使用Lucene构建全文检索引擎:原理与实践
发布时间: 2023-12-30 19:05:18 阅读量: 31 订阅数: 23 
# 章节一:全文检索引擎简介
## 1.1 什么是全文检索引擎?
全文检索引擎是一种用于快速检索大量文本数据的工具或系统。它通过将文本数据进行分词处理,并构建索引,以实现高效的文本搜索和匹配功能。全文检索引擎能够根据关键词或查询语句,快速找到与之相关的文档或记录,并按照相关性进行排序。全文检索引擎可以应用于各种领域,例如搜索引擎、电子商务、知识管理等。
## 1.2 全文检索引擎的应用领域
全文检索引擎在各个领域都有广泛应用。在搜索引擎领域,全文检索引擎是实现搜索功能的核心技术,能够快速索引和搜索互联网上的大量网页。在电子商务领域,全文检索引擎可以用于商品搜索、推荐和广告投放等场景。在知识管理领域,全文检索引擎可以用于文档检索、智能问答和信息抽取等功能。此外,全文检索引擎还可以应用于日志分析、数据挖掘、社交网络等领域,具有非常广泛的应用前景。
## 1.3 Lucene在全文检索引擎中的地位
Lucene是一个开源的全文检索引擎工具包,由Apache软件基金会开发和维护。Lucene提供了强大的文本搜索和索引功能,被广泛应用于各个领域。Lucene支持多种编程语言,并提供了丰富的API和功能,使得开发者可以快速构建高性能的全文检索引擎系统。在全文检索引擎领域,Lucene具有较高的市场占有率和较为稳定的技术生态,是开发者首选的工具之一。
## 1.4 Lucene的优势与特点
Lucene具有以下几个优势和特点:
- 高性能:Lucene使用了倒排索引等高效的数据结构和算法,能够实现快速的搜索和检索功能。
- 精确度:Lucene支持各种查询语法和查询类型,可以实现准确的文本匹配和相关性排序。
- 可扩展性:Lucene提供了丰富的API和插件机制,开发者可以根据需求定制和扩展功能。
- 多语言支持:Lucene支持多种常见的自然语言处理功能,如中文分词、同义词处理等。
- 易于使用:Lucene提供了简单易用的API和文档,开发者可以快速上手并构建全文检索引擎系统。
在接下来的章节中,我们将深入探讨Lucene的工作原理、构建全文检索引擎的准备工作、搜索功能实现以及扩展与应用等内容。通过学习和实践,您将掌握使用Lucene构建高效全文检索引擎的技能。
## 章节二:Lucene的工作原理
Lucene作为一款全文检索引擎,其工作原理主要包括倒排索引的概念及原理、索引结构与数据存储方式、搜索过程及相关算法,以及性能优化策略。让我们逐一来了解Lucene的工作原理。
### 3. 章节三:使用Lucene构建全文检索引擎的准备工作
全文检索引擎的实现离不开Lucene的支持,下面我们将详细介绍使用Lucene构建全文检索引擎的准备工作。
#### 3.1 安装与配置Lucene环境
在开始构建全文检索引擎之前,首先需要安装并配置Lucene环境。你可以通过以下步骤来完成:
##### Python环境下的安装与配置:
首先,你需要安装Python,然后使用pip命令安装Python的Lucene库:
```python
pip install lucene
```
接下来,配置Lucene的环境变量,确保Python可以找到Lucene的相关库。
##### Java环境下的安装与配置:
在Java环境下,你可以按照以下步骤安装Lucene:
1. 下载Lucene的最新版本压缩包,并解压到指定目录。
2. 配置环境变量,将Lucene的bin目录添加到系统PATH中。
#### 3.2 数据处理与准备
构建全文检索引擎之前,需要对待索引的数据进行处理与准备。这包括数据清洗、分词处理、数据格式转换等工作,确保数据能够被正确地索引与搜索。
#### 3.3 构建索引库的步骤与方法
构建索引库是全文检索引擎的核心任务之一,需要按照以下步骤进行:
1. 创建索引Writer对象;
2. 遍历待索引的数据,将数据转换为文档对象;
3. 将文档对象添加到索引库中;
4. 提交索引库的更改并关闭资源。
#### 3.4 Lucene的常用API介绍
在构建全文检索引擎时,你会用到许多Lucene提供的API,这些API包括索引管理、搜索查询、分词器等。在接下来的章节中,我们将会深入介绍这些API的使用方法。
以上是使用Lucene构建全文检索引擎的准备工作,下一步我们将深入探讨Lucene索引库的构建与搜索功能的实现。
### 4. 章节四:Lucene的搜索功能实现
在本章中,我们将深入探讨Lucene全文检索引擎的搜索功能实现原理,包括简单搜索与多字段搜索、条件过滤与排序、查询语法与高级查询、相似度匹配与相关性排序等内容。通过本章的学习,读者将能够深入了解Lucene搜索功能的实现细节,并能够在实际应用中灵活运用。
#### 4.1 简单搜索与多字段搜索
在这一部分,我们将介绍如何使用Lucene实现简单搜索和多字段搜索的功能。简单搜索是最基本的搜索方式,而多字段搜索可以通过指定字段进行搜索,从而提高搜索的精确度。
```java
// Java示例代码
// 创建查询解析器
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
// 解析查询字符串
Query query = parser.parse("Lucene");
// 执行搜索
TopDocs topDocs = searcher.search(query, 10);
```
```python
# Python示例代码
from whoosh.qparser import QueryParser
from whoosh.index import open_dir
# 打开索引
ix = open_dir("indexdir")
# 创建查询解析器
qp = QueryParser("content", schema=ix.schema)
# 解析查询字符串
q = qp.parse("Lucene")
# 执行搜索
results = searcher.search(q, limit=10)
```
#### 4.2 条件过滤与排序
在本节中,我们将讨论如何在Lucene中实现条件过滤和排序功能。条件过滤可以帮助用户缩小搜索范围,而排序功能可以根据相关性对搜索结果进行排序。
```java
// Java示例代码
// 创建查询解析器
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
// 解析查询字符串
Query query = parser.parse("Lucene");
// 创建过滤器
Query filterQuery = NumericRangeQuery.newIntRange("publishYear", 2010, 2020, true, true);
// 构建组合查询
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(query, BooleanClause.Occur.MUST);
builder.add(filterQuery, BooleanClause.Occur.MUST);
Query finalQuery = builder.build();
// 执行搜索并排序
TopDocs topDocs = searcher.search(finalQuery, 10, Sort.INDEXORDER);
```
```python
# Pyt
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏深入探讨了全文检索的各种技术和应用,涵盖了从基础概念到高级算法的全面内容。文章从入门指南到实践应用,介绍了全文检索中的原理、技术和实现方法。专栏主题涉及文本分词、倒排索引、TF-IDF算法、N-gram模型、BM25算法、Word2Vec、Redis缓存系统、多语言支持、Bloom Filter、Spark等多个方面,覆盖了全文检索中的语义分析、性能优化、缓存系统、国际化解决方案等关键问题。不仅如此,还包括了全文检索的近似字符串匹配、自动纠错、关键词扩展、异构数据集成与查询优化等高级技术与应用。无论是全文检索初学者还是资深开发工程师,都能从中获取到丰富的知识和实践经验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据表结构革新】租车系统数据库设计实战:提升查询效率的专家级策略

# 1. 数据库设计基础与租车系统概述
## 1.1 数据库设计基础
数据库设计是信息系统的核心,它涉及到数据的组织、存储和管理。良好的数据库设计可以使系统运行更加高效和稳定。在开始数据库设计之前,我们需要理解基本的数据模型,如实体-关系模型(ER模型),它有助于我们从现实世界中抽象出数据结构。接下来,我们会探讨数据库的规范化理论,它是减少数据冗余和提高数据一致性的关键。规范化过程将引导我们分解数据表,确保每一部分数据都保持其独立性和
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【可持续发展】:绿色交通与信号灯仿真的结合

# 1. 绿色交通的可持续发展意义
## 1.1 绿色交通的全球趋势
随着全球气候变化问题日益严峻,世界各国对环境保护的呼声越来越高。绿色交通作为一种有效减少污染、降低能耗的交通方式,成为实现可持续发展目标的重要组成部分。其核心在于减少碳排放,提高交通效率,促进经济、社会和环境的协调发展。
## 1.2 绿色交通的节能减排效益
相较于传统交通方式,绿色交
自助点餐系统的云服务迁移:平滑过渡到云计算平台的解决方案

# 1. 自助点餐系统与云服务迁移概述
## 1.1 云服务在餐饮业的应用背景
随着技术的发展,自助点餐系统已成为餐饮行业的重要组成部分。这一系统通过提供用户友好的界面和高效的订单处理,优化顾客体验,并减少服务员的工作量。然而,随着业务的增长,许多自助点餐系统面临着需要提高可扩展性、减少维护成本和提升数据安全性等挑战。
## 1.2 为什么要迁移至云服务
传统的自助点餐系统
视觉SLAM技术应用指南:移动机器人中的应用详解与未来展望

# 1. 视觉SLAM技术概述
## 1.1 SLAM技术的重要性
在机器人导航、增强现实(AR)和虚拟现实(VR)等领域,空间定位
【并发链表重排】:应对多线程挑战的同步机制应用
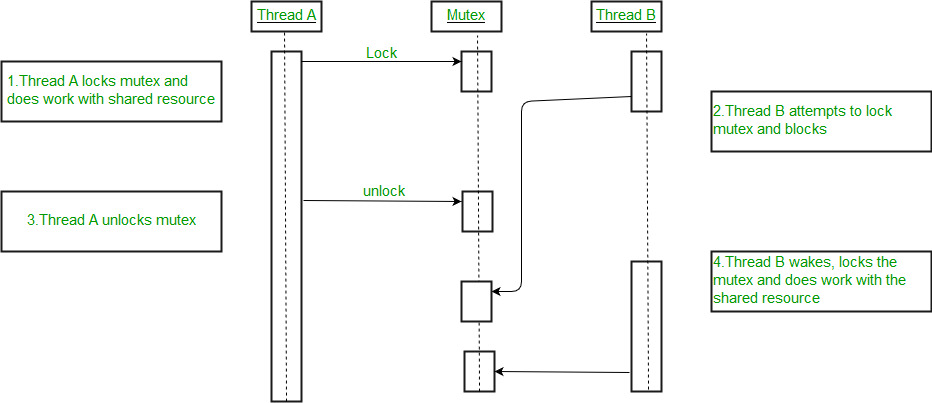
# 1. 并发链表重排的理论基础
## 1.1 并发编程概述
并发编程是计算机科学中的一个复杂领域,它涉及到同时执行多个计算任务以提高效率和响应速度。并发程序允许多个操作同时进行,但它也引入了多种挑战,比如资源共享、竞态条件、死锁和线程同步问题。理解并发编程的基本概念对于设计高效、可靠的系统至关重要。
## 1.2 并发与并行的区别
在深入探讨并发链表重排之前,我们需要明确并发(Con
【同轴线老化与维护策略】:退化分析与更换建议

# 1. 同轴线的基本概念和功能
同轴电缆(Coaxial Cable)是一种广泛应用的传输介质,它由两个导体构成,一个是位于中心的铜质导体,另一个是包围中心导体的网状编织导体。两导体之间填充着绝缘材料,并由外部的绝缘护套保护。同轴线的主要功能是传输射频信号,广泛应用于有线电视、计算机网络、卫星通信及模拟信号的长距离传输等领域。
在物理结构上,
STM32与IIC设备通讯实战手册:手把手教你成为通信大师

# 1. STM32与IIC设备通信基础
IIC(Inter-Integrated Circuit)即集成电路总线,是一种多主机的串行通信协议,广泛应用于微控制器和各种外围设备之间的数据交换。了解STM32与IIC设备的通信基础是构建稳定嵌入式系统的关键步骤。
## 1.1 IIC总线简介
IIC总线由两根线组成,
【Chirp信号抗干扰能力深入分析】:4大策略在复杂信道中保持信号稳定性
# 1. Chirp信号的基本概念
## 1.1 什么是Chirp信号
Chirp信号是一种频率随时间变化的信号,其特点是载波频率从一个频率值线性增加(或减少)到另一个频率值。在信号处理中,Chirp信号的这种特性被广泛应用于雷达、声纳、通信等领域。
## 1.2 Chirp信号的特点
Chirp信号的主要特点是其频率的变化速率是恒定的。这意味着其瞬时频率与时间
【低功耗设计达人】:静态MOS门电路低功耗设计技巧,打造环保高效电路
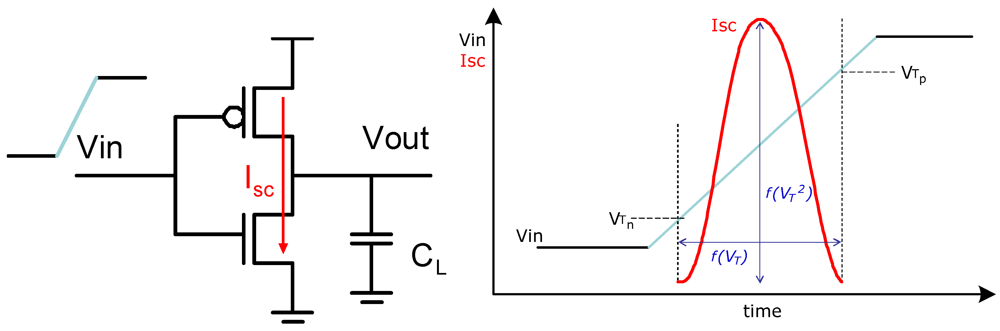
# 1. 静态MOS门电路的基本原理
静态MOS门电路是数字电路设计中的基础,理解其基本原理对于设计高性能、低功耗的集成电路至关重要。本章旨在介绍静态MOS门电路的工作方式,以及它们如何通过N沟道MOSFET(NMOS)和P沟道MOSFET(PMOS)的组合来实现逻辑功能。
## 1.1 MOSFET的基本概念
MOSFET,全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )