【httplib实战演习】:如何构建HTTP服务器,掌握网络编程核心
发布时间: 2024-10-09 17:58:24 阅读量: 152 订阅数: 70 

cpp-httplib:仅C ++标头的HTTPHTTPS服务器和客户端库

# 1. httplib概述及HTTP协议基础
在现代IT行业中,无论是开发、测试还是部署应用,HTTP协议都是不可或缺的基础。httplib,作为Python的标准库之一,提供了一系列工具来简化与HTTP相关的客户端编程任务。我们将从HTTP协议的基础讲起,逐步深入到httplib的使用和高级特性。
## 1.1 HTTP协议简介
超文本传输协议(HTTP)是互联网上应用最为广泛的一种网络协议,它规定了客户端与服务器之间进行通信的规则。HTTP协议是无状态的,这意味着服务器不会保存任何关于客户端请求的状态信息。请求和响应是HTTP通信的两个基本动作,它们通过网络传输层的TCP协议进行连接。
## 1.2 HTTP协议的特点
HTTP协议以明文方式传输数据,易于阅读和调试,但这也意味着它不安全。为了解决安全问题,HTTPS协议被引入,通过SSL/TLS对HTTP协议进行加密。
## 1.3 HTTP请求与响应模型
一个HTTP请求包括请求行、请求头、空行和可选的消息体。而响应则包括状态行、响应头、空行和响应体。状态码是响应的一部分,指示了请求是否成功。常见的状态码如200代表成功,404代表资源未找到,500代表服务器内部错误等。
在下一章中,我们将通过httplib模块,构建一个基本的HTTP服务器,并详细解析其工作原理。
# 2. 使用httplib创建基本的HTTP服务器
### 2.1 HTTP服务器的工作原理
#### 2.1.1 请求和响应模型
HTTP服务器通过一个基于请求和响应模型的机制工作。客户端(通常是Web浏览器)发送一个HTTP请求到服务器,请求某种资源或服务,例如请求一个HTML页面。服务器处理这个请求,并返回一个HTTP响应,响应中包含了客户端请求的数据或错误消息。
这个模型非常简单,但非常强大。因为HTTP请求可以包含很多信息,比如客户端的类型、所请求资源的描述、客户端支持的数据类型等。服务器根据这些信息决定如何处理请求,比如从数据库获取数据,或者从文件系统中读取一个文件。
#### 2.1.2 HTTP请求方法与状态码
HTTP定义了多种请求方法,如GET、POST、PUT、DELETE等,每种方法有其特定用途。GET用于获取资源,POST用于提交数据,PUT用于更新资源,DELETE用于删除资源等。服务器根据不同的请求方法来执行不同的操作。
HTTP响应状态码用于告诉客户端请求是否成功。状态码的范围从1xx到5xx,其中1xx表示信息,2xx表示成功,3xx表示重定向,4xx表示客户端错误,5xx表示服务器错误。例如,当请求的资源不存在时,服务器会返回404状态码。
### 2.2 构建简单的HTTP服务器
#### 2.2.1 Python中的httplib模块
虽然httplib主要用于创建HTTP客户端,它也可以帮助我们理解HTTP协议的基本原理。httplib模块提供了对底层HTTP协议的支持,可以通过它来实现一个简单的HTTP服务器。不过,要注意的是,httplib并不适用于生产环境下的服务器构建,因为它的功能相对有限。
#### 2.2.2 服务器端代码编写与运行
一个基本的HTTP服务器可以使用Python的内置库来实现。以下是一个简单的HTTP服务器示例代码,它监听8000端口,并对任何请求响应一个简单的“Hello, World!”消息。
```python
import http.server
import socketserver
PORT = 8000
class SimpleHTTPRequestHandler(http.server.SimpleHTTPRequestHandler):
pass
with socketserver.TCPServer(("", PORT), SimpleHTTPRequestHandler) as httpd:
print(f"Serving at port {PORT}")
httpd.serve_forever()
```
运行上述代码会启动一个简单的HTTP服务器。你可以通过访问`***`来查看服务器的响应。这个服务器只能处理静态文件请求,并且没有安全措施,不应用于生产环境。
### 2.3 简单服务器的功能扩展
#### 2.3.1 处理静态文件服务
静态文件服务是HTTP服务器中最简单的功能之一。服务器需要做到的是,将存储在服务器上的文件直接发送给客户端。通常,Web服务器对文件系统有一定的路径映射机制,以便正确地找到并返回请求的资源。
```python
# 在SimpleHTTPRequestHandler类中重写目录列表方法
def do_GET(self):
if self.path == "/":
self.path = "/index.html"
return http.server.SimpleHTTPRequestHandler.do_GET(self)
```
上面的代码段展示了如何在请求根目录时,将请求重定向到`index.html`文件。
#### 2.3.2 动态内容生成与模板渲染
静态文件服务不能满足所有需求,因为很多Web应用需要动态内容。这就需要服务器在运行时根据请求生成数据,并将其嵌入到模板中返回给客户端。
动态内容生成常常通过模板引擎来实现。模板引擎允许开发者定义一个模板文件,在模板中包含一些特殊标记或变量。服务器接收到请求时,解析模板,并用实际数据替换标记,然后返回填充好的HTML内容。
虽然httplib不适合用来实现动态内容生成,但是理解这个过程对于理解HTTP服务器如何工作是有帮助的。在生产环境中,通常会使用更高级的Web框架,如Flask或Django,来处理动态内容的生成和模板渲染。
本章节介绍了HTTP服务器的工作原理,并通过构建一个简单的Python服务器和扩展其基本功能,进一步探讨了如何处理静态文件和动态内容。通过这个过程,我们可以更深入地理解HTTP协议以及Web服务器的内部机制。
# 3. 深入理解网络编程与httplib
## 3.1 网络编程核心概念
### 3.1.1 网络层与传输层协议
网络编程是指通过计算机网络交换数据包的过程。在深入学习httplib之前,有必要了解网络通信中的两个核心层:网络层与传输层。
- 网络层主要关注的是将数据从源点传输到终点,它的主要协议是IP(Internet Protocol)。IP协议负责将数据包传送到目的地,但不保证包的顺序、完整性或者重复性,这是传输层要处理的问题。
- 传输层关注的是数据包的可靠性、顺序及流量控制,主要有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议,提供全双工通信服务;而UDP是无连接的,尽最大努力交付,不保证数据包的顺序和可靠性,但开销小,效率高。
### 3.1.2 套接字编程基础
网络编程是建立在网络协议栈之上的,而套接字(sockets)是网络应用层和传输层之间的一个抽象层。Python中的套接字编

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入解析了 Python 中的 httplib 库,涵盖了从基础到高级的各个方面。从库的内部机制到高效爬虫的打造,从安全连接实践到自定义 HTTP 请求,再到高效并发处理和异常处理技巧,专栏提供了全面的指南。此外,还探讨了 httplib 在 RESTful API、SSL/TLS 加密通信、Cookie 处理和微服务架构中的应用。通过深入剖析和实战演练,本专栏旨在帮助读者掌握网络编程的精髓,提升 HTTP 请求响应效率,并打造高效可靠的网络应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南

# 摘要
随着数字化时代的到来,信息安全成为企业管理中不可或缺的一部分。本文全面探讨了信息安全的理论与实践,从ISO/IEC 27000-2018标准的概述入手,详细阐述了信息安全风险评估的基础理论和流程方法,信息安全策略规划的理论基础及生命周期管理,并提供了信息安全风险管理的实战指南。
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解

# 摘要
本文全面介绍了戴尔笔记本BIOS的基本知识、界面使用、多语言界面设置与切换、文档支持以及故障排除。通过对BIOS启动模式和进入方法的探讨,揭示了BIOS界面结构和常用功能,为用户提供了深入理解和操作的指导。文章详细阐述了如何启用并设置多语言界面,以及在实践操作中可能遇到的问题及其解决方法。此外,本文深入分析了BIOS操作文档的语
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点

# 摘要
本文深入探讨了VCS高可用性的基础、核心原理、配置与实施、案例分析以及高级话题。首先介绍了高可用性的概念及其对企业的重要性,并详细解析了VCS架构的关键组件和数据同步机制。接下来,文章提供了VC
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方

# 摘要
随着信息技术的发展,日志数据的采集与分析变得日益重要。本文旨在详细介绍Fluentd作为一种强大的日志驱动开发工具,阐述其核心概念、架构及其在日志聚合和系统监控中的应用。文中首先介绍了Fluentd的基本组件、配置语法及其在日志聚合中的实践应用,随后深入探讨了F
Cygwin系统监控指南:性能监控与资源管理的7大要点

# 摘要
本文详尽探讨了使用Cygwin环境下的系统监控和资源管理。首先介绍了Cygwin的基本概念及其在系统监控中的应用基础,然后重点讨论了性能监控的关键要点,包括系统资源的实时监控、数据分析方法以及长期监控策略。第三章着重于资源管理技巧,如进程优化、系统服务管理以及系统安全和访问控制。接着,本文转向C
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略

# 摘要
本文旨在深入解析Arcmap空间参考系统的基础知识,详细探讨SHP文件的坐标系统理解与坐标转换,以及地理纠正的原理和方法。文章首先介绍了空间参考系统和SHP文件坐标系统的基础知识,然后深入讨论了坐标转换的理论和实践操作。接着,本文分析了地理纠正的基本概念、重要性、影响因素以及在Arcmap中的应用。最后,文章探讨了SHP文
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
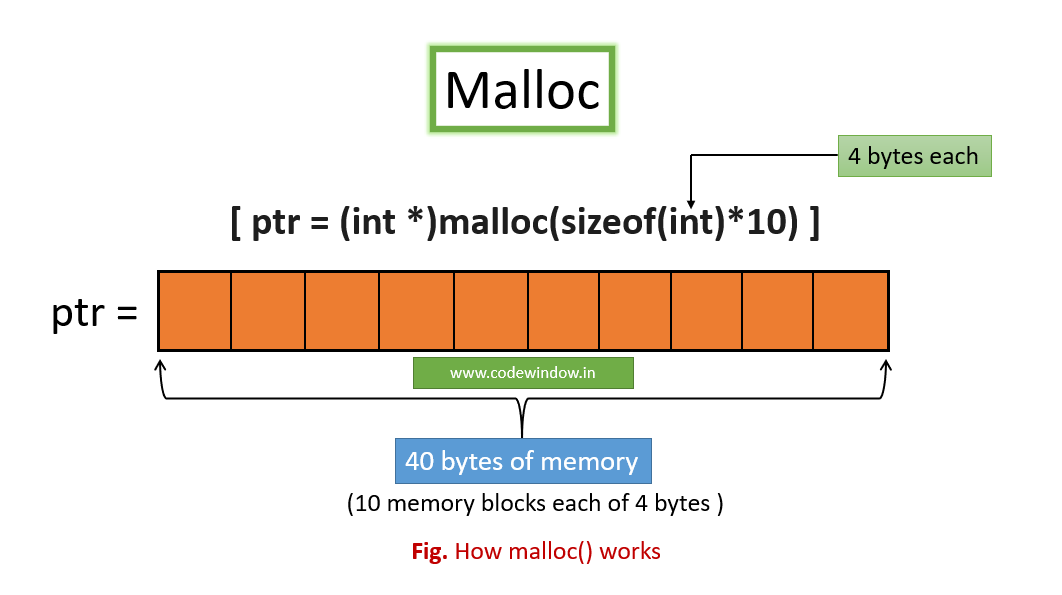
# 摘要
本文深入探讨了内存分配的基础知识,特别是malloc函数的使用和相关问题。文章首先分析了内存泄漏的成因及其对程序性能的影响,接着探讨内存碎片的产生及其后果。文章还列举了常见的内存错误类型,并解释了malloc钩子技术的原理和应用,以及如何通过钩子技术实现内存监控、追踪和异常检测。通过实践应用章节,指导读者如何配置和使用malloc钩子来调试内存问题,并优化内存管理策略。最后,通过真实世界案例的分析
【T-Box能源管理】:智能化节电解决方案详解

# 摘要
随着能源消耗问题日益严峻,T-Box能源管理系统作为一种智能化的能源管理解决方案应运而生。本文首先概述了T-Box能源管理的基本概念,并分析了智能化节电技术的理论基础,包括发展历程、科学原理和应用分类。接着详细探讨了T-Box系统的架构、核心功能、实施路径以及安全性和兼容性考量。在实践应用章节,本文分析了T-Bo
【精准测试】:确保分层数据流图准确性的完整测试方法
# 摘要
分层数据流图(DFD)作为软件工程中描述系统功能和数据流动的重要工具,其测试方法论的完善是确保系统稳定性的关键。本文系统性地介绍了分层DFD的基础知识、测试策略与实践、自动化与优化方法,以及实际案例分析。文章详细阐述了测试的理论基础,包括定义、目的、分类和方法,并深入探讨了静态与动态测试方法以及测试用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )