揭秘模糊逻辑系统在决策支持中的作用:案例分析与最佳实践
发布时间: 2024-08-21 12:40:36 阅读量: 176 订阅数: 24 
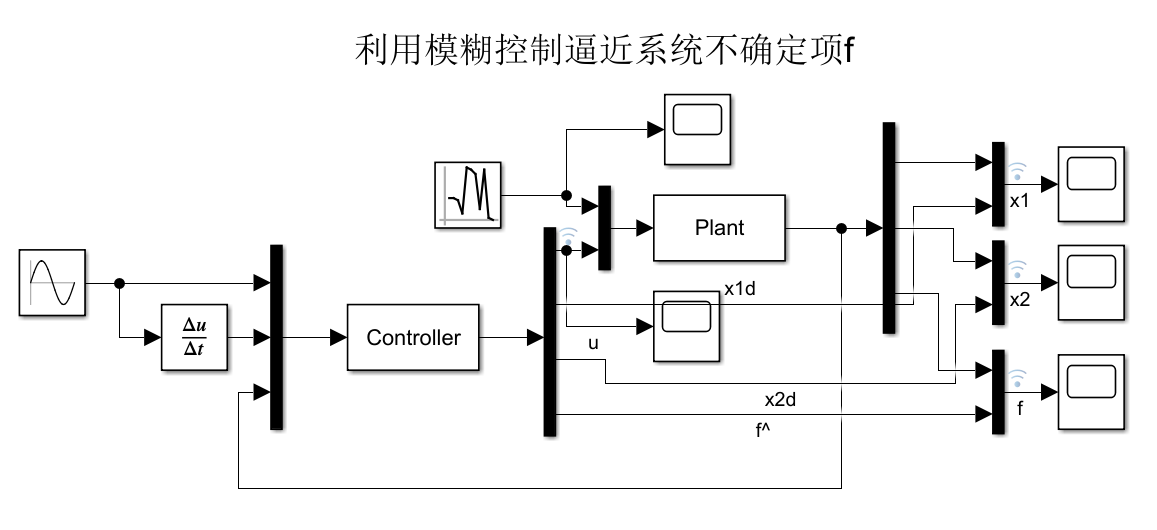
# 1. 模糊逻辑系统概述**
模糊逻辑系统是一种处理不确定性和模糊性的计算模型。它基于模糊集合理论,该理论允许元素具有部分成员资格。模糊逻辑系统由以下组件组成:
- 模糊化器:将输入变量转换为模糊集合。
- 模糊规则库:包含一系列模糊规则,定义了系统如何根据输入做出决策。
- 模糊推理机:使用模糊规则库对输入变量进行推理,产生模糊输出。
- 解模糊化器:将模糊输出转换为清晰输出。
# 2. 模糊逻辑系统在决策支持中的应用
### 2.1 模糊逻辑系统在决策中的优势
模糊逻辑系统在决策支持中具有以下优势:
- **处理不确定性和模糊性:**模糊逻辑系统可以处理不确定性和模糊性,这在现实世界决策中很常见。它允许决策者使用模糊变量和规则来表达他们的知识和经验。
- **模拟人类推理:**模糊逻辑系统使用类似于人类推理的规则和推理机制,使其能够模拟人类决策者的思维过程。
- **鲁棒性和适应性:**模糊逻辑系统对输入数据的变化具有鲁棒性,并且可以随着新信息的出现而适应。
- **可解释性:**模糊逻辑系统的规则和推理过程易于理解和解释,这有助于决策者理解系统的决策。
### 2.2 模糊逻辑系统在决策支持中的实际案例
模糊逻辑系统已成功应用于各种决策支持领域,包括:
- **医疗诊断:**模糊逻辑系统用于诊断疾病,如癌症和心脏病,利用模糊规则将患者症状映射到疾病概率。
- **金融预测:**模糊逻辑系统用于预测股票价格和市场趋势,通过模糊规则整合经济指标和市场情绪。
- **制造业控制:**模糊逻辑系统用于控制制造过程,如机器人操作和过程优化,利用模糊规则将传感器数据映射到控制动作。
- **交通管理:**模糊逻辑系统用于管理交通流量,如信号灯控制和路线规划,利用模糊规则优化交通流和减少拥堵。
**示例:模糊逻辑系统在医疗诊断中的应用**
以下是一个使用模糊逻辑系统进行医疗诊断的示例:
```python
# 导入必要的库
import numpy as np
import skfuzzy as fuzz
# 定义模糊变量
symptoms = ['发烧', '咳嗽', '喉咙痛', '流鼻涕']
disease = ['流感', '普通感冒', '肺炎']
# 定义模糊集
fever = fuzz.trimf(symptoms, [0, 38, 40])
cough = fuzz.trimf(symptoms, [0, 5, 10])
sore_throat = fuzz.trimf(symptoms, [0, 3, 6])
runny_nose = fuzz.trimf(symptoms, [0, 2, 4])
flu = fuzz.trimf(disease, [0, 0.5, 1])
cold = fuzz.trimf(disease, [0, 0.5, 1])
pneumonia = fuzz.trimf(disease, [0, 0.5, 1])
# 定义模糊规则
rules = [
fuzz.Rule(fever['high'] & cough['high'] & sore_throat['high'] & runny_nose['high'], flu['high']),
fuzz.Rule(fever['medium'] & cough['medium'] & sore_throat['medium'] & runny_nose['medium'], cold['high']),
fuzz.Rule(fever['low'] & cough['low'] & sore_throat['low'] & runny_nose['low'], pneumonia['high'])
]
# 输入患者症状
patient_symptoms = [39, 7, 5, 3]
# 模糊化输入
fever_level = fuzz.interp_membership(symptoms, fever, patient_symptoms[0])
cough_level = fuzz.interp_membership(symptoms, cough, patient_symptoms[1])
sore_throat_level = fuzz.interp_membership(symptoms, sore_throat, patient_symptoms[2])
runny_nose_level = fuzz.interp_membership(symptoms, runny_nose, patient_symptoms[3])
# 应用模糊规则
activated_rules = []
for rule in rules:
firing_strength = rule.antecedent.membership_grade(fever_level, cough_level, sore_throat_level, runny_nose_level)
if firing_strength > 0:
activated_rules.append((rule, firing_strength))
# 聚合模糊输出
aggregated_output = np.zeros_like(disease)
for rule, firing_strength in activated_rules:
aggregated_output = np.fmax(aggregated_output, firing_strength * rule.consequent)
# 反模糊化输出
diagnosis = fuzz.defuzz(disease, aggregated_output, 'centroid')
# 打印诊断结果
print(f"诊断结果:{diagnosis}")
```
**代码逻辑分析:**
1. 导入必要的库。
2. 定义模糊变量:症状和疾病。
3. 定义模糊集:使用三角形隶属函数定义症状和疾病的模糊集。
4. 定义模糊规则:使用模糊规则将症状映射到疾病概率。
5. 输入患者症状:获取患者的症状值。
6. 模糊化输入:将患者症状模糊化为模糊变量。
7. 应用模糊规则:根据模糊规则计算每个规则的激发强度。
8. 聚合模糊输出:聚合所有激发规则的模糊输出。
9. 反模糊化输出:将聚合模糊输出反模糊化为疾病概率。
10. 打印诊断结果:输出疾病诊断。
# 3. 模糊逻辑系统设计与实现
### 3.1 模糊逻辑系统的架构和组件
模糊逻辑系统通常由以下组件组成:
- **模糊化器:**将输入变量转换为模糊变量。
- **模糊规则库:**包含模糊规则,这些规则定义了输入变量和输出变量之间的关系。
- **推理引擎:**使用模糊规则和模糊推理方法来推导出输出变量。
- **去模糊化器:**将模糊输出变量转换为清晰输出变量。
### 3.2 模糊逻辑系统的建模与仿真
模糊逻辑系统的建模和仿真是一个迭代过程,涉及以下步骤:
1. **定义输入和输出变量:**确定模糊逻辑系统将处理的输入和输出变量。
2. **创建模糊集合:**为每个输入和输出变量定义模糊集合,这些集合代表变量的不同值。
3. **建立模糊规则库:**根据专家知识或数据分析,制定模糊规则。
4. **选择推理方法:**选择一种模糊推理方法,例如 Mamdani 或 Sugeno 方法。
5. **仿真系统:**使用输入数据仿真模糊逻辑系统,并观察输出。
6. **调整模型:**根据仿真结果,调整模糊集合、规则或推理方法,以提高系统性能。
### 代码块示例
以下 Python 代码展示了如何使用 Mamdani 推理方法实现模糊逻辑系统:
```python
import numpy as np
import skfuzzy as fuzz
# 定义输入变量
input_var = np.arange(0, 101, 1)
# 定义模糊集合
low = fuzz.trimf(input_var, [0, 0, 50])
medium = fuzz.trimf(input_var, [0, 50, 100])
high = fuzz.trimf(input_var, [50, 100, 100])
# 定义输出变量
output_var = np.arange(0, 101, 1)
# 定义模糊集合
low_output = fuzz.trimf(output_var, [0, 0, 50])
medium_output = fuzz.trimf(output_var, [0, 50, 100])
high_output = fuzz.trimf(output_var, [50, 100, 100])
# 定义模糊规则
rules = [
fuzz.Rule(low, low_output),
fuzz.Rule(medium, medium_output),
fuzz.Rule(high, high_output)
]
# 仿真系统
input_value = 75
output = fuzz.centroid(output_var, fuzz.interp_membership(input_var, low, input_value))
print(output)
```
### 逻辑分析和参数说明
- **模糊化器:** `fuzz.trimf()` 函数用于创建三角形模糊集合,它需要三个参数:左边界、峰值和右边界。
- **推理引擎:** Mamdani 推理方法使用最小-最大推理来计算输出隶属度。
- **去模糊化器:** `fuzz.centroid()` 函数用于计算输出变量的质心,它返回一个清晰值。
- **仿真:** `input_value` 是输入变量的值,`output` 是模糊逻辑系统输出的清晰值。
# 4. 模糊逻辑系统优化与评估
### 4.1 模糊逻辑系统的参数优化方法
模糊逻辑系统的性能受其参数的影响,包括模糊集的定义、规则库和推理机制。参数优化旨在调整这些参数以提高系统的性能。常用的优化方法包括:
- **梯度下降法:**一种迭代算法,通过计算性能指标的梯度并沿着梯度方向调整参数来优化系统。
```python
import numpy as np
def gradient_descent(params, learning_rate, num_iterations):
for i in range(num_iterations):
gradient = compute_gradient(params)
params -= learning_rate * gradient
```
- **遗传算法:**一种受进化论启发的算法,通过选择、交叉和变异操作来优化参数。
```python
import random
def genetic_algorithm(params, population_size, num_generations):
population = generate_population(params, population_size)
for i in range(num_generations):
population = select_parents(population)
population = crossover(population)
population = mutate(population)
```
- **粒子群优化:**一种受鸟群行为启发的算法,通过粒子之间的信息共享来优化参数。
```python
import numpy as np
def particle_swarm_optimization(params, num_particles, num_iterations):
particles = generate_particles(params, num_particles)
for i in range(num_iterations):
for particle in particles:
particle.update_velocity()
particle.update_position()
```
### 4.2 模糊逻辑系统的性能评估指标
评估模糊逻辑系统的性能至关重要,以确定其有效性和准确性。常用的评估指标包括:
- **准确率:**预测值与实际值之间的匹配程度。
- **召回率:**系统正确识别正例的比例。
- **F1 分数:**准确率和召回率的加权平均值。
- **均方根误差(RMSE):**预测值与实际值之间的平均平方差。
```python
from sklearn.metrics import accuracy_score, recall_score, f1_score, mean_squared_error
def evaluate_fuzzy_system(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
return accuracy, recall, f1, rmse
```
### 4.3 模糊逻辑系统优化与评估的交互
模糊逻辑系统的优化和评估是相互关联的过程。通过评估系统的性能,可以识别需要优化的参数。优化后,系统性能得到提高,评估指标也相应提高。这种迭代过程有助于创建具有最佳性能的模糊逻辑系统。
```mermaid
graph LR
subgraph 优化
A[参数优化] --> B[性能评估]
end
subgraph 评估
C[性能评估] --> D[优化需求]
end
A --> C
D --> B
```
# 5. 模糊逻辑系统在决策支持中的最佳实践
### 5.1 模糊逻辑系统在决策支持中的应用场景
模糊逻辑系统在决策支持中具有广泛的应用场景,包括但不限于:
- **风险评估:**评估投资、项目或决策的潜在风险,并根据模糊变量(如市场不确定性、竞争强度)做出明智的决定。
- **故障诊断:**分析复杂系统中的故障模式,并根据模糊症状(如振动、噪音)确定可能的故障原因。
- **预测建模:**预测未来事件或趋势,例如销售额、客户流失或经济增长,基于模糊输入(如消费者偏好、市场条件)。
- **决策优化:**优化决策变量,例如资源分配、生产计划或投资组合管理,以最大化目标函数,同时考虑模糊约束(如预算限制、时间限制)。
- **知识管理:**捕获和表示专家知识,以便在决策过程中使用,例如医疗诊断、法律咨询或财务规划。
### 5.2 模糊逻辑系统在决策支持中的实施指南
实施模糊逻辑系统进行决策支持时,应遵循以下指南:
1. **明确决策问题:**定义决策目标、约束和模糊变量。
2. **收集数据:**收集有关模糊变量和决策结果的历史数据或专家意见。
3. **建立模糊逻辑模型:**使用模糊规则和模糊推理机制创建模糊逻辑模型,将模糊输入映射到决策输出。
4. **验证和优化模型:**使用验证数据测试模型的准确性和鲁棒性,并根据需要调整模糊规则和参数。
5. **集成到决策支持系统:**将模糊逻辑模型集成到现有的决策支持系统中,提供模糊推理功能。
6. **持续监控和评估:**定期监控模型的性能,并根据需要进行调整或重新训练,以确保持续的准确性和有效性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
模糊逻辑系统应用专栏深入探讨了模糊逻辑系统在广泛领域的应用,从决策支持和图像处理到自然语言处理和专家系统。它提供了从基础概念到高级应用的全面指南,包括案例分析、最佳实践和创新应用。专栏重点介绍了模糊逻辑系统在增强系统鲁棒性、提升适应能力、赋予机器人智能决策能力、提高医疗诊断准确性、优化供应链效率、应对复杂系统的不确定性、量化风险、寻找最佳解决方案、提取有价值的见解、增强机器学习算法的鲁棒性、构建智能知识库、打造个性化舒适体验、提升用户体验、实现智能决策和优化生产流程等方面的优势。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【跨模块协同效应】:SAP MM与PP结合优化库存管理的5大策略

# 摘要
本文旨在探讨SAP MM(物料管理)和PP(生产计划)模块在库存管理中的核心应用与协同策略。首先介绍了库存管理的基础理论,重点阐述了SAP MM模块在材料管理和库存控制方面的作用,以及PP模块如何与库存管理紧密结合实现生产计划的优化。接着,文章分析了SAP MM与PP结合的协同策略,包括集成供应链管理和需求驱动的库存管理方法,以减少库存
【接口保护与电源管理】:RS232通信接口的维护与优化
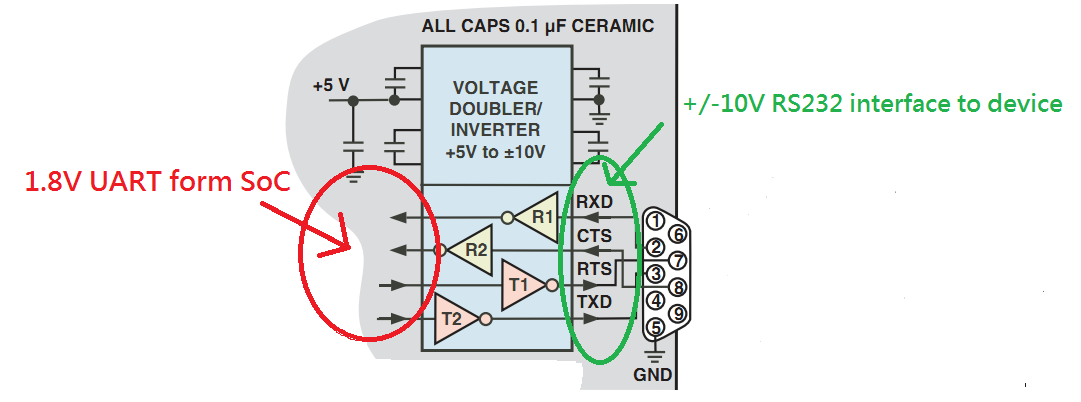
# 摘要
本文全面探讨了RS232通信接口的设计、保护策略、电源管理和优化实践。首先,概述了RS232的基本概念和电气特性,包括电压标准和物理连接方式。随后,文章详细分析了接口的保护措施,如静电和过电压防护、物理防护以及软件层面的错误检测机制。此外,探讨了电源管理技术,包括低功耗设计和远程通信设备的案例
零基础Pycharm教程:如何添加Pypi以外的源和库

# 摘要
Pycharm作为一款流行的Python集成开发环境(IDE),为开发人员提供了丰富的功能以提升工作效率和项目管理能力。本文从初识Pycharm开始,详细介绍了环境配置、自定义源与库安装、项目实战应用以及高级功能的使用技巧。通过系统地讲解Pycharm的安装、界面布局、版本控制集成,以及如何添加第三方源和手动安装第三方库,本文旨在帮助读者全面掌握Pycharm的使用,特
【ArcEngine进阶攻略】:实现高级功能与地图管理(专业技能提升)

# 摘要
本文深入介绍了ArcEngine的基本应用、地图管理与编辑、空间分析功能、网络和数据管理以及高级功能应用。首先,本文概述了ArcEngine的介绍和基础使用,然后详细探讨了地图管理和编辑的关键操作,如图层管理、高级编辑和样式设置。接着,文章着重分析了空间分析的基础理论和实际应用,包括缓冲区分析和网络分析。在此基础上,文章继续阐述了网络和数据库的基本操作
【VTK跨平台部署】:确保高性能与兼容性的秘诀

# 摘要
本文详细探讨了VTK(Visualization Toolkit)跨平台部署的关键方面。首先概述了VTK的基本架构和渲染引擎,然后分析了在不同操作系统间进行部署时面临的挑战和优势。接着,本文提供了一系列跨平台部署策略,包括环境准备、依赖管理、编译和优化以及应用分发。此外,通过高级跨平台功能的
函数内联的权衡:编译器优化的利与弊全解
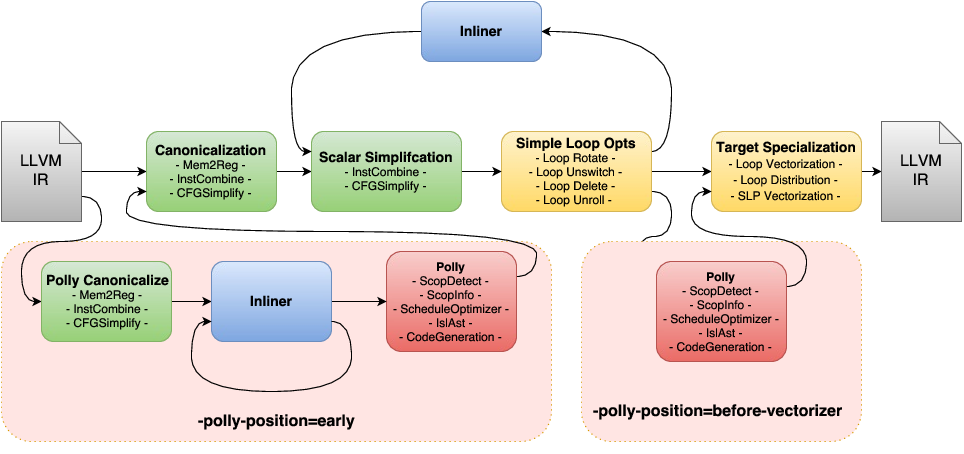
# 摘要
函数内联是编译技术中的一个优化手段,通过将函数调用替换为函数体本身来减少函数调用的开销,并有可能提高程序的执行效率。本文从基础理论到实践应用,全面介绍了函数内联的概念、工作机制以及与程序性能之间的关系。通过分析不同编译器的内联机制和优化选项,本文进一步探讨了函数内联在简单和复杂场景下的实际应用案例。同时,文章也对函数内联带来的优势和潜在风险进行了权衡分析,并给出了相关的优化技
【数据处理差异揭秘】

# 摘要
数据处理是一个涵盖从数据收集到数据分析和应用的广泛领域,对于支持决策过程和知识发现至关重要。本文综述了数据处理的基本概念和理论基础,并探讨了数据处理中的传统与现代技术手段。文章还分析了数据处理在实践应用中的工具和案例,尤其关注了金融与医疗健康行业中的数据处理实践。此外,本文展望了数据处理的未来趋势,包括人工智能、大数据、云计算、边缘计算和区块链技术如何塑造数据处理的未来。通过对数据治理和
C++安全编程:防范ASCII文件操作中的3个主要安全陷阱

# 摘要
本文全面介绍了C++安全编程的核心概念、ASCII文件操作基础以及面临的主要安全陷阱,并提供了一系列实用的安全编程实践指导。文章首先概述C++安全编程的重要性,随后深入探讨ASCII文件与二进制文件的区别、C++文件I/O操作原理和标准库中的文件处理方法。接着,重点分析了C++安全编程中的缓冲区溢出、格式化字符串漏洞和字符编码问题,提出相应的防范
时间序列自回归移动平均模型(ARMA)综合攻略:与S命令的完美结合
# 摘要
时间序列分析是理解和预测数据序列变化的关键技术,在多个领域如金融、环境科学和行为经济学中具有广泛的应用。本文首先介绍了时间序列分析的基础知识,特别是自回归移动平均(ARMA)模型的定义、组件和理论架构。随后,详细探讨了ARMA模型参数的估计、选择标准、模型平稳性检验,以及S命令语言在实现ARMA模型中的应用和案例分析。进一步,本文探讨了季节性ARMA模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )