【C语言数据处理】:整型与浮点型,高级技巧与性能优化


16进制数据与浮点型数据转换——c语言程序
1. C语言中的数据类型基础
在C语言中,理解数据类型是进行有效编程的关键。数据类型定义了变量存储的数据种类以及在程序中的操作方式。本章我们将首先回顾C语言支持的原始数据类型,并探讨它们的基本用途。我们将从最简单的字符和整数类型开始,逐步深入到更复杂的数据类型如浮点数和布尔值,介绍它们在内存中的表示和操作。
1.1 C语言数据类型概述
C语言提供了一系列的内置数据类型,包括字符型(char)、整型(int)、浮点型(float和double)、布尔型(bool)等。每种类型都有特定的大小和表示范围,它们是构建更复杂数据结构和进行计算的基础。
1.2 内存中的数据表示
不同的数据类型占用不同的字节数,这影响了它们在内存中的表示。例如,一个int类型在大多数现代系统中占用4个字节,而float类型也通常占用4个字节,但它们在内存中的二进制表示完全不同。
1.3 变量的定义和初始化
在C语言中定义变量的基本格式是声明其类型和名称。例如,声明一个整型变量的方式如下:
- int number;
接着,可以使用=操作符进行初始化:
- number = 10;
初始化是编程中的一个常见步骤,它确保变量开始时拥有已知的状态。
通过本章,我们将搭建起理解后续各章节的基础,为深入探索C语言数据类型和它们在复杂场景下的运用打下坚实的基础。
2. 整型数据处理的深入理解
2.1 整型数据的分类和特性
2.1.1 基本整型变量的定义和使用
C语言提供了多种整型数据类型,包括有符号整型(signed)和无符号整型(unsigned)两大类。有符号整型能够表示正数、负数和零,而无符号整型仅能表示非负数。整型数据类型通常分为:char、int、short、long以及它们的无符号版本。
基本的整型变量定义可以使用以下语句:
- int num = 10;
- short int smallNum = 5;
- long bigNum = 1000000;
- unsigned int positiveNum = 15U;
int 类型在大多数平台上默认为 32 位,但这是平台相关的。short 通常为 16 位,long 至少为 32 位,但在64位系统中long可能是64位。char 类型可以是有符号或无符号的,取决于编译器和平台,它通常用于处理字符数据。
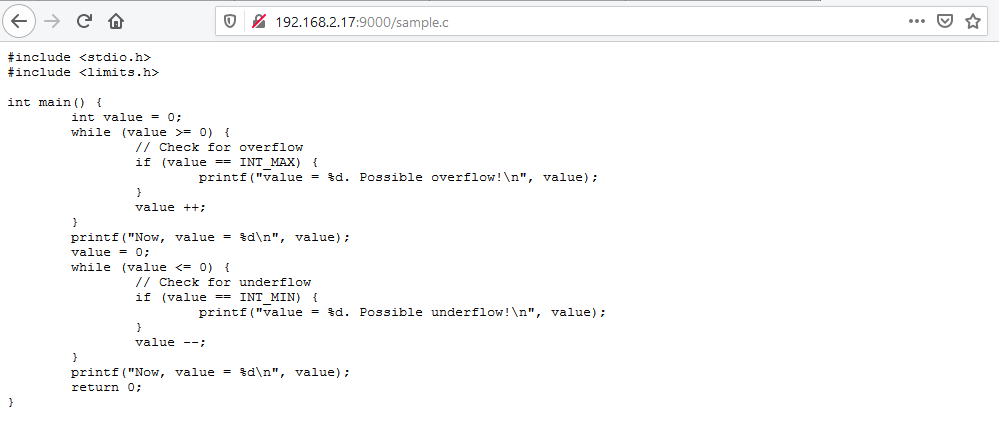
2.1.2 整型的溢出问题和边界条件
整型变量存在最大值和最小值的限制,当运算结果超出了其数据类型能表示的范围时,就会发生溢出。溢出会导致数据错误,因此理解和预防整型溢出是数据处理的关键。
- int main() {
- unsigned int max = UINT_MAX; // uint.h 中定义的最大值
- unsigned int result = max + 1;
- printf("Result is %u\n", result); // 输出将循环回 0
- return 0;
- }
在上面的代码中,result 的实际值将为 0,因为 max + 1 的值超出了 unsigned int 的表示范围。为了避免此类错误,开发者应检查边界条件,或者使用更大范围的数据类型(比如从 int 到 long)以确保可以容纳运算的结果。
2.2 整型数据的高级操作技巧
2.2.1 整型位操作的使用和注意事项
位操作是指通过位运算符对数据的二进制表示进行操作,这是一种高效的处理方式,尤其适用于硬件级别的编程。
位操作运算符包括:
&(按位与)|(按位或)^(按位异或)~(按位取反)<<(左移)>>(右移)
一个位操作示例代码如下:
- int main() {
- int x = 12; // 二进制表示为 1100
- int y = 10; // 二进制表示为 1010
- int result = x & y; // 按位与操作,结果为 1000,即 8
- printf("Result is %d\n", result); // 输出为 8
- return 0;
- }
注意事项:
- 位操作通常用于
int类型的数据,因为它的大小适合进行位操作。 - 使用位操作时要注意优先级,像
&和|的优先级比算术运算符低,通常需要加括号。 - 在进行位操作时,考虑数据类型的影响,尤其是无符号和有符号类型的差异。
2.2.2 整型与逻辑运算的交互技巧
在整型数据处理中,逻辑运算通常用于条件判断和流程控制。逻辑运算符包括:
&&(逻辑与)||(逻辑或)!(逻辑非)
需要注意的是,逻辑运算通常与条件表达式配合使用,且在逻辑判断中,它们会导致“短路”现象。
例如:
- int main() {
- int a = 5;
- int b = 10;
- if (a > 0 && b++ > 10) {
- // 由于 && 运算符左侧为真,右边也会执行,但只有当左边为假时右边才不会执行
- printf("b is %d\n", b); // 此时 b 的值为 11
- }
- return 0;
- }
逻辑运算在C语言中常常与位运算结合使用,能够提供更灵活的控制方式。
2.3 整型性能优化策略
2.3.1 整型数据存储的优化技术
整型数据的存储优化主要涉及减少内存占用和提高访问速度。数据类型的选择直接影响存储空间。例如,使用short代替int可以减少内存占用,但可能会影响性能,具体取决于硬件架构。
代码示例:
- short int compactArray[100]; // 使用 short int 减少内存占用
2.3.2 整型算法的性能调优方法
算法性能调优通常包括:
- 选择合适的算法和数据结构来减少运算量。
- 利用局部性原理优化数据访问模式,比如缓存友好的排序算法。
- 尽量减少分支预测失败,利用条件编译和位操作避免分支。
示例代码:
- // 利用循环展开来减少循环次数
- void fastSum(int *arr, int n, int *sum) {
- *sum = 0;
- for(int i = 0; i < n; i += 2) {
- *sum += arr[i] + (i + 1 < n ? arr[i + 1] : 0); // 条件编译减少分支
- }
- }
整型数据处理是C语言编程中最基础也是最核心的部分。深入理解整型数据的处理方式对于任何希望提升C语言编程能力的开发者都至关重要。通过优化整型数据的存储和算法,可以使程序运行更加高效,减少资源消耗。在这一章节中,我们探讨了整型数据的基本定义、高级操作技巧以及性能优化的方法,帮助读者能够更准确和高效地处理整型数据。
由于篇幅限制,以上内容仅作为第二章第二节的简介性内容。在实际的文章中,每个章节的内容会更为详尽,包含更多的示例代码、性能优化的案例分析、以及相关知识点的深入探讨。此外,根据要求,接下来的每个小节内容也会依据指定的字数标准进行扩展,确保整篇文章的丰富性和深度。
3. 浮点型数据处理的深入探索
3.1 浮点型数据的表示和精度问题
浮点型数据是用于表示非整数值的,在C语言中,浮点型数据主要指的是float、double和long double类型。这类数据类型在计算机内部是通过IEEE标准来表示的,这就意味着它们具有有限的范围和精度。
3.1.1 浮点数的存储机制和表示范围
浮点数的存储遵循IEEE 754标准,它定义了单精度(float,32位)、双精度(double,64位)和扩展精度(long double,80位或更多位)浮点数的二进制表示。
以单精度浮点数为例,其结构可以分为三个部分:
- 符号位(sign bit):1位,0表示正数,1表示负数。
- 指数位(exponent bits):8位,用于表示2的幂次。
- 尾数位(fraction bits):也称为小数位或有效数字位,23位。
通过这些位的组合,可以表示大约±3.4e±38的数值范围。双精度和扩展精度的表示方式类似,但它们的位数更多,因此可以表示更大范围和更高精度的数值。
3.1.2 浮点运算中的精度损失和解决方案
浮点数在进行运算时,尤其是加法和乘法,可能会导致精度损失。这是因为计算机需要对指数和尾数进行对齐,从而可能发生舍入。
为了最小化精度损失,我们可以采取以下策略:
- 尽量避免在不相关的数值范围之间进行混合运算。
- 使用更高精度的浮点数类型,比如从
float类型升级到double类型。 - 使用特定的数学函数库,这些库提供了更精确的算术操作。
3.2 浮点型数据的高级操作技巧
3.2.1 高精度浮点运算的实现方法
在C语言中,处理高精度浮点运算通常需要借

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【音视频同步技术】:HDP高清电视直播软件的技术难点与解决方案
ClustalX在进化生物学中的应用:揭开生命演化新篇章
波士顿矩阵分析误区全解析:避免常见陷阱的实用技巧
【高级仿真进阶】:线路阻抗变化对电力系统影响的深入剖析
【环境科学的空间分析】:莫兰指数在污染模式研究中的应用
环境感知流水灯:单片机与传感器接口技术
深入STM32内核:揭秘最小系统启动流程与性能优化(内附故障诊断技巧)
【VMWare vCenter高可用性部署秘籍】:确保业务连续性的终极方案
vRealize Automation 7.0:零基础快速入门指南
【电源设计升级】:LLC谐振变换器控制策略与性能指标计算(必备知识)


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )