Python实战:利用爬虫技术获取网页数据
发布时间: 2024-04-08 20:40:28 阅读量: 52 订阅数: 48 
# 1. 理解爬虫技术的基本概念
- 1.1 什么是爬虫技术
- 1.2 爬虫技术的应用领域
- 1.3 爬虫技术的工作原理
# 2. 准备工作与环境搭建
- 2.1 安装Python和必要的库
- 2.2 选择适合的开发环境
- 2.3 设置代理服务器(如果需要)
# 3. 编写简单的爬虫程序
爬虫程序是利用编程技术自动获取网页数据的程序。在这一章节中,我们将介绍如何编写一个简单的爬虫程序来获取网页数据。
#### 3.1 使用Requests库发送HTTP请求
在Python中,我们通常使用Requests库来发送HTTP请求。以下是一个简单的示例代码,用于向目标网站发送GET请求并获取页面内容:
```python
import requests
url = 'http://example.com'
response = requests.get(url)
if response.status_code == 200:
print(response.text)
else:
print('Failed to retrieve webpage')
```
**代码说明:**
- 导入Requests库
- 指定要访问的URL
- 使用`requests.get()`方法发送GET请求并获取响应
- 判断响应状态码,若为200,则打印页面内容,否则提示请求失败
#### 3.2 解析HTML页面
解析HTML页面是爬虫程序中的重要步骤,通常我们会使用BeautifulSoup库进行解析。以下是一个简单的示例代码,用于解析网页内容:
```python
from bs4 import BeautifulSoup
html_content = '<html><head><title>Example</title></head><body><h1>Hello, World!</h1></body></html>'
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.string
print('Title:', title)
h1_text = soup.find('h1').get_text()
print('H1 Text:', h1_text)
```
**代码说明:**
- 导入BeautifulSoup库
- 定义待解析的HTML页面内容
- 使用`BeautifulSoup`构造函数解析HTML内容
- 提取页面标题和H1标签内的文本内容并打印
#### 3.3 提取目标数据
在爬取页面后,我们通常需要提取其中的目标数据。这可能涉及到对页面进行进一步解析和提取。以下是一个简单的示例代码,用于提取页面中的链接:
```python
from bs4 import BeautifulSoup
import requests
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')
for link in links:
print(link.get('href'))
```
**代码说明:**
- 导入BeautifulSoup和Requests库
- 发送GET请求并解析页面
- 使用`find_all()`方法提取所有链接标签
- 遍历链接并打印链接地址
通过以上示例,我们可以初步了解如何编写一个简单的爬虫程序来获取网页数据,如发送HTTP请求、解析HTML页面以及提取目标数据。
# 4. 提升爬虫程序的效率
爬虫程序的效率是影响数据获取速度和稳定性的重要因素,下面将介绍如何提升爬虫程序的效率。
#### 4.1 设置请求头信息
在发送HTTP请求时,设置适当的请求头信息是提高爬虫程序成功率的重要步骤。有些网站会检测请求头信息,如果请求头信息不符合标准,就有可能将其识别为爬虫并阻止访问。因此,通过设置合理的请求头信息,可以模拟浏览器进行访问,避免被识别为爬虫。
```python
import requests
url = 'https://www.example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
```
#### 4.2 使用多线程或异步IO方式提高爬取速度
当需要爬取大量数据时,可以考虑利用多线程或异步IO方式提高爬取速度,以节约时间和资源。通过同时执行多个请求或采用异步IO模式,可以充分利用计算机的多核性能和网络资源,加快数据的获取速度。
```python
import requests
import threading
def fetch_data(url):
response = requests.get(url)
# 处理响应数据的逻辑
urls = ['https://www.example.com/page1', 'https://www.example.com/page2', 'https://www.example.com/page3']
threads = []
for url in urls:
thread = threading.Thread(target=fetch_data, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
```
#### 4.3 避免被网站封禁的策略
为了避免被网站识别为恶意爬虫而封禁IP或采取其他限制措施,开发爬虫程序时需要注意一些策略,如设置访问频率、尽量不要对同一目标频繁请求等。此外,也可以使用代理IP进行请求,以减少对单一IP地址的请求频率,从而降低被封禁的风险。
通过以上提升爬虫程序效率的方法,可以使爬虫程序更高效、稳定地获取数据,提升整体开发体验和效果。
# 5. 爬取特定网页数据
在本章中,我们将针对特定网页进行数据爬取,实现对目标数据的获取和处理。
#### 5.1 确定目标网站及需要获取的数据
在进行数据爬取之前,首先需要确定我们的目标网站以及需要获取的具体数据类型。这可以包括网站的URL地址、页面结构、目标数据的位置等信息。以确定清晰的爬取目标。
#### 5.2 编写爬虫程序实现数据抓取
在编写爬虫程序时,我们可以利用Requests库发送HTTP请求,并通过解析HTML页面和提取目标数据的方式,实现数据的抓取。可以使用Beautiful Soup、XPath或正则表达式等工具进行数据解析。
#### 5.3 数据处理与存储
获取到目标数据后,我们可以进行进一步的数据处理,包括数据清洗、格式转换等操作。最后,我们可以选择将数据存储到本地文件、数据库或其他数据存储介质中,以便后续分析和应用。
通过以上步骤,我们可以实现对特定网页数据的爬取,并将其应用于实际场景中。
# 6. 面对反爬措施的挑战与解决方案
在实际爬虫过程中,我们常常会面对各种网站的反爬措施,为了顺利获取数据,我们需要理解这些反爬措施并采取相应的解决方案。下面将介绍如何应对这些挑战:
#### 6.1 识别常见的反爬手段
- **User-Agent检测:** 网站会通过User-Agent信息来判断请求是否来自爬虫,如果检测到是爬虫请求,则会拒绝服务或返回伪造数据。
- **IP限制:** 网站可能会对频繁访问同一IP地址的请求进行限制,导致爬虫无法正常访问网站。
- **验证码:** 有些网站会在访问频繁或请求过多时,要求用户输入验证码才能访问,给爬虫带来了困难。
#### 6.2 使用代理IP和User-Agent等方法进行反制
- **代理IP:** 通过使用代理IP,可以隐藏真实IP地址,降低被网站封禁的风险,同时也可以实现更高效的数据爬取。
```python
import requests
url = 'http://example.com'
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.11:1080',
}
response = requests.get(url, proxies=proxies)
print(response.text)
```
- **随机User-Agent:** 在请求时随机选择不同的User-Agent信息,模拟不同用户的请求,减少被识别为爬虫的概率。
```python
import requests
from fake_useragent import UserAgent
url = 'http://example.com'
ua = UserAgent()
headers = {'User-Agent': ua.random}
response = requests.get(url, headers=headers)
print(response.text)
```
#### 6.3 实践中的应对策略与技巧
- **限制请求频率:** 合理设置爬取间隔时间,避免短时间内频繁请求同一网站,降低被封禁风险。
- **使用验证码识别工具:** 针对需要验证码的网站,可以使用验证码识别工具进行处理,提高爬虫的自动化程度。
- **模拟人工操作:** 在爬取过程中,模拟真实用户的行为路径、点击等操作,降低被识别为爬虫的概率。
通过以上方法,我们能够更加灵活高效地应对各种网站的反爬措施,顺利获取我们需要的数据。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“pid”是一本全面的技术指南,涵盖了广泛的技术领域。它从编程语言的基础知识开始,深入探讨数据结构和算法,以及Python实战和数据库入门。此外,它还深入探索了前端开发、面向对象编程、Linux命令和Shell脚本编程。
专栏还涵盖了更高级的技术,如网络协议、网络安全、数据科学、大数据技术、微服务架构、容器化应用开发、云计算、自然语言处理、区块链、移动应用开发、物联网、机器人学、自动化测试和深度学习。
无论您是技术新手还是经验丰富的专业人士,“pid”专栏都为每个人提供了宝贵的见解和实用指南,帮助您在技术世界中取得成功。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
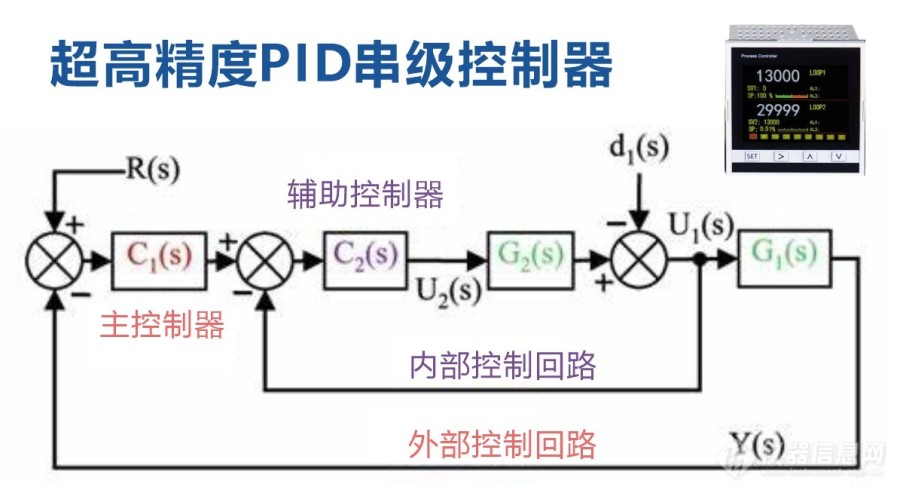
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
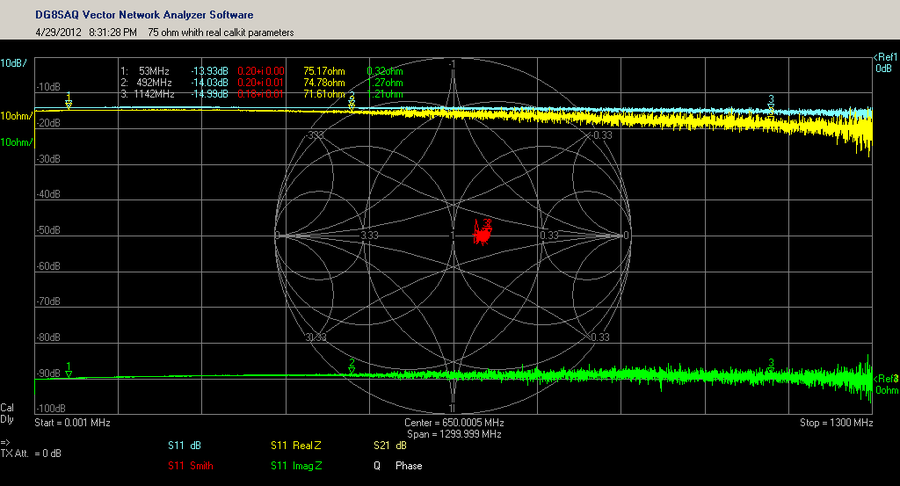
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )