【C语言数据类型】:9个关键点深入剖析变量与内存管理
发布时间: 2024-12-10 01:07:27 阅读量: 7 订阅数: 18 

C语言深度剖析笔记_
# 1. C语言数据类型的概述
C语言是IT行业中一门经典的编程语言,其强大的功能和灵活性主要源于其丰富的数据类型。理解数据类型是学习C语言的基础,也是进行高效编程的前提。
## 1.1 数据类型的意义
在编程世界中,数据类型是定义变量存储数据的种类和范围的一种方法。它有助于编译器在编译时期做出正确的内存分配,并确保在运行时期,数据的操作符和函数能够正确地应用于这些数据。
## 1.2 C语言中的数据类型
C语言提供了多种数据类型,按照存储数据的不同,大致可以分为基本数据类型、构造类型、指针类型和空类型四大类。基本数据类型包括整型、浮点型、字符型等;构造类型是由基本类型组合而成,如数组和结构体;指针类型存储的是内存地址;而空类型主要用于函数返回无值的情况。
理解数据类型,不仅能帮助我们更好地控制数据的存储,还能提高程序的执行效率。接下来的章节将对各类数据类型进行更详细的解析和讲解。
# 2. 基本数据类型详解
## 2.1 整型家族
### 2.1.1 int类型及其范围
在C语言中,`int` 类型是最基本的整型数据类型,通常用于存储整数值。在32位系统上,`int` 通常占用4个字节(32位),其取值范围依赖于编译器,但在大多数平台上,其范围是从-2,147,483,648到2,147,483,647。在64位系统上,`int` 的大小可能也是4个字节,但其取值范围与32位系统相同,这是为了向后兼容。
```c
#include <stdio.h>
int main() {
printf("int size in bytes: %zu\n", sizeof(int));
printf("int minimum value: %d\n", INT_MIN);
printf("int maximum value: %d\n", INT_MAX);
return 0;
}
```
在上述代码中,我们使用了 `sizeof` 操作符来确定 `int` 类型在当前系统中的大小,并通过 `INT_MIN` 和 `INT_MAX` 预定义宏来输出 `int` 类型的最小值和最大值。
### 2.1.2 short、long和long long的差异
除了标准的 `int` 类型,C语言还提供了其他整型:`short`、`long` 和 `long long`。它们各自有不同的大小和用途。
- `short` 通常用于需要节省内存的情况,其大小为2字节(16位)。
- `long` 通常为4字节(32位),但在64位系统上,`long` 可能是8字节(64位),以适应更大的地址空间。
- `long long` 是在C99标准中引入的,至少为8字节(64位),用于存储更大的整数值。
```c
#include <stdio.h>
int main() {
printf("short size in bytes: %zu\n", sizeof(short));
printf("long size in bytes: %zu\n", sizeof(long));
printf("long long size in bytes: %zu\n", sizeof(long long));
return 0;
}
```
在执行这段代码时,我们可以观察到不同系统和编译器对这些类型的大小的影响。
## 2.2 浮点数类型
### 2.2.1 float和double的区别
浮点数类型用于存储小数或者实数。C语言中,`float` 用于存储单精度浮点数,而 `double` 用于存储双精度浮点数。`float` 通常占用4个字节,而 `double` 占用8个字节。
```c
#include <stdio.h>
int main() {
printf("float size in bytes: %zu\n", sizeof(float));
printf("double size in bytes: %zu\n", sizeof(double));
return 0;
}
```
### 2.2.2 浮点数的精度问题
浮点数精度是需要注意的问题。由于浮点数使用二进制表示,某些十进制数可能无法精确表示,这会导致精度丢失。通常,`double` 提供比 `float` 更高的精度。
```c
#include <stdio.h>
int main() {
float f = 0.1;
double d = 0.1;
printf("Float representation of 0.1: %.15f\n", f);
printf("Double representation of 0.1: %.15f\n", d);
return 0;
}
```
在该代码段中,我们尝试打印 `float` 和 `double` 类型的 `0.1` 的表示,可以看到 `double` 类型提供了更加精确的表示。
## 2.3 字符类型
### 2.3.1 char的使用和字符集编码
`char` 类型用于存储字符,通常占用1个字节。`char` 类型既可以表示字符也可以表示小整数。字符编码可以是ASCII或扩展的字符集如UTF-8。
```c
#include <stdio.h>
int main() {
char c = 'A';
printf("The character '%c' is represented as %d\n", c, c);
return 0;
}
```
### 2.3.2 字符数组和字符串处理
字符数组用于存储字符串。在C语言中,字符串总是以空字符(null terminator)`'\0'` 结尾。
```c
#include <stdio.h>
#include <string.h> // 引入字符串处理函数库
int main() {
char str[] = "Hello, World!";
printf("The string '%s' is %zu characters long\n", str, strlen(str));
return 0;
}
```
字符串的处理包括复制、连接、比较等操作,C标准库提供了如 `strcpy`, `strcat`, `strcmp` 等函数用于处理字符串。
以上我们分别介绍了整型家族、浮点数类型以及字符类型的基础知识。深入理解这些基本数据类型对于编写高效和正确的C语言代码至关重要,特别是在内存使用和性能优化方面。接下来的章节将继续深入探讨构造类型及其应用,让我们能够构建更为复杂和功能丰富的数据结构。
# 3. 构造类型及其应用
## 3.1 数组的声明和使用
### 3.1.1 一维数组和多维数组的初始化
数组是构造类型中的一种,用于存储固定大小的相同类型元素。在C语言中,声明和初始化数组是一个基础而重要的操作。一维数组存储线性数据,而多维数组则用于存储表格形式或矩阵形式的数据。
**一维数组初始化:**
```c
int array[5] = {1, 2, 3, 4, 5};
```
在上述代码中,我们声明了一个包含5个整数的数组`array`,并使用花括号初始化。如果初始化时没有完全指定所有元素,则剩余元素会自动初始化为0。
```c
int array[5] = {1}; // 剩余元素会自动为0,结果为 {1, 0, 0, 0, 0}
```
**多维数组初始化:**
```c
int matrix[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
```
这里声明了一个2行3列的二维数组`matrix`。如果没有为所有元素提供初始值,则只有第一维(行)可以省略大小,其他维度必须指定大小。
```c
int matrix[2][3] = {[0][0] = 1}; // 只初始化一个元素,其余自动为0
```
### 3.1.2 数组与指针的关系
数组和指针在C语言中是紧密相关的。数组名在大多数表达式中会被解释为指向数组第一个元素的指针。
```c
int array[] = {1, 2, 3};
int *ptr = array; // ptr 指向数组的第一个元素
```
当你通过索引访问数组元素时,如`array[i]`,实际上是在访问`*(array + i)`。
在处理多维数组时,指针的算术和解引用会更加复杂,但原理是相同的。对于二维数组,`array[i][j]`等同于`*(*(array + i) + j)`。
## 3.2 结构体的定义和操作
### 3.2.1 结构体的基本定义和使用
结构体是C语言中将不同类型数据组合成一个单一类型的一种复合数据类型。它是一种构造类型,允许创建和操作复杂的数据结构。
**定义结构体:**
```c
struct Person {
char *name;
int age;
float height;
};
```
这里定义了一个名为`Person`的结构体,包含一个字符指针`name`,一个整型`age`和一个浮点数`height`。
**使用结构体:**
```c
struct Person person1;
person1.name = "Alice";
person1.age = 30;
person1.height = 5.5;
```
在上述代码中,我们声明了一个`Person`类型的变量`person1`并为其成员变量赋值。
### 3.2.2 结构体与函数的交互
结构体可以作为函数的参数、返回值,或者用于函数内部作为局部变量。
**作为函数参数传递:**
```c
void printPerson(struct Person person) {
printf("Name: %s, Age: %d, Height: %.2f\n", person.name, person.age, person.height);
}
```
在上面的函数`printPerson`中,我们以`Person`类型的结构体作为参数,并打印其内容。
**作为返回值:**
```c
struct Person getPerson() {
struct Person p;
// 假设从某处获取数据填充到p中
return p;
}
```
函数`getPerson`返回一个`Person`类型的结构体实例。
### 结构体的动态内存分配
结构体也可以使用动态内存分配,特别是当结构体大小在编译时未知或当需要创建结构体数组时。
```c
struct Person *createPersonArray(int size) {
struct Person *arr = malloc(size * sizeof(struct Person));
if (arr == NULL) {
// 错误处理
exit(EXIT_FAILURE);
}
return arr;
}
```
上面的`createPersonArray`函数为`Person`类型的数组分配了动态内存,并返回指向该数组的指针。
## 3.3 联合体与枚举类型
### 3.3.1 联合体的特点和应用场景
联合体(Union)是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。联合体的大小等于它最大成员的大小。
**定义联合体:**
```c
union Data {
int i;
float f;
char str[20];
};
```
这里定义了一个`Data`类型的联合体,它可以存储一个整数、一个浮点数或一个字符数组。
**联合体的应用场景:**
- **节省空间:** 当需要在不同的数据类型中共享内存时。
- **多种类型数据的混合:** 用于实现可以保存不同数据类型的一个变量,例如在某些嵌入式系统中。
### 3.3.2 枚举类型的定义和好处
枚举类型(Enum)是一组命名整型常量的集合。它使得程序代码的可读性和维护性得到提高。
**定义枚举类型:**
```c
enum Color {
RED,
GREEN,
BLUE
};
```
这里定义了一个名为`Color`的枚举类型,包含三个值:`RED`、`GREEN`和`BLUE`。
**枚举类型的好处:**
- **代码可读性:** 使用枚举常量替代晦涩的数字,使代码更易阅读和理解。
- **减少错误:** 避免了使用整数常量时可能发生的值不匹配错误。
- **类型安全:** 提高代码的类型检查能力。
在后续章节中,我们将继续深入探讨指针、内存管理、数据类型转换以及如何针对不同的应用场景优化数据类型的使用。
# 4. 指针与内存管理
## 4.1 指针的概念与声明
### 4.1.1 指针的基本概念和作用
指针是C语言中的核心概念之一,它提供了一种直接访问内存的方式。指针变量存储的是内存地址,通过指针我们可以访问和操作其他变量所占用的内存空间。这一特性使得指针在动态数据结构的实现(如链表、树、图等)以及内存动态分配等方面发挥着至关重要的作用。
### 4.1.2 指针与数组、函数的关系
指针与数组有着天然的联系。在C语言中,数组名本质上是一个指向数组首元素的指针。这种关系使得我们可以用指针来遍历数组元素,或者将数组作为参数传递给函数时,通过指针来处理。此外,函数也可以返回指针类型的数据,允许函数返回动态分配的内存或者数组、结构体等数据结构的地址。
## 4.2 指针的高级用法
### 4.2.1 指针与结构体的结合使用
指针与结构体的结合使用极大增强了C语言对复杂数据结构的处理能力。通过指针访问结构体成员不仅节省了内存空间,还可以灵活地操作数据。利用指针指向结构体,可以在函数间传递结构体数据的地址,从而避免了结构体数据的复制,提高了效率。
```c
// 结构体定义
struct Person {
char* name;
int age;
};
// 使用指针操作结构体
int main() {
struct Person p;
p.name = "John Doe";
p.age = 30;
struct Person* ptr = &p;
printf("Name: %s, Age: %d\n", ptr->name, ptr->age);
return 0;
}
```
### 4.2.2 动态内存分配与释放
在C语言中,动态内存分配通常通过`malloc`、`calloc`、`realloc`和`free`这四个函数实现。动态内存管理允许我们在程序运行时申请内存,并且可以调整已经分配的内存大小。正确管理动态分配的内存,是避免内存泄漏和资源浪费的关键。
```c
// 动态内存分配和释放的示例
int main() {
int* array = (int*)malloc(10 * sizeof(int)); // 分配10个整数的内存空间
if (array == NULL) {
// 处理内存分配失败的情况
return 1;
}
// 初始化内存空间
for (int i = 0; i < 10; ++i) {
array[i] = i;
}
// 使用完毕后释放内存
free(array);
return 0;
}
```
## 4.3 内存泄漏与管理技巧
### 4.3.1 内存泄漏的原因和危害
内存泄漏是指程序在分配了内存后,未能在不再使用时及时释放,导致这些内存无法被后续操作重新使用。内存泄漏的危害在于它逐渐消耗系统资源,可能导致性能下降,甚至程序崩溃。在长时间运行的应用中,内存泄漏尤为严重。
### 4.3.2 防止内存泄漏的方法和工具
为了防止内存泄漏,应该遵循良好的编程实践,比如使用智能指针管理内存,确保每个分配的内存都有对应的释放操作。除此之外,还可以使用专门的内存检测工具,如Valgrind,它可以帮助开发者在代码中定位内存泄漏和内存错误。
```mermaid
graph LR
A[开始分析] --> B[编译程序带调试信息]
B --> C[运行程序并监控内存使用]
C --> D{是否发现内存泄漏?}
D -->|是| E[提供泄漏位置和上下文信息]
D -->|否| F[程序内存使用正常]
E --> G[修复内存泄漏问题]
G --> H[重新运行程序进行检测]
F --> I[报告内存管理良好]
```
代码块说明了如何使用Valgrind对一个简单的C程序进行内存泄漏检测:
```sh
valgrind --leak-check=full ./your_program
```
以上步骤和代码块展现了如何利用Valgrind工具检测内存泄漏,并通过示例展示了动态内存分配和释放的基本方法。下一章节中,我们将探讨数据类型转换与运算的规则和应用。
# 5. 数据类型转换与运算
## 5.1 类型转换规则和实例
### 5.1.1 隐式类型转换
C语言在执行运算时,当操作数的数据类型不一致时,会发生隐式类型转换(也称为自动类型转换)。隐式转换遵循一定的规则,通常遵循以下原则:
1. 如果操作数之一是`long double`类型,另一个操作数会转换为`long double`。
2. 否则,如果操作数之一是`double`类型,另一个操作数会转换为`double`。
3. 否则,如果操作数之一是`float`类型,另一个操作数会转换为`float`。
4. 否则,如果操作数之一是`unsigned long`类型,另一个操作数会转换为`unsigned long`。
5. 否则,如果操作数之一是`long`类型且另一个操作数是`unsigned int`类型,且`unsigned int`可以表示`long`的所有值,则另一个操作数转换为`unsigned int`,否则两者都转换为`long`。
6. 否则,如果操作数之一是`long`类型,另一个操作数转换为`long`。
7. 否则,如果操作数之一是`unsigned int`类型,另一个操作数转换为`unsigned int`。
隐式类型转换可能导致精度降低,例如,当`float`类型的数与`int`类型的数运算时,`int`类型数会转换为`float`类型数进行运算。
#### 示例代码:
```c
int a = 5;
float b = 2.5;
double c = a + b; // a隐式转换为float类型,然后与b相加,结果赋值给c
```
### 5.1.2 显式类型转换及注意事项
显式类型转换,也称为强制类型转换,是程序员主动指定数据类型的转换。格式为:`(目标类型) 表达式`。显式类型转换可以强制改变表达式中操作数的数据类型,但需要注意以下几点:
- 不要丢失数据:在转换过程中应确保不会丢失数据,例如,不要将较大的`int`类型转换为`char`。
- 符合逻辑的转换:只在逻辑上合理的场景下使用显式转换,例如,从`int`转为`float`以进行浮点运算。
- 确保转换前后类型兼容:在进行显式转换时,确保数据类型之间是可以转换的,例如,从`double`转为`int`。
#### 示例代码:
```c
int a = 123;
float b = (float)a; // 将int类型的a显式转换为float类型
```
## 5.2 类型转换的应用场景
### 5.2.1 与硬件相关的数据处理
在与硬件相关的低级编程中,数据类型的转换尤为重要。例如,在嵌入式开发中,常常需要将数据从一种格式转换为另一种格式,以适应硬件设备的要求。
- 从`int`到`char`:用于访问内存中的特定字节。
- 从`float`到`int`:用于处理数字的整数部分。
#### 示例代码:
```c
// 假设0x000000FF是我们想要修改的内存地址
unsigned char* ptr = (unsigned char*)0x000000FF;
int value = 0x12345678;
*ptr = (unsigned char)value; // 将int类型的值的最低字节写入内存地址
```
### 5.2.2 高性能计算中的类型选择
高性能计算需要对数据类型进行细致选择以达到最优性能。例如:
- 使用`float`而不是`double`可以减少计算时间并减小内存占用,但会损失一定的计算精度。
- 对于位操作,`int`或`unsigned int`类型更为高效。
#### 示例代码:
```c
float sum = 0.0f;
for (int i = 0; i < 1000000; ++i) {
sum += i; // 这里使用float而不是double可以节省计算时间
}
```
## 5.3 运算符与数据类型
### 5.3.1 运算符的优先级和类型影响
在C语言中,运算符有固定的优先级顺序。数据类型不同,运算的结果和运算符的优先级都可能受到影响。例如,整型和浮点型相加时,整型会被提升为浮点型再进行计算。
#### 示例代码:
```c
int a = 10;
double b = 5.5;
double c = a + b; // a会被提升为double类型再进行加法运算
```
### 5.3.2 类型对算术运算结果的影响
数据类型不同,可能导致不同的算术运算结果。例如,整型除法会丢失小数部分,而浮点型除法则会保留小数部分。
#### 示例代码:
```c
int a = 5;
int b = 2;
float c = a / (float)b; // 结果为2.5,因为b被提升为float类型
```
### 5.3.3 类型转换与运算符的结合使用
在实际应用中,我们经常会结合类型转换和运算符来达到预期的效果。了解类型转换和运算符的特性,可以帮助我们写出更高效的代码。
#### 示例代码:
```c
unsigned int a = 0xFFFFFFFF;
int b = (int)(a + 1); // 超过unsigned int表示范围时,会发生整型溢出
```
以上代码段通过强制类型转换,使得原本的无符号整型溢出,通过溢出得到我们预期的负数结果,这在某些特定场景下非常有用,例如在哈希表的索引计算中。
在这一章节中,我们深入探讨了C语言中的类型转换规则和应用实例,类型转换在不同的应用场景中扮演着重要的角色,特别是与硬件相关的数据处理和高性能计算中。理解类型转换和运算符之间的关系,可以帮助我们编写更高效且可靠的代码。
# 6. 深入理解C语言的数据类型
## 6.1 数据类型的适用场景分析
在C语言编程中,合适的数据类型选择对于程序的效率和可靠性至关重要。数据类型的适用场景分析需要考虑数据范围、内存占用、计算精度以及特定平台的需求。
### 6.1.1 如何根据需求选择数据类型
选择数据类型时,开发者需要对预期存储的数据范围有清晰的认识。例如:
- `int`类型适用于存储常规整数,但如果数值范围超过`int`的最大或最小值,就需要考虑使用`long`或`long long`类型。
- 对于需要高精度的科学计算,`double`类型比`float`类型更适合,因为其提供了更高的精度和更大的范围。
- 如果涉及到字符编码转换或字符串操作,应优先考虑使用`char`数组或标准库中的字符串处理函数。
### 6.1.2 数据类型与编译器优化
不同的数据类型对编译器优化有不同的影响。编译器通常可以对固定大小和类型的数组进行优化,提高访问速度。例如,使用`const`修饰符的变量可以被编译器优化为常量,减少运行时的开销。例如:
```c
const int MAX_SIZE = 100;
for (int i = 0; i < MAX_SIZE; i++) {
// Some processing
}
```
在这个例子中,`MAX_SIZE`是一个常量,编译器可以将循环次数在编译时确定,提高程序的执行效率。
## 6.2 标准库中的数据类型使用
C语言标准库为数据类型提供了广泛的处理支持,从基本输入输出到数据结构和算法,标准库都提供了丰富的接口。
### 6.2.1 标准输入输出中的数据类型处理
C语言中的`printf`和`scanf`是常用的输入输出函数,它们支持多种数据类型的格式化输出和输入。例如:
```c
int num = 42;
printf("The number is %d\n", num);
```
此代码段使用`%d`格式化占位符输出一个整型变量的值。
### 6.2.2 数据类型与STL容器的交互
C++标准模板库(STL)与C的数据类型有着良好的兼容性,C++中的STL容器,如`vector`和`map`,可以直接存储C语言的基本数据类型。C++中的STL容器会根据数据类型来自动分配内存,支持高效的数据操作。
```cpp
#include <vector>
#include <iostream>
int main() {
std::vector<int> myVec;
myVec.push_back(10); // 使用 push_back 存储 int 类型
std::cout << "The first element is " << myVec[0] << std::endl;
return 0;
}
```
在这个例子中,`std::vector<int>`能够处理`int`类型的数据。
## 6.3 数据类型在系统编程中的应用
系统编程通常需要与硬件接口紧密交互,数据类型的选用对于性能和兼容性尤为关键。
### 6.3.1 数据类型与操作系统接口
在系统编程中,数据类型需要根据操作系统提供的接口进行选择。例如,在Linux系统中,`size_t`类型常用于表示文件大小,它能很好地适应不同系统架构下的大小差异。
### 6.3.2 数据类型的字节序问题和跨平台开发
字节序(Endianness)决定了多字节数据在内存中的存储顺序,这对于跨平台开发至关重要。大端字节序(Big-endian)和小端字节序(Little-endian)在不同的硬件平台上有所差异。开发者在处理网络通信或二进制文件时,必须处理字节序问题以保证数据在不同平台间正确传输。
例如,网络通信中经常使用大端字节序作为标准,如果平台使用小端字节序,则需要在发送或接收数据时进行字节序转换。
```c
// 一个简单的字节序转换函数示例
uint16_t swap_endian(uint16_t val) {
return (val >> 8) | (val << 8);
}
```
此代码段展示了如何将16位的整数从一种字节序转换为另一种字节序。通过右移和左移操作的组合,可以在大小端之间进行转换。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C 语言中数据类型和变量的使用,从基本概念到高级技巧,全面覆盖了以下主题:
* 变量地址的运用和内存分配
* 常量和变量的比较和最佳实践
* 整型和浮点型的处理,高级技巧和性能优化
* 位字段和位运算,数据存储和性能的提升
* 变量嵌套和联合体的结构体
* 枚举和位掩码的灵活运用
* 全局变量减少术,提升代码执行效率
* 内存管理和效率提升的字符串操作
通过深入浅出的讲解和丰富的案例,本专栏旨在帮助读者掌握 C 语言中数据类型和变量的奥秘,提高代码质量,提升程序性能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
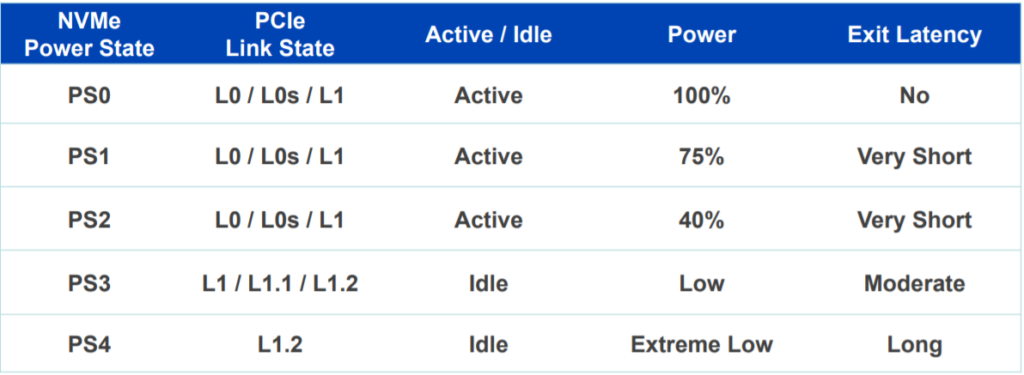
【PCIe 5.0兼容性指南】:保证旧有设备与新标准无缝对接(7大实用技巧)
# 摘要
本文深入探讨了PCIe 5.0技术的兼容性问题,从基本架构、协议新特性到设备升级和兼容性实践技巧,提供了全面的理论和实践指导。文中分析了PCIe 5.0的兼容性挑战,探讨了硬件、软件以及固件的升级策略,并通过多种实际案例,讨论了如何实现旧设备与PCIe 5.0的无缝对接。此外,本文还提出了一系列解决兼容性问题的方法,并对如何进行兼容性验证和认证给出了详细流程,旨在帮助技术人员确保设备升级后与PCIe 5.0技术的兼容性和性能的优化。
深入理解SpringBoot与数据库交互:JPA和MyBatis集成指南
# 摘要
本文详细介绍了SpringBoot与数据库交互的技术实践,探讨了JPA(Java Persistence API)和MyBatis两种流行的ORM(Object-Relational Mapping)框架的集成与应用。文章从基本概念和原理出发,详细阐述了JPA的集成过程、高级特性以及MyBatis的核心组件和工作方式。在深入分析了JPA
硬件在环仿真实战:Simetrix与你的完美结合
# 摘要
本文详细介绍了硬件在环仿真(Hardware in the Loop, HIL)的基本概念、Simetrix软件的功能及应用,并提供了多个实战案例分析。首先,概述了Simetrix软件的安装、界面布局和仿真技术,包括与其它仿真软件的对比。随后,本论文深入探讨了硬件在环仿真平台的搭建、测试实施以及结果分析方法。在Simetrix的高级应用方面,本文探讨了脚本编写、自动化测试、电路
【WinCC V16 脚本编程高级教程】

# 摘要
WinCC V16是西门子公司推出的组态软件,其脚本编程功能强大,是实现用户特定功能的关键工具。本文全面介绍了WinCC V16脚本编程的各个层面,从基础语法特性到高级应用技巧,再到问题诊断与优化策略。文中详细分析了变量、数据结构、控制结构、逻辑编程以及性能优化等关键编程要素。在实践应用方面,探讨了用户界面交互设计、数据通信、动态数据处理与可视化等实际场景。高级脚本应用部分着重讲解了数据处理、系统安
Layui上传文件错误处理:文件上传万无一失的终极攻略

# 摘要
Layui作为一款流行的前端UI框架,其文件上传功能对于开发交互性网页应用至关重要。本文首先介绍了Layui文件上传功能的基础知识,随后深入探讨了文件上传的理论基础,包括HTTP协议细节、Layui upload模块原理及常见错误类型。第三章和第四章集中于错误诊断与预防,以及解决与调试技巧,提供了前端和后端详细的错误处理方法和调试工具的使用。最后,第五章通过案例分析,展示了在复杂环境
【ESP8266与CJSON的结合】:打造个性化天气预警系统

# 摘要
本文介绍ESP8266平台与CJSON库的集成,旨在构建一个高效、个性化的天气预警系统。首先,本文概述ESP8266平台和CJSON库的基础知识,包括硬件架构、开发环境搭建,以及CJSON库在数据处理中的优势。接着,详细阐述了如何获取和解析天气数据,以及如何在ESP8266平台上利用CJSON进行数据解析和本地化显示。文中还探讨了如
【实战揭秘】:用社区地面系统模型解决复杂问题的技巧
# 摘要
本文深入探讨了社区地面系统模型的构建与应用,从理论基础到实践案例进行了全面分析。首先,概述了社区地面系统模型的重要性和构建原则,接着讨论了系统模型的数学表达和验证方法。文章详细介绍了该模型在城市规划、灾害管理以及环境质量改善方面的具体应用,并探讨了模型在解决复杂问题时的多层次结构和优化策略。此外,本文
【Asap光学设计界面布局】:全面解析提升设计效率的关键步骤
# 摘要
本文详细探讨了Asap光学设计软件界面布局的各个方面,从基础的理论框架、设计元素到实际的应用技巧以及高级应用。文中分析了界面布局的基本原则和设计效率的关系,介绍了提高用户体验的交互设计和优化策略,并通过用户研究、设计工具的应用与界面布局的迭代来强化实践技巧。此外,文章还讨论了动态布局与响应式设计,高级交互技术的应用,以
【PLSY与PLSR调试优化】:三菱PLC脉冲控制技巧,提升性能

# 摘要
本文深入探讨了PLC(可编程逻辑控制器)中PLSY(脉冲输出)与PLSR(脉冲输入)指令的基础知识、理论基础及其在实际应用中的优化与调试方法。重点介绍了这些指令的工作原理、参数设置对性能的影响、以及在特定场合如电机控制中的实现。文章还探讨了脉冲控制技术在三菱PLC中的应用,包括多轴协调控制和精密位置控制策略,并提出
【个性化和利时M6软件体验】

# 摘要
本文介绍个性化和利时M6软件的理论基础和实践应用。首先,概述了软件的功能需求和核心架构,包括用户研究、功能模块化设计、软件的整体架构以及关键技术组件。其次,通过实践案例,展示了用户界面个性化定制、功能模块灵活配置和用户行为数据分析的应用。接着,深入探讨了软件与企业业务流程集成的最佳实践,以及技术创新对软件个性化的影响。最后,分析了个性化和利时M6软件在性能优化、安全挑战应对以及持续支持与服务升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )