链接:[RK3588硬件设计全套资料,原理图与PCB文件下载](https://wenku.csdn.net/doc/89nop3h5n
微信视频通话质量提升必杀技:虚拟摄像头高级设置全解

参考资源链接:[使用VTube Studio与OBS Studio在微信进行虚拟视频通话的探索](https://wenku.csdn.net/doc/85s1wr0wvy?spm=1055.2635.3001.10343)
# 1. 虚拟摄像头技术概述
在信息技术高速发展的今天,虚拟摄像头技术以其独特的魅力,成为了一个引人注目的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )