【Python网络编程秘籍】:从httplib库基础到高效爬虫打造(掌握网络编程的10大技巧)
发布时间: 2024-10-09 17:37:05 阅读量: 246 订阅数: 68 
# 1. Python网络编程概览
## 网络编程简介
网络编程在现代软件开发中扮演着至关重要的角色,它使得应用程序能够通过网络进行通信。Python作为一种高级编程语言,提供了强大的网络编程能力,这得益于其丰富的标准库,尤其是对于HTTP协议的支持。
## Python网络编程的优势
Python的网络编程库简单易用,且具有高度的抽象。举个例子,httplib库让开发者能够轻松地发起HTTP请求,并处理服务器的响应。Python还支持其他多种网络协议和复杂的应用场景,包括套接字编程、异步IO、WebSocket、以及最新的网络协议HTTP/2。
## 发展趋势与应用前景
随着云计算、物联网、大数据等技术的兴起,Python在网络编程方面的应用不断拓宽。它的简洁语法和强大库支持,不仅使得快速开发成为可能,而且提高了代码的可维护性和可读性。无论是构建Web服务、开发爬虫、还是实现机器间通信,Python都能够胜任。
在下一章节中,我们将进一步探讨Python中httplib库的入门与应用,揭示其在网络编程中的强大功能和使用技巧。
# 2. httplib库入门与应用
### 2.1 httplib库基础介绍
#### 2.1.1 httplib库的作用与特点
httplib库是Python标准库的一部分,专门用于处理HTTP协议的各种细节。它是一个低级别的库,因此提供了强大的功能来发送各种HTTP请求,并处理返回的HTTP响应。httplib特别适合处理需要直接与HTTP协议交互的应用程序,例如网络爬虫、自动化测试以及需要直接向服务器发送请求的各种脚本。
特点方面,httplib库的主要特点包括:
- 支持HTTP/1.1协议,可以处理HTTP代理和持久连接(keep-alive)。
- 提供了易于使用的接口来执行请求,并读取响应。
- 支持各种HTTP请求方法,例如GET、POST、PUT、DELETE等。
- 可以处理重定向,并通过自定义异常来处理错误。
- 可以通过SSL进行安全的HTTP连接。
#### 2.1.2 创建和配置HTTP连接
创建一个基本的HTTP连接通常涉及创建一个`http.client.HTTPConnection`对象,并指定服务器的地址。对于安全的HTTPS连接,则使用`http.client.HTTPSConnection`。下面是一个创建HTTP连接的基本示例:
```python
import http.client
# 创建一个HTTP连接
http_conn = http.client.HTTPConnection('***')
# 创建一个HTTPS连接
https_conn = http.client.HTTPSConnection('***')
# 指定端口,如果默认端口不是80或443的话
https_conn = http.client.HTTPSConnection('***', port=8080)
```
在创建连接之后,我们就可以执行请求了。在执行请求之前,可以对连接进行各种配置,例如设置超时时间,以防止程序无限期地等待服务器响应。以下是设置超时的示例:
```python
http_conn.settimeout(5) # 设置超时时间为5秒
```
配置完毕后,即可进行各种HTTP请求的执行,这将在2.2节中详细讨论。
### 2.2 发送请求与接收响应
#### 2.2.1 常见HTTP请求方法
httplib库支持多种HTTP请求方法,其中最常用的是GET和POST。GET请求一般用于请求数据,而POST请求则用于提交数据到服务器。此外,httplib也支持PUT、DELETE等其他HTTP方法。下面是一个GET请求的示例:
```python
import http.client
http_conn = http.client.HTTPConnection('***')
http_conn.request('GET', '/path/to/resource')
response = http_conn.getresponse()
# 检查状态码
print(response.status)
# 读取响应内容
data = response.read()
print(data)
```
在上述代码中,首先创建了一个HTTP连接,然后使用`request()`方法发送了一个GET请求。之后,通过`getresponse()`方法获取了服务器的响应,并打印了状态码和响应内容。
POST请求则稍有不同,通常需要在请求中包含一些数据,这些数据被添加到HTTP请求的主体中,如下所示:
```python
import http.client
http_conn = http.client.HTTPConnection('***')
post_data = 'key1=value1&key2=value2'
http_conn.request('POST', '/path/to/resource', post_data.encode('utf-8'))
response = http_conn.getresponse()
# 检查状态码
print(response.status)
# 读取响应内容
data = response.read()
print(data)
```
在这个POST请求的示例中,`post_data`是一个包含键值对的字符串,它被编码为字节串,并作为请求体发送。
#### 2.2.2 处理HTTP响应
处理HTTP响应时,我们主要关心的内容包括响应状态码和响应体。状态码可以告诉我们请求是否成功,以及如果失败,失败的原因是什么。响应体则包含了服务器返回的数据。httplib库通过`getresponse()`方法返回的响应对象来处理这些信息。
```python
response = http_conn.getresponse()
print(response.status) # 打印状态码
print(response.reason) # 打印状态码的文本描述
# 检查响应类型,例如:'text/html; charset=utf-8'
print(response.getheader('Content-Type'))
# 读取响应主体
data = response.read()
print(data.decode('utf-8')) # 假设响应内容是utf-8编码的文本
```
在上述代码中,`getheader()`方法用于获取HTTP头中的信息,这对于处理内容类型、内容长度以及自定义的头信息非常有用。
### 2.3 HTTP连接管理
#### 2.3.1 连接池的使用
在许多网络应用中,会频繁地向同一个服务器发送请求。为了避免每次都建立新的连接,httplib库提供了一种机制来重用连接,这被称为连接池。使用连接池可以显著提高性能,特别是在高并发的网络应用中。
在httplib库中,连接池的使用是透明的,意味着你不需要显式地管理连接池。每次调用`request()`方法时,如果已经存在一个匹配的连接(即相同的服务器地址和端口),库会尝试重用这个连接。如果没有匹配的连接,它会创建一个新的连接。
```python
import http.client
# 创建连接
conn = http.client.HTTPConnection('***')
# 使用连接发送多个请求
for _ in range(5):
conn.request('GET', '/path/to/resource')
response = conn.getresponse()
# 处理响应...
conn.close() # 注意:在发送下一个请求前应关闭响应,以便库可以回收连接
# 确保连接被关闭
conn.close()
```
上述代码展示了如何使用同一个连接来发送多个请求。需要注意的是,为避免潜在的问题,如缓冲区溢出,通常在发送下一个请求之前关闭前一个响应。
#### 2.3.2 保持连接与重试机制
httplib库中的连接默认是持久的,意味着在请求结束后连接不会立即关闭,而是保持打开状态,以便于后续的请求复用。这可以减少TCP握手的开销,并降低延迟。要关闭持久连接,可以在发送请求时通过设置`Connection: close`头来指示服务器关闭连接。
```python
http_conn = http.client.HTTPConnection('***')
http_conn.request('GET', '/path/to/resource', headers={'Connection': 'close'})
```
此外,httplib库本身不直接支持自动重试机制。不过,我们可以通过编写额外的逻辑来实现重试,例如:
```python
import http.client
import time
def request_with_retry(url, method='GET', retries=3):
for attempt in range(retries):
try:
http_conn = http.client.HTTPConnection(url)
http_conn.request(method, '/')
response = http_conn.getresponse()
# 成功的处理逻辑
print(response.status, response.read())
break
except Exception as e:
print(f'Retry {attempt+1}/{retries}:', e)
time.sleep(1) # 等待1秒钟后重试
else:
print('Maximum retries exceeded.')
finally:
http_conn.close()
request_with_retry('***')
```
在该示例中,如果请求失败,则会在循环中进行重试,并在失败次数达到最大重试次数后停止。这提供了一种机制,可以在遇到网络问题或其他临时错误时继续尝试,从而增强程序的鲁棒性。
# 3. 网络编程的10大技巧
在本章节中,我们将深入探讨网络编程中的实用技巧和高级概念。理解这些技巧对于创建高效、健壮的网络应用至关重要。
## 3.1 网络请求优化
网络请求的优化可以显著提升应用的性能和用户体验。在此部分,我们将介绍如何通过并发请求和缓存机制来优化网络编程。
### 3.1.1 并发请求的实现与优化
并发网络请求允许同时发送多个请求到服务器,这对于提高应用响应速度和减少等待时间非常关键。
#### 实现并发请求
Python中的`concurrent.futures`模块提供了一个简单的方法来实现并发执行。使用`ThreadPoolExecutor`或`ProcessPoolExecutor`可以创建一个线程池或进程池来并行化执行多个任务。
```python
import requests
from concurrent.futures import ThreadPoolExecutor
def fetch_url(url):
return requests.get(url).text
urls = ['***', '***', '***']
with ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(fetch_url, urls)
for result in results:
print(result)
```
在这个例子中,我们定义了一个`fetch_url`函数来抓取给定URL的内容。然后我们使用`ThreadPoolExecutor`的`map`方法来并行执行这个函数。
#### 并发请求优化
并发请求虽然能够加速执行,但也可能给服务器带来不必要的压力。为了优化并发请求,可以考虑以下几个方面:
- **限制并发数量**:不建议无限制地增加线程数量。根据服务器的处理能力合理设置线程池大小。
- **动态调整并发策略**:如果服务器响应变慢或发生错误,动态减少并发量或增加超时时间。
- **使用连接池**:重用已建立的连接可以减少连接建立和销毁的开销。
### 3.1.2 使用缓存减少网络负载
缓存是一种减少网络负载的有效方法,它通过存储响应数据来避免不必要的重复请求。
#### 缓存策略
Python的`requests`库支持简单的缓存策略,可以通过`requests-cache`包轻松实现。
```python
import requests_cache
requests_cache.install_cache('my_cache', expire_after=3600) # 缓存1小时
response = requests.get('***')
print(response.from_cache) # 检查响应是否来自缓存
```
通过使用缓存,我们可以大大减少对同一资源的重复请求,特别是在网络速度较慢或请求成本较高的情况下。
## 3.2 数据解析与处理
数据解析是网络编程中一个重要的环节。在网络请求中,我们通常会接收到JSON或XML格式的数据,因此掌握这些数据的解析和转换技巧非常关键。
### 3.2.1 解析JSON和XML数据
Python的标准库中提供了`json`模块来处理JSON数据,而对于XML,我们可以使用第三方库如`xml.etree.ElementTree`或`lxml`。
```python
import json
# JSON数据解析示例
data = '{"name": "John", "age": 30, "city": "New York"}'
parsed_data = json.loads(data)
print(parsed_data['name']) # 输出: John
```
在解析XML时,`ElementTree`提供了方便的接口来访问和查询XML文档中的数据。
```python
from xml.etree import ElementTree as ET
# XML数据解析示例
xml_data = '<user><name>John</name><age>30</age><city>New York</city></user>'
root = ET.fromstring(xml_data)
print(root.find('name').text) # 输出: John
```
### 3.2.2 数据转换技巧
在处理数据时,经常需要对数据进行转换以满足不同的需求。Python中的字典和对象可以很容易地相互转换。
```python
# 将字典转换为JSON字符串
json_string = json.dumps(parsed_data)
print(json_string)
# 将JSON字符串转换回字典
restored_data = json.loads(json_string)
```
## 3.3 异常处理与调试
在编写网络应用时,错误处理和日志记录至关重要。良好的异常处理机制可以保证程序的健壮性,而日志记录可以帮助开发者进行问题的调试。
### 3.3.1 网络异常的捕获与处理
网络请求可能会因为各种原因失败,如连接超时、HTTP错误等。合理地捕获和处理这些异常对于提供良好的用户体验非常必要。
```python
try:
response = requests.get('***', timeout=10)
except requests.exceptions.Timeout:
print('请求超时')
except requests.exceptions.HTTPError as errh:
print('HTTP错误:', errh)
except requests.exceptions.ConnectionError as errc:
print('连接错误:', errc)
except requests.exceptions.RequestException as err:
print('发生错误:', err)
```
在这段代码中,我们使用`try-except`块来捕获和处理不同的异常。这样可以在发生错误时给予用户合理的反馈。
### 3.3.2 日志记录与分析
日志记录是任何生产级应用不可或缺的一部分。Python的`logging`模块提供了灵活的日志记录系统。
```python
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(levelname)s - %(message)s')
logging.debug('这是一个调试信息')
***('这是一个信息性的消息')
logging.warning('这是一个警告信息')
logging.error('这是一个错误信息')
logging.critical('这是一个严重的错误信息')
```
我们可以通过配置`logging`模块的级别、格式和输出来实现详细的日志记录,这对于问题的快速定位和解决非常有帮助。
在本章节的介绍中,我们探索了网络编程中的多个实用技巧。从优化网络请求到数据解析与处理,再到异常处理与日志记录,每一个细节都对提升应用性能、稳定性和可维护性有着不可忽视的作用。掌握这些技巧将有助于开发者编写出更加高效和健壮的网络应用。
# 4. 打造高效爬虫
在构建高效爬虫的过程中,遵循设计原则、数据提取与清洗技巧、以及反反爬策略是不可或缺的要素。下面将对这些要素进行深入探讨。
## 爬虫的设计原则
在设计一个高效的爬虫时,首先需要明确设计原则,确保爬虫能够遵循网络礼仪,高效工作。
### 遵守Robots协议
Robots协议是网站定义了哪些内容可以被爬虫访问的协议。编写爬虫之前,要确保爬虫遵守目标网站的Robots.txt文件规定,避免违反网站规则和法律法规。
```python
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url("***")
rp.read()
# 检查是否有权限请求某路径
user_agent = "MyCrawler"
path = "/some/page.html"
print(rp.can_fetch(user_agent, path)) # 输出 True 或 False
```
### 构建请求队列与调度器
一个高效爬虫需要能够管理和调度大量的网络请求。请求队列和调度器是管理这些请求的重要组件。它们可以控制爬虫访问网站的速率,防止对网站造成过大压力。
```python
import queue
class RequestQueue:
def __init__(self):
self.queue = queue.Queue()
def add_request(self, request):
self.queue.put(request)
def get_request(self):
return self.queue.get()
# 示例:添加和获取请求
request_queue = RequestQueue()
request_queue.add_request("/page1")
request_queue.add_request("/page2")
first_request = request_queue.get_request()
second_request = request_queue.get_request()
```
## 数据提取与清洗
数据提取和清洗是爬虫获取信息的关键步骤。良好的数据提取与清洗技巧可以显著提高爬虫数据处理的效率。
### 使用XPath和CSS选择器提取数据
XPath和CSS选择器是定位HTML文档中元素的常用工具,它们使得数据提取变得更加灵活和准确。
```python
from lxml import etree
import requests
# 发送HTTP请求获取网页
response = requests.get("***")
tree = etree.HTML(response.text)
# 使用XPath提取文章标题
titles = tree.xpath('//h1[@class="article-title"]/text()')
# 使用CSS选择器提取文章内容
content = tree.cssselect('.article-content p')
```
### 数据预处理和清洗技巧
提取数据后,通常需要进行一系列的预处理和清洗。这可能包括去除无关字符、格式化数据、验证数据等步骤。
```python
import pandas as pd
# 将提取的数据转换为Pandas DataFrame
df = pd.DataFrame(content, columns=['title', 'content'])
# 数据清洗,例如去除空白字符
df['title'] = df['title'].str.strip()
# 更多的数据清洗操作...
```
## 爬虫的反反爬策略
反反爬策略对于应对目标网站的反爬虫措施至关重要。下面介绍几种常见的反反爬策略。
### 用户代理(User-Agent)与IP代理的使用
网站常常通过检测User-Agent来识别爬虫,因此更改User-Agent或使用多个不同的代理IP可以有效绕过这一检测。
```python
import requests
proxies = {
'http': '***',
'https': '***',
}
# 使用代理发送请求
response = requests.get("***", proxies=proxies)
```
### 登录认证与Cookies管理
对于需要登录认证的网站,爬虫需要能够管理Cookies,以保持登录状态和追踪用户会话。
```python
from requests.cookies import RequestsCookieJar
cookies = RequestsCookieJar()
cookies.set('session_id', '123456', domain='.***')
# 发送带有Cookies的请求
response = requests.get("***", cookies=cookies)
```
## 总结
高效爬虫的设计与实现是数据采集与分析工作的基础。它不仅涉及技术层面,还包括法律、道德等多方面的考量。在本章节中,我们详细探讨了爬虫的设计原则、数据提取与清洗技巧以及反反爬策略。这些内容将为构建一个稳定、高效的爬虫系统奠定坚实的基础。接下来的章节将更进一步,通过实战项目展示如何运用这些知识构建RESTful API客户端和开发分布式爬虫。
# 5. Python网络编程实战
## 5.1 实战项目:构建RESTful API客户端
RESTful API客户端的设计和实现是网络编程中常见的任务,它允许我们与远程服务器进行通信,获取或提交数据。构建这样的客户端可以帮助我们更好地理解HTTP协议的工作原理以及如何在Python中使用httplib库等工具。
### 5.1.1 设计API请求与响应处理流程
在设计RESTful API客户端时,首先要明确API的请求方法、URL结构和请求体数据格式。然后,根据API文档构建请求,并处理响应数据。常见的请求方法有GET(获取数据)、POST(提交数据)、PUT(更新数据)、DELETE(删除数据)等。
一个简单的流程包括:
1. 解析API端点。
2. 根据API要求构建请求头(Headers)和数据负载(Payload)。
3. 发送HTTP请求,并获取响应。
4. 解析响应内容。
5. 处理异常和错误情况。
下面是一个使用httplib库向RESTful API发送GET请求并解析响应的基本代码示例:
```python
import httplib
import json
# 构建请求的URL和HTTP头部信息
url = '***'
headers = {'Accept': 'application/json'}
# 创建HTTP连接并发送GET请求
conn = httplib.HTTPSConnection('***')
conn.request('GET', url, headers=headers)
# 获取响应
response = conn.getresponse()
data = response.read()
# 解析响应内容,假设响应的内容是JSON格式
parsed_data = json.loads(data.decode('utf-8'))
# 打印解析后的数据
print(parsed_data)
# 关闭连接
conn.close()
```
### 5.1.2 实现API调用的封装与接口测试
实现API调用的封装可以提高代码的可重用性,并且使得接口测试更加方便。我们可以创建一个专门的类来处理API的调用逻辑,如下:
```python
class APIClient:
def __init__(self, base_url):
self.base_url = base_url
def get(self, endpoint, params=None):
url = self.base_url + endpoint
headers = {'Accept': 'application/json'}
conn = httplib.HTTPSConnection('***')
conn.request('GET', url, params=params, headers=headers)
response = conn.getresponse()
data = response.read()
parsed_data = json.loads(data.decode('utf-8'))
conn.close()
return parsed_data
# 创建API客户端实例
client = APIClient('***')
# 使用客户端调用API
response_data = client.get('data', {'param1': 'value1', 'param2': 'value2'})
# 打印响应数据
print(response_data)
```
通过封装,我们可以将API请求的细节隐藏在`APIClient`类中,而客户端调用方只需关注需要调用的API端点和传递的参数。这不仅让代码更加整洁,而且让接口测试更加简单,因为我们可以轻松地在测试代码中使用`APIClient`类的实例。
## 5.2 实战项目:开发分布式爬虫
随着互联网的快速发展,数据的获取变得越来越重要。分布式爬虫是一种能够在多个节点上并发执行的爬虫程序,它可以高效地爬取大规模数据。在本节中,我们将探讨如何设计分布式爬虫架构以及实现任务分发与数据聚合。
### 5.2.1 设计分布式爬虫架构
设计分布式爬虫需要考虑以下几个方面:
1. **任务调度**:如何高效地分配和管理任务,确保不会重复爬取相同的内容。
2. **请求管理**:如何控制并发请求的数量,避免对目标服务器造成过大压力。
3. **数据存储**:数据应存储在何处,以及如何保证数据的一致性和完整性。
4. **错误处理**:如何处理网络错误和数据解析异常。
分布式爬虫架构通常包括以下几个组件:
- **爬虫节点**:负责实际的网页下载和数据提取工作。
- **任务调度器**:负责分配任务给不同的爬虫节点。
- **中心数据库**:存储任务信息、已爬取URL集合、提取的数据等。
- **缓存系统**:使用如Redis这样的内存数据库缓存任务,提高响应速度。
### 5.2.2 实现任务分发与数据聚合
在分布式爬虫的实现中,任务分发和数据聚合是核心。任务分发涉及将爬取任务均匀地分配到多个爬虫节点上,而数据聚合则负责将各个节点爬取的数据汇总。
以下是一个简化的任务分发和数据聚合的伪代码实现:
```python
class Scheduler:
def __init__(self):
self.task_queue = [] # 存储待爬取的URL
def add_task(self, url):
self.task_queue.append(url)
def get_task(self):
if self.task_queue:
return self.task_queue.pop(0)
else:
return None
class Worker:
def __init__(self, scheduler):
self.scheduler = scheduler
def work(self):
task = self.scheduler.get_task()
if task:
# 执行爬取任务
# 提取数据
# 数据聚合
pass
# 实例化调度器和工作器
scheduler = Scheduler()
worker = Worker(scheduler)
# 添加初始任务
scheduler.add_task('***')
scheduler.add_task('***')
# 启动工作器
while True:
worker.work()
```
在实际的分布式爬虫系统中,任务调度和数据聚合会更加复杂。可能会使用消息队列(如RabbitMQ)来处理任务分发,并使用分布式数据库(如Cassandra)来聚合数据。此外,还需要考虑到负载均衡、容错处理、动态扩展节点等高级特性。
通过本章节的学习,我们了解了如何构建RESTful API客户端,并掌握了分布式爬虫的设计与实现。这些知识将帮助我们在网络编程的道路上更进一步。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入解析了 Python 中的 httplib 库,涵盖了从基础到高级的各个方面。从库的内部机制到高效爬虫的打造,从安全连接实践到自定义 HTTP 请求,再到高效并发处理和异常处理技巧,专栏提供了全面的指南。此外,还探讨了 httplib 在 RESTful API、SSL/TLS 加密通信、Cookie 处理和微服务架构中的应用。通过深入剖析和实战演练,本专栏旨在帮助读者掌握网络编程的精髓,提升 HTTP 请求响应效率,并打造高效可靠的网络应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
双闭环直流电机调速:电机类型选择的不传之秘

# 摘要
直流电机在工业领域内广泛应用,其工作原理和分类是电机控制系统设计的基础。本文首先介绍了直流电机的基本工作原理及其分类,然后详细探讨了双闭环直流电机调速系统的结构和关键性能指标。文章深入分析了不同类型直流电机的特性,并提供了电机类型选择的理论计算方法。实践应用方面,本文讨论了工业场景下的电机选型和调速系统设计的综合考量。最后,文章通过案例研究展示了双闭环调速系统的实现、优化以及在工业自动化中
组播路由协议深度探讨:网络中的部署与案例分析

# 摘要
本文全面探讨了组播路由协议的各个方面,包括其理论基础、实践部署、案例分析以及未来发展趋势。首先概述了组播路由协议的重要性及其在组播通信模型中的应用。接着,深入分析了不同类型的组播路由协议,并讨论了组播路由的基本原理和数据包转发机制。在实践部署章节中,本文详细介绍了环境搭建、配置步骤、监控管理以及安全性与性能优化的方法。案例分析部分通过行业应用案例解析和部署挑战的探讨,展现了组播路由在
云原生合规性黄金法则:行业标准与法规的满足秘籍
# 摘要
本文系统地探讨了云原生合规性的核心概念,分析了行业标准与法规对企业和组织合规性的重要性。重点介绍了ISO/IEC 27001、SOC 2、GDPR等主要云服务合规标准,并讨论了合规性政策制定、风险评估、员工培训等实施策略。文章进一步阐述了技术实现层面的安全架构设计、监控日志管理、应急响应等关键实践,以及合规性实施的成功案例分析。最后,文章展望了云原生合规性的未来趋势,包括新兴法规适应及技术创新在合规性中的潜在应用。
深入解析CMOS传感器:如何最大化1_4英寸的30万像素潜力
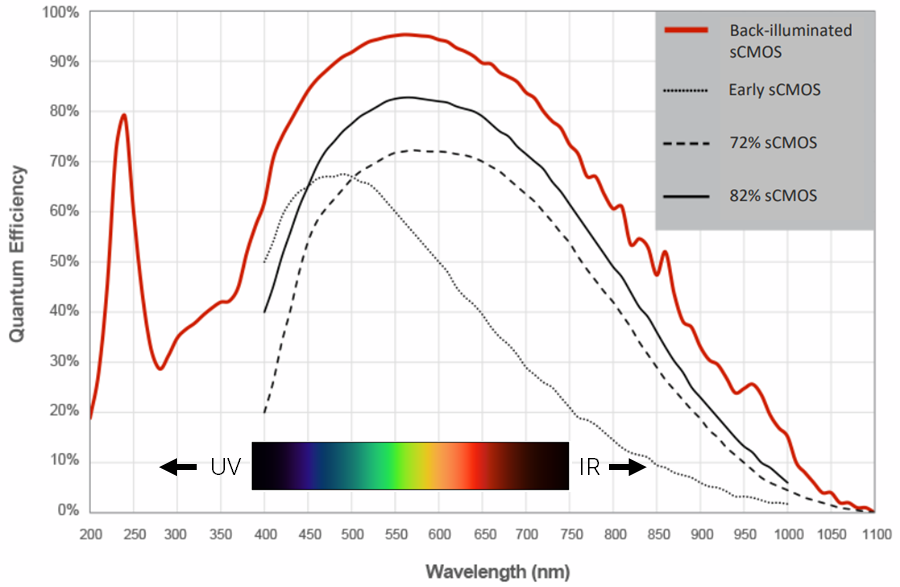
# 摘要
本文全面探讨了CMOS传感器的基础知识、技术参数、图像质量影响因素以及在不同场景下的应用,并分析了30万像素CMOS传感器的潜力挖掘与优化策略。通过对传感器尺寸、读出噪声、色彩还原等关键技术参数的解析,结合低光环境、高速成像等特定应用领域的分析,本文深入讨论了如何通过技术手段提升图像质量。此外,本文还展望了CMOS传感器技术的发展趋势,包括新型像素设计、智能化融合以及绿色节能技
【Python日期处理:进阶挑战】:自定义函数,精确计算年日
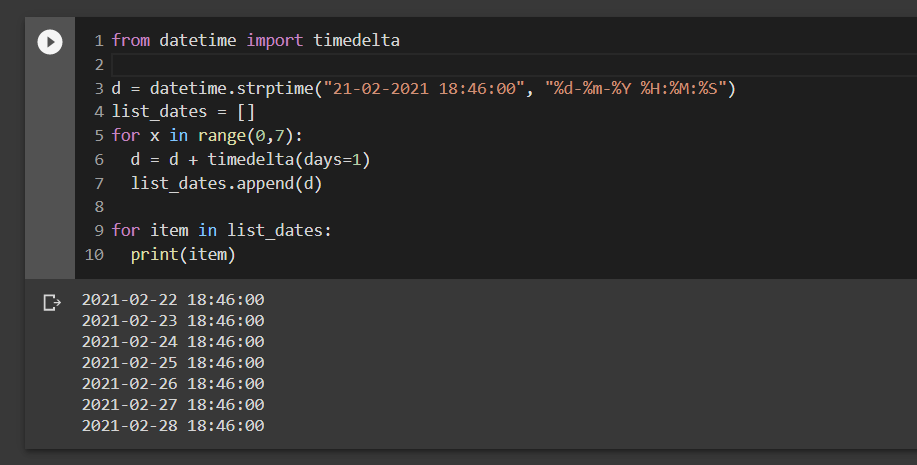
# 摘要
Python是一种广泛使用的编程语言,尤其在日期和时间处理方面提供了强大的库支持。本文首先概述了Python在日期处理方面的基本概念,随后深入讲解了datetime模块的使用,包括日期时间对象的创建和操作,时间的格式化与解析,以及时区的处理。文章第三部分探讨了编写自定义日期处理函数时面临的挑战,并介绍了相关的设计思路和算法选择。第四章着重于提高日期处理精确度的策略,包括理解
欧陆590直流调速器长寿秘诀:维护保养与延长设备寿命的黄金法则

# 摘要
本文首先概述了欧陆590直流调速器的基本情况,然后深入分析了其工作原理、结构与功能以及维护要点。在直流调速器的使用与维护策略方面,文中详细探讨了如何通过正确操作、预防性维护以及环境与电气因素的考量来延长设备的使用寿命。故障诊断与解决技巧章节提供了一系列故障分析、排除步骤和修复方法。最后,文章通过案例研究与行业应用,展示了欧陆590在不同领域的应用情况,分析了设备
商品上架自动化革新:淘宝天猫秒级库存同步技术内幕

# 摘要
随着电子商务的迅速发展,商品上架自动化成为提高效率和响应速度的关键技术革新。本文首先概述了商品上架自动化的基本概念与重要性,随后深入分析了秒级库存同步技术的原理和实践。详细阐述了实现该技术所需的数据抓取、数据同步流程自动化以及实时监控与报警系统的技术细节。通过淘宝天猫
GSM网络创新引擎:TDMA超帧演进的10年回顾与前瞻
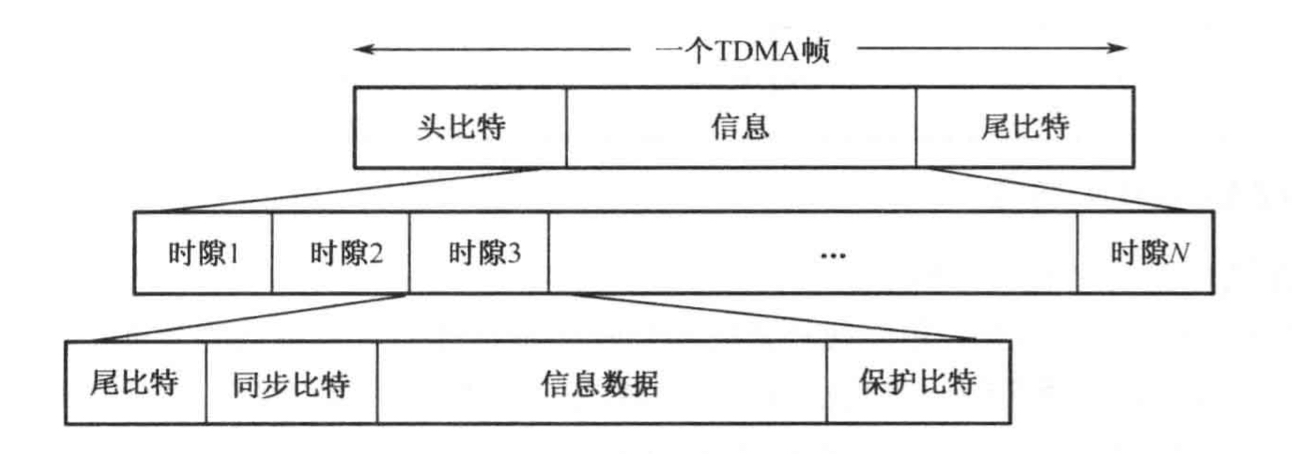
# 摘要
本文概述了GSM网络和TDMA技术的发展历程及其超帧结构的演进。文章详细介绍了TDMA超帧的起源、主要变化及其对网络性能的影响,探讨了在技术创新与实践中的无线接口技术、网络架构优化以及无线资源管理的改进。同时,本文也针对网络安全问题、新兴技术融合以及网络覆盖与服务升级方面的挑战提出了应对策略。最后,文章展望了TDM
SX-DSV03244_R5_0C通信参数故障排查:从新手到高手
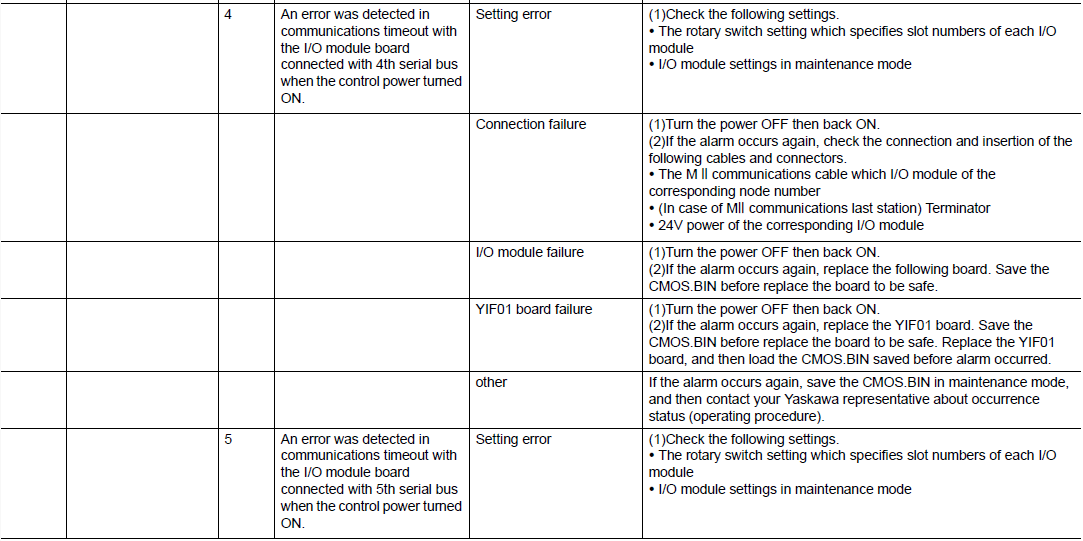
# 摘要
本文旨在深入探讨SX-DSV03244_R5_0C型号通信设备的参数故障排查技术。第一章提供该通信参数的概述,第二章分析通信参数功能的重要性及故障诊断的基础理论。第三章通过实践技巧,介绍了使用测试设备和仿真软件进行故障排查的方法。第四章进一步讨论通信参数设置的影响、高级故障诊断技术和维护策略。第五章探讨故障排查的自动化与智能化路径,展示自动化测试工具和智能故障诊断系统的应用。
Unicode编码国际化与本地化:策略与执行细节

# 摘要
本文全面探讨了Unicode编码的基础知识、国际化策略的理论以及本地化的实际技巧,并进一步分析了Unicode编码在软件中的应用和面对的挑战。首先介绍了字符编码的历史发展和Unicode标准,强调了国际化的需求以及设计原则。随后,本文阐述了本地化过程中的关键实践,包括文本翻译、资源管理以及测试和验证。接着,文章深入探讨了Unicode编码在编程语言实现、用户界面设计以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )