【编程基础打造】:专升本程序设计要点全掌握!
发布时间: 2024-12-15 12:26:55 阅读量: 4 订阅数: 2 

重庆专升本计算机VF程序设计.doc
参考资源链接:[2021广东专插本计算机基础真题及答案解析](https://wenku.csdn.net/doc/3kcsk8vn06?spm=1055.2635.3001.10343)
# 1. 编程基础概述
编程是构建现代软件技术的基石。对于初学者来说,掌握基础概念是至关重要的,这些概念包括变量、数据类型、控制流程、函数和模块化编程。理解这些概念有助于新手在掌握更高级的编程技巧之前,建立起扎实的基础知识结构。
## 1.1 编程语言的选择
选择合适的编程语言是迈向成功的第一步。不同的编程语言适用于不同的场景,例如:Python以其易读性和简洁性在数据分析和人工智能领域广泛使用;JavaScript则是在Web开发中不可或缺的语言。正确选择语言可以提高开发效率并降低项目的复杂度。
## 1.2 环境搭建与工具熟悉
工欲善其事,必先利其器。安装开发环境、熟悉文本编辑器或集成开发环境(IDE)是每个程序员的必经之路。例如,对于Python开发者来说,安装Anaconda并配置Jupyter Notebook可以让数据科学实验变得更加简便。
```python
# 示例:Python环境配置和简单代码示例
print("Hello, World!") # 输出 Hello, World! 到控制台
```
在本章节中,我们将简单介绍编程语言的基础知识、选择合适的编程语言以及如何搭建开发环境,为下一章深入探讨程序设计打下坚实基础。
# 2. 程序设计核心概念
在深入探讨编程和软件开发的世界时,理解程序设计的核心概念是至关重要的。这些概念构成了现代编程语言的基石,并且是软件开发者在创建高效和可维护的软件时所依赖的基础。本章将细致地探讨这些核心概念,从数据类型和变量的使用到控制结构与流程,再到函数与模块化编程的设计与实现。
## 2.1 数据类型与变量
### 2.1.1 数据类型基础与选择
在编程中,数据类型是定义变量或函数可以存储或处理的数据种类的构造。数据类型为变量赋予了特定的意义和限制,确保数据能够被正确处理。每种数据类型都有其特定的范围和操作。选择正确的数据类型对于程序的性能、可读性和正确性至关重要。
基本数据类型包括整型、浮点型、字符型和布尔型等。不同的编程语言有不同的数据类型实现,例如在C语言中,基本数据类型包括`int`、`float`、`double`、`char`等,而在Java中则有`byte`、`short`、`int`、`long`、`float`、`double`、`char`、`boolean`等。
当选择数据类型时,开发者需要考虑数据的范围、内存使用以及操作的精确性。例如,对于存储年龄,一个`byte`类型的数据就足够了,因为年龄的值域通常在0到120左右。但如果需要存储大量数字并且进行复杂的数学计算,`float`或`double`类型会是更好的选择。
### 2.1.2 变量的声明、初始化和作用域
变量是存储数据值的命名位置。它们是程序中不可或缺的组件,因为它们存储了程序运行时所需的信息。
变量的声明包括指定变量的数据类型和名称。在声明时,程序员需明确变量类型以及变量名,例如在Java中声明一个整型变量:`int number;`。
初始化是在声明变量的同时给变量赋予一个初始值。这可以保证变量在使用前已经被赋予了预期的值,而不是一个随机的垃圾值,例如`int number = 0;`。初始化减少了程序的运行时错误,并有助于提高代码的可读性。
变量的作用域指的是变量可以在哪些部分的代码中被访问。变量的作用域取决于其声明的位置。例如,在C++中,局部变量的作用域限于声明它们的函数内部,而全局变量可以在整个程序的任何地方访问。正确管理变量作用域有助于创建封装性更好的代码,并可以避免不必要的变量命名冲突。
下面是一个C++代码示例,演示了变量声明、初始化和作用域的概念:
```cpp
#include <iostream>
int globalNumber = 10; // 全局变量初始化
void function() {
int localNumber = 5; // 局部变量初始化
std::cout << "Global Number: " << globalNumber << std::endl;
std::cout << "Local Number: " << localNumber << std::endl;
}
int main() {
std::cout << "Global Number: " << globalNumber << std::endl;
function();
// std::cout << "Local Number: " << localNumber << std::endl; // 错误: localNumber不在作用域内
return 0;
}
```
在上述代码中,`globalNumber` 是全局变量,可以在 `main` 函数和 `function` 函数中被访问。而 `localNumber` 是在 `function` 函数内局部声明的变量,仅限于在 `function` 内部使用。试图在 `main` 函数中访问 `localNumber` 会导致编译错误,因为它的作用域仅限于声明它的函数内。
通过本节的介绍,你可以了解到数据类型与变量是程序设计中最基础的组成部分,它们是构建更复杂概念如控制结构、函数和模块化编程的基石。正确地选择和使用数据类型,并合理地声明、初始化和控制变量的作用域,对于编写可读性好、高效和可维护的代码至关重要。在下一节中,我们将进一步深入控制结构和程序流程的讨论,探索顺序执行、条件判断和循环控制等程序设计中的关键环节。
# 3. 面向对象编程基础
### 3.1 类与对象的创建与使用
面向对象编程(OOP)是目前主流的编程范式之一,它强调使用对象来设计和开发软件。对象是类的实例,类则是对象的蓝图。本节将深入探讨类和对象的创建与使用,以及它们如何在编程实践中发挥作用。
#### 3.1.1 类的定义和属性
类是面向对象编程中的一个核心概念,它定义了一组具有相同属性和行为的对象。在定义类时,需要指定其属性和方法。
```java
class Car {
String model;
int year;
void start() {
// start car engine
}
void stop() {
// stop car engine
}
}
```
上面的Java代码定义了一个简单的`Car`类,具有`model`和`year`两个属性,以及`start`和`stop`两个方法。这些方法定义了汽车的行为,即启动和停止引擎。
#### 3.1.2 对象的实例化和生命周期
对象是类的实例,对象的生命周期从实例化开始,到不再被任何变量引用而被垃圾回收结束。
```java
public class Main {
public static void main(String[] args) {
Car myCar = new Car(); // 实例化
myCar.model = "Tesla Model S"; // 访问并赋值属性
myCar.start(); // 调用方法
}
}
```
在这个Java示例中,我们实例化了一个`Car`对象,并给它的属性赋值,然后调用了它的方法。当`myCar`对象在`main`方法结束后不再被引用,它就会被垃圾回收器处理。
### 3.2 继承与多态
#### 3.2.1 继承的概念与实现
继承是面向对象编程中一个重要的概念,它允许创建一个类(子类),它继承另一个类(父类)的属性和方法。
```java
class ElectricCar extends Car {
int batteryCapacity;
void recharge() {
// recharge battery
}
}
```
在这里,`ElectricCar`类继承自`Car`类,并添加了一个新的属性`batteryCapacity`和一个新方法`recharge`。
#### 3.2.2 多态的表现与应用
多态允许我们将子类对象当作其父类类型的对象使用。这样,我们可以在运行时根据对象的实际类型来决定调用哪个方法。
```java
Car car = new ElectricCar();
car.start(); // 调用Car类中的start方法
```
在上面的例子中,尽管`car`变量实际指向的是`ElectricCar`类型的对象,但我们可以将其视为`Car`类型的对象,并调用`start`方法。如果在`ElectricCar`中重写了`start`方法,那么实际调用的将是子类版本的`start`。
### 3.3 封装与访问控制
#### 3.3.1 封装的目的与实现方式
封装是一种隐藏对象内部状态和行为的机制,只暴露有限的操作接口。封装有助于减少系统中各个组件之间的依赖。
```java
class BankAccount {
private double balance;
public void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
public double getBalance() {
return balance;
}
}
```
在`BankAccount`类中,`balance`属性是私有的,意味着它不能直接从类外部访问。我们提供`deposit`和`getBalance`方法来操作和查询余额。
#### 3.3.2 访问修饰符的作用域控制
Java提供了不同的访问修饰符来控制类、方法和变量的可访问性。常见的访问修饰符有`private`、`default`(无修饰符)、`protected`和`public`。
```java
public class AccessModifiers {
public static void main(String[] args) {
BankAccount account = new BankAccount();
account.deposit(100); // 公共方法可访问
System.out.println(account.getBalance());
}
}
```
在这个例子中,即使`balance`是私有的,我们仍然可以通过公共方法`deposit`和`getBalance`来间接访问它。这展示了封装和访问控制如何共同工作来保护类的内部状态。
# 4. 数据结构与算法基础
## 4.1 常见的数据结构
在计算机科学和软件工程中,数据结构是组织和存储数据的一种方式,以便于访问和修改。更高效的数据结构可以显著提高算法的性能。
### 4.1.1 数组、链表、栈和队列
这些基础数据结构是构建更复杂数据结构和算法的基石。
#### 数组 (Arrays)
数组是一种线性数据结构,它按照顺序存储一系列相同类型的元素。数组中的元素可以通过下标直接访问,下标通常从0开始。
```c
// C语言中的数组使用示例
int arr[10]; // 声明一个包含10个整数的数组
arr[0] = 1; // 通过下标访问和赋值
```
数组的操作主要有:初始化、读取、修改元素、迭代遍历等。数组的优点是快速随机访问,但其大小是固定的,且插入和删除操作相对低效,因为这通常涉及移动大量元素。
#### 链表 (Linked Lists)
链表是一种包含一系列节点的线性集合。每个节点都包含数据部分和一个或多个指向下个节点的引用。
```python
# Python中的单链表节点定义示例
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
```
链表的优点是动态大小且易于插入和删除,但访问元素需要遍历链表,所以随机访问效率较低。
#### 栈 (Stacks)
栈是一种后进先出(LIFO)的数据结构,它只允许在结构的末端进行添加和移除数据的操作。
```javascript
// JavaScript中的栈操作示例
class Stack {
constructor() {
this.items = [];
}
push(item) {
this.items.push(item);
}
pop() {
return this.items.pop();
}
}
```
栈通常用于实现函数调用、撤销操作和深度优先搜索。
#### 队列 (Queues)
队列是一种先进先出(FIFO)的数据结构,它允许在结构的末端添加元素,并从另一端移除元素。
```java
// Java中的队列操作示例
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
queue.offer(1); // 添加元素
queue.offer(2);
int removedElement = queue.poll(); // 移除并返回元素
System.out.println(removedElement);
}
}
```
队列常用于实现缓存、任务调度和广度优先搜索。
### 4.1.2 树、图和散列表
这些数据结构在处理复杂关系和高效检索方面发挥着关键作用。
#### 树 (Trees)
树是一种分层数据结构,它由节点组成,节点间有连接(边),通常具有一个根节点和子节点。
```java
// Java中的树节点定义示例
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
```
树的特定类型包括二叉树、二叉搜索树、平衡树、红黑树等,它们在数据库索引、文件系统、排序和搜索算法中有着广泛的应用。
#### 图 (Graphs)
图由顶点(节点)的集合和连接顶点的边组成,图可以是有向的或无向的,并可以包含权重。
```python
# Python中的图操作示例
class Graph:
def __init__(self):
self.graph_dict = {}
def add_vertex(self, vertex):
if vertex not in self.graph_dict:
self.graph_dict[vertex] = []
def add_edge(self, edge):
(vertex1, vertex2) = edge
self.add_vertex(vertex1)
self.add_vertex(vertex2)
self.graph_dict[vertex1].append(vertex2)
self.graph_dict[vertex2].append(vertex1)
```
图的算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、最短路径(如Dijkstra算法)和最小生成树(如Prim和Kruskal算法)。
#### 散列表 (Hash Tables)
散列表是一种通过散列函数处理数据,将键映射到对应值的数据结构。散列表提供了快速的插入、删除和查找操作。
```c
// C语言中的简单散列表实现示例
#define TABLE_SIZE 100
typedef struct Entry {
int key;
int value;
struct Entry *next;
} Entry;
Entry *hashtable[TABLE_SIZE]; // 散列表数组
int hash(int key) {
return key % TABLE_SIZE; // 简单的散列函数
}
```
散列表的应用包括数据库索引、哈希表、缓存机制、集合操作等。需要处理冲突解决策略,如开放寻址法和链表法。
以上介绍的数据结构在实际应用中相互结合使用,共同构建出强大的数据处理和算法解决方案。在本章节中,我们将深入了解算法的设计与分析,这些算法如何与数据结构相互作用,以及它们在实际问题解决中的应用。
# 5. 实战演练与项目构建
## 5.1 小型项目的规划与开发流程
### 5.1.1 需求分析和设计
在进行项目开发之前,需求分析是一个关键步骤,它涉及到与项目的利益相关者进行沟通,明确项目的目标和要求。在这一步骤中,我们通常需要创建用例图、活动图和业务流程图等,以可视化需求和预期的业务流程。
一旦需求被定义,接下来就需要进行系统设计。设计可以包括软件架构、数据库设计、用户界面设计等。在这一阶段,我们可能需要使用一些设计模式来保证系统的灵活性和可扩展性。
### 5.1.2 代码实现与版本控制
代码实现是根据设计文档编写实际代码的过程。开发者在这一阶段需要关注代码的质量、测试以及代码风格的一致性。对于团队协作来说,版本控制是不可或缺的。Git是最常用的版本控制系统,它可以帮助开发者记录项目的历史状态,并在团队成员之间高效地协作。
```mermaid
graph LR
A[开始] --> B[需求分析]
B --> C[系统设计]
C --> D[代码实现]
D --> E[代码审查]
E --> F[版本控制]
F --> G[测试]
G --> H[部署上线]
```
## 5.2 开发环境与工具
### 5.2.1 集成开发环境(IDE)的选择
集成开发环境(IDE)是一个为程序员提供编写代码、调试和运行程序等所有功能的软件应用程序。一个高效的IDE能够大大提高开发效率。不同的IDE有其各自的特点,如Visual Studio Code适合前端开发,Eclipse和IntelliJ IDEA则是Java开发者的首选。
### 5.2.2 调试工具与性能分析
调试是开发过程中不可或缺的部分。现代IDE通常内置了强大的调试工具,它能够使开发者单步执行代码,观察变量状态,甚至在运行时修改变量值。性能分析工具则帮助开发者定位代码中的瓶颈,优化性能。
## 5.3 实战案例分析
### 5.3.1 一个简单应用的开发案例
假设我们要开发一个简单的待办事项应用。首先,我们需要确定应用的基本功能,如添加、删除、编辑和查看待办事项。然后,我们根据功能要求来设计数据库模型和应用界面。在实现代码的时候,我们可能会用到MVC设计模式来分离数据、业务逻辑和界面。
### 5.3.2 项目中的问题解决与总结
在开发过程中,我们可能会遇到各种问题,比如数据存储的问题、前端和后端的数据同步问题等。通过团队讨论和对现有技术的研究,我们可以找到解决方案。项目完成后,回顾整个开发过程,记录下哪些地方做得好,哪些地方需要改进,将有助于我们未来的项目。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
离散时间信号与系统实现:分析与操作指南
参考资源链接:[《数字信号处理》第三版课后答案解析](https://wenku.csdn.net/doc/12dz9ackpy?spm=1055.2635.3001.1
【送料机构设计原理】:深度解析送料机制构造与工作原理,让你的设计更加精准
.png?mw=1000&hash=95c18cc54587512e123ef22f83defb8a7f7f8789)
参考资源链接:[板料冲制机冲压与送料机构设计解析](https://wenku.csdn.net/doc/5hfp00n04s?spm=1055.2635.3001.10343)
# 1. 送料机构的设计基础与功能概述
## 1
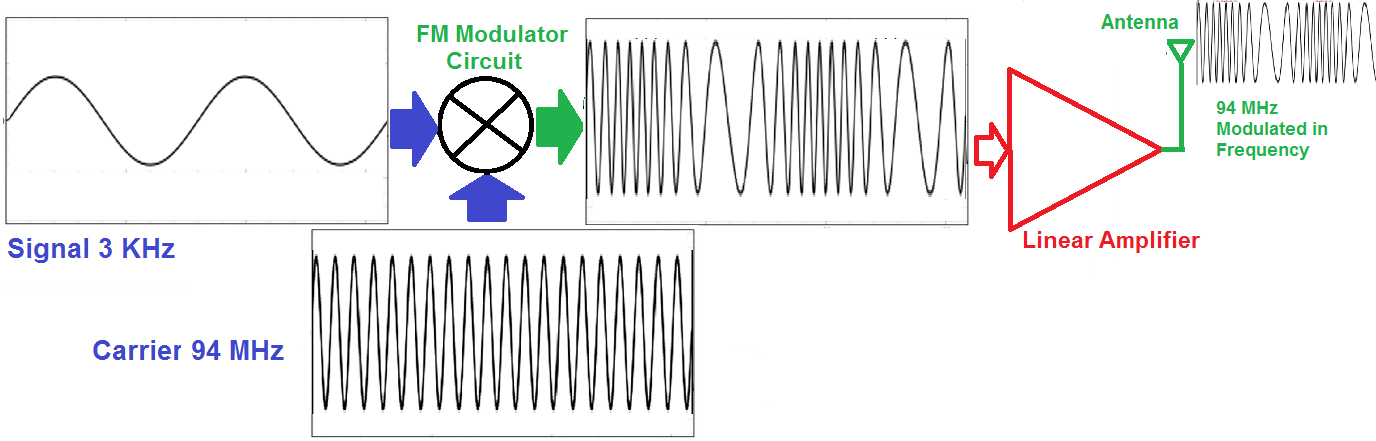
数字通信同步技术:3步走,理论与实践无缝对接
参考资源链接:[9ku文库_数字通信第五版答案_数字通信第五版习题及答案完整版.pdf](https://wenku.csdn.net/doc/4mxpsvzwxh?spm=1055.2635.3001.10343)
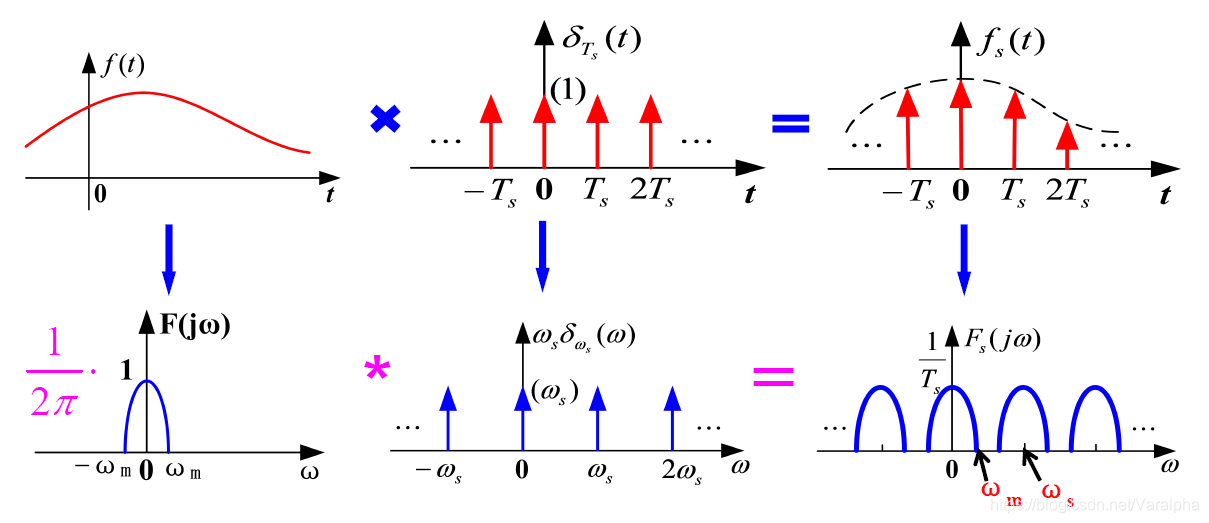
# 1. 数字通信同步技术概述
同步技术在数字通信中起着至关重要的作用。它确保数据包在复杂的网
【代码规范检查全攻略】:EETOP.cn SpyGlass LintRules教程

参考资源链接:[SpyGlass Lint规则参考指南:P-2019.06-SP1](https://wenku.csdn.net/doc/5y956iqsgn?spm=1055.2635.3001.10343)
# 1. 代码规范检查概述
## 1.1 代码规范检查的重要性
在软件
【西门子PLC STL编程秘籍】:全面入门到精通指南

参考资源链接:[西门子STL编程手册:语句表指令详解](https://wenku.csdn.net/doc/1dgcsrqbai?spm=1055.2635.3001.10343)
# 1. 西门子PLC STL编程基础
西门子PLC(Programmable Logic Controller)作为自动化领域的领导者,其STL(Statement List)
【海明码全解析】:10个关键技巧让你成为编码专家

参考资源链接:[海明码与码距:概念、例子及纠错能力分析](https://wenku.csdn.net/doc/5qhk39kpxi?spm=1055.2635.3001.10343)
Tetgen高级功能全解析:自定义约束与边界处理技巧

参考资源链接:[tetgen中文指南:四面体网格生成与优化](https://wenku.csdn.net/doc/77v5j4n744?spm=1055.2635.3001.10343)
# 1. Tetgen软件概述与基础功能
## 1.1 Tetgen软件简介
Tetgen是一款开源的三维网格生成器,专门为科学研究与工程应用设计。它能够自动将三维几何模型划分为高质量的四面体网格,对处理复杂的表面和体
【FIBOCOM FM150-AE 系列硬件深度解析】:性能提升必备攻略
参考资源链接:[FIBOCOM FM150-AE系列硬件指南:5G通信模组详解](https://wenku.csdn.net/doc/5a6i74w47q?spm=1055.2635.3001.10343)
# 1. FIBOCOM FM150-AE 系列硬件概览
FIBOCOM FM150-AE 系列硬件作为面向工业级应用设计的通信模块,以高性能、高稳定性和低功耗的特点获得市场的青睐。本章节将对FM150-AE系列进行全方位的硬件概览,包括硬件设计理念、主要功能特点以及应用场景。通过清晰的架构图和功能描述,读者可以迅速把握该系列硬件的核心技术和优势。
## 1.1 硬件设计理念
设计
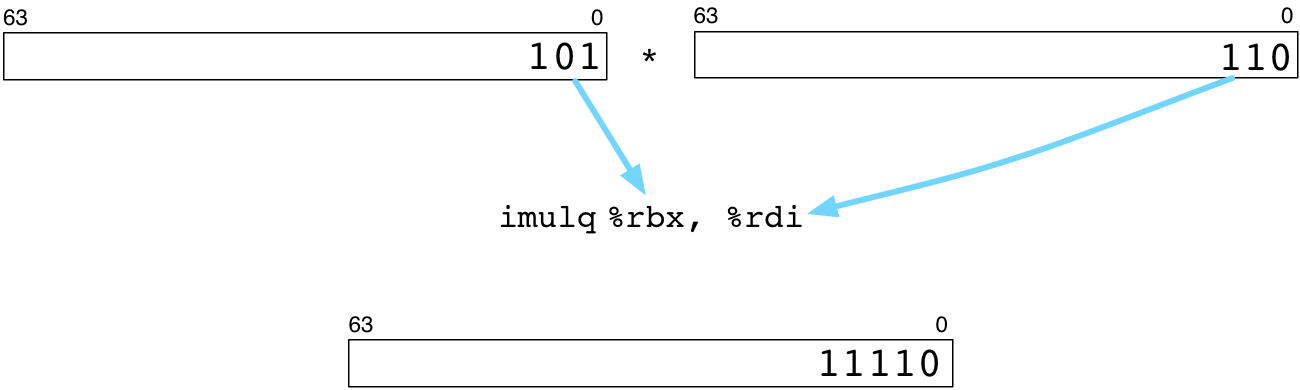
一文精通8051汇编:指令全览与编程高手秘籍
参考资源链接:[8051指令详解:111个分类与详细格式](https://wenku.csdn.net/doc/1oxebjsphj?spm=1055.2635.3001.10343)
# 1. 8051微控制器及汇编语言概述
## 微控制器简介
微控制器(MCU)是一种集成电路芯片,它集成了处理器核心、存储器和各种外设接口,广泛应用于嵌入式系统和自动控制领域。8051微控制器是微控制器领域的一个经典范例,它的简单性和易用性使它成为教学
CEC05 benchmark深度探索:挑战极限,提升算法性能

参考资源链接:[CEC2005真实参数优化测试函数与评估标准](https://wenku.csdn.net/doc/ewbym81paf?spm=1055.2635.3001.10343)
# 1. CEC05基准测试简介
## 什么是CEC05基准测试
CEC05基准测试是针对连续、离散以及多目标优化算法性能评估的年度竞赛。其目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )